基于多核處理器的雷達多通道處理與優化
2019-04-26 05:03:08竇澤華黎賀
電子技術與軟件工程 2019年4期
文/竇澤華 黎賀
隨著作戰場景的日益復雜,以及雷達技術的不斷發展,雷達處理通道數越來越多,帶寬(采樣率)越來越高。以泰勒斯公司的GM200雷達為例,處理通道數大于20個,采樣率5MHz,總數據率大于6.4Gbps;另一方面現代信號處理技術快速發展,運算量較傳統雷達信號處理技術大幅增加。高數據率、大運算量,對后端處理的需求越來越高。
幸運的是處理器的能力也在不斷進步,多核CPU,眾核GPU的出現,使得高數據率、大運算量的處理成為可能。以目前市場上的商用服務為例,四顆CPU(E5或E7)架構的服務器,最大有60個計算核。如此多的計算核(并且按照發展趨勢CPU核的數量會越來越多),雷達信息處理軟件該如何設計,以便充分發揮其計算性能。
本文以實際工程中的某產品為例,探討多核CPU下的使用方案,并在實施過程中對不必要的多余內存操作進行優化,進一步提高處理通過率。為后續雷達高數據率、大運算量處理提供工程參考。
1 需求分析
1.1 產品介紹
某雷達通道數24個,采樣率5MHz,分6根光纖,每個光纖傳輸4個通道數據,總數據量6.7Gbps。如圖1所示。
雷達陣面下行的每個光纖內4個通道的數據打包格式如圖2所示。
對信息處理而言,第一級處理的任務是將6根光纖數據接收緩存,并完成光纖之間的數據同步、通道數據拆分(將屬于同一個通道的數據整理在一起),以方便后續處理。其對內存數據的頻繁操作,使其成為整個信息處理的瓶頸。本文就以通道拆分為例,研究多核CPU的高數據率、大運算量的應用。

圖2:光纖內多通道數據格式

圖3:方法(1)處理器執行示意圖

圖4:方法(2)處理器執行示意圖
1.2 處理平臺介紹
本文使用基于2顆Intel志強E5處理器的刀片服務器作為處理平臺,其關鍵參數如下:
(1)計算資源:雙路Intel Xeon E5-2648L v3(12核,1.8GHz)
(2)內存資源:板載DDR4 2133MT/s 64GB
該處理平臺除去操作系統、中間件驅動使用的4個核,總計有20個核用于計算。
2 方案設計
2.1 方案比較
根據上述需求,通道拆分需要完成6根光纖數據的拆分重組,基于多核處理器有多種并行處理方法:
方法(1)按光纖數量并行,6根光纖并行處理,按照此方法,只有6個核在運行,有14個核處于空閑狀態,處理時間T1;
方法(2)按24個通道并行,由于處理平臺只有20個計算核,一次并行20個通道,剩下的4個通道還得處理一遍,此時會有16個核處于空閑狀態,處理時間2T2;
方法(3)按數據點數并行,一次并行20個點,依次執行,最后一次執行可能不足20個點,處理時間
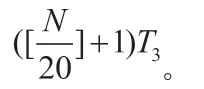
三種方法的并行示意圖如圖3、圖4、圖5所示。
方案(1)和方案(2)并行顆粒度較粗,均會出現多個核的空閑,且每次執行時間較長,沒有充分發揮多核的性能。只有在光纖數量、通道數量是核的整數倍時,效率最高,但實際工程中該情況較少;方案(3)并行顆粒度最細,雖然在最后一次執行也存在部分核的空閑,但每次執行只處理1個數據點,執行時間短,整體效率最高。在工程中,也可以考慮舍棄最后小于20(即核的數量)個點的數據,對雷達系統影響甚微。
根據上述分析,多核并行處理,要求并行的顆粒度越細,執行效率越高。
2.2 方案實施
根據上述分析,設計多通道收數預處理的處理流程如下(圖6):
(1)6個核并行接收6根光纖的數據;
(2)通道拆分前,完成6根光纖數據的合并;
(3)通道拆分:6根光纖24個通道的數據整理;
(4)通道整理,按需求完成有效通道的整理。
2.3 方案優化
對初步方案的處理性能進行測試,整體數據通過率7.05Gbps。相比輸入數據率6.7Gbps,系統余量只有5%,處理能力臨界,存在系統飽和的風險,需要對方案進行優化。
對照流程圖,步驟(3)的通道拆分經過方案的比較,提升空間不大。初步方案為考慮軟件的通用性,在通道拆分前后對數據整理以滿足步驟(3)通道拆分接口的簡化統一,但其對內存訪問頻繁,占據一半的處理時間。
按照盡量減少對內存的訪問原則,對初步方案作以下優化:2.3.1 多核光纖收數
步驟(1)設計6個核并行接收6根光纖的數據,同樣存在并行顆粒度過粗,處理核空閑,效率不高。改進為6根光纖串行收數,每根光纖20個核并行訪問內存。
2.3.2 舍棄多光纖數據合并,
步驟(2)的數據合并是為了方便步驟(3)通道拆分的執行。舍棄該步驟后,步驟(3)的通道拆分采用6根光纖串行,依次調用通道拆分函數完成6根光纖的數據拆分。因為通道拆分是按數據點并行,所以6根光纖串行處理,并不會降低效率改造后的流程圖
2.3.3 舍棄拆分后的通道整理
通道拆分后,在某些應用模式下,24個通道中的部分數據并不完全需要,或者需要調整數據順序,方便后續的處理,因此需要對拆分后的24個通道再進行一次整理。
舍棄該步驟后,結合第2.3.2條優化,在每根光纖數據拆分的同時,根據應用模式需求,完成拆分后的數據存放。
最終優化后的處理流程如圖7所示。
優化后的整體數據通過率大于14Gbps,比初始方案提高1倍,系統余量50%,大大滿足系統需求。可見內存作為處理器的外設存儲設備,是多核/眾核高性能處理器的性能瓶頸,對處理能力的影響巨大。工程使用過程中,應盡量減少對內存的頻繁訪問操作。
3 結束語
本文基于24核雙CPU處理平臺,探討了雷達多通道的處理方式。
(1)多核并行顆粒度越細,對多核的利用效率越高。對于后續的脈沖壓縮、CFAR等需要訪問相鄰數據的算法,可考慮將數據劃分成若干片段進行并行,最大程度接近最優的方案;
(2)內存作為處理器的外設,已成為高性能處理的瓶頸,處理過程中應盡量較少對內存的讀寫操作,以此提高整體通過率。
基于上述多核多通道并行處理的方法,已經在某軟件化雷達項目中成功應用。

圖5:方法(3)處理器執行示意圖

圖6:多通道預處理流程圖

圖7:多通道預處理流程圖
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
