面向高維特征和多分類的分布式梯度提升樹?
2019-04-18 05:07:20江佳偉符芳誠邵鎣俠
軟件學(xué)報 2019年3期
關(guān)鍵詞:特征
江佳偉,符芳誠,邵鎣俠,崔 斌
1(高可信軟件技術(shù)教育部重點實驗室(北京大學(xué)),北京 100871)
2(北京郵電大學(xué) 計算機學(xué)院,北京 100876)
梯度提升樹(gradient boosting decision tree,簡稱 GBDT)是一種使用 Boosting策略的集成機器學(xué)習(xí)算法.集成機器學(xué)習(xí)算法通常使用Bagging,Boosting,AdBoost等策略[1,2],基本思想是訓(xùn)練多個弱分類器來生成更準(zhǔn)確的結(jié)果.GBDT使用的 Boosting策略通過依次學(xué)習(xí)多個弱學(xué)習(xí)器不斷地提升性能,梯度提升樹使用樹模型作為弱學(xué)習(xí)器.梯度提升樹算法在分類、回歸、排序等諸多問題上取得了優(yōu)異的性能[3-5],在學(xué)術(shù)界和工業(yè)界中被廣泛地使用[6],也是例如Kaggle等數(shù)據(jù)競賽中最受歡迎的算法之一.在大數(shù)據(jù)時代,由于單機的計算能力和存儲能力有限,無法有效地處理動輒達(dá)到TB甚至PB級別的數(shù)據(jù),因而需要在分布式環(huán)境下設(shè)計和執(zhí)行梯度提升樹算法,分布式梯度提升樹算法因而成為目前的研究熱點.
梯度提升樹算法的訓(xùn)練主要包括3個關(guān)鍵過程.
1) 建立梯度直方圖.對于給定的損失函數(shù),對輸入的訓(xùn)練數(shù)據(jù),計算它們的梯度,將所有的梯度數(shù)據(jù)組織成梯度直方圖的數(shù)據(jù)結(jié)構(gòu);
2) 尋找最佳分裂點.根據(jù)建立的所有特征的梯度直方圖,計算出樹節(jié)點的最佳分裂點,包括特征和分裂特征值;
3) 分裂樹節(jié)點.根據(jù)計算出的最佳分裂點來分裂樹節(jié)點,建立子節(jié)點,根據(jù)分裂點將訓(xùn)練數(shù)據(jù)劃分到子節(jié)點上,并回到步驟1)開始下一輪迭代.
在分布式環(huán)境下設(shè)計機器學(xué)習(xí)算法,有數(shù)據(jù)并行和特征并行兩種策略:數(shù)據(jù)并行將訓(xùn)練數(shù)據(jù)集按行進(jìn)行切分,每個計算節(jié)點處理一部分?jǐn)?shù)據(jù)子集;而特征并行將訓(xùn)練數(shù)據(jù)集按列進(jìn)行切分,每個計算節(jié)點處理一部分特征子集.已有的分布式梯度提升樹系統(tǒng),例如MLlib[7],XGBoost[8],LightGBM[9,10]等,通常使用數(shù)據(jù)并行策略在分布式環(huán)境下訓(xùn)練.目前,沒有工作系統(tǒng)性地比較數(shù)據(jù)并行和特征并行策略的優(yōu)劣,數(shù)據(jù)并行是否在所有情況下都能取得最佳的性能,是一個仍然未被討論和解決的問題.
筆者發(fā)現(xiàn),在多種情況下,采用數(shù)據(jù)并行的分布式梯度提升樹算法會遇到性能瓶頸:一方面,在梯度提升樹算法所處理的多種問題中,多分類問題由于較高的計算復(fù)雜度和空間復(fù)雜度,采用數(shù)據(jù)并行的梯度提升樹算法目前無法在分布式環(huán)境下有效地處理;另一方面,隨著各行業(yè)的飛速發(fā)展,數(shù)據(jù)的來源越來越多,因而數(shù)據(jù)集的特征維度越來越高,這樣的高維特征給數(shù)據(jù)并行的梯度提升樹算法帶來了新的挑戰(zhàn).為了解決以上存在的問題,本文關(guān)注在高維特征和多分類問題下如何高效地訓(xùn)練分布式梯度提升樹算法.
在分布式環(huán)境下訓(xùn)練梯度提升樹算法時,數(shù)據(jù)并行和特征并行采用不同的方式:數(shù)據(jù)并行策略將訓(xùn)練數(shù)據(jù)集按行切分到計算節(jié)點,計算節(jié)點建立局部梯度直方圖,然后通過網(wǎng)絡(luò)匯總計算節(jié)點的局部梯度直方圖;特征并行策略將訓(xùn)練數(shù)據(jù)集按列切分到計算節(jié)點,計算節(jié)點建立梯度直方圖并計算出最佳分裂點,然后通過網(wǎng)絡(luò)交換分裂結(jié)果.由于梯度直方圖的大小與特征數(shù)量和類別數(shù)量成正比,對于高維和多分類問題,數(shù)據(jù)并行需要通過網(wǎng)絡(luò)傳輸大量的梯度直方圖,因而存在性能不佳的問題.相比之下,特征并行需要通過網(wǎng)絡(luò)傳輸?shù)臄?shù)據(jù)只與數(shù)據(jù)量大小有關(guān),因而更適合高維和多分類的場景.
為了使用梯度提升樹算法高效地求解高維和多分類問題,本文提出了一種基于特征并行的梯度提升樹算法FP-GBDT.通過從理論上比較數(shù)據(jù)并行和特征并行,本文證明特征并行更適合高維和多分類場景,然后設(shè)計了特征并行的分布式梯度提升樹算法.本文的貢獻(xiàn)可以總結(jié)如下:在提出代價模型的基礎(chǔ)上,從理論上比較了數(shù)據(jù)并行和特征并行兩種訓(xùn)練策略的開銷,證明對于高維和多分類數(shù)據(jù)集,特征并行具有較小的網(wǎng)絡(luò)開銷、內(nèi)存開銷和可擴展性;提出了基于特征并行的分布式梯度提升樹算法FP-GBDT.首先,設(shè)計了一種分布式矩陣轉(zhuǎn)置方法轉(zhuǎn)換數(shù)據(jù)表征;然后,在建立梯度直方圖時使用了稀疏感知的方法;最后,在分裂樹節(jié)點時提出了比特圖壓縮方法來減少數(shù)據(jù)傳輸;通過與現(xiàn)有分布式梯度提升樹算法進(jìn)行詳盡的實驗比較,證明了FP-GBDT算法的高效性.
本文第 1節(jié)介紹梯度提升樹算法的預(yù)備知識和相關(guān)工作,包括算法模型和訓(xùn)練方法.第 2節(jié)從理論上比較數(shù)據(jù)并行和特征并行的開銷.第3節(jié)介紹FP-GBDT算法的細(xì)節(jié).第4節(jié)給出實驗對比結(jié)果.第5節(jié)總結(jié)全文.
1 預(yù)備知識及相關(guān)工作
在本節(jié)中,主要介紹研究對象梯度提升樹算法的模型和訓(xùn)練方法.其中,第 1.1節(jié)介紹數(shù)據(jù)集表征,第 1.2節(jié)簡要介紹梯度提升樹算法,第1.3節(jié)介紹梯度提升樹的訓(xùn)練方法,第1.4節(jié)介紹分布式梯度提升樹的研究進(jìn)展.
1.1 輸入數(shù)據(jù)集
1.2 梯度提升樹算法概述
梯度提升樹算法是基于樹的集成機器學(xué)習(xí)方法[8],梯度提升樹算法會依次訓(xùn)練多個回歸樹模型.在一棵樹中,從根節(jié)點開始,每個樹節(jié)點需要給出一個分裂規(guī)則,此分裂規(guī)則包括分裂特征和分裂特征值,根據(jù)分裂規(guī)則將數(shù)據(jù)樣本切分到下一層的子樹節(jié)點,最終,每個數(shù)據(jù)樣本xi被分配到一個葉子節(jié)點,葉子節(jié)點將其上的數(shù)據(jù)樣本預(yù)測為w.與決策樹不同之處在于:梯度提升樹的葉子節(jié)點給出的是連續(xù)值,而不是類別,在訓(xùn)練完一棵樹之后,將w加到每個數(shù)據(jù)樣本的預(yù)測值上,然后以新的預(yù)測值開始訓(xùn)練下一棵樹.梯度提升樹累加所有樹的預(yù)測值作為最終的預(yù)測值[1]:
其中,T是樹的數(shù)量,ft(xi)是第t棵樹的預(yù)測結(jié)果,η是一個叫學(xué)習(xí)速度的超參數(shù).
圖1展示了梯度提升樹算法的例子,目的是預(yù)測一個購物網(wǎng)站上用戶的消費能力.
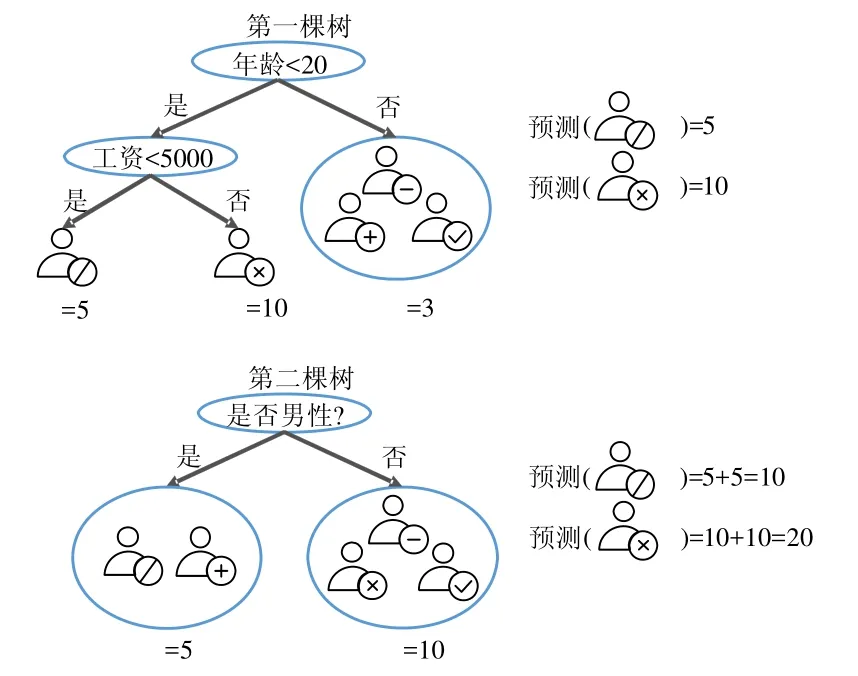
Fig.1 An example of gradient boosting decision tree圖1 梯度提升樹算法示例
第1棵樹使用年齡是否小于20和工資是否小于5 000作為分裂規(guī)則,得到第1棵樹的預(yù)測值,并以此更新數(shù)據(jù)樣本的預(yù)測值;接著,以新的預(yù)測值開始訓(xùn)練第2棵樹,第2棵樹以是否為男性作為分裂規(guī)則,得到第2棵樹的預(yù)測值.最終的預(yù)測值為兩棵樹的預(yù)測值之和,例如,標(biāo)識為“/”的用戶,預(yù)測值為5加上5,等于10.
1.3 訓(xùn)練方法
梯度提升樹算法是有監(jiān)督機器學(xué)習(xí)算法,其目標(biāo)是最小化一個目標(biāo)函數(shù),對于梯度提升樹來說,在建立第t棵樹時,需要最小化以下的代價函數(shù):
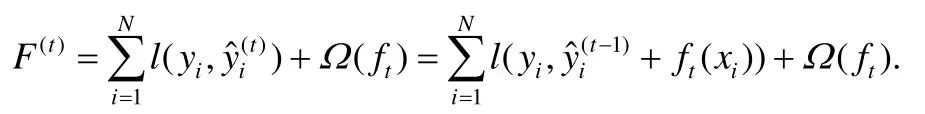
這里,l對于真實值和預(yù)測值給出損失,例如,logistic損失,square損失.Ω是正則項,可以避免過擬合.依照XGBoost的選擇[8],選擇如下的正則項:
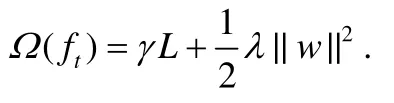
L是樹中葉子節(jié)點的數(shù)量,w是葉子節(jié)點的預(yù)測值組成的向量,γ和λ是超參數(shù).LogitBoost算法用二階近似來擴展F(t):
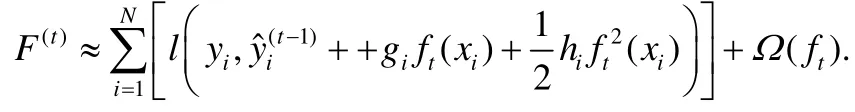
這里,gi和hi是數(shù)據(jù)的一階和二階梯度:.用Ij={i|xi∈leafj}代表屬于第j個葉子節(jié)點的數(shù)據(jù)樣本的集合,去掉常數(shù)項之后,可以得到F(t)的近似表達(dá):
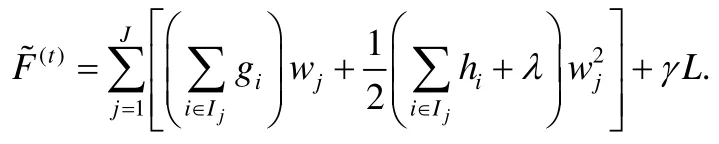
根據(jù)以上的公式,第j個葉子節(jié)點的最佳預(yù)測值和最佳目標(biāo)函數(shù)是:
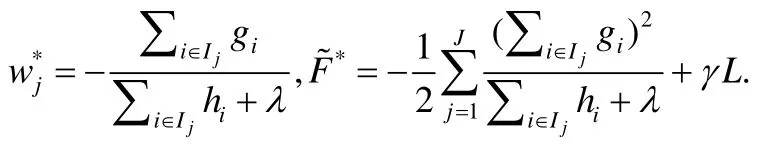
以上的結(jié)果假設(shè)已經(jīng)知道樹的結(jié)構(gòu)和數(shù)據(jù)樣本的分布,可以遍歷所有可能的樹結(jié)構(gòu)和數(shù)據(jù)樣本分布來找到最佳的解.但是這種方法的計算復(fù)雜度太高,在實際中不可行.因此,現(xiàn)有的方法采用一種貪心的方法,從根節(jié)點開始逐層地分裂樹節(jié)點,見算法1.
算法1.訓(xùn)練梯度提升樹的貪心分裂算法.
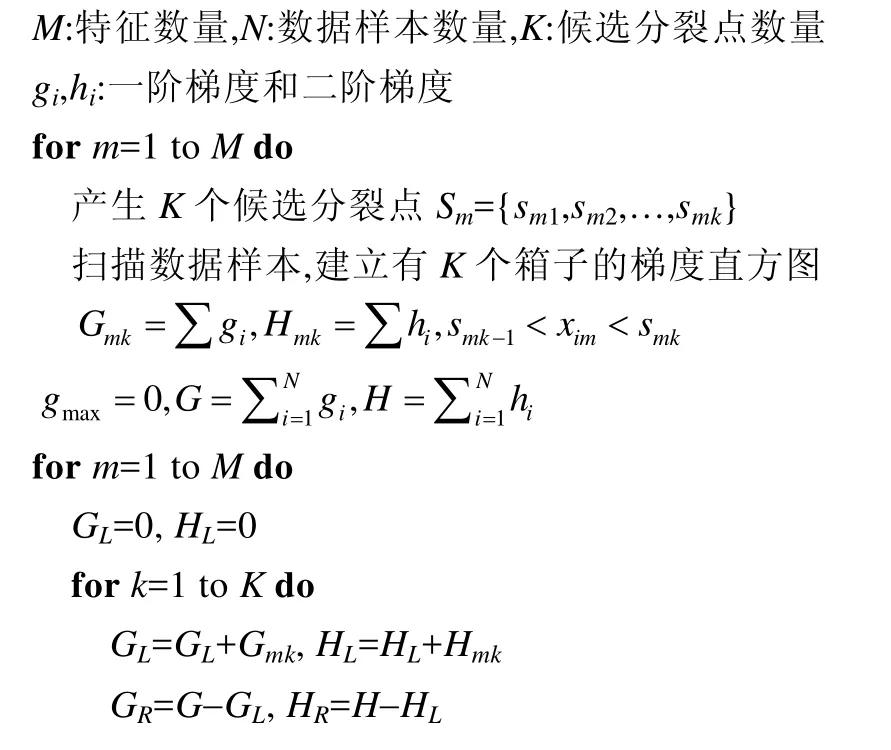

輸出增益最大的分裂結(jié)果
在計算一個樹節(jié)點的最佳分裂點時,首先對每個特征計算出K個候選分裂點,然后掃描一遍所有數(shù)據(jù)樣本,用梯度數(shù)據(jù)建立梯度直方圖.例如:Gmk對應(yīng)第m個特征,累加所有對應(yīng)特征值處在第k-1和第k個候選分裂點之間的數(shù)據(jù)樣本的一階梯度;Hmk以同樣的方式累加二階梯度.建立完所有特征的梯度直方圖之后,根據(jù)下面公式找到代價函數(shù)增益最大的分裂結(jié)果:
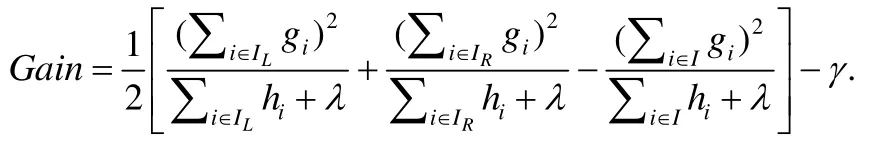
這里,IL和IR代表分裂之后的左子節(jié)點和右子節(jié)點.選擇候選分裂點有多種方式,精確的方法依據(jù)每個特征對所有數(shù)據(jù)樣本進(jìn)行排序,然后選擇所有可能的分裂點.但這種方法需要反復(fù)地排序,在數(shù)據(jù)量很大時,計算開銷和時間開銷過于昂貴.另外一種叫分位數(shù)據(jù)草圖的方法使用基于概率的近似數(shù)據(jù)結(jié)構(gòu),對每個特征產(chǎn)生對應(yīng)特征值的近似分布[11].經(jīng)典的分位數(shù)據(jù)草圖的算法是GK[12],基于GK的變種有DataSketches[13]和WQS[8]等.
梯度提升樹算法中,兩種避免過擬合的方法是衰減和特征下采樣:衰減方法在累加樹的預(yù)測值時乘以一個叫做學(xué)習(xí)速度的超參數(shù)η;特征下采樣方法對每棵樹采樣一個特征子集,這種方法被證明能夠加快訓(xùn)練速度和提高模型的泛化能力.
1.4 分布式訓(xùn)練
目前已經(jīng)有一些研究工作提出了分布式梯度提升樹算法,例如 XGBoost[8],LightGBM[10],TencentBoost[14],DimBoost[18]等.XGBoost由華盛頓大學(xué)的研究者提出,采用數(shù)據(jù)并行的訓(xùn)練模式,在單個計算節(jié)點上將數(shù)據(jù)集按列切分,以列存塊的形式存儲數(shù)據(jù)樣本,為每個特征值增加一個指針指向其屬于的數(shù)據(jù)樣本,這樣帶來了很大的額外內(nèi)存開銷.XGBoost提出了一系列的優(yōu)化方法,包括一種對數(shù)據(jù)加權(quán)的分位數(shù)據(jù)草圖算法、一種稀疏感知的尋找分裂點算法、一種將列存塊存儲到磁盤的塊壓縮和塊切分的算法.LightGBM由微軟亞洲研究院的研究者提出,默認(rèn)采用數(shù)據(jù)并行的訓(xùn)練模式,提出了深度優(yōu)先的策略.實驗證明,這能夠提高準(zhǔn)確率.除了數(shù)據(jù)并行之外,LightGBM 也實現(xiàn)了特征并行.但是這個簡單的實現(xiàn)不支持?jǐn)?shù)據(jù)集按列切分,需要在每個計算節(jié)點上存儲完整的數(shù)據(jù)集,這在超大規(guī)模數(shù)據(jù)和真實的工業(yè)界環(huán)境中是不可行的.TencentBoost和DimBoost由北京大學(xué)和騰訊聯(lián)合設(shè)計,采用數(shù)據(jù)并行的訓(xùn)練模式,利用參數(shù)服務(wù)器[16-18]架構(gòu)分布式存儲算法模型,以支持高維度的數(shù)據(jù)集,在建立梯度直方圖階段提出了稀疏感知的算法,只需要讀取數(shù)據(jù)樣本中的非零特征;同時,用高效的并行機制加速梯度直方圖的建立,在尋找最佳分裂點階段提出了量化壓縮算法減少梯度數(shù)據(jù)的傳輸.針對參數(shù)服務(wù)器的特殊架構(gòu)提出了兩階段的方法,在參數(shù)服務(wù)器端計算局部最佳分裂點,在計算節(jié)點端匯總得到全局最佳分裂點.可以看到,目前的分布式梯度提升樹算法的系統(tǒng)基本都采用數(shù)據(jù)并行的訓(xùn)練方式,或者實現(xiàn)的特征并行方式在實際中不可行,不能有效地處理本文針對的高維特征和多分類問題.
2 并行策略比較
將一個串行的機器學(xué)習(xí)算法并行化,首先需要設(shè)計如何將數(shù)據(jù)樣本在多個計算節(jié)點之間分配.常用的并行策略包括數(shù)據(jù)并行和特征并行.假設(shè)訓(xùn)練數(shù)據(jù)集是一個矩陣,每一行是一個數(shù)據(jù)樣本,數(shù)據(jù)并行按行切分?jǐn)?shù)據(jù)集,這樣,每個計算節(jié)點負(fù)責(zé)一個數(shù)據(jù)子集.與此相對應(yīng)的,特征并行按列切分?jǐn)?shù)據(jù)集,每個計算節(jié)點負(fù)責(zé)一個特征子集.
本節(jié)將針對內(nèi)存開銷和網(wǎng)絡(luò)開銷兩個方面,從理論上比較運用兩種并行策略的分布式梯度提升樹算法,并針對本文研究的高維和多分類問題選擇合適的并行策略.為了形式化地描述結(jié)果,本文中用到的符號定義見表1,其中,訓(xùn)練數(shù)據(jù)集是一個N×D的矩陣,N是數(shù)據(jù)樣本的數(shù)量,D是數(shù)據(jù)樣本的特征數(shù)量;集群中有W個計算節(jié)點,梯度提升樹模型包含T棵樹,每棵樹有L層,每個特征的候選分裂點的個數(shù)是q;對于多分類問題,用C來表示類別數(shù)量.

Table 1 Definition of symbols表1 符號定義
2.1 梯度直方圖大小
梯度提升樹算法的核心操作是建立梯度直方圖和尋找分裂點.梯度直方圖的大小與3個因素有關(guān).
1) 特征維度D.由于需要為每種特征建立兩個梯度直方圖(一階梯度直方圖和二階梯度直方圖),因而梯度直方圖的總數(shù)量與2D成比例;
2) 候選分裂點的數(shù)量q.一個梯度直方圖中箱子的數(shù)量等于候選分裂點的個數(shù);
3) 類別數(shù)量C.在多分類問題中,每個梯度數(shù)據(jù)是一個向量,表示在所有類別上的偏微分,因此,梯度直方圖的大小與C成比例.二分類是一個特例,二分類時C=1.
綜上,一個樹節(jié)點的梯度直方圖大小為Sh=8×2×D×q字節(jié),其中,8字節(jié)表示一個雙精度浮點數(shù)的大小.
2.2 內(nèi)存開銷
梯度提升樹訓(xùn)練中的一個技巧是,只要樹節(jié)點之間不存在數(shù)據(jù)重疊,就可以同時處理多個樹節(jié)點,代價是存儲更多的梯度直方圖.對于目前普遍采用的逐層訓(xùn)練的方式,樹的同一層的樹節(jié)點之間不存在數(shù)據(jù)重疊,因而可以同時被處理,樹的深度最大為L,因此,同時處理的樹節(jié)點的最大數(shù)量是2L-1.
使用數(shù)據(jù)并行策略時,每個計算節(jié)點需要建立所有待處理樹節(jié)點上每個特征的直方圖,因此,每個計算節(jié)點上梯度直方圖的內(nèi)存開銷最多是Sh×2L-1.但是用特征并行時,每個計算節(jié)點只需要負(fù)責(zé)計算一部分特征的梯度直方圖,因此內(nèi)存開銷是Sh×2L-1/W,與數(shù)據(jù)并行相比要低得多.
2.3 通信開銷
當(dāng)使用數(shù)據(jù)并行時,主要的通信開銷是梯度直方圖的匯總.盡管目前存在多種在分布式環(huán)境下聚合數(shù)據(jù)的分布式架構(gòu),例如 MapReduce[7],AllReduce[8],ReduceScatter[10],Parameter Server[14-17]等,但是每個計算節(jié)點至少需要通過網(wǎng)絡(luò)傳輸本地存儲的梯度直方圖,因此,一棵樹需要傳輸?shù)奶荻戎狈綀D的大小至少是Sh×W×(2L-1).
當(dāng)使用特征并行時,由于每個計算節(jié)點上存儲著一個特征的全部特征值,因此,梯度提升樹算法不需要在計算節(jié)點之間匯總梯度直方圖.但由于按列切分?jǐn)?shù)據(jù)集,在尋找最佳分裂點時,每個計算節(jié)點從本地存儲的梯度直方圖中計算出一個局部最佳分裂點,然后從所有計算節(jié)點中選擇出一個全局最佳分裂點,這樣的代價是只有一個計算節(jié)點知道數(shù)據(jù)樣本的分裂結(jié)果,也就是數(shù)據(jù)樣本被分到左子節(jié)點還是右子節(jié)點.這樣,在完成樹節(jié)點分裂之后,此計算節(jié)點需要向其他計算節(jié)點廣播數(shù)據(jù)樣本的位置(左子節(jié)點或者右子節(jié)點),帶來了一定的通信開銷.這部分的通信開銷與數(shù)據(jù)樣本的數(shù)量成正比,因此當(dāng)樹的深度增大時,通信量保持不變.綜上,一棵樹的總通信開銷是4×N×W×L字節(jié),其中,4字節(jié)表示32位整型數(shù)的大小.這樣簡單地實現(xiàn)存在的問題是,直接用整型來發(fā)送數(shù)據(jù)樣本的位置開銷較大.為了解決這個問題,本文提出將數(shù)據(jù)樣本的位置編碼為比特圖,每個比特代表一個數(shù)據(jù)樣本的位置,0代表左子節(jié)點,1代表右子節(jié)點.這種方法能夠顯著降低通信開銷,對于一個L層的樹,總的通信開銷是字節(jié).
2.4 分析結(jié)果總結(jié)
根據(jù)之前的分析結(jié)果,使用數(shù)據(jù)并行策略最多需要Sh×2L-1的內(nèi)存開銷和Sh×W×(2L-1)的通信開銷,特征并行需要Sh×2L-1/W的內(nèi)存開銷和的通信開銷.
下面以公開數(shù)據(jù)集 RCV1-multi為例,定量地比較兩種策略的內(nèi)存開銷和通信開銷.RCV1-multi數(shù)據(jù)集有53.4萬個樣本、4.7萬個特征和53個類別,使用8個計算節(jié)點建立深度為7的樹,候選分裂點的個數(shù)設(shè)置為100,每棵樹上梯度直方圖的大小是 3.7GB.當(dāng)使用數(shù)據(jù)并行時,建立一棵樹的內(nèi)存開銷最大是 118.4GB,通信開銷最差情況下總共是 1.8TB;當(dāng)使用特征并行時,建立一棵樹的內(nèi)存開銷是 14.8GB,通信開銷是 3.8MB.由此可見,對于高維和多分類問題,特征并行與數(shù)據(jù)并行相比,在通信開銷和內(nèi)存開銷上明顯更為高效.
3 算法介紹
本節(jié)首先從整體上介紹本文提出的算法FP-GBDT,然后分別詳細(xì)介紹FP-GBDT的關(guān)鍵技術(shù).
3.1 整體介紹
圖2是FP-GBDT整體工作流程,主要包括以下幾個關(guān)鍵步驟.
(1) 訓(xùn)練數(shù)據(jù)集存儲在分布式文件系統(tǒng)上,例如 HDFS,GFS,Ceph等,默認(rèn)的存儲方式是按行切分.FPGBDT從分布式文件系統(tǒng)上加載訓(xùn)練數(shù)據(jù)集到計算節(jié)點,讀入內(nèi)存中;
(2) FP-GBDT對訓(xùn)練數(shù)據(jù)集執(zhí)行數(shù)據(jù)集轉(zhuǎn)置操作,將原本按行切分的數(shù)據(jù)集轉(zhuǎn)換為按列切分的方式,以特征行的方式存儲在計算節(jié)點上;
(3) 每個計算節(jié)點獨立地建立梯度直方圖.為了有效地處理普遍存在的高維稀疏數(shù)據(jù),本文提出了一種稀疏感知的方法來加速梯度直方圖的建立;
(4) 建立完梯度直方圖之后,每個計算節(jié)點從本地的梯度直方圖中找出一個局部最佳分裂點,然后通過一個主節(jié)點從所有候選中找到全局最佳分裂點;
(5) 產(chǎn)生全局最佳分裂點的計算節(jié)點執(zhí)行分裂樹節(jié)點的操作,并產(chǎn)生數(shù)據(jù)樣本在樹中的位置;然后,使用一種比特圖的壓縮方法發(fā)送數(shù)據(jù)樣本的位置給其他計算節(jié)點.
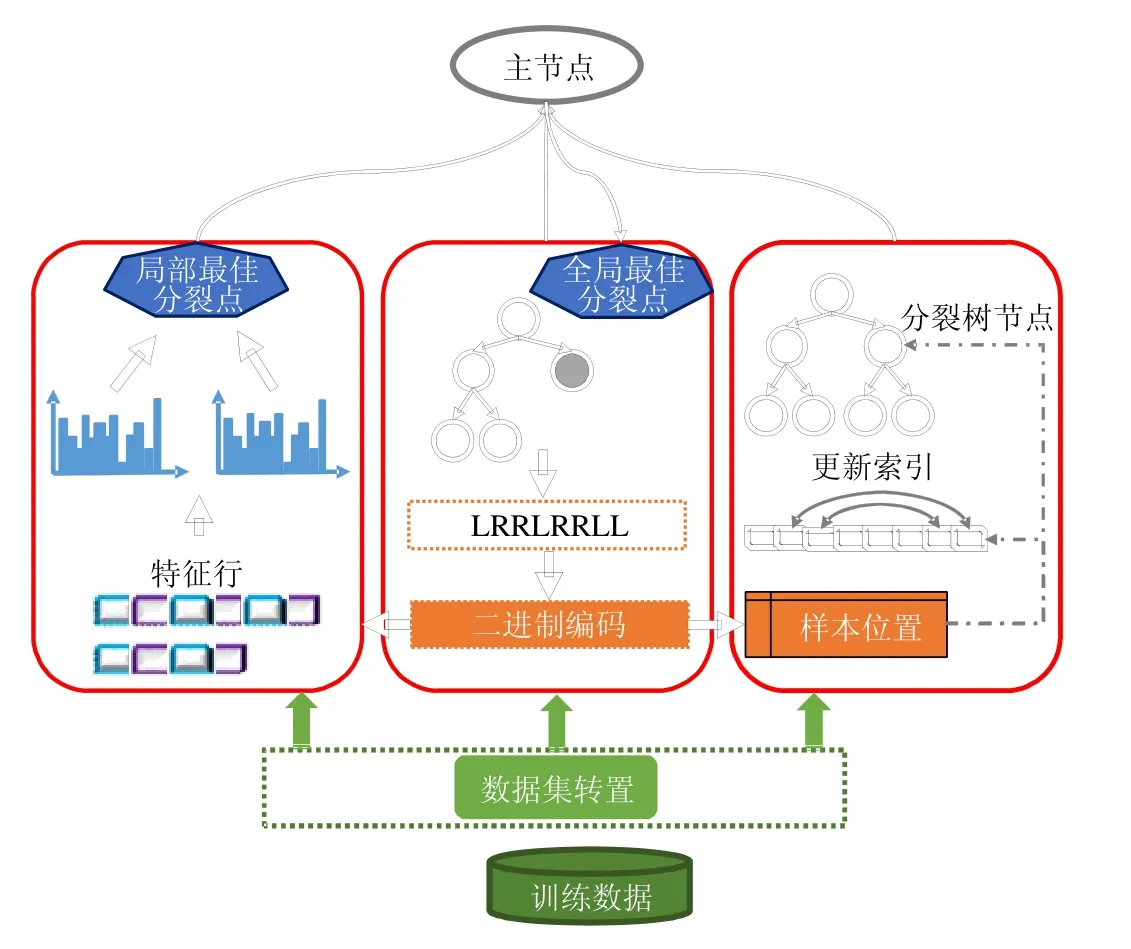
Fig.2 Framework of FP-GBDT圖2 FP-GBDT的架構(gòu)
3.2 數(shù)據(jù)集轉(zhuǎn)置
原始的訓(xùn)練數(shù)據(jù)集由多行組成,每行包含了一個數(shù)據(jù)樣本的特征和標(biāo)簽.目前的數(shù)據(jù)集常常是稀疏格式,因此經(jīng)常將數(shù)據(jù)樣本的特征存儲為鍵值對的形式,其中,鍵是特征索引、值是特征值.數(shù)據(jù)集常常按行切分并存儲在分布式文件系統(tǒng)上,例如HDFS等,這種存儲格式天然不適合特征并行,因為特征并行需要在單個計算節(jié)點上匯總一個特征的所有特征值.為了解決這個問題,需要在梯度提升樹算法執(zhí)行之前對訓(xùn)練數(shù)據(jù)集進(jìn)行轉(zhuǎn)置操作,將按行存儲的數(shù)據(jù)集轉(zhuǎn)換為按列存儲的方式.本文設(shè)計了一種高效的分布式數(shù)據(jù)集轉(zhuǎn)置算法,如圖3所示.

Fig.3 Distributed dataset transposition圖3 分布式數(shù)據(jù)集轉(zhuǎn)置
本方法的計算流程包括4個步驟.
(1) 計算數(shù)據(jù)樣本的偏移.為了唯一標(biāo)識每個數(shù)據(jù)樣本,每個計算節(jié)點將本地數(shù)據(jù)樣本的數(shù)量發(fā)送給主節(jié)點,然后,主節(jié)點從全局上統(tǒng)計數(shù)據(jù)樣本的數(shù)量,給每個計算節(jié)點發(fā)送一個全局偏移值,限定了每個計算節(jié)點上數(shù)據(jù)樣本標(biāo)識范圍.這樣,每個數(shù)據(jù)樣本的標(biāo)識就等于計算節(jié)點的全局偏移加上本地偏移;
(2) 轉(zhuǎn)置數(shù)據(jù)集.每個計算節(jié)點對本地的數(shù)據(jù)樣本進(jìn)行轉(zhuǎn)置操作.原始的數(shù)據(jù)集由樣本行組成,每個樣本行存儲著(特征索引,特征值)的鍵值對.本節(jié)的數(shù)據(jù)集轉(zhuǎn)置方法將這種數(shù)據(jù)表示方式轉(zhuǎn)換為特征行,每個特征行存儲著一個特征出現(xiàn)的所有位置,也就是(樣本索引,特征值)的鍵值對,表示此特征在每個數(shù)據(jù)樣本中的非零值,這里的樣本索引根據(jù)上一步產(chǎn)生的樣本偏移計算而出;
(3) 重切分特征行.由于一個特征的特征值可能存在多個計算節(jié)點上,因而每個特征在多個計算節(jié)點上存在局部特征行.本方法通過MapReduce操作重切分所有計算節(jié)點上的局部特征行,使得每個特征的所有局部特征行在一個計算節(jié)點行進(jìn)行匯總,形成此特征完整的特征行.通過這個操作,每個計算節(jié)點負(fù)責(zé)一個特征子集,存儲著這個特征子集中所有特征的特征行,由(樣本索引,特征值)的鍵值對組成;
(4) 廣播樣本標(biāo)簽.主節(jié)點從所有計算節(jié)點收集數(shù)據(jù)樣本的標(biāo)簽,然后廣播給計算節(jié)點.這些標(biāo)簽被每個計算節(jié)點用來計算數(shù)據(jù)樣本的梯度.
3.3 建立梯度直方圖
在數(shù)據(jù)集轉(zhuǎn)置之后,每個計算節(jié)點使用特征行來建立梯度直方圖.首先掃描特征行,為每個特征建立分位數(shù)據(jù)草圖,然后使用數(shù)據(jù)草圖產(chǎn)生候選分裂點,具體而言,使用一組 0~1之間的分位值,例如{0,0.1,0.2,…,1.0},從分位數(shù)據(jù)草圖中查詢出每個特征的候選分裂值.
特征并行策略下,一個計算節(jié)點包含了某個特征所有出現(xiàn)的特征值,而數(shù)據(jù)并行策略下,一個計算節(jié)點只包含了某個特征的部分特征值.因此在特征并行策略下,一個樹節(jié)點建立梯度直方圖的操作比數(shù)據(jù)并行策略的計算量更大.由此可見:針對特征并行的特點,設(shè)計高效的機制來加速梯度直方圖的建立是非常有意義的.
· 稀疏感知的建立梯度直方圖方法.
建立梯度直方圖需要直接處理數(shù)據(jù)樣本,要達(dá)到優(yōu)化的目標(biāo),應(yīng)該考慮數(shù)據(jù)樣本的特點.在實際應(yīng)用中,很多真實的數(shù)據(jù)集常常是稀疏的,一個數(shù)據(jù)樣本中只有一部分非常少的特征有非零值.傳統(tǒng)的建立梯度直方圖的方法需要數(shù)據(jù)樣本的所有特征值,包括值為零和值非零的特征,因此計算復(fù)雜度是O(N×D),這里,N是數(shù)據(jù)樣本的數(shù)量,D是特征數(shù)量.對于數(shù)據(jù)量大、特征維度高的情況,這樣的計算復(fù)雜度過高.考慮到稀疏的數(shù)據(jù)特點和存在的問題,一個直觀的想法是,能否利用數(shù)據(jù)稀疏性來加速梯度直方圖的建立.基于這樣的思路,本文提出一種稀疏感知的建立梯度直方圖的技術(shù),如圖4所示,主要技術(shù)細(xì)節(jié)如下所述.
(1) 在讀取數(shù)據(jù)樣本之前,假設(shè)數(shù)據(jù)樣本的所有特征值都為 0.一般情況下會認(rèn)為特征值為非零是正常情況,特征值為0是異常情況,但真實情況是,數(shù)據(jù)樣本中大部分特征值為0,從概率的角度來看,特征值為0是大多數(shù)情況,而特征值為非零是極少數(shù)情況.基于這樣的觀察,本方法在讀取數(shù)據(jù)樣本之前,假設(shè)它們所有的特征值都為0;
(2) 累加數(shù)據(jù)樣本的梯度.經(jīng)過數(shù)據(jù)集轉(zhuǎn)置之后,每個計算節(jié)點上保存著所有數(shù)據(jù)樣本的標(biāo)簽,使用數(shù)據(jù)樣本的標(biāo)簽和預(yù)測值,計算數(shù)據(jù)樣本的梯度,接著累加所有的梯度;
(3) 將梯度和增加到零桶中.一個特征的梯度直方圖中,每個桶包含特征值的一個區(qū)間,這里將零桶定義為包含特征值為零的桶.本方法的第 1步中假設(shè)所有特征值都為零,這樣應(yīng)該將每個數(shù)據(jù)樣本的梯度放入零桶中,因此,本方法將第2步求得的梯度和加到每個特征的梯度直方圖的零桶中;
(4) 重定位非零特征值.依次讀取特征行存儲的非零特征值,根據(jù)特征值的大小找到對應(yīng)的梯度直方圖的桶,然后將此特征值對應(yīng)的數(shù)據(jù)樣本的梯度加到此梯度直方圖桶中;同時,為了保證梯度直方圖的正確性,從零桶中減去此數(shù)據(jù)樣本的梯度.
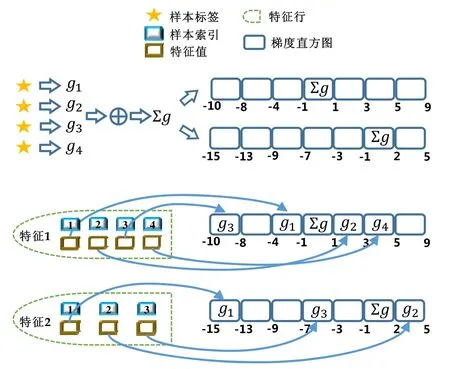
Fig.4 Sparsity-aware histogram construction圖4 稀疏感知的建立梯度直方圖方法
· 計算復(fù)雜度分析.
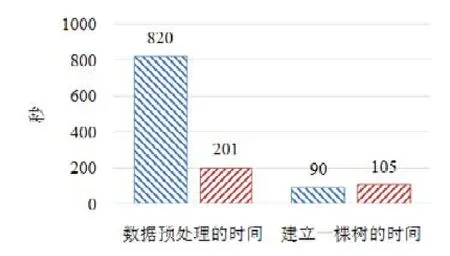
使用本文提出的稀疏感知建立梯度直方圖的方法,首先需要掃描一遍數(shù)據(jù)樣本計算梯度和,然后將梯度和加到每個特征的梯度直方圖的零桶中,最后掃描一遍非零特征值.這樣的計算復(fù)雜度是.這里,N是數(shù)據(jù)樣本的數(shù)量,D是特征的數(shù)量,W是集群計算節(jié)點的數(shù)量,d代表一個數(shù)據(jù)樣本中非零特征值的平均數(shù)量.與傳統(tǒng)方法的計算復(fù)雜度O(N×D)相比,由于d< 找到一個樹節(jié)點的最佳分裂點后,下一步是分裂樹節(jié)點.使用特征并行策略時,某個計算節(jié)點產(chǎn)生了全局最佳分裂點,樹節(jié)點的分裂結(jié)果(數(shù)據(jù)樣本的位置)也只有此計算節(jié)點知道,因而,此計算節(jié)點需要將數(shù)據(jù)樣本的位置廣播給其他計算節(jié)點.為了減少通信開銷,本文設(shè)計了一種比特圖的方法來壓縮數(shù)據(jù)樣本的位置,如圖5所示. Fig.5 Bitmap compression圖5 比特圖壓縮方法 · 比特圖壓縮. 如果使用整型的表達(dá)方式,廣播數(shù)據(jù)樣本位置的通信開銷是4×N×W字節(jié).一個數(shù)據(jù)樣本的位置是左子節(jié)點或者右子節(jié)點,因此,本方法使用一個比特圖來二進(jìn)制編碼樣本位置,左子節(jié)點編碼為 0,右子節(jié)點編碼為 1.使用這種方法,通信開銷降低為N×W/8字節(jié),帶來了32倍的提升.當(dāng)其他計算節(jié)點接收到比特圖后,逐個比特地讀取,然后更新數(shù)據(jù)樣本在樹中的位置. 除了能夠節(jié)省通信開銷,特征并行相比數(shù)據(jù)并行還有另外一個優(yōu)勢:當(dāng)樹的層數(shù)加深時,同層樹節(jié)點的數(shù)量指數(shù)增長,數(shù)據(jù)并行策略下通信開銷也會指數(shù)級增長;而使用特征并行策略時,樹的一層的通信開銷與樹節(jié)點的數(shù)量無關(guān),樹深度的增加不會造成通信開銷的增加. 本節(jié)通過詳盡的實驗來驗證FP-GBDT算法的有效性. · 原型實現(xiàn). FP-GBDT在Spark[19]的基礎(chǔ)上實現(xiàn),數(shù)據(jù)存儲在HDFS上,機器學(xué)習(xí)任務(wù)提交到一個8節(jié)點的Yarn[20]集群上.每個機器配置了4個E3-1220 v3 CPU,32GB內(nèi)存和1Gb網(wǎng)絡(luò). · 數(shù)據(jù)集. 本文的實驗使用了3個數(shù)據(jù)集,見表2.RCV1[21]和 RCV1-multi[22]是兩個公開的文本分類數(shù)據(jù)集[23],樣本數(shù)量分別為69.7萬和53.4萬,特征數(shù)量均為4.7萬,RCV1有2種類別,RCV1-multi有53種類別.Synthesis是一個人造數(shù)據(jù)集,包含1千萬個樣本和10萬個特征.Synthesis是一個二分類數(shù)據(jù)集,用來評估本文提出的優(yōu)化方法的效果和特征維度的影響,RCV1和RCV1-multi的特征相同而類別數(shù)量不同,被用來評估類別數(shù)量的影響. · 基準(zhǔn)方法. 如前所述,目前有多種分布式梯度提升樹算法的實現(xiàn),例如Mllib,XGBoost和LightGBM等.本文基于兩個原因選擇 XGBoost作為數(shù)據(jù)并行策略的代表:第一,XGBoost是目前使用最廣泛的分布式梯度提升樹系統(tǒng);第二,XGBoost有基于Spark實現(xiàn)的版本,因而實驗對比是公平的. · 超參數(shù). 除非另外聲明,對RCV1和RCV1-multi數(shù)據(jù)集選擇L=7,對Synthesis數(shù)據(jù)集選擇L=8,計算節(jié)點數(shù)量W=10.對于其他超參數(shù),候選分裂點數(shù)量q=100,學(xué)習(xí)速度η=0.1,特征采樣率設(shè)為1.0,樹的數(shù)量設(shè)為100. Table 2 Datasets表2 數(shù)據(jù)集 本節(jié)的實驗用來評估本文提出的優(yōu)化方法,驗證它們的有效性,這些優(yōu)化方法包括數(shù)據(jù)集轉(zhuǎn)置、稀疏感知建立梯度直方圖和比特圖壓縮. · 數(shù)據(jù)集轉(zhuǎn)置. 首先展示分布式數(shù)據(jù)集轉(zhuǎn)置方法的性能,實驗數(shù)據(jù)如圖6所示,從HDFS上加載3個數(shù)據(jù)集的時間分別是17s、12s和 106s.使用簡單的直接數(shù)據(jù)集轉(zhuǎn)置,在 RCV1,RCV1-multi和 Synthesis數(shù)據(jù)集上需要的時間分別是20s、13s和168s;而FP-GBDT執(zhí)行數(shù)據(jù)集轉(zhuǎn)置的操作,在3個數(shù)據(jù)集上的耗時分別是9s、6s和95s,相比原始的數(shù)據(jù)集轉(zhuǎn)置方法,速度得到了最高 2倍的提升.雖然相比于數(shù)據(jù)并行的策略,FP-GBDT帶來了額外的時間開銷,但是在后面的實驗中將顯示,FP-GBDT顯著提升了整體的性能. · 稀疏感知建立梯度直方圖. 當(dāng)使用稀疏感知的方法時,對Synthesis數(shù)據(jù)集,建立樹的根節(jié)點的梯度直方圖的時間是9s.但是當(dāng)不使用這種方法時,在1h之內(nèi)無法完成建立根節(jié)點的梯度直方圖,原因是需要讀取一個數(shù)據(jù)樣本的所有特征. · 比特圖壓縮. 找到最佳分裂點后,處理分裂樹節(jié)點的任務(wù)時,FP-GBDT廣播數(shù)據(jù)樣本的位置時使用比特圖的壓縮方法.本實驗在 Synthesis數(shù)據(jù)集上訓(xùn)練梯度提升樹算法,建立一棵樹的總時間開銷中分裂樹節(jié)點需要 18s;當(dāng)使用了比特圖壓縮方法后,此部分時間開銷降低為8s,帶來了2倍的速度提升. Fig.6 Effects of dataset transposition圖6 數(shù)據(jù)集轉(zhuǎn)置的效果 4.3.1 FP-GBDT與XGBoost的性能對比 本節(jié)的實驗比較FP-GBDT與XGBoost,FP-GBDT使用特征并行策略,XGBoost使用數(shù)據(jù)并行策略,下面分別評估特征數(shù)量、類別數(shù)量等因素對結(jié)果的影響. · 特征數(shù)量的影響. 本文提出的FP-GBDT適合高維特征的數(shù)據(jù)集,為了評估特征數(shù)量對于實驗結(jié)果的影響,本文使用Synthesis數(shù)據(jù)集的一部分特征子集,例如Synthesis-25K代表使用Synthesis數(shù)據(jù)集前2.5萬個特征,Synthesis-100K代表Synthesis數(shù)據(jù)集的全部特征.分別用FP-GBDT與XGBoost在Synthesis的多個數(shù)據(jù)子集上訓(xùn)練梯度提升樹算法,FP-GBDT與XGBoost對比的實驗結(jié)果如圖7所示.當(dāng)特征數(shù)量從2.5萬增加到5萬和10萬時,XGBoost建立一棵樹的時間從80s增加到了144s和301s,性能分別下降了1.8倍和3.7倍.原因是特征數(shù)量增大1倍時,梯度直方圖的大小也增加 1倍,XGBoost使用數(shù)據(jù)并行,通信開銷線性增大,從而造成性能幾乎線性下降;FPGBDT的性能下降較小,分別慢了1.4倍和2.2倍,FP-GBDT使用特征并行,通信開銷與特征數(shù)量無關(guān),樹的每一層的開銷一樣,因而只會受到計算開銷增大的影響.總的來說,特征數(shù)量增大時FP-GBDT比XGBoost更加高效. · 類別數(shù)量的影響. 如前文所分析,對于多分類問題,類別數(shù)量對梯度直方圖的大小有直接的影響.為了更好地顯示結(jié)果,本實驗選擇了兩分類的RCV1數(shù)據(jù)集和53分類的RCV1-multi數(shù)據(jù)集,同時又將RCV1-multi的53類合并為5類.用8個計算節(jié)點對這3個數(shù)據(jù)集訓(xùn)練梯度提升樹模型,圖8顯示了實驗結(jié)果,統(tǒng)計了建立一棵樹的平均時間.在2分類上的RCV1數(shù)據(jù)集上,XGBoost平均需要53s訓(xùn)練一棵樹,而FP-GBDT只需要26s,訓(xùn)練速度快了2倍,所以FP-GBDT的收斂速度比 XGBoost快得多.在 5分類的RCV1-multi數(shù)據(jù)集上,XGBoost需要251s訓(xùn)練一棵樹,FP-GBDT只需要41s,快了6.1倍.類別增加到5類時,梯度直方圖的大小增大了5倍,XGBoost的性能下降了接近5倍,而FP-GBDT只慢了1.5倍,這說明FP-GBDT更適合多分類問題.當(dāng)使用53類的RCV1-multi數(shù)據(jù)集時,FP-GBDT訓(xùn)練一棵樹需要 161s,而 XGBoost出現(xiàn)了內(nèi)存溢出(out of memory,簡稱 OOM)的錯誤,這證明了XGBoost使用的數(shù)據(jù)并行策略的內(nèi)存開銷較大.總的來說,FP-GBDT比XGBoost更適合多分類任務(wù),特別是類別數(shù)量較大的情況. Fig.7 Impact of feature dimensionality圖7 特征數(shù)量的影響 Fig.8 Impact of class number圖8 類別數(shù)量的影響 · 樹深度的影響. 接下來的實驗將評估樹的深度對性能的影響.一般來說,樹的深度越大,訓(xùn)練時間越長,模型準(zhǔn)確率更高.本實驗在RCV1數(shù)據(jù)集上訓(xùn)練梯度提升樹算法,逐步地增加樹的深度,實驗結(jié)果顯示在圖9和圖10中. 深度增大時,XGBoost和 FP-GBDT的誤差均下降,證明更深的樹可以提高模型的準(zhǔn)確率,代價是訓(xùn)練時間的增大.當(dāng)樹的深度從8增大到9時,數(shù)據(jù)并行策略下梯度直方圖的大小增大1倍,因此,XGBoost的運行速度慢了2倍;繼續(xù)將樹的深度增大到10時,XGBoost出現(xiàn)了內(nèi)存溢出的錯誤. 與此相對應(yīng),FP-GBDT使用特征并行,能夠高效地處理更深的樹,樹的深度增大時,每一層的通信開銷保持不變,因此性能下降較為平穩(wěn),在可接受范圍之內(nèi);同時,FP-GBDT的內(nèi)存開銷較小,樹的深度增加時沒有出現(xiàn)資源不足的情況. Fig.9 Impact of tree depth (time to build one tree)圖9 樹深度的影響(建立一棵樹的平均時間) Fig.10 Impact of tree depth (error after the first tree)圖10 樹深度的影響(第1棵樹后的誤差) 4.3.2 FP-GBDT與LightGBM的性能對比 如第1.4節(jié)所述,LightGBM也實現(xiàn)了一個特征并行的梯度提升樹算法,但是LightGBM的實現(xiàn)需要每個計算節(jié)點上已經(jīng)存有完整的數(shù)據(jù)集,訓(xùn)練時,LightGBM 將整個數(shù)據(jù)集加載進(jìn)內(nèi)存,這樣,LightGBM 不需要進(jìn)行數(shù)據(jù)集轉(zhuǎn)置的處理,也不需要在節(jié)點之間廣播分裂后數(shù)據(jù)樣本的位置.嚴(yán)格意義上,這不是一種真正的特征并行方式,在真實的應(yīng)用中,單機的內(nèi)存常常無法存儲完整的數(shù)據(jù)集;在真實的環(huán)境中,數(shù)據(jù)集常常以存儲在分布式文件系統(tǒng)上,LightGBM在這種情況下無法工作.因此,LightGBM的特征并行實現(xiàn)無法用在實際中. 但是為了給出更加全面的結(jié)果,本節(jié)使用Synthesis數(shù)據(jù)集比較了FP-GBDT和LightGBM的性能,實驗設(shè)置與之前的實驗保持一致.由于LightGBM無法從分布式文件系統(tǒng)讀取數(shù)據(jù),首先使用hadoop fs命令從HDFS上下載到每一個計算節(jié)點上,在所有計算節(jié)點下載完成之后,在每個計算節(jié)點上啟動 LightGBM,從 HDFS下載數(shù)據(jù)集加上本地讀取數(shù)據(jù)的總時間是LightGBM的數(shù)據(jù)預(yù)處理的時間. 圖11給出了實驗結(jié)果,FP-GBDT的數(shù)據(jù)預(yù)處理(包括加載數(shù)據(jù)集和數(shù)據(jù)集轉(zhuǎn)置)時間是201s,而LightGBM需要 820s來對數(shù)據(jù)進(jìn)行預(yù)處理,比 FP-GBDT慢了 4倍多;在訓(xùn)練階段,FP-GBDT建立一棵樹的平均時間是105s,LightGBM需要90s;在內(nèi)存開銷方面,LightGBM由于需要在每個節(jié)點上存儲完整的數(shù)據(jù)集,因此每臺機器上消耗了30GB的內(nèi)存,是FP-GBDT的內(nèi)存開銷的6倍.總體來看,LightGBM單棵樹的速度略快.這主要是因為每個計算節(jié)點加載完整的數(shù)據(jù)集,從而避免了通過網(wǎng)絡(luò)傳輸數(shù)據(jù)樣本的分裂位置;很多工業(yè)界的數(shù)據(jù)集大小常常達(dá)到 TB級別,單個計算節(jié)點的內(nèi)存顯然無法存儲這樣大的數(shù)據(jù)集;對于存儲在分布式文件系統(tǒng)上的數(shù)據(jù)集,LightGBM 首先需要將數(shù)據(jù)集下載到每個計算節(jié)點上,這帶來了很大的開銷.因此,對于較小的數(shù)據(jù)集和實驗室級別的環(huán)境,并且資源較充裕時,LightGBM 是一個不錯的選擇;但是對于較大的數(shù)據(jù)集和真實的生產(chǎn)環(huán)境,LightGBM常常是不可用的,而FP-GBDT的適用性很廣,更加適合大數(shù)據(jù)時代的需求和發(fā)展趨勢. Fig.11 Performance comparison of FP-GBDT and LightGBM圖11 FP-GBDT與LightGBM的性能對比 本文研究面向高維特征和多分類問題的分布式梯度提升樹算法.根據(jù)一個嚴(yán)格的代價模型,比較了數(shù)據(jù)并行策略和特征并行策略,證明了特征并行策略更適合高維和多分類場景;基于理論分析的結(jié)果,本文提出一種使用特征并行的分布式梯度提升樹算法FP-GBDT.FP-GBDT首先利用對數(shù)據(jù)集進(jìn)行分布式轉(zhuǎn)置,轉(zhuǎn)換為特征并行需要的數(shù)據(jù)表征;在建立梯度直方圖時,FP-GBDT設(shè)計了稀疏感知的方法;在分裂樹節(jié)點時,FP-GBDT使用一種比特圖壓縮的方法傳輸數(shù)據(jù)樣本的位置.實驗結(jié)果顯示,FP-GBDT與使用數(shù)據(jù)并行的 XGBoost相比,性能的提升最高達(dá)到6倍以上,證明了特征并行的FP-GBDT在高維和多分類問題上的高效性.3.4 分裂樹節(jié)點
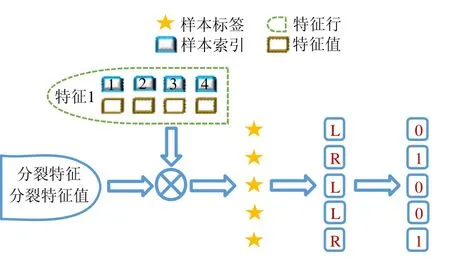
4 實驗對比
4.1 實驗設(shè)置

4.2 優(yōu)化方法有效性
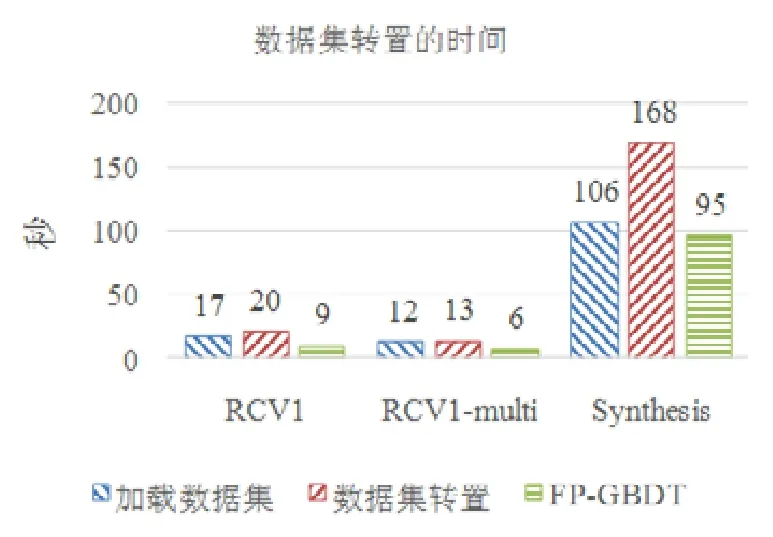
4.3 性能對比
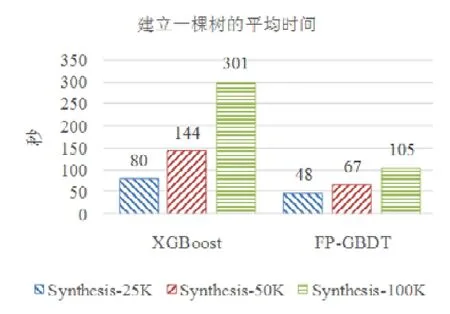
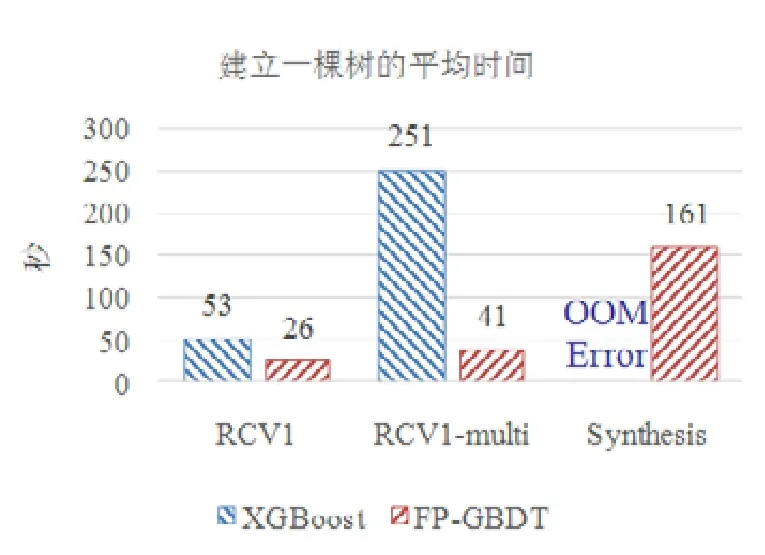
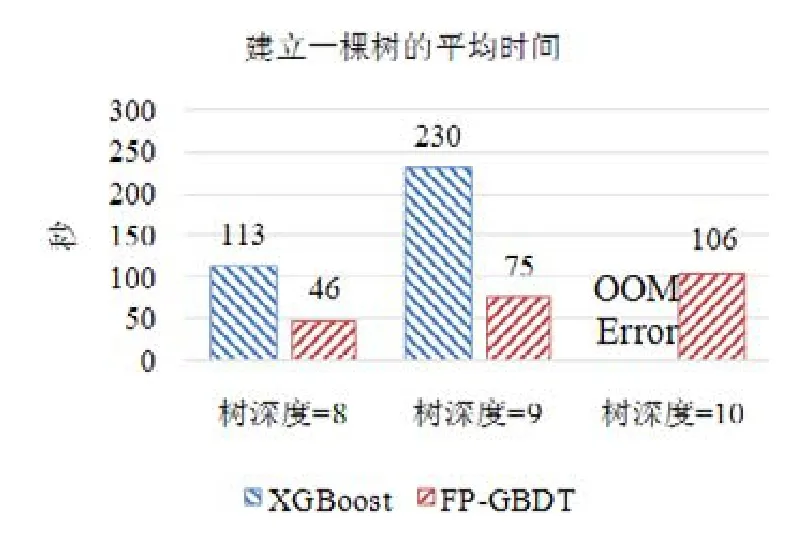
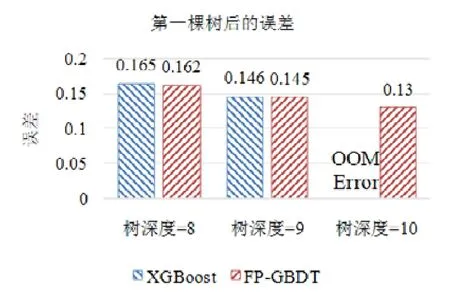
5 總 結(jié)
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2022年3期)2022-04-26 14:04:16
數(shù)學(xué)年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學(xué)學(xué)報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(xué)(2019年8期)2019-11-25 01:38:14
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學(xué)學(xué)報(2016年1期)2016-06-22 13:10:38
