基于Hadoop大數(shù)據(jù)平臺(tái)的金融產(chǎn)品購(gòu)買行為分析
2019-04-26 05:03:34龐雙玉
電子技術(shù)與軟件工程 2019年4期
文/龐雙玉
1 引言
商業(yè)銀行非常重要的一項(xiàng)業(yè)務(wù)就是零售業(yè)務(wù),銀行零售業(yè)務(wù)成既能夠提供為銀行提供穩(wěn)定的低成本的來(lái)源,又能對(duì)沖銀行其他業(yè)務(wù)的不穩(wěn)定性,同時(shí)又滿足了客戶的理財(cái)需求,銀行零售業(yè)務(wù)迅速成為新的業(yè)務(wù)增長(zhǎng)點(diǎn)。銀行代銷各大基金公司推出的產(chǎn)品,針對(duì)差異化的客戶和客戶需求,發(fā)售不同風(fēng)險(xiǎn)級(jí)別和不同收益區(qū)間段的產(chǎn)品。
銀行的產(chǎn)品研發(fā)部門(mén)能否針對(duì)當(dāng)前經(jīng)濟(jì)形勢(shì)和客戶存款狀況,結(jié)合基金公司發(fā)行的產(chǎn)品類型研發(fā)出適應(yīng)市場(chǎng)和客戶需求的產(chǎn)品,是整個(gè)銀行零售業(yè)務(wù)核心競(jìng)爭(zhēng)力的來(lái)源。針對(duì)銀行海量的交易數(shù)據(jù),運(yùn)用大數(shù)據(jù)框架,從交易數(shù)據(jù)中尋找規(guī)律和做出判斷,為銀行的產(chǎn)品引入決策提供支持,是一件有意義的事情。
本文討論在Hadoop大數(shù)據(jù)框架下,利用map/reduce機(jī)制,對(duì)交易數(shù)據(jù)進(jìn)行分析,分析在銀行代銷的各大基金公司在某個(gè)歷史時(shí)間段的交易額,從交易金額數(shù)據(jù)中,判斷出客戶對(duì)基金公司的偏愛(ài)度。
2 數(shù)據(jù)建模和處理
銀行的數(shù)據(jù)庫(kù)系統(tǒng)中存儲(chǔ)有大量的客戶交易數(shù)據(jù),從交易數(shù)據(jù)中,提取出下列的字段組合,(交易基金公司,基金公司產(chǎn)品,交易金額)以C(Company)代表交易基金公司,以P(Product)代表產(chǎn)品名稱,以A(Amount)代表交易金額,字段組合為(C,P,A)。
在字段(C,P,A)中,有價(jià)值的字段是C和A,因?yàn)榛鸸井a(chǎn)品名稱不是關(guān)心的對(duì)象,所以,在map階段,去掉字段組合(C,P,A)中的P字段,以(C,A)作為reuduce的輸入字段。map/reduce完成對(duì)字段的統(tǒng)計(jì)和排序,整個(gè)統(tǒng)計(jì)和排序字段值的變化過(guò)程如圖1所示。
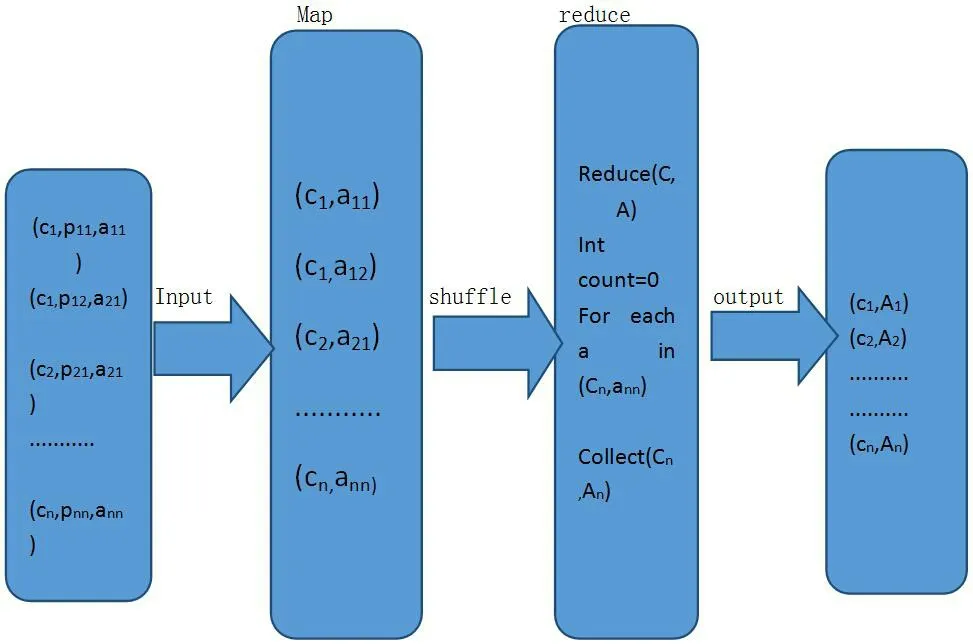
圖1:map/reduce處理數(shù)據(jù)模型
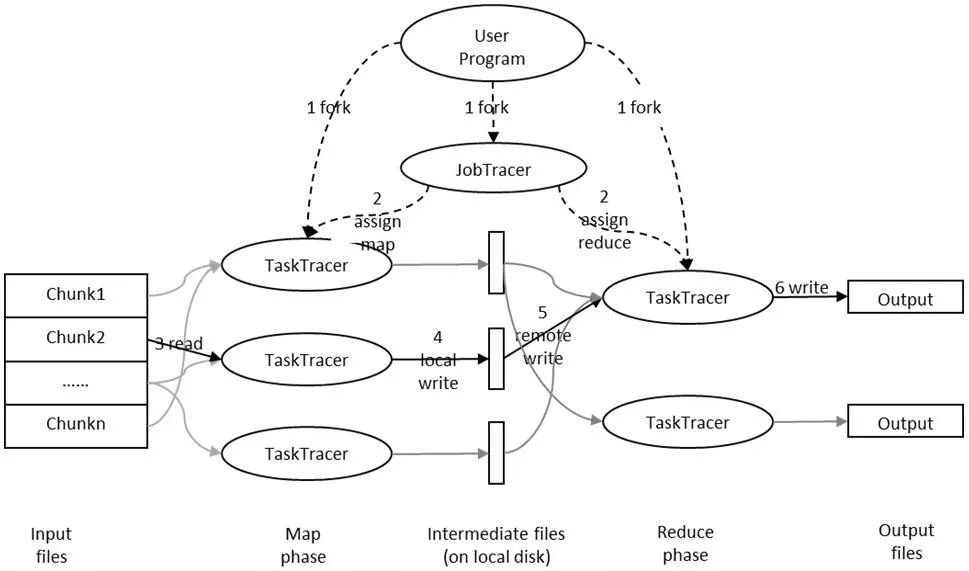
圖2:map/reducec處理流程圖
在圖1中,Cn代表基金公司ID,第n個(gè)基金公司,Pnn代表第n個(gè)基金公司的第n個(gè)產(chǎn)品名稱,ann代表第n個(gè)基金公司第n個(gè)產(chǎn)品的銷售金額,把(cn, pnn, ann)作為map/reduce的輸入。
在map階段,去掉字段組合中的pnn,因?yàn)槟硞€(gè)基金公司的某個(gè)特定產(chǎn)品名稱不是我們關(guān)心的內(nèi)容,我們只關(guān)心,每個(gè)客戶對(duì)于某個(gè)特定基金公司的交易金額,去掉pnn字段后,字段組合只剩下(cn, ann)。
在shuff le階段,按照基金公司ID,進(jìn)行分組排列字段(cn, ann),比如:

這樣,我們就得到了一個(gè)
在reduce階段完成對(duì)每個(gè)C下面的交易金額的累加,最后形成輸出結(jié)果,每個(gè)基金公司總的交易金額(Cn, An)。
整個(gè)數(shù)據(jù)模型的變換過(guò)程如下:

3 map/reduce作業(yè)處理流程
在Hadoop處理框架中,map/reduce作業(yè)處理流程如圖2所示。
(1)MapReduce首先將資源文件進(jìn)行分解,分成多個(gè)Chunk,一個(gè)chunk大概64M,同時(shí)用fork將進(jìn)程拷貝到集群內(nèi)其它機(jī)器上。
(2)集群中的JobTracer在TaskTracer中制定map和Reduce。
(3)被分配了Map作業(yè)的worker,開(kāi)始讀取第1步分解好的Trunk,Map作業(yè)數(shù)量是由M決定的,和split一一對(duì)應(yīng);Map作業(yè)從輸入數(shù)據(jù)中抽取出鍵值對(duì),每一個(gè)鍵值對(duì)都作為參數(shù)傳遞給map函數(shù),map函數(shù)產(chǎn)生的中間鍵值對(duì)被緩存在內(nèi)存中。
(4)緩存的中間鍵值對(duì)會(huì)被定期寫(xiě)入本地磁盤(pán),而且被分為R個(gè)區(qū),R的大小是由用戶定義的,將來(lái)每個(gè)區(qū)會(huì)對(duì)應(yīng)一個(gè)Reduce作業(yè);這些中間鍵值對(duì)的位置會(huì)被通報(bào)給master,master負(fù)責(zé)將信息轉(zhuǎn)發(fā)給Reduce worker。
(5)master通知分配了Reduce作業(yè)的worker它負(fù)責(zé)的分區(qū)在什么位置(肯定不止一個(gè)地方,每個(gè)Map作業(yè)產(chǎn)生的中間鍵值對(duì)都可能映射到所有R個(gè)不同分區(qū)),當(dāng)Reduce worker把所有它負(fù)責(zé)的中間鍵值對(duì)都讀過(guò)來(lái)后,先對(duì)它們進(jìn)行排序,使得相同鍵的鍵值對(duì)聚集在一起。因?yàn)椴煌逆I可能會(huì)映射到同一個(gè)分區(qū)也就是同一個(gè)Reduce作業(yè)(誰(shuí)讓分區(qū)少呢),所以排序是必須的。
(6)reduce worker遍歷排序后的中間鍵值對(duì),對(duì)于每個(gè)唯一的鍵,都將鍵與關(guān)聯(lián)的值傳遞給reduce函數(shù),reduce函數(shù)產(chǎn)生的輸出會(huì)添加到這個(gè)分區(qū)的輸出文件中。
(7)當(dāng)所有的Map和Reduce作業(yè)都完成了,master喚醒正版的user program,MapReduce函數(shù)調(diào)用返回user program的代碼。
4 結(jié)論
利用Hadoop平臺(tái)的map/reduce流程對(duì)銀行交易數(shù)據(jù)的分析,從數(shù)據(jù)規(guī)模上,可以對(duì)海量數(shù)據(jù)進(jìn)行分析,從分析結(jié)果上,在足夠大的客戶交易數(shù)據(jù)樣本上得出的每個(gè)基金公司的交易金額更能客觀的反映出客戶對(duì)該基金公司的偏愛(ài)度,從而為銀行引入產(chǎn)品提供決策支持。
猜你喜歡
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
High Technology Letters(2017年3期)2017-09-25 12:53:30
中國(guó)老區(qū)建設(shè)(2016年3期)2017-01-15 13:53:21
故事大王(2016年7期)2016-09-22 17:30:08
創(chuàng)新作文(小學(xué)版)(2016年20期)2016-08-22 09:11:22
上海國(guó)資(2015年8期)2015-12-23 01:47:31
兒童故事畫(huà)報(bào)(2013年3期)2013-06-24 05:40:30
投資與理財(cái)(2009年21期)2009-11-17 09:59:46
投資與理財(cái)(2009年18期)2009-09-30 06:18:16
小哥白尼·軍事科學(xué)畫(huà)報(bào)(2009年9期)2009-09-14 03:18:56
