高校共享停車行為特性及影響機理分析
2019-04-17 02:30:46胥晶晶
四川水泥 2019年2期
胥晶晶
(長安大學公路學院, 陜西 西安 710064)
關鍵字:高等院校;停車泊位共享;二元Logit模型;BP神經網絡模型
近年來,停車難、亂停亂放問題擾亂了城市良好的交通秩序,單純的依靠增加停車基礎設施建設已經無法滿足城市的停車需求,基于泊位共享的理念充分利用現有停車資源的方法得到廣泛關注。目前關于泊位共享的研究大多針對居住區,但高等院校通常具有面積大,停車需求時變規律明顯的特征。將高校的停車資源合理對外共享,對于緩解停車供需矛盾,提高泊位利用效率具有重要意義。本文在對高校泊位利用情況廣泛調研的基礎上,通過建立二元Logit模型并利用BP神經網絡對自變量篩選及建模,研究影響駕駛人選擇高校泊位共享的因素。
1 高校泊位空閑時間特性分析
本文以西安典型高校華清學院為例,進行高校泊位空閑特性分析。為獲取準確的高校停車數據,盡量避免毗鄰商業區、醫院等外來車輛干擾較大的高校。高校實現泊位共享需滿足時間、空間、停車場及泊位的相關要求。目前華清學院擁有地上停車位264個。
在華清學院門口進行為期一周的停車觀察,采用全時段車牌號記錄法獲取車輛進出學院的時間信息,以半小時為一個時間段,記錄每個時間段進出學院的車輛數;對比工作日與雙休日的平均停車數,以此為基礎進行車輛出行特性分析。
華清學院工作日和雙休日車輛出行特性,華清學院工作日車輛大體呈現出早間到達高峰和晚間離開高峰,雙休日車輛到達離開趨勢基本平穩。
高校車輛工作日朝來夕去的出行特性造成停車場在夜間出現明顯閑置,可供附近居民夜間長時停車;因受工作等影響,高校泊位在工作日午間時段空閑率略有下降,說明高校泊位白天不適合長時間停車,但為短時停車提供了方便的資源。高校停車場雙休日的泊位空閑數基本平穩且數量較高,適宜對外共享。總之,高校具備優良的對外共享條件,是具有潛力的共享停車資源。
2 基于二元Logit模型的共享停車選擇行為分析
2.1 共享停車選擇行為調查
本文采用SP調查方法,結合駕駛員和停車場的特性設計調查問卷,假設本次出行目的地的停車位已滿,附近有一處高校可進行泊位共享,研究分析影響駕駛員停車行為選擇的因素。根據目前的研究,影響駕駛人停車選擇的因素很多,包括個人經濟條件、個人停車習慣、環境狀況、車輛因素等。本文選取駕駛人特性和停車場特性兩個方面共16個變量。
2.2 模型標定及影響因素分析
本文根據問卷調查的數據建立共享停車選擇行為模型,進行參數標定。本文有兩種選擇,i=1表示選擇高校泊位共享,i=2表示不選擇;由此可以分析駕駛員是否選擇高校泊位共享的影響因素。
根據模型系數進行分析:1)隨著年齡的增加,停車者更愿意選擇高校泊位共享。2)收入越高的人會選擇收費較高的公共停車設施。3)停放時間越長,停車者更愿意選擇高校泊位共享。4)停車目的對駕駛人是否選擇高校泊位共享影響很大。5)停車后距目的地的步行距離越近,選擇高校泊位共享的可能性越大。6)停車誘導信息發布越完整以及停車設施安全性越高,選擇高校泊位共享的可能性越大。
通過模型的二元Logistic回歸分析,模型可以表達為:
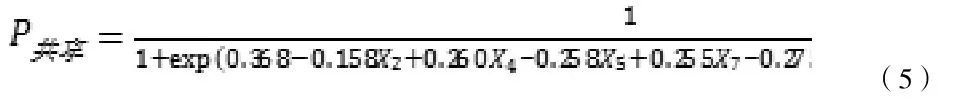
3 基于BP神經網絡的建模分析
Logit模型是基于效用最大化理論的離散選擇模型,在建模的過程中,變量對目標變量的非線性影響很難通過變量的篩選方法來模擬,BP神經網絡是由非線性單元組成的前饋網絡,能夠通過不斷的自主學習和反饋判斷彌補Logit模型的不足。
3.1 BP神經網絡模型的構建
本文選取影響駕駛人泊位共享的因素包括駕駛人特性和停車場特性,BP神經網絡培訓和檢驗樣本的輸入變量為表1中的16個變量,即輸入層的神經元個數為16,停車者是否選擇高校泊位共享作為輸出層的神經元,故而檢驗和培訓樣本輸出層的神經元個數為2。
3.2 因子分析
因子分析的對象包括駕齡、年齡和年收入等16個變量,檢驗結果表明各變量能夠獨立提供信息。
除去停車設施附近交通狀況、停車設施管理和服務水平外,其他公因子被抽取的比例均低于70%,說明這些變量較好無法的解釋其他變量。
自變量的特征值處于下降的狀態,并沒有陡降點。雖然從第 9個成分開始特征值小于1,但是和前9和特征值相差不大,所以認為特征值大于1的成分無法較好的解釋剩余變量。綜上所述,選取的16個變量滿足進一步變量篩選分析的條件。
3.3 明確并驗證最優隱層節點數
運用SPSS 22,采用神經網絡多層感知器模型進行數據分析,首先將協變量標準化,并將培訓樣本和檢驗樣本按照7:3的比例設置;然后隱藏層和輸出層的激活函數均使用Sigmoid,培訓類型為批處理,優化算法選擇調整的共軛梯度;最后將初始Lambda值和初始西格瑪值分別設為0.0000005和0.00005。按照此方法得到共享泊位選擇情況預測結果,確定最優隱層節點數為6。
驗證最優隱層節點數的合理性主要有兩種方法:預測累計增益圖分析和ROC曲線。
ROC曲線反映正確預測的百分比,橫軸特意性與 ROC曲線之間的面積大小AUC值反映了模型預測的優劣程度,AUC值越大表明預測結果越好。預測選擇或不選擇高校泊位共享的兩種情況精度接近,當錯誤預測比例達到0.3時,兩者預測精度均接近80%,此時AUC為0.768,表明可以利用該預測結果進行自變量篩選分析。
增益較高的為不選擇高校進行泊位共享,當抽取的樣本數達到 30%時,能被預測到的結果超過60%。綜上,檢驗和培訓樣本的選取和模型預測均較為滿意。
3.4 模型結果
整理自變量的原始重要性和標準化重要性如圖 1所示,修正后泊位共享模型的建模自變量選取標準化后重要性在 60%以上的變量,變量分別為停車目的、步行距離以及停車設施的安全性。
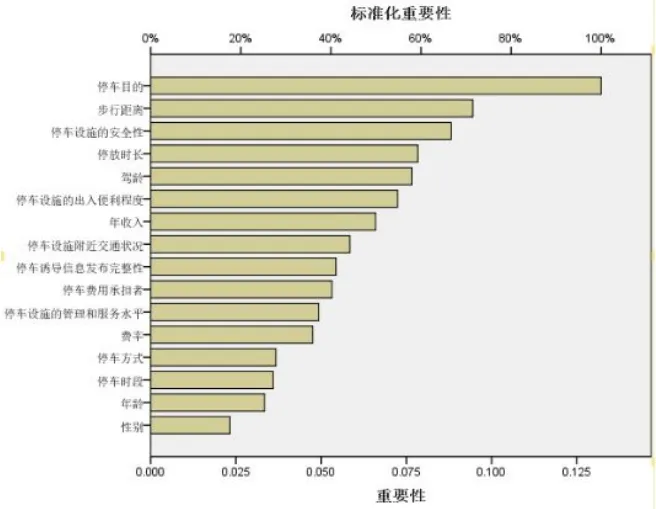
圖1 自變量重要性排序圖
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
