特征級融合方法及其在醫學圖像方面的應用
2019-04-15 06:53:52張飛飛陸惠玲梁蒙蒙
計算機應用與軟件 2019年4期
張飛飛 周 濤,* 陸惠玲 梁蒙蒙 楊 健
1(寧夏醫科大學公共衛生與管理學院 寧夏 銀川 750000) 2(寧夏醫科大學理學院 寧夏 銀川 750000)
0 引 言
圖像融合按照不同的層次劃分為像素級融合、特征級融合和決策級融合,其中特征級融合屬于中間層次的融合。首先對原圖像進行歸一化、幾何變化等預處理,其次根據不同模態圖像的特點提取特征構造原始特征空間,最后對特征信息進行綜合處理。其目的是實現不同模態圖像的分類、匯集和綜合。
特征級融合方法主要包括特征變換和特征選擇兩種,特征變換是將數據從原始特征空間映射到較低維數的特征空間中,降低數據特征空間的維數、消除特征相互之間的相關性,減少冗余和不相關的特征[1]。特征選擇是從原始特征空間中選擇出一定數量的具有代表性的特征,達到降低數據集維度的目的,包括特征子集的生成、評價特征子集、停止準則的判斷、驗證方法四個步驟。圖像特征級融合作為信息融合的重要分支,廣泛應用于臨床醫療診斷、遙感技術、計算機視覺以及軍事檢測等領域。其中在醫學圖像處理領域主要應用于計算機輔助診斷,減輕臨床醫生的工作負擔,減少漏診和誤診。如Zhu等[2]將特征不對稱度量納入目標函數的正則化項,提出減少超聲圖像斑點的優化方法,有效區分特征和斑點噪聲,有助于超聲在臨床診斷和治療中的應用;任亞平[3]提出核獨立成分分析用于醫學圖像去噪,可以保留圖像細節信息提高圖像質量,降低計算復雜度;Li等[4]提出了一種基于監督正交線性局部切線空間排列算法和最優監督模糊C均值聚類算法,用于生命等級的識別,提高了模式識別效率,避免了局部最小化。
雖然特征級融合方法應用廣泛,但其基礎理論和結構體系還不完整,技術劃分不是很明確。特征級融合的主要問題是提取何種特征構造原始特征空間以及如何獲取分類性能較好的特征子集,即特征的變換和選擇,同時面向具體的應用時,選取何種融合算法也是應該考慮的重要因素。因此,本文從特征變換和特征選擇兩個維度對特征級融合方法進行分類總結,從理論層面對改進的方法進行匯總,并簡單介紹其在醫學圖像處理領域的應用。
1 圖像特征級融合流程
圖像特征級融合分為圖像獲取、預處理、提取特征構造原始特征空間、通過特征變換或特征選擇進行特征融合達到降低維度的目的,最后進行決策識別。隨著計算機技術的發展,學者們根據實際情況提出了很多特征級融合方法,分為特征變換和特征選擇。特征變換是將原始特征空間映射到低維空間中[1],減少特征空間維數,減少相關性或冗余性較強的特征,壓縮數據量和結構,特征變換方法按照是否線性可分分為線性和非線性兩大類。特征選擇是從原始特征空間中選擇最有代表性的特征以降低數據集維度,包括候選特征子集的生成、子集評價、停止準則、驗證方法四個步驟。如圖1所示,以醫學圖像為例,給出了特征級融合流程圖。
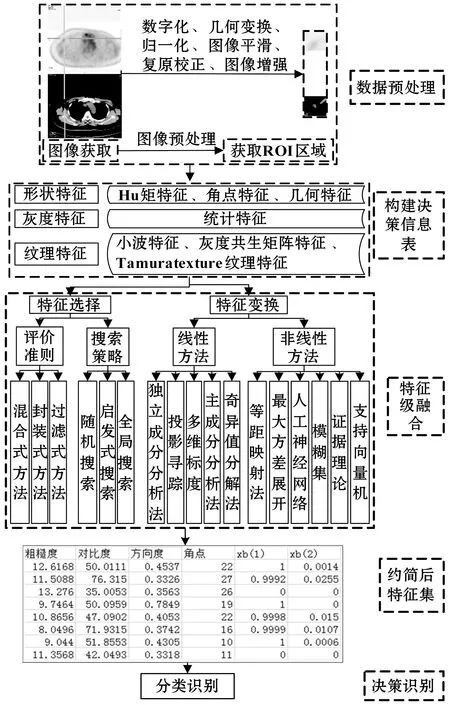
圖1 圖像特征級融合流程圖(以醫學圖像為例)
2 特征變換方法及在醫學圖像中的應用
在圖像處理領域,專家學者們根據實際應用提出了很多特征變換算法,本節對特征變換算法及其在醫學圖像中的應用進行梳理總結,按照是否線性可分(線性方法和非線性方法)和是否有監督(監督學習、半監督學習和無監督學習)兩個維度進行分類總結,歸納其發展現狀和方向。線性方法和非線性方法具有各自獨特的優勢,應根據所需處理的數據特點,選擇合適的方法。
2.1 線性方法
線性特征變換方法是數據降維算法的一個重要分支,是一種比較簡單、成熟的降維方法。該方法要求數據集滿足全局線性結構并且各變量之間保持獨立無關聯。線性方法的核心是采用線性變換的方式從高維數據中提取最能夠體現樣本差異的成分,得到的數據特征能夠盡可能反映原始高維樣本數據的特征。圖2為線性特征變換算法分類圖,在醫學圖像特征級融合領域,專家學者提出了很多線性特征變換方法,如判別分析法[5]、多維尺度法[6]、Fisher鑒別分析[7]、K鄰近法[8]、樸素貝葉斯算法[9]、主成分分析法[10]、半監督鑒別分析法[11]、保持投影法[12]、獨立成分分析法[13]、局部特征分析法[14]、典型相關分析法[15]等,這些方法在很多文獻中都進行了總結闡述,下面重點介紹奇異值分解法和非負矩陣分解法及其改進算法,介紹其在特征級融合過程中的應用現狀、分析優缺點,并闡述其發展方向。

圖2 線性特征變換方法分類圖
2.1.1 奇異值分解
奇異值分解SVD(Singular Value Decomposition)方法是1873年由Beltrami首次提出的,是一種有效的代數特征變換方法,具有穩定性、比例和旋轉不變性等性質,在醫學圖像處理領域的應用包括圖像增強、壓縮、復原、降噪等。如Chen等[16]提出了一種對稱SVD表示方法,并將其應用于人臉識別;Zhang等[17]提出一種高階SVD方法,用于磁共振圖像中噪聲的消除,該方法顯著減少了條紋偽影,提高了降噪質量;Tai等[18]提出了一種用于面部識別的學習判別SVD方法,該方法在處理照明、遮擋、偽影等方面具有良好的效果;Chen等[19]提出了一種廣度截斷SVD方法,與現有的時域法相比具有更高的精度、適應性和抗躁等優點。雖然SVD具有全局意義上的數據處理能力,但仍存在不足,如算法的可解釋性不強,對噪聲數據的處理能力不穩定等。特別是當處理數據是高維海量時,SVD分解的速度和精度會成為其發展的瓶頸。
2.1.2 非負矩陣分解
非負矩陣分解NMF(Non-negative matrix factorization)是1999年D.D.Lee和H.S.Seung首次提出的,其應用前提是矩陣中的元素均為非負數據,具有實現簡單方便,存儲空間占用少的特點,在實際生活中的應用越來越廣泛,如圖像處理、語音分析、文本分析、數據挖掘、模式識別等。很多專家學者在經典NMF的基礎上提出了很多改進算法,主要分為約束NMF、結構化NMF和泛化NMF三種。如楊永生等[20]提出利用多核NMF對原始數據進行約簡,多核SVM進行分類識別,實驗證明該方法可有效降低原始數據的維數,提高分類識別的效率;Gao等[21]提出了一種空間加權NMF,并結合分層交替最小二乘法用于圖像、視頻等視覺信號的處理;Shu等[22]提出了一種無參數自動加權多重圖形正則化NMF,證明其具有良好的性能。目前,NMF的主要問題是容易早熟收斂、收斂速度慢,后續研究一方面要解決收斂速度和唯一解問題,另一方面也要拓寬NMF在實際中的應用。
2.2 非線性方法
雖然線性特征變換方法簡單易于實現,但是現實中大多數數據具有“高維數、非結構化”的特點,此時傳統的線性特征變換方法就不能得到期望的約簡效果。因此,近年來許多非線性特征變換方法在理論和應用層面都得到了很大的發展,如核Fisher鑒別分析[23]、拉普拉斯特征映射[24]、隨機領域嵌入[25]、核獨立成分分析[26]、局部線性嵌入[27]、等距映射[28]、核主成分分析[29]、局部切空間排列[4]、最大方差展開[30]、證據理論[31]等。圖3為非線性特征變換算法分類圖,其中,神經網絡、模糊集、支持向量機應用最為廣泛,因此對這三種方法及其改進算法進行梳理總結。

圖3 非線性特征變換方法分類圖
2.2.1 人工神經網絡
人工神經網絡ANN(Artificial neural network)是對人腦神經元網絡的一種抽象表達,由大量處理單元按照不同的方式互聯組成,對于處理含糊性和不確定性的圖像問題具有很好的效果。隨著逐漸深入的研究,ANN的應用已經越來越廣泛,如模式識別、衛生保健、生物醫學等。目前,已有大約40種ANN模型,如Kohonen神經網絡、Elman動態神經網絡、自組織映射神經網絡、脈沖耦合神經網絡等。ANN在疾病診斷過程中的應用廣泛,如文獻[32]使用卷積神經網絡對黑色素瘤進行早期診斷,診斷精度高于其他算法;文獻[33]等采用誤差反向傳播算法,從輸入數據中提取有價值的體積和檢測肺結節CT圖像子塊來構建檢測胸部CT圖像中肺結節的CADe系統;文獻[34]提出反向傳播神經網絡,用于超聲圖像去噪和去模糊處理;文獻[35]使用神經網絡對計算機斷層掃描圖像進行去噪處理。為提高ANN算法的效率及其魯棒性,與其他方法如模糊系統、遺傳算法、進化機制、混沌理論、小波算法、粗集理論等相結合是其研究的重要方向,同時改進網絡的拓撲結構、權重、激勵函數及學習規則也是發展的一個方向。
圖4為人工神經網絡方法分類圖。
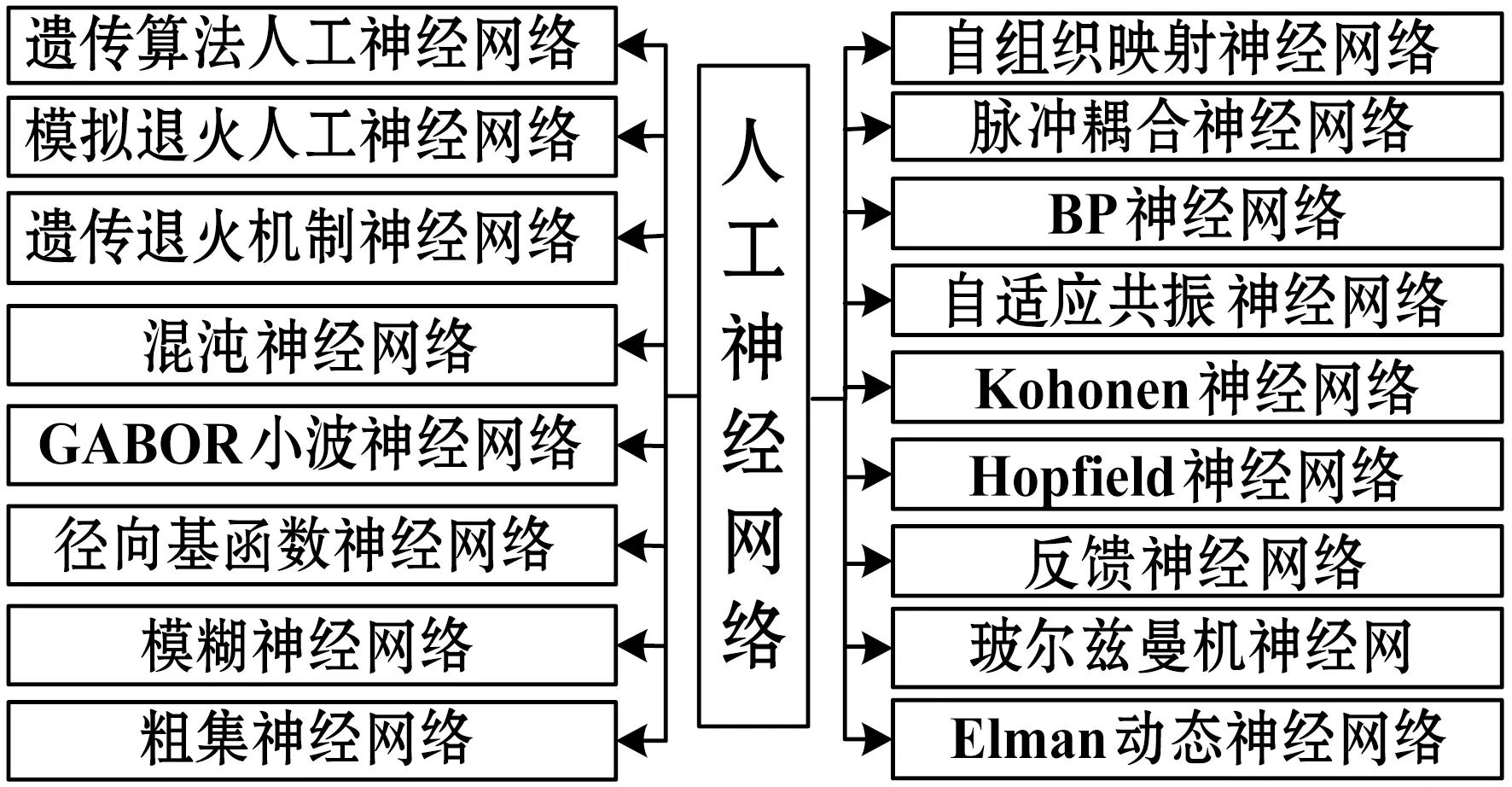
圖4 人工神經網絡方法分類圖
2.2.2 支持向量機
支持向量機SVM(Support vector machine)于1995年被Corinna Cortes和Vapnik等首次提出,該模型的基礎是統計學習和結構風險最小原理。SVM具有泛化能力強、樣本維數大小不敏感、全局收斂等特點,在理論和應用方面都取得飛速發展。目前在理論方面:SVM的理論改進主要包括四個方面:一是SVM本身的改進,包括光滑SVM、拉格朗日SVM、最小二乘SVM、Robust SVM、單類SVM、小波SVM等;二是核函數的選擇,常用的核函數包括多項式核函數、線性核函數、Sigmoid核函數和徑向基核函數[36];三是參數的優化,群智能算法經常被用來優化SVM的懲罰因子和核函數參數,例如蝙蝠算法、螢火蟲算法、人工蜂群算法、果蠅算法、蟻群算法、灰狼算法、人工魚群算法等[37];四是與其他分類算法的結合使用,包括AdaBoost、K臨近、隱馬爾科夫等。在醫學圖像處理領域的應用如文獻[38]使用SVM進行阿爾茨海默病、輕度認知障礙和正常人的分類,明顯提高了精度和性能;文獻[39]使用SVM在肺癌早期診斷的CAD系統中進行特征分類;文獻[40]使用SVM進行乳腺癌的篩查,提高了敏感性、特異性和準確性。雖然SVM的理論研究和應用已經成為數據挖掘的熱點,但仍存在一定的缺點,如當數量較大時,計算速度大幅度減慢,對噪聲和孤立點數據非常敏感。拓寬待解決問題的應用領域、與其他機器學習方法進行融合、加強訓練算法等是今后研究的重要方向。對SVM改進算法分類如圖5所示。

圖5 支持向量機改進算法分類圖
2.2.3 模糊集
模糊集(Fuzzy set)理論是L.A.Zadeh在1965年提出的,主要思想是用屬于的程度大小來描述屬性之間的屬于或者不屬于關系,表達差異的一種中間過度,是用精確性去逼近模糊性,已經成為處理不確定信息和知識的重要數學工具。近年來,模糊集在圖像增強、濾波、邊緣檢測等領域不斷擴展,在提高信噪比、保留細節信息等方面具有很大的優越性。為了提高系統在處理不確定性信息方面的能力,對模糊集進行不斷擴展,提出很多改進模型,如n維模糊集、雙極值模糊集、直覺模糊集、Flou模糊集、模糊值模糊集、區間值模糊集、擾動模糊集、粗糙模糊集、猶豫模糊集等。在醫學領域的應用廣泛,例如Liang等[41]在決策粗糙集理論的基礎上提出了對偶猶豫模糊集,通過緊急血液轉運評估來驗證該模型的有效性;文獻[42]提出一種新的確定直覺模糊集距離度量的方法,用于提高醫學圖像診斷的正確性,在真實的數據集上驗證了該方法的適用性和有效性。目前,完善模糊集理論、改進經典算法、與其他優化方法相結合是其發展的主要方向。如圖6為模糊集及其改進方法分類圖。
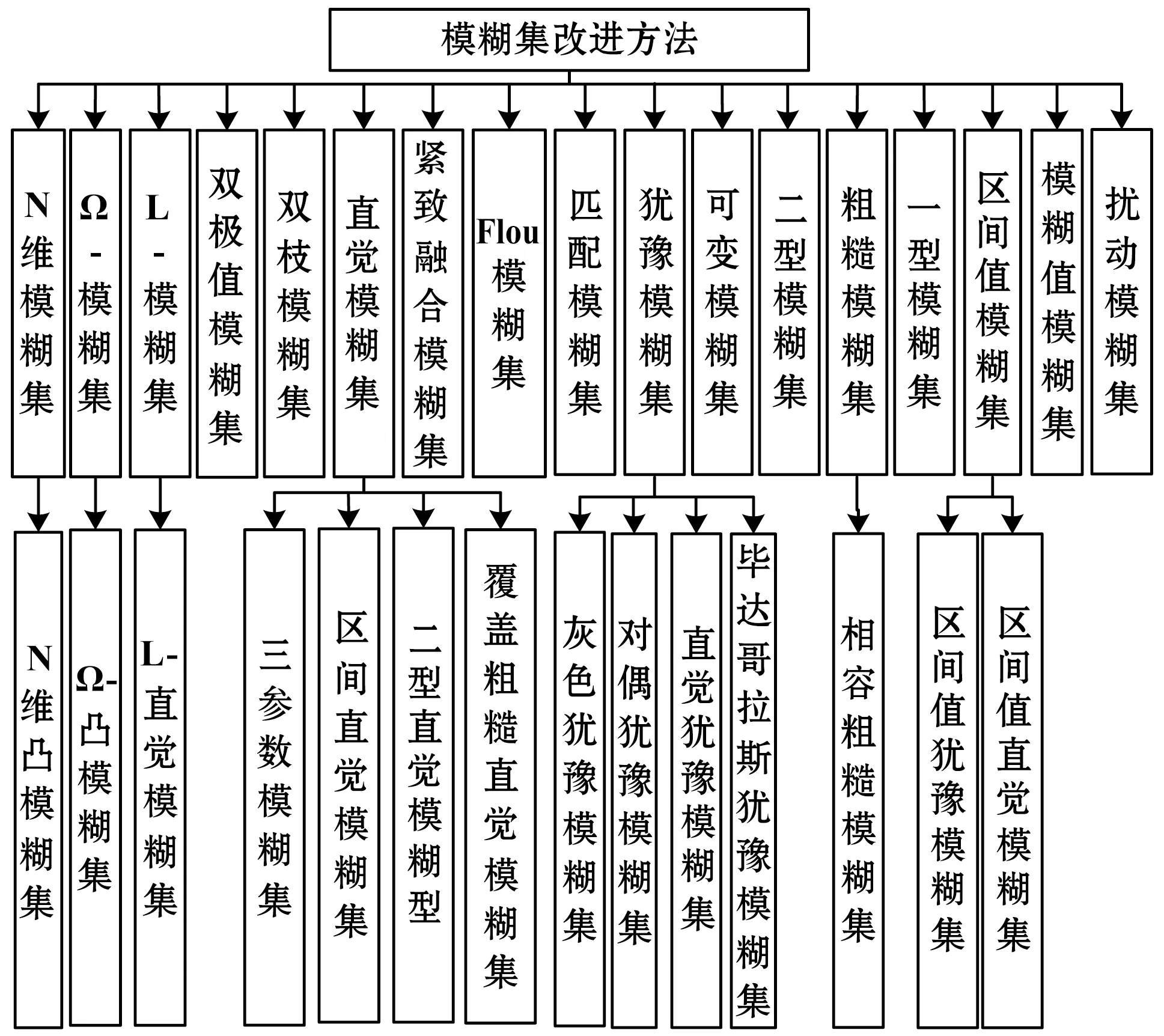
圖6 模糊集改進方法分類
3 特征選擇方法及在醫學圖像中的應用
特征選擇也稱候選特征子集的選擇,是指從原始特征數據中選擇分類性能較好的特征子集,使選擇后的特征構建的模型效果更好。文獻[1]中根據選擇思想不同分為特征優選和特征劣選。特征優選是指從原始特征空間中選出分類性能較好的特征子集,特征劣選是指從原始特征中剔除冗余或無關的特征子集。特征選擇分為特征子集的生成、評價特征子集、判斷停止準則、驗證方法四個部分。
3.1 特征子集的生成
特征選擇的關鍵步驟就是生成候選特征子集,特征子集生成方式取決于不同的搜索策略,主要分為全局最優搜索策略、隨機搜索策略、啟發式搜索策略和混合搜索策略四類。下面按照四種搜索策略對基本的特征選擇算法進行分類總結,主要方法分類如圖7所示。
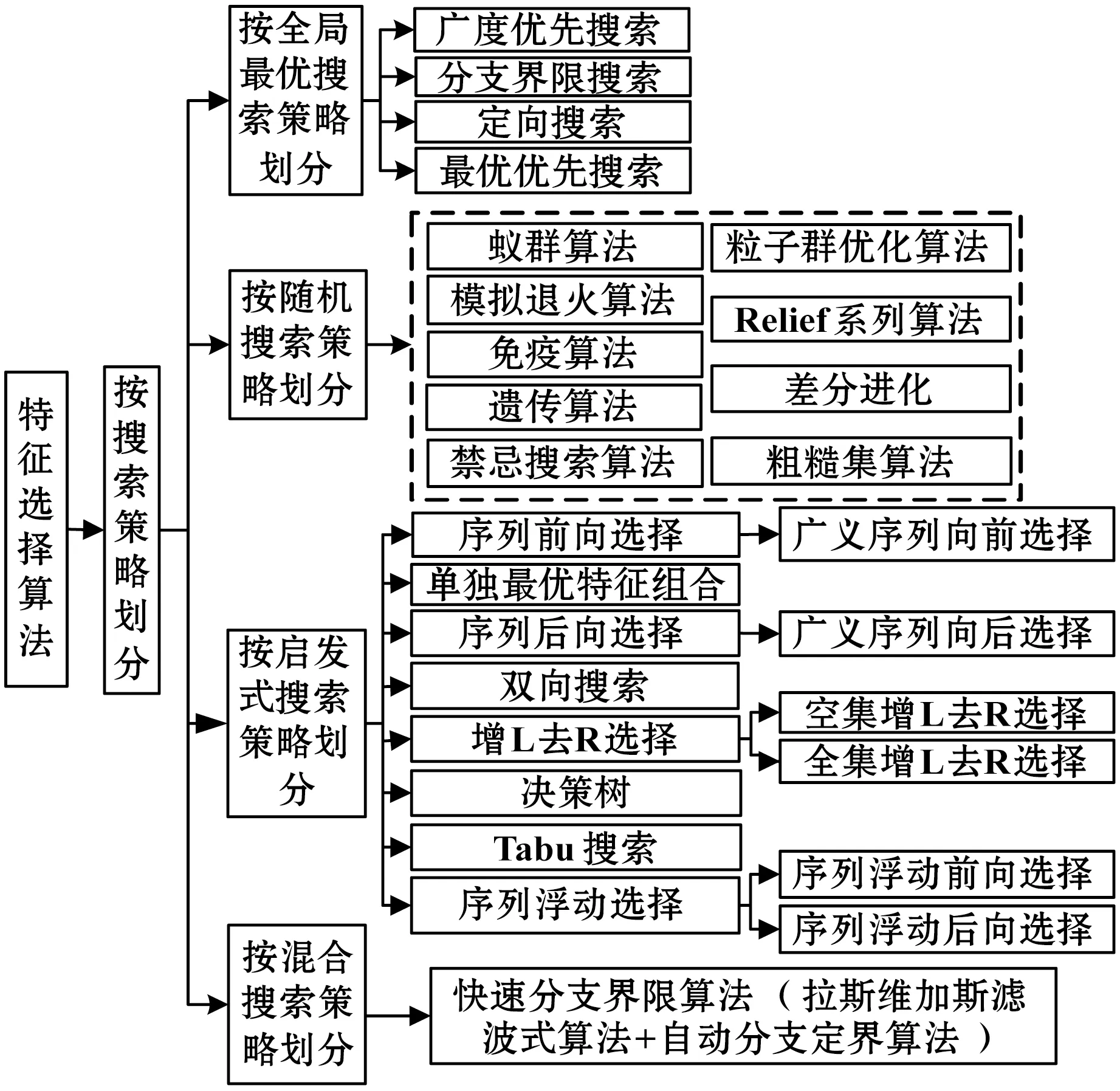
圖7 按搜索策略劃分特征選擇算法
3.1.1 采用全局最優搜索策略特征選擇算法
全局最優搜索是一種通過算法的不斷迭代來實現的窮舉式搜索,可以搜索到所有符合條件的特征子集。常用的全局最優搜索方法包括:廣度優先搜索、分支界限搜索、定向搜索和最優優先搜索等。其中廣度優先搜索又名寬度優先搜索,時間復雜度高,實用性低;定向搜索相比寬搜可以節省時間和空間,可以算是啟發式搜索的一種;最優優先方法的搜索過程是計算特征集合評價函數,再將計算結果進行排序,選擇代價最小的路徑繼續搜索。由于在搜索過程中總是放棄代價大的路徑,因此最終得到的特征子集就是搜索過程中代價最小的問題答案。分支界限搜索是使用最廣泛的一種全局最優搜索算法,通過剪枝處理來減少搜索時間,具體原理是將需要解決的原始問題逐步分解成為多個不能再分解的子問題,通過求解子問題的最優解得到原始問題的最優解,它的優點是在保證特征數目一定的情況下,搜索到相對而言的最優特征子集。
雖然全局最優搜索策略劃分的方法能找到全局最優解,但隨著特征數量的增大,計算時間和空間大幅增加,因此無法廣泛應用。
3.1.2 采用隨機搜索策略的特征選擇算法
隨機搜索策略的特征選擇算法首先隨機產生一個候選特征子集,再根據實際問題的啟發信息逐步搜索全局最優解。常用的方法包括遺傳算法、粒子群算法、免疫算法、禁忌搜索算法、粗糙集、差分進化等。遺傳算法和粗糙集的應用非常廣泛,下面對這兩種方法進行歸納總結。
(1) 粗糙集。粗糙集RS(rough set)是處理模糊性和不確定性信息的一種數學工具,是一種新的軟計算方法,因其無需先驗知識的特性,在機器學習、分析決策、過程控制等領域引起了專家學者的廣泛關注,在傳統Pawlak RS的基礎上相繼提出了很多改進算法,例如粒度RS、鄰域RS、加權RS、覆蓋RS、灰色RS、決策RS、模糊RS、優勢RS等。其中模糊RS的應用最為廣泛,與其他方法相結合,形成一系列的改進模糊RS,例如多粒度模糊RS、F-模糊RS、直覺模糊RS、雙論域模糊RS、穩健模糊RS、模糊決策RS等。在醫學圖像處理領域,RS廣泛應用于圖像濾波、識別、分類、融合、分割;醫學數據挖掘;疾病預測、醫療診斷、疾病分類等。例如Wang等[43]提出首先使用ANN對乳腺癌數據進行離散化,GA進行屬性約簡,最后使用RS從決策表中歸納診斷規則,相比傳統的CAD系統,診斷精度顯著提高;Guo等[44]提出了一種基于模糊RS的特征選擇方法,用于乳腺癌的風險評估,提高了降維效率和分類準確率;文獻[45]提出了直覺模糊RS模型,用直方圖作為RS的下近似,直覺模糊直方圖作為上近似進行腦MR圖像的分割,定量評價表明,該算法具有一定的優越性。雖然RS無需先驗知識,但缺乏處理數據本身模糊性的能力,且對邊界區域刻畫過于簡單,與很多實際問題不符,后續應在這些方面進行改進。圖8為粗糙集方法分類圖。
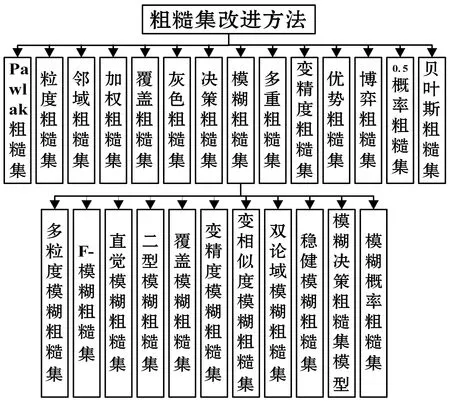
圖8 粗糙集改進方法分類圖
(2) 遺傳算法。遺傳算法GA(Genetic Algorithm)是根據生物遺傳的規律,通過選擇、交叉、變異等遺傳操作達到提高個體適應性的目的。雖然GA在機器學習、圖形圖像處理、社會科學、數據挖掘、人工生命等領域取得了卓越的成效,但是仍然存在收斂速度過快和容易陷入局部最小(早熟)的問題。因此,很多專家學者針對這兩個問題在理論層面提出了很多改進算法。例如,為了保持種群的多樣性,于歆杰等[46]提出了擁擠GA,根據競爭方式和評價個體生存能力的不同,派生出不同類型的擁擠GA,如:限制性錦標選擇方法、多小生境擁擠算法和確定性擁擠算法;王聰等[47]對小生境GA進行改進,提出一種新的混合GA,通過實驗證明該算法具有較好的收斂性和較低的時間復雜度。適應度函數改進方面,陳果等[48]提出四種新的GA特征選擇適應度函數,即基于改進的距離判據適應度函數、基于平均值方差比的適應度函數、基于Fisher準則的適應度函數和基于最近鄰分類法的適應度函數,通過實驗證明不同適應度函數的適用性和有效性;李乃成等[49]為了自適應調整變異概率,提出一種具有對偶適應度函數的GA,通過在不同的函數上測試,證明該方法具有較好的收斂速度;楊水清等[50]將乘冪變換和線性尺度變換相結合,提出了一種基于乘冪變換的非線性動態適應度函數,在常用的測試函數上驗證算法的有效性與可行性。在遺傳算子方面,楊新武等[51]采用自適應比例選擇策略,調整平衡算法求精和求泛能力,實驗證明該算法可有效克服早熟;李書全等[52]針對不同的編碼方式總結了常用交叉算子,并從不同的角度提出了相應的改進算法。同時,也逐步形成了很多混合GA,例如:文化GA、蟻群GA、粒子群GA、模擬退火GA等。GA算法廣泛應用于醫學圖像處理領域,例如文獻[53]在混合醫學圖像檢索系統的設計時,采用GA進行特征降維,在保證正確率的前提下降低時間復雜度,解決維數災難問題;文獻[54]提出一種基于改進GA和耦合映像格的混合模型,用于醫學圖像的加密,實驗證明該算法不僅能完成加密工作,也能抵御各種典型的攻擊。GA以后研究重點應該是與優化技術的融合,對算法本身的改進以及新算法的提出,更重要的應該是混合GA的研究。GA是對自然進化規則的一個理論性簡化,缺乏系統的數學基礎,后續應該不斷完善基礎理論,拓寬應用的范圍。從編碼、初始種群構建、適應度函數、遺傳算子還有混合算法幾個方面對GA進行總結,如圖9所示。
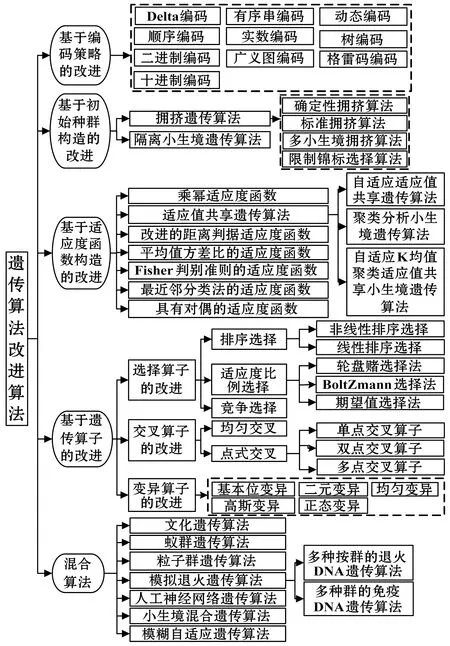
圖9 遺傳算法改進方法分類圖
隨機搜索策略特征選擇算法可以獲得一個近似最優解,但是,隨著特征維數的增加,時間復雜度也會嚴重增加。
3.1.3 采用啟發式搜索策略的特征選擇算法
為了避免窮舉式搜索帶來的計算代價,啟發式搜索特征選擇算法為了有效指導搜索的方向,在搜索過程中加入了與實際問題有關的啟發式信息,以便加速獲得優化特征子集的過程。比較典型的搜索算法包括單獨最優特征組合、序列前向選擇、序列后向選擇、增L去R選擇、決策樹、Tabu搜索以及浮動搜索等。
3.1.4 采用混合搜索策略的特征選擇算法
綜合上述三種策略優點的混合式搜索策略是今后特征子集產生的新研究方向,可以有效避免單獨一種搜索策略的缺點,得到一些在各方面比單獨策略更優的特征選擇方法。每種搜索策略劃分的算法各有優缺點,在處理實際問題時,必須綜合考慮問題的時間復雜度、空間復雜度和全局最優解,在這些條件之間尋找一個最佳平衡點。例如當原始特征集合維數較少時,可選用全局最優搜索策略方法;若要求時間復雜度低,對選擇的子集全局性要求不高時,可選用啟發式策略方法;若需相對較高性能的特征子集,計算時間要求較低時,可采用隨機搜索策略方法[55]。
3.2 特征子集評價函數
評價函數是特征子集優劣的判斷依據,按特征子集評價標準和算法劃分結果如圖10所示。
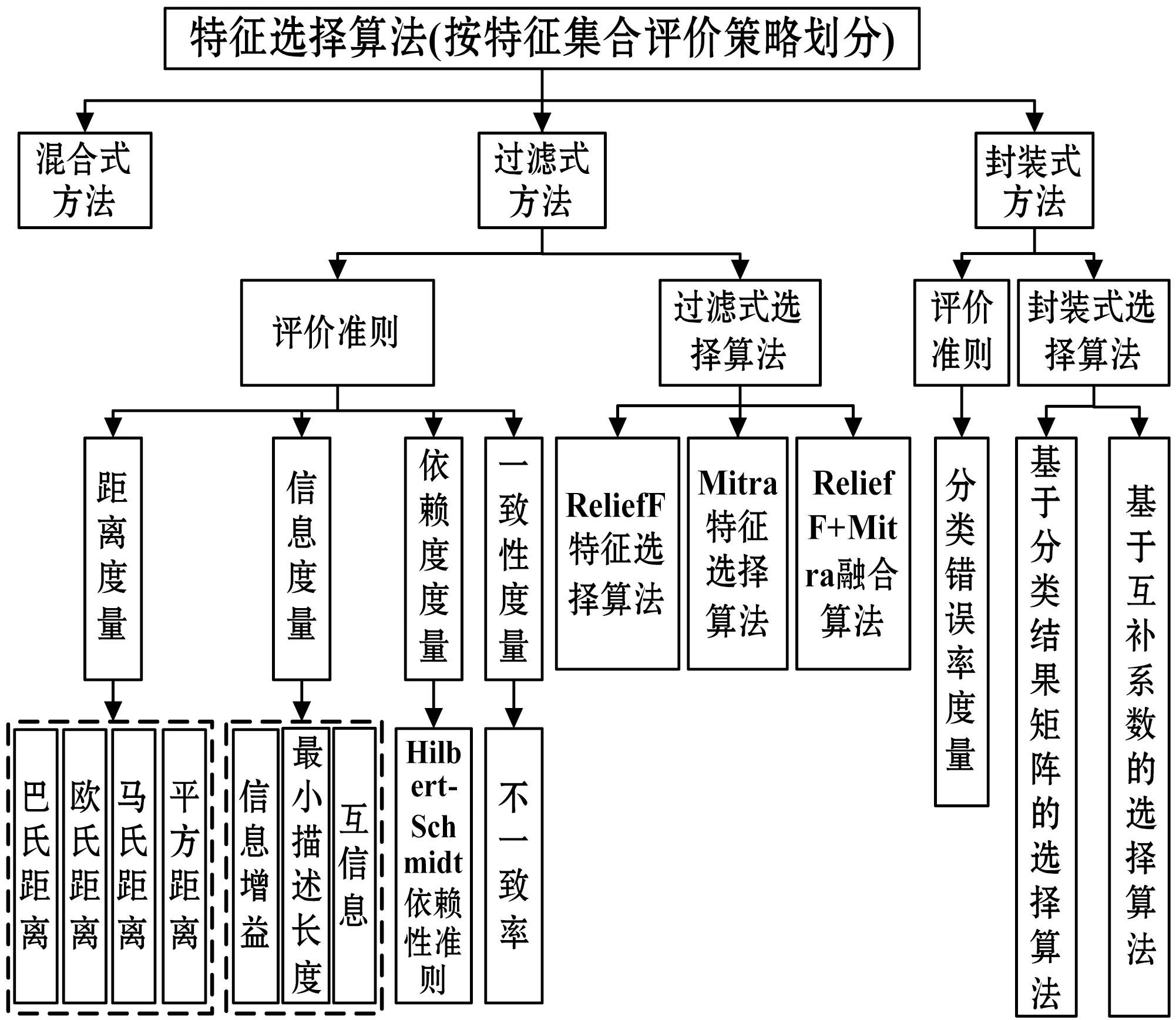
圖10 按特征集合評價策略劃分圖
3.2.1 過濾式評價策略的特征選擇方法
Filter過濾式特征選擇方法使用評價準則來加強不同的特征與其所屬類之間的相關性,達到減弱特征關聯性的目的。通常使用的評價準則包括:距離(歐式距離、馬氏距離、平方距離等)、信息(信息增益、互信息、最小描述長度等)、依賴度和一致度等。ReliefF系列算法是最常用的Filter特征選擇算法。它不依賴于確定的學習算法,而是根據數據集內在的固有特征來評價不同特征的分類性能,找到最優的特征子集,主要通過統計學習的方法檢測變量之間的差異性。Filter算法運算的優點是速度較快,但是評價結果與后續學習算法本身的性能之間存在較大偏差。
3.2.2 封裝式評價策略的特征選擇方法
Wrapper模型是一種有監督學習方法,直接使用分類性能的優劣作為評價特征重要性程度的標準,它的最終目的是構造分類器模型。因此如果在構造初始分類器的過程中,直接使用分類性能較高的特征,就可以使得分類器模型取得比較高的性能。Wrapper方法決定特征子集優劣的標準是通過在特征選擇流程中嵌入其他的學習算法,測試不同算法中特征子集的分類性能來實現的,而很少去關注特征子集中單個特征預測性能的優劣。常用的Wrapper特征選擇算法包括基于分類結果矩陣和基于互補系數的方法。Wrapper方法使用后續嵌入學習算法的分類精確度來評價特征子集的優劣,分類的偏差小,但是計算量大,適合于數據量較小的樣本,通用性較弱。
3.2.3 Filter和Wrapper組合式算法
Filter結果與最終使用的分類器無關,不便于進一步優化分類器的性能。Wrappe雖然能獲得較高的分類率,但不能標記出選擇的屬性與對象之間的相關性,因此,將Filter和Wrapper兩種互補的模式相結合將是未來研究的方向。如:陳巖等[56]利用Filter-Wrapper結合的方法獲取特征變量的屬性,首先使用Filter方法從原始特征集合中選出一定數量的具有代表意義的特征子集,降低搜索空間的維數。其次使用Wrapper方法從特征子集中二次選出滿足精確度要求的特征變量,實驗證明該方法的優越性。
3.3 停止條件
特征子集評價完成后要判斷是否符合“停止條件”的要求,如果不滿足設置的停止條件,搜索過程將進入死循環,無限執行下去。通常選用的停止條件包括:算法運行時間、評價的閾值次數、特征子集的數量、評價函數的閾值以及算法早熟或收斂等。
3.4 結果驗證
驗證特征子集的優劣一般選用人工或真實的數據集,將經過特征級融合后的約簡結果作為分類器的輸入進行訓練和測試,最后將分類結果與沒有經過特征級融合的原始數據集進行比較。比較指標包括分類的時間、空間復雜度以及分類器的精確度等。
特征選擇是特征降維方法中非常重要的分支,隨著研究逐漸深入,已經形成了很多成熟的方法,但是,研究過程中同樣也存在很多問題。例如:如何針對不同數據量、不同數據類型設計最適合的特征選擇方法,不同類別特征選擇算法之間的相互融合,算法的進一步優化與實際應用等。將來的研究應該在克服這些問題的基礎上繼續探索,完善特征選擇算法體系,為特征降維提供良好的技術支撐。
4 結 語
隨著數字圖像處理技術的不斷發展,相繼提出了很多新的方法和技術。本文圍繞特征級融合方法,對特征變換和特征選擇方法進行了分類總結,通過總結不同方法的發展現狀,發現特征級融合仍存在以下不足和需要繼續改善的地方:
(1) 雖然特征級融合方法已經提出了很多理論和算法,但未形成一個完善的理論體系,在不同的應用中效果仍然無法系統地評價,因此制定一個比較完善并且客觀的評價標準勢在必行。
(2) 特征級融合過程中最重要的過程就是特征的提取,當特征數量增加時,融合算法的時間復雜度和空間復雜度會迅速增加,會出現維數災難問題,因此優化算法降低復雜度是今后發展的重要方向。
(3) 盡管特征級融合研究目前已經有不少的研究成果,但與現實要求還存在很大的差距,很多融合算法的運行速度、精確度、實用性以及魯棒性等仍需改進。
(4) 特征級融合技術在實際應用中扮演著越來越重要的角色,提取何種特征以及選擇合適的融合算法等仍是主要的研究問題。
(5) 醫學圖像模態眾多,功能各異,圖像所表現的信息也各不相同,如何針對不同模態的醫學圖像進行特征變換和選擇,從而促進計算機輔助診斷的發展也是今后發展的重要方向。
總之,特征級融合相比像素融合和決策級融合有其獨特的優勢,在現實中的應用也越來越廣泛,為信息處理帶來重大的變革,發揮著不可替代的作用。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
