動態物流中多源多點最佳路徑算法研究①
2019-04-10 05:09:20畢明華何利力
計算機系統應用 2019年2期
畢明華,何利力
(浙江理工大學 信息學院,杭州 310018)
企業物流主要關系到配送的成本和對需求的服務,目前仍處于發展階段,物流配送的能力直接影響了企業的市場競爭力,如何更快更好的把貨物送到目的地并能快速響應市場是一個需要持續解決的問題.企業物流是一個典型的多源多點問題,解決這類問題的關鍵是對多目標進行優化.這類問題起源于許多實際復雜系統的設計,建模和規劃,在很多實際的領域中都存在多目標優化問題[1].與普通的單目標相比,帶有多約束條件的多目標路徑優化問題更加復雜,且解往往不是唯一的.近年來,關于車輛最短路徑問題的研究層出不窮,關于這類問題的解決辦法有多種,在目標需求點較多的情況下,往往會使用傳統的算法,但這類算法效果差強人意.遺傳算法是一種高效的全局尋優算法,從串集開始的搜索最優解,而傳統算法只是從單個初始值進行迭代,這是兩者的最大區別,另外,遺傳算法搜索的覆蓋面更廣,便于全局擇優[2].
在解決車輛配送路徑問題的研究上,目前已有了很多的研究成果,但對于多源多點問題并沒有得到很好地解決.文獻[3]提出了一種帶訂單選擇的車輛路徑問題,建立經濟效益最大化的目標模型;文獻[4]從空間角度進行區域分割和路徑優化,實驗測試算法性能;文獻[5]提出了一種物流配送地理位置規劃的成本分析方法,建立包括所有終端成本和運輸成本的數學模型;文獻[6]從按門店配送和按貨物種類2種配送方式,建立相應模型,通過仿真實驗比較2種成本;文獻[7]以提高車輛滿載率為目標構建優化模型,并驗證模型和算法的有效性;文獻[8] 提出了用于解決容量車輛路徑問題的遺傳算法,通過實例進行算法測試;文獻[9-14]也是通過應用遺傳算法來求解不同種類的VRP問題;文獻[15]將動態路徑求解問題轉換為靜態VRP序列,使用蟻群系統算法進行研究DVRP問題.
以上文獻從不同的方面研究車輛配送路徑問題,著重于貨物種類分倉存儲的裝載配送是極少的,這與現實的倉儲情況存在一定的差距.實際配送當中,往往是多種貨物的混合需求,而現實的企業也是通過分倉分類目進行存儲,這就需要解決從多個倉庫取貨按各種不同貨物需求進行分類送貨.在以往的配貨過程中,通常出現單輛車不能滿足需求而多輛車空載率過高的情況,因此,本文提出一種新的配送方式: 不同倉庫存儲不同種貨物,由單輛車完成配送,充分考慮需求量,配送路徑,車輛載重之間的關系,建立重量修正車輛優化路徑模型,并通過仿真實驗進行可行性分析.
1 問題完整性描述
本文著重研究了單輛車承運情況下基于多倉庫和多目的地的最佳路徑配送,并提出一種基于重量修正的新配送方式.從車輛貨物裝載倉庫路徑的選擇,到中間路徑的優化,找到其費用最低,耗時更少的一條最佳配送路徑.配送分兩種情況: 一種是車輛非滿載情況,即總需求量不大于車輛本身載重量,這種情況下不做重量修正的最短路徑配送;另外一種是車輛滿載情況,即需求量大于車輛本身載重量,就要從不同需求點對不同種貨物的需求量進行分析,確定最開始配貨的倉庫,選擇優先配送的目的地,完成車容量差值的修正后,實現多目的地的共同配送.如圖1所示.
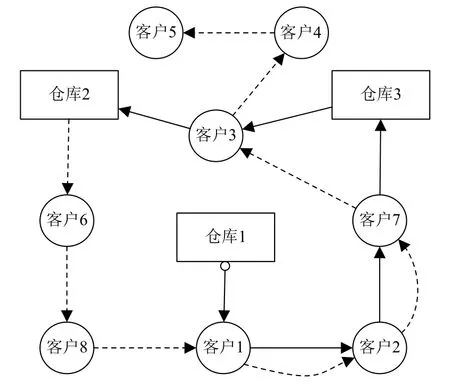
圖1 配送方式圖
2 將實際問題轉化為數學模型
多倉庫,多目的地的物流配送路徑優化問題的數學模型如下.建立成本最小目標函數:
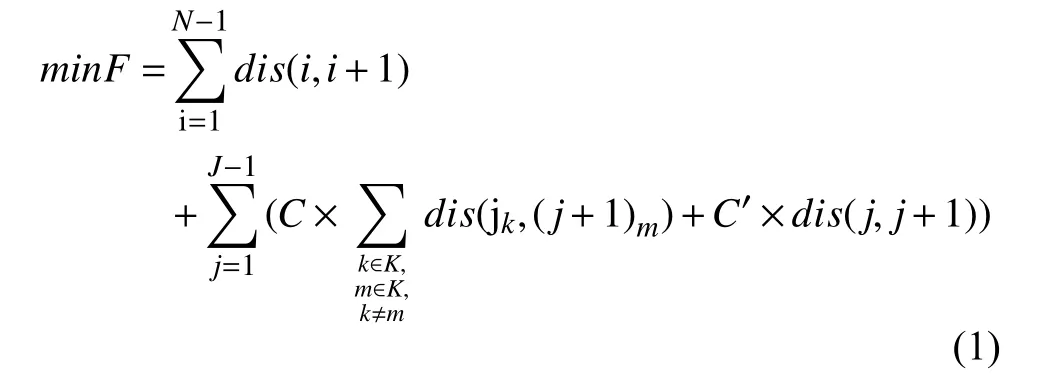
其中,i表示需求點,N表示需求點的總數量,dis(a,b)表示需求點a和b之 間的距離.j表示倉庫點,J表示倉庫點的總數量.C與C′為互斥變量,當需求總量大于車輛本身載重時,需要計算部分需求點的距離,此時C為1,C′為0;否則,當載重量滿足時,只需計算兩個倉庫之間的距離,此時C為0,C′為1.K表示所有需求點的集合.jk,(j+1)m分別表示倉庫j與倉庫j+1之間的兩個需求點,且假設每兩個倉庫點之間的k,m取值各不相同,其值根據適應度算法動態生成.多源多點問題的配送路徑優化問題有以下約束條件:
1)存在多個倉庫j1,j2,j3,···,jn,其存儲的產品種類分別為h1,h2,h3,···,hn.
2)各個需求點對不同種產品的需求總和不超過其存儲總量:
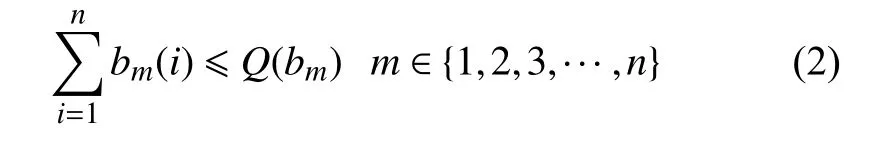
3)車輛的裝載重量不超過該車型的最大載重量
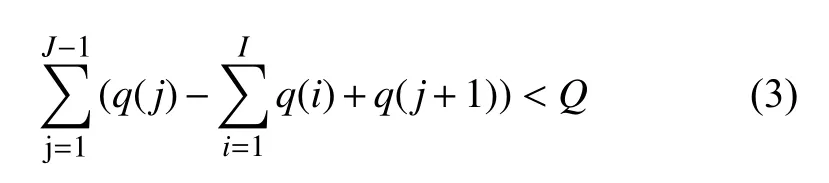
其中,I表示倉庫j到倉庫j+1之間的需求點總數量.q(i)表 示需求點i的需求量.當車輛到達下一個倉庫時,假設上一個倉庫與下一個倉庫之間需求點的貨物需求總量小于該車的最大載重量.
4)倉庫只經過一次.

cj表示倉庫經過的次數.源于貪心策略和現實運輸情況,這里規定倉庫只經過一次,即將所有需求點對此倉庫存儲的貨物需求總量一次性裝車,減少其配送成本.
5)每個需求點經過次數最少一次且不能超過兩次.

ci表示需求點經過的次數.需求點每多經過一次,其成本多增加一份,因此這里規定需求點最少經過一次且不能超過2次,若需求總量大于車輛本身載重且此需求點適應度值較高,允許經過一次部分卸貨以減少需求點的總量,之后第二次經過時滿足剩余需求.否則,只允許經過一次且滿足此需求點所有種類的貨物需求.
3 對模型求解
3.1 編碼方式
遺傳算法的進化過程是建立在染色體編碼結構基礎上的,編碼的好壞對算法的性能有很大的影響,相比二進制0-1的編碼方式,自然數編碼更加直觀,簡潔,尤其在多源點,多目的地的求解問題中更具優勢.因此,本文采用自然數編碼.其編碼方式如下: 每個需求點編碼都大于0,其編號分別為 1,2,···,n;表示形式為r1,r2,···,rn;每個倉庫的編碼都不大于0,其編號分別為0,-1,-2,···,m,表示形式為s0,s1,s2,···,sm.
通過預定義數組的方式定義倉庫所在城市,當檢測為倉庫時,將編號值取反作為數組下標來獲取相應的倉庫城市.具體的染色體編碼表示如圖2所示,其中t,k,p表示待定需求點,由具體的函數動態計算確定.

圖2 染色體編碼
3.2 初始種群的產生
遺傳算法的初始種群對最終解的優劣有很大的影響,選擇合適的初始種群并確定合理的規模大小是很必要的,因此,本文采用了如下方法來產生初始種群并繪制了產生初始種群的流程圖如圖3所示.
1)首先,計算出所有目的地的需求總量與汽車載重量之間的差值C.
2)將染色體編碼表示為數組chromosome,chromosome中的下標為0的位置為0,表示從某一倉庫出發.
3)使用Random函數生成隨機數,用來檢測下一個到達的點是否為倉庫點.其概率為: 倉庫點數/(需求點數+倉庫點數),當小于此值時,即為倉庫點.
4)當判定為倉庫點時,若為最后一個倉庫點且差值C大于0,轉步驟3)若為最后一個倉庫點且差值C不大于0,則說明汽車載重量已經滿足,執行步驟5);若非最后一個倉庫點且差值C不大于 0,則將剩余倉庫點依次加入數組chromosome并執行步驟5);若非最后一個倉庫點且差值C大于0,判定此隨機數是否已經加入過數組chromosome,即: 是否此需求點已經經過一次,若此隨機數未加入過數組chromosome,則取反加入并計算每個需求點對此倉庫貨物的需求量的和將其加入差值C.若已加入,則判斷相鄰數是否加入,直到找到未加入的倉庫點,并取反加入數組chromosome.當判定不為倉庫時,則重新生成隨機數為下一次到達的需求點.若此需求點已經加入數組chromosome,處理方式與倉庫相同,并將差值C的值減去此需求點需求的值.完成后執行步驟3)繼續查找下一次需要經過的倉庫點或需求點.
5)到此階段說明當前的差值C已經不大于0,后續只需要在各個需求點之間尋找一條最優路徑即可.
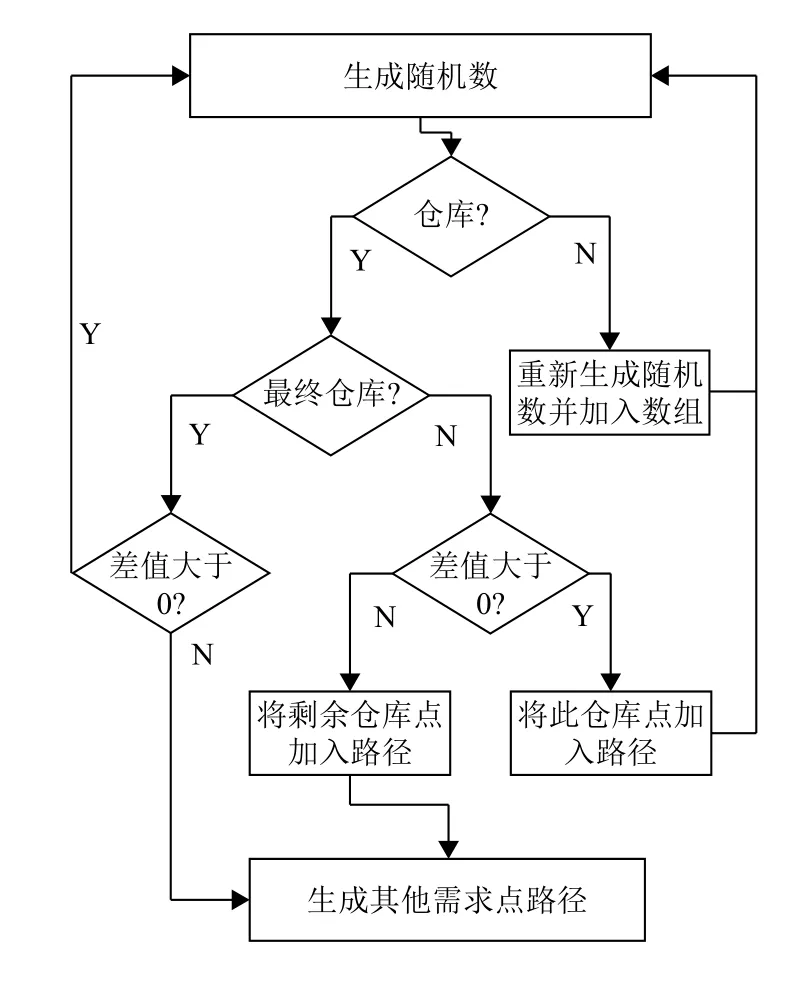
圖3 產生初始種群的流程圖
3.3 適應度函數的確定
在遺傳算法中,適應度函數是遺傳操作的重要衡量指標,依賴適應度函數值進行區別種群個體的優劣,適應值越大說明染色體性能就越好,反之越差.因此,適應值越高被選擇進入下一代的機會越大,本文適應度函數的模型建立分為以下兩種情況:
1)當車輛由倉庫到達第一個需求點時的適應度函數如下:
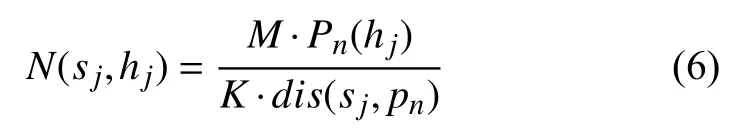
式中,N(sj,hj)表示適應度值,M表示需求量的闕值,K表示距離的闕值,Pn(hj)表示需求點n對 貨物hj的需求量,dis(sj,pn)表示倉庫sj到需求點pn的距離.
2)當車輛離開第一個需求點轉至下一個需求點(或倉庫)時適應度函數如下:
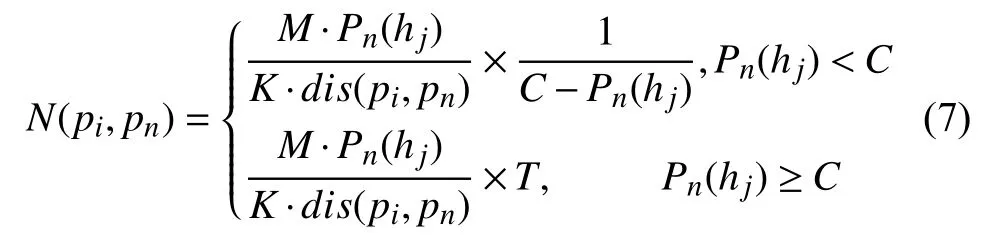
其中,C表示其需求總量與車輛載重之間的差值,T為常數,其值大于1,目的是用于提高適應度.
3.4 選擇算子
根據上面確定的適應度函數求出種群中個體的適應值,然后對個體的適應度進行排序,選擇前50%的較優個體進行下一步.采取精英保留策略,把群體在進化過程中迄今出現的最好個體直接進入到下一代中,并將最小適應度的個體淘汰.
3.5 模擬細胞分裂
對于求解本文最佳路徑問題,因每個個體是由多需求點與多倉庫點構成,若使用交叉方式,當交叉兩個個體的需求點或倉庫點時,極易破壞個體的最佳基因片段,因此本文提出了一種模擬細胞分裂的方法產生下一代.細胞分裂是指活細胞增殖由一個細胞分裂為兩個細胞的過程,而在分裂過程中會發生基因重組.因此,本文采用這一方式,將父代個體的全部信息復制到子代個體之中,并在生成子代個體時重組基因序列.其重組規則如下:
1)若只有兩個倉庫點,則隨機選擇兩個倉庫點之間的任意一個需求點,判定其到其他需求點的適應度值,找到適應值最大的需求點,將其與該需求點之后的第一個需求點交換.判定交換后的總適應度值與交換之前的總適應度值大小,若小于交換之前的總適應度值,則舍棄此次基因重組.否則,則標記該需求點,下次重組時若隨機到該需求點,則計算之后的需求點.
2)若倉庫點數大于2,則每個倉庫點之間重復步驟1).
3)對于最后一個倉庫點之后的所有需求點,采用步驟1)的方式判定其重組后的位置.
3.6 選擇變異方式
變異算子的基本內容是通過改變群體中個體染色體的某些基因值,來加快最優解的收斂速度并提高種群多樣性.本文使用交換需求點的方式來進行變異操作,首先生成此個體的變異概率P(n)m,將此概率與設定的總變異概率Pm進 行比較,若P(n)m<Pm,則生成兩個隨機數用來標識兩個需求點并進行交換;否則,進行下一個個體的判定.對于總變異概率,使用階段性的值,即隨世代數越來越大,其總變異概率越來越小,這樣可以確保在種群的最后的階段不會破壞其中的優秀個體.
3.7 結束標識
若種群達到規定的遺傳代數,則結束迭代,否則從選擇算子開始下一輪循環.
4 實驗分析
假設各個倉庫存放的貨物為表1,各個需求點對每種貨物的需求量為表2,各倉庫與各需求點之間的距離為表3,各個倉庫點之間的距離為表4,汽車載重量為3000 kg.

表1 各倉庫存放的貨物類型
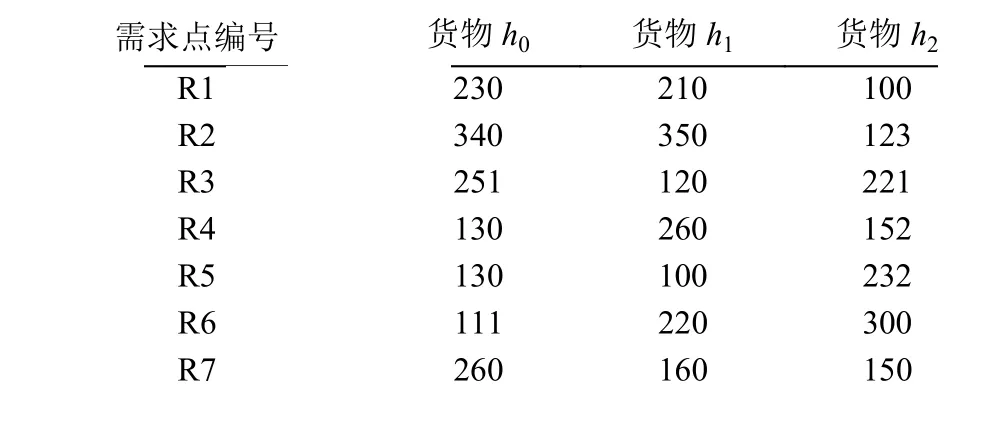
表2 各需求點對每種貨物的需求量(kg)

表3 各倉庫與各需求點之間的距離(km)

表4 各需求點之間的距離(km)
表中倉庫編號s0,s1,s2分別對應城市杭州,南京,合肥.表中需求點編號R1,R2,R3,R4,R5,R6,R7分別對應城市寧波,上海,上饒,南昌,石家莊,濟南,北京.
本文設置初始種群數量為1000,世代數為200,初始變異概率為0.1,通過執行100次仿真運算,從結果中隨機取10次,如表5所示.
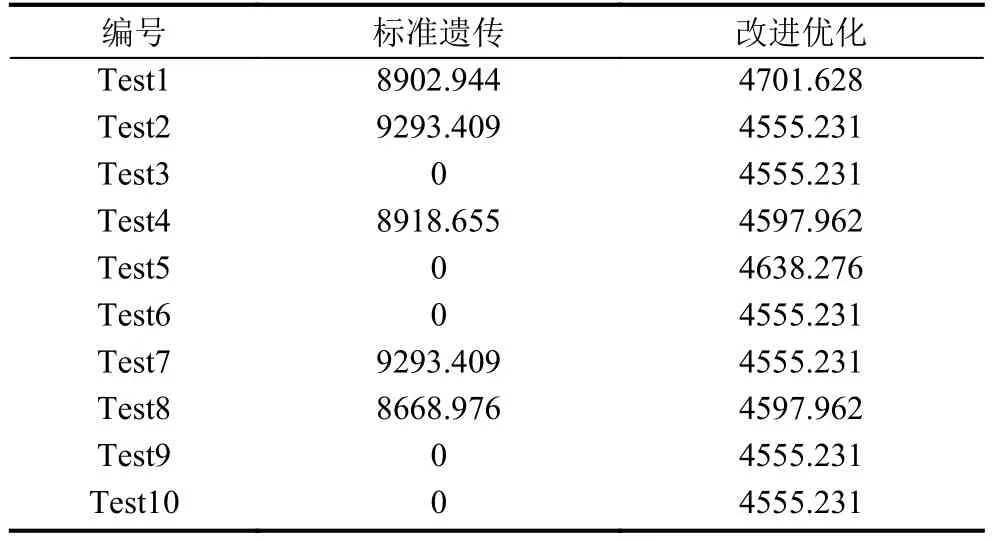
表5 10次測試生成的最短路程(km)
從表5中可以看出在初始種群中使用的隨機數對結果并無較大影響.在第3,5,6,9,10次測試中,其標準遺傳里程為0 KM,原因是標準遺傳算法未考慮重量修正的情況,在最終結果中因不能完成客戶點的需求,導致發生異常退出程序.對應狀態如圖4所示,由圖4得出,改進的遺傳算法比標準的遺傳算法路程減少約一半且10次測試結果變化幅度較平穩,其最短路程為4555.231 KM,生成的路徑如下:s0,s1,R2,R1,R3,s2,R4,R3,R1,R2,R6,R5,R7.對應的城市為: 杭州,南京,上海,寧波,上饒,合肥,南昌,上饒,寧波,上海,濟南,石家莊,北京.
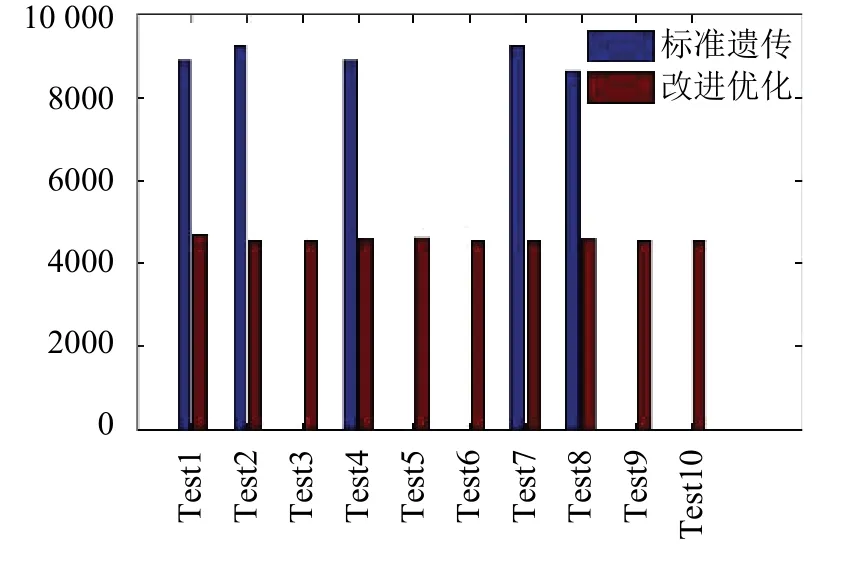
圖4 10次測試生成的最短路程(單位: KM)
圖5為需求總量與汽車載重的差值隨經過城市數的變化圖.由圖5可以分析得出,當汽車經過第4個城市后,其汽車載重量已經滿足需求總量的條件.此時,汽車將前往其他倉庫點裝載貨物,之后按照最佳路徑完成每個需求點的配送.
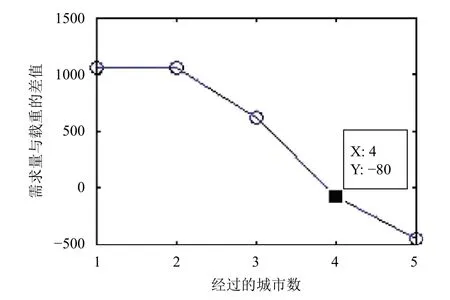
圖5 需求總量與汽車載重的差值隨經過城市數的變化圖
5 結論
在大規模多源多點倉儲物流的配送問題中,因其存在多約束條件和多優化目標,使得優化問題相當困難.本文提出的基于重量修正的物流配送新方式,優化了初始種群的產生,且提出了模擬細胞分裂的方式來產生下一代,有效地避免了傳統遺傳算法中“早熟收斂”等問題,經實驗驗證增強了遺傳算法的收斂速度,在有限的計算能力下,縮短了尋優時間.該算法對于實際運輸中一輛車負載過重多輛車空載率較高問題是一種較好的解決方案.
