基于數據挖掘的醫院綜合評價量化建模方法研究
2019-04-01 13:12:10任嘉駿李心怡薛凱琳
計算機應用與軟件 2019年2期
任嘉駿 李心怡 薛凱琳
(西安交通大學附屬中學 陜西 西安 710043)
0 引 言
每位患者在病情緊急時,多會選擇最近的醫院,但在不耽誤病情的情況下,均傾向選擇治療效果好的醫院[1],那么如何評價醫院的水平以及在多家醫院中篩選出最合適自己的醫院,是絕大數患者所面臨的問題。在我國對醫院實行了分級管理,共分三級十等,美國和澳大利亞等國實行由第三方機構進行的醫院評審制度[2-3]。文獻[4-10]分別就醫院的運行效率、服務質量、學術水平、患者滿意度、績效、科技影響力以及信息化建設等方面進行了建模評價,這些方法從不同的角度為患者就醫時選擇醫院提供參考。對于普通患者來說,最關注的是醫院目前的診療水平,因此,就需要基于醫院現有診療的數據,建立適合的數學模式,對醫院診療水平做出科學翔實評價,為患者就醫提供參考。
基于數據挖掘建立數學模型對醫院水平做出評價,需滿足以下四個假設條件:(1) 各醫院接待的病例情況相同;(2) 在存活病例中,病情嚴重程度與住院時長正相關;(3) 所有醫生對患者病癥判斷準確且使用了(其認為)正確的治療方案;(4) 所給數據足夠完整,數據真實可靠,并且數據量足夠大。
1 基于死亡率的評價模型
在評價一個醫院時,最直接方法就是參考這家醫院的就醫患者死亡率,但由于不同醫院中死亡患者(即所有樣本中死亡樣本)個體差異程度不盡相同,故僅由死亡率評價醫院的醫療水平不夠客觀[11]。因此,需要結合樣本死亡率及死亡樣本個體差異程度對醫院水平做出評價。
1.1 模型準備
影響患者治療效果的因素有患者方和醫院方,評價醫院方診療水平時,就需要把患者方的因素放在同一基準下。影響治療效果的患者方的因素很多,本文篩選出年齡、治療配合程度、經濟狀況、并發癥以及初診病情程度五個最主要的因素,并將各因素進行合理量化。為防止不同因素量化方式的差異對各項目權重計算的影響,故將每因素不同標準量化結果的均值穩定在同一數值(即4)。量化結果數值越大,該因素對死亡的影響程度越大,量化標準及結果如表1所示。
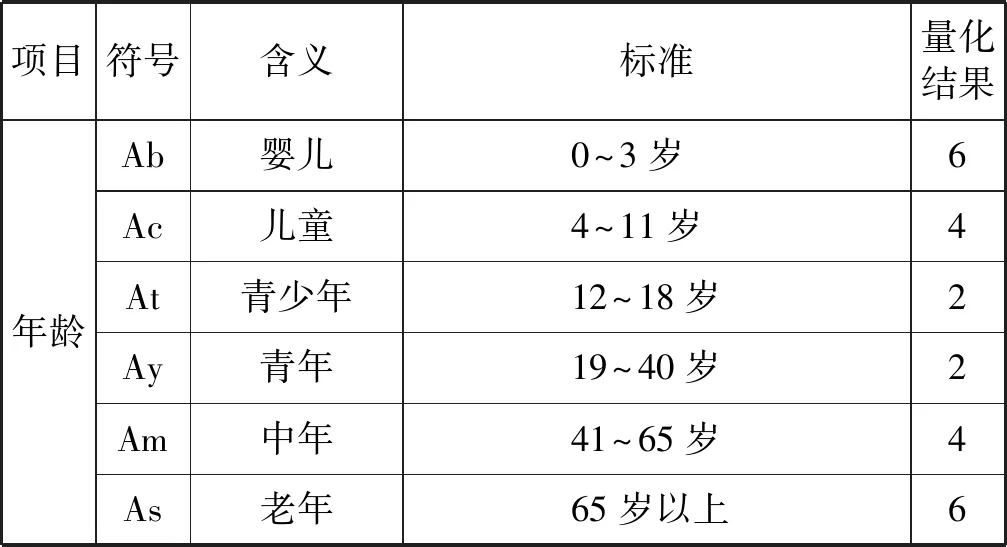
表1 死亡率影響因素量化標準

續表1
1.2 求各因素權重值
患者個體因素對治療后果(即治愈天數和患者死亡)的影響程度(即權值)不同,在擁有大數據前提下,我們將某地區某疾病所有治愈患者的資料每5份為一樣本組假設共分n組,每個樣本組可構成一個5元1次方程組,如下式所示:
(1)
式中:Ai1-Ai5,Di1-Di5,Ei1-Ei5,Ci1-Ci5,Si1-Si5分別表示第i樣本組(i∈n)中每個樣本年齡、治療配合程度、經濟狀況、并發癥以及病情初診嚴重程度的量化值,KAi、KDi、KEi、KCi、KSi分別表示該i樣本組中年齡、治療配合程度、經濟狀況、并發癥和病情初診嚴重程度的權值,Ti1-Ti5分別表示該i樣本組該患者的治愈天數。每一組樣本能計算出一組權值解。并對n組樣本求出的權值計算其平均值,得到年齡、治療配合程度、經濟狀況、并發癥以及病情嚴重程度的最終權值(KA、KD、KE、KC、KS),如對病情嚴重程度的權值KS計算如下式所示:
(2)
1.3 判定樣本死亡可避免性
通過1.2節中已求解出的患者本身因素的權重值,就可求解出不同患者個體J治愈的預期天數TJ,其計算如式(3)所示。式(3)中,AJ、DJ、EJ、CJ、SJ為患者J個體因素的量化值。
TJ=AJKA+DJKD+EJKE+CJKC+SJKS
(3)
將全體已治愈樣本中治愈最長天數作為是否可治愈閾值,計算所評價醫院所有該疾病死亡患者的治愈預估天數,若預估天數大于可治愈閾值,則認為該病人死亡不可避免,否則認為可避免。
1.4 評價醫院單一疾病治療水平
統計評價醫院該疾病L所有死亡樣本中可避免死亡樣本數NL,并計算所占該院該疾病全體就診患者數SL百分比,就可得出該院的此疾病的不當死亡率PL,如下式所示:
(4)
該疾病不當死亡率的PL值越小,則該醫院在該疾病治療方面的評價就越高。
1.5 對醫院的總體評價
在選擇醫院時,人們不僅會考察在對癥治療上醫院的優劣,還會考慮到醫院整體情況,只需計算出該醫院所有疾病不當死亡率的均值作為評價指標。對于專科醫院或科室不全的醫院,只計算其所能接診疾病種類,將各醫院不當死亡率進行升序排序,排名越靠前(不當死亡率P越小)的醫院被認定為越優。
2 基于綜合實力的評價模型
在對一家醫院進行評價的過程中,僅僅參考醫院不當死亡率不夠客觀、全面,應從各個方面對醫院水平進行綜合評價。
2.1 模型準備
在選擇判斷指標時,模型參考了國內對醫院的評價標準和人們通常評價一所醫院的判斷依據,提煉出硬件條件、軟件條件和醫院成果三個方面:(1) 硬件條件包括:衛生情況、設備情況、科室數量、床位數據;(2) 軟件條件包括:醫護人數、診療效果、醫護態度、醫護經驗和患者受關注度;(3) 醫院成果包括:經濟效益和科研成果等11個指標,作為衡量醫院的標準,對所涉及的指標進行量化,表2列出了量化標準的計算方法。
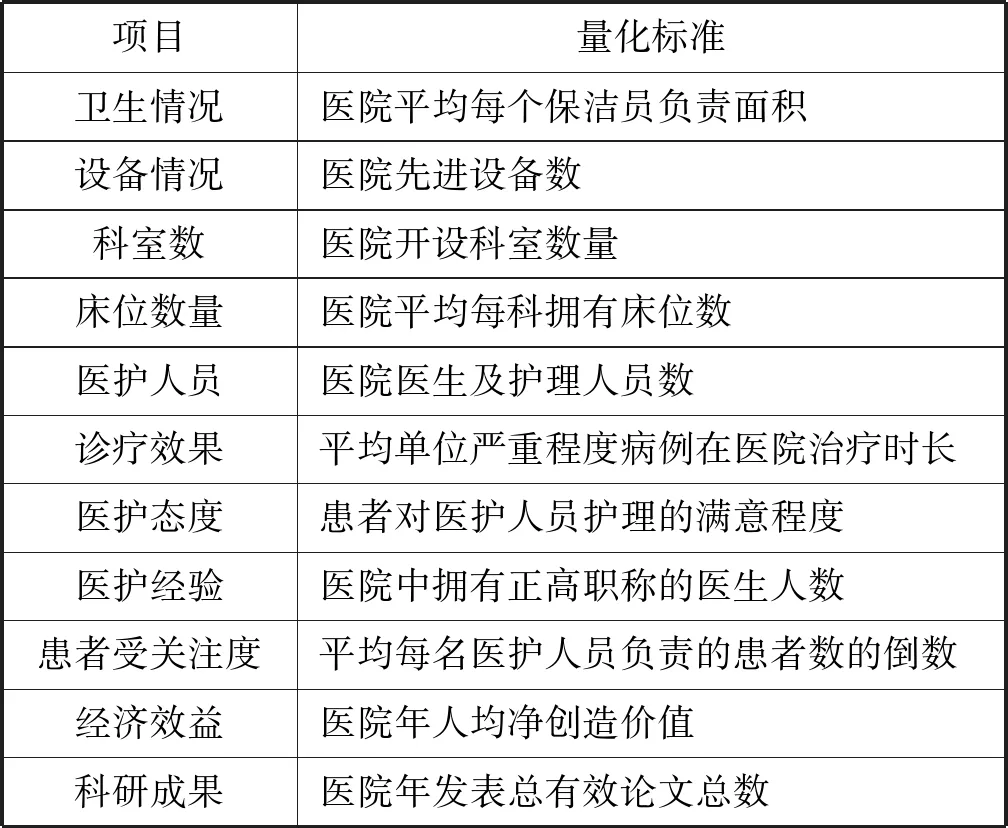
表2 綜合評價模型影響因素量化標準
2.2 主成分分析法求權重
主成分分析法應用于影響因素較多且兩兩影響因素之間有一定相關關系時,可將原來眾多具有一定相關性的變量,重新組合成為一種新的相互無關的綜合變量,大大減少了參與評價的影響因素個數,同時也不會造成信息的大量丟失[12-13]。由于選取了11個指標,為避免在之后的計算中出現歧義,故使用十六進制作為矩陣及變量角標。
根據影響因素的確立及量化,用主成分分析法分別求11個影響因素的權重,令影響因素的權重分別為K1,K2,…,KB。
(1) 將上述K1,K2,…,KB共11個指標重新組合成一組較少個數并且互不相關的綜合指標Fn,代替原來指標,構造出的F1,F2,…,Fn為原變量指標K1,K2,…,KB的第一、第二、…、第n個主成分。(規定:主成分F1所含的信息量最大,在所有線性組合中選取的F1是K1,K2,…,KB所有線性組合中方差最大的,為第一主成分;F2是與F1不相關的K1,K2,…,KB所有線性組合中方差最大的,稱為第二主成分;以此類推)。主成分線性方程如式(5)所示,式中rij(i∈[1,n],j∈(1,B)為每個指標變量的系數矩陣。
(5)
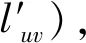
(6)
(3) 由于量綱不同,故對原始數據進行標準化處理,得到標準化數據矩陣,如下式所示:
(7)
(4) 計算得到主成分相關系數矩陣,如下式所示:
(8)
(5) 計算相關系數矩陣R的特征值和相應的特征向量。前n個較大的特征值λ1,λ2,…,λn>0,即為前n個主成分對應的方差;λu對應的單位特征向量au就是主成分Fn的關于原變量的系數。
(6) 選擇重要的主成分。由主成分分析可以得到n個主成分,主成分F1包含的信息大于F2,以此類推,因此各個主成分的方差也是遞減的,包含的信息量也是遞減的,在實際使用時不會選取所有的n個主成分,而是根據各個主成分累計貢獻的大小選取前面m個主成分。此處的貢獻率是指某個主成分的方差占據全部主成分方差的比重,也就是某個特征值占據全部特征值和的比重,如下式所示:
(9)
某個主成分貢獻率越大說明該主成分包含原始信息量越大,主成分m值的選取,主要依據主成分累計貢獻率G來決定,一般來說當累計貢獻率達到85%以上時,可以認為這m個主成分包含了原始信息中絕大多數信息。
(7) 得到主成分公式(得到ruv)。
(8) 依據主成分線性公式得到權重K1,K2,…,KB,如下式所示:
(10)
2.3 對醫院的整體評價
為了避免權值計算時失去實際意義,采用將某醫院中某一項指標加權之后與全體醫院該指標加權之后的平均值進行比較。首先,計算出全體醫院(共計L個醫院)的指標V量化加權后的平均值,如下式所示:
(11)
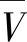
(12)
求出X醫院全部十一個指標的總得分即為該醫院最終得分,如下式所示:
Sx=Sx1+Sx2+…+SxB
(13)
最后,用求出的Sx可較為公正、全面地衡量X醫院的綜合質量。將L個醫院所得的最終得分按大小降序排列,認為排名最靠前醫院是綜合質量最優的醫院。
3 模型檢驗
本文搜集到北京大學第一醫院[14]、中國人民解放軍總醫院[15]、陜西省中醫醫院[16]、北京市海淀醫院[17]四家醫院與評價因素有關的數據如表3所示,因素量化后的數據如表4所示。
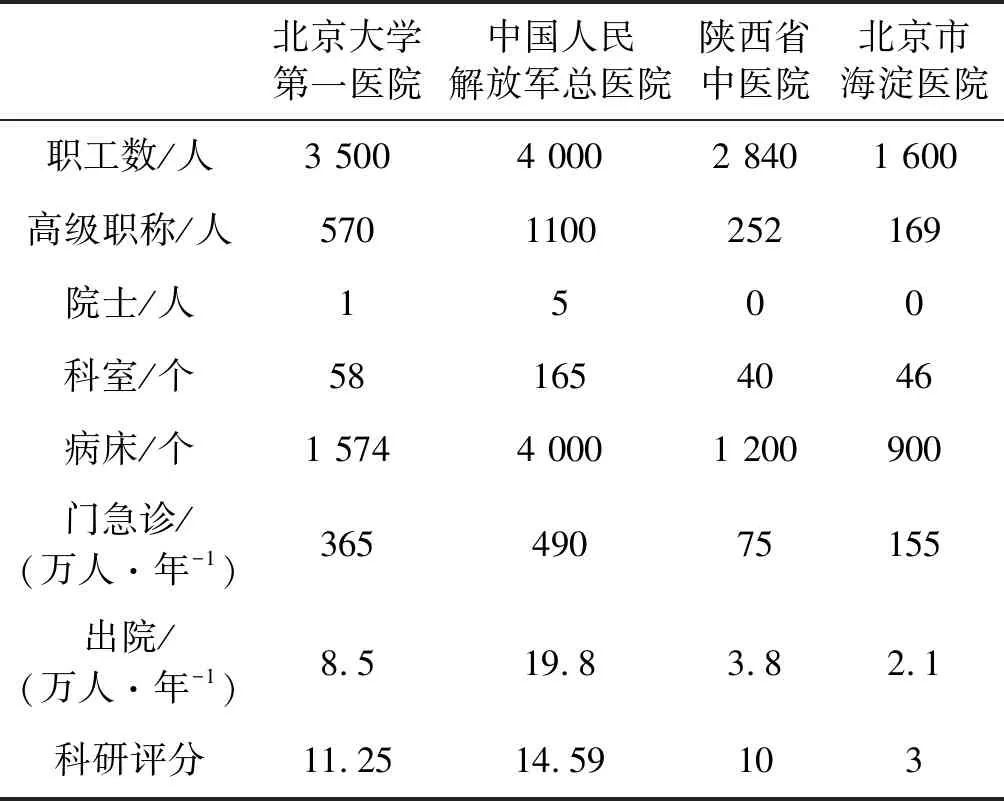
表3 模型檢驗樣本醫院數據表
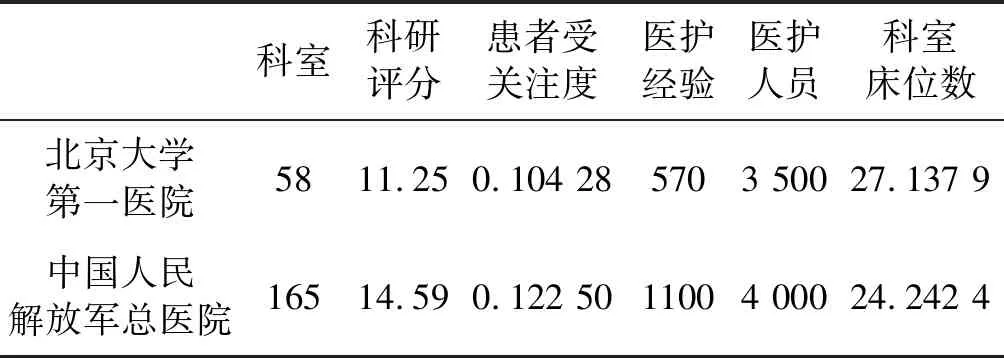
表4 樣本醫院相關因素量化后數據表
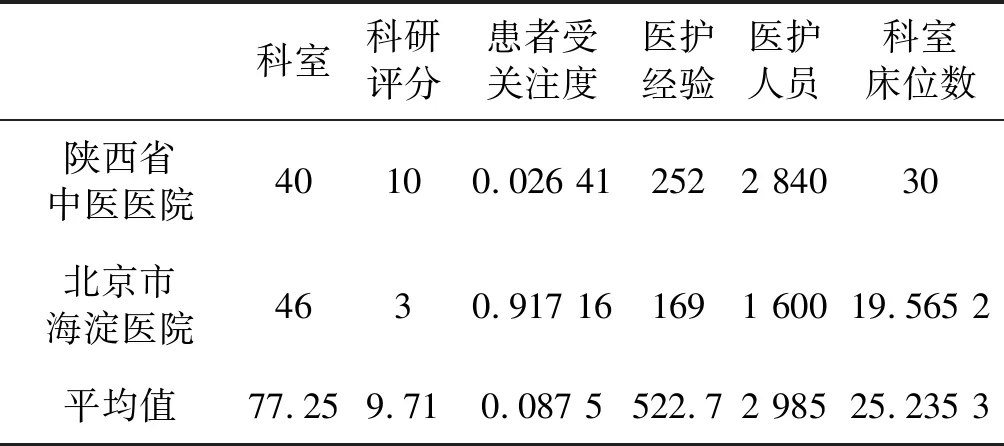
續表4
將表4中的數據,按2.2節中步驟(2)建立初始量化數據矩陣,并對其采用2.2節中步驟(3)進行標準化處理,得到標準化數據矩陣如表5所示。
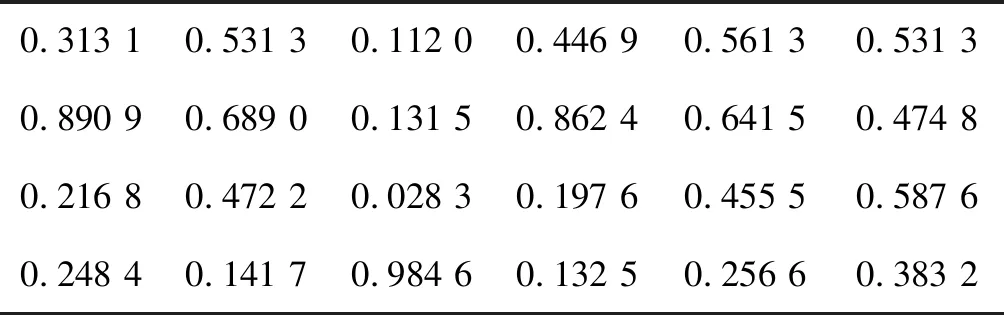
表5 主成分分析樣本醫院標準化數據矩陣
按2.2節中步驟(4)計算得到主成分相關系數矩陣如表6所示。
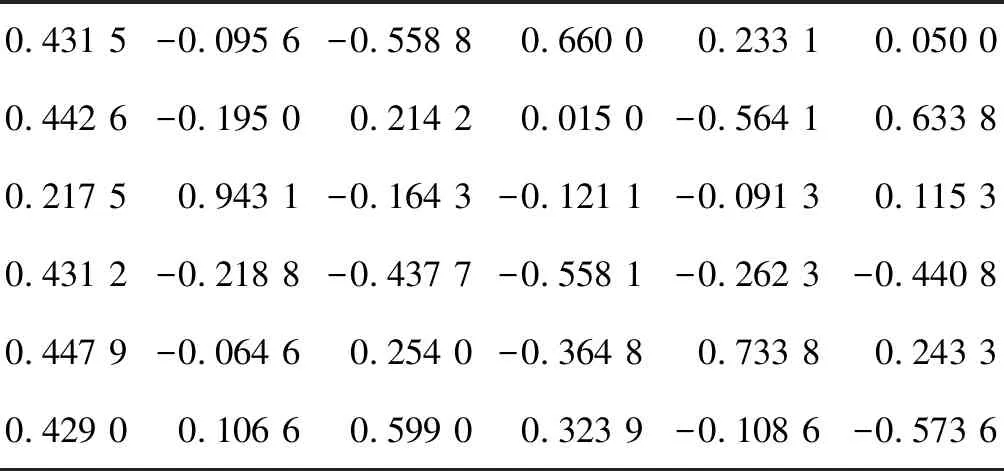
表6 主成分相關系數矩陣
按2.2節中步驟(5)和步驟(6)計算其特征向量、主成分值和主成分貢獻率,其前3主成分的值如表7所示。
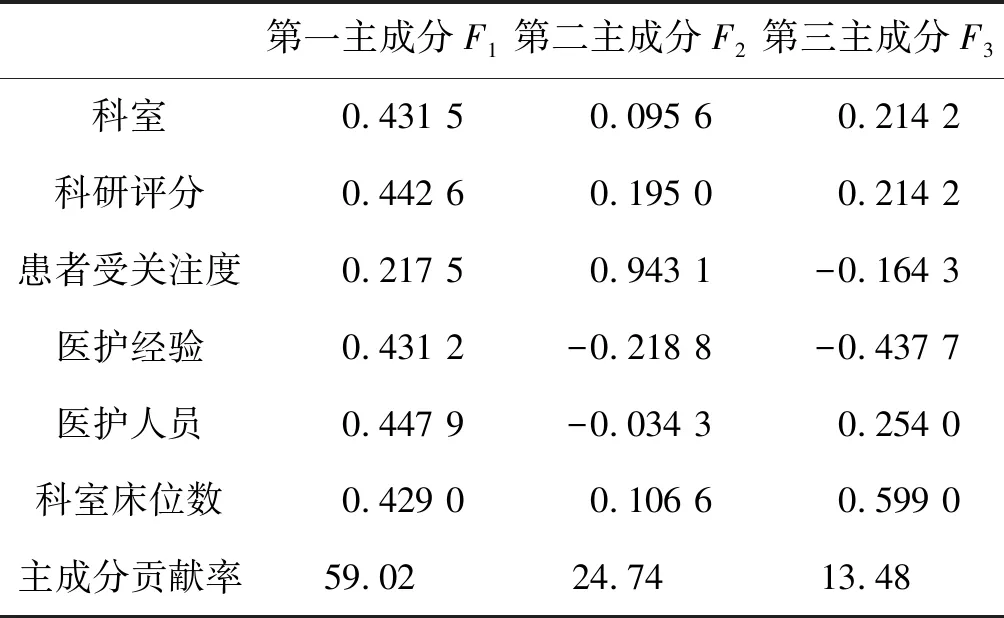
表7 主成分分析法分析出的前3主成分
按2.2節中步驟(7)和步驟(8)計算其各因素權重值,計算出的權重值如表8所示。
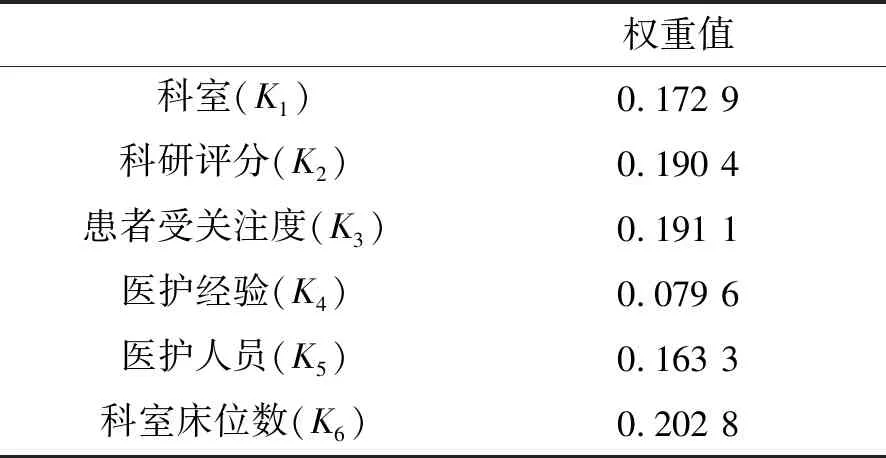
表8 各因素權重值
最后,依據各樣本醫院各因素的量化數據(表4),以及計算的各因素的權重值(表8),計算各因素的分值以及總評分值,計算結果如表9所示。
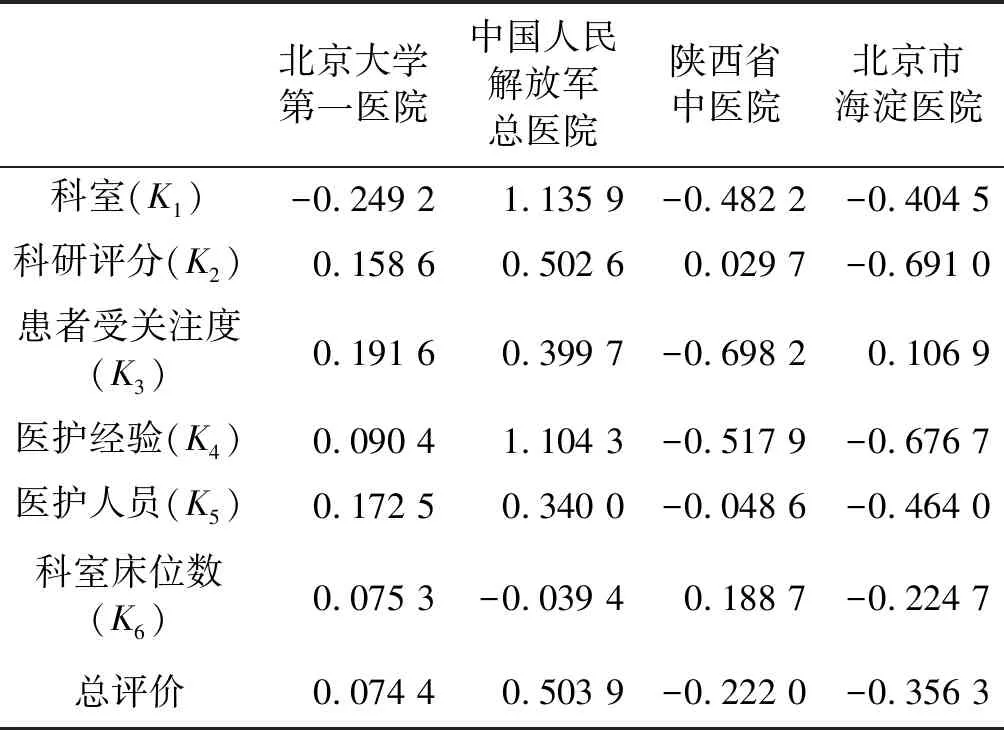
表9 評價醫院總評價計算表
從結果可以看出,中國人民解放軍總醫院的總評價分0.503 9,遠遠高出其他各樣本醫院。其他三所樣本醫院的評價順序由高到低分別為北京大學第一醫院0.074 4、陜西省中醫醫院-0.222 0和北京市海淀醫院-0.356 3。結合復旦大學醫院管理研究所和國家衛生健康委員會對上述四所醫院的等級評定[18],本文計算結果符合醫院診療水平,故認為模型有效。
4 結 語
為解決患者就醫尋找合適醫院難的問題,本文依據醫院診療數據,建立了基于死亡率與綜合實力的醫院評價模型。基于死亡率的模型中,采用“不當死亡率”來評價醫院對某疾病的診療水平,避免患者自身因素對評價結果的影響,但模型存在無法評估醫院在治療非致死疾病水平的問題。基于綜合實力的模型中,采用主成分分析法對評價指標的權值進行了計算,避免了各指標之間相關性的影響,該模型評價結果綜合性和說服力強,但由于計算復雜度等方面限制,仍忽略部分次要因素。
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:36:04
石油瀝青(2021年4期)2021-10-14 08:50:44
當代陜西(2021年12期)2021-08-05 07:45:46
兒童繪本(2018年10期)2018-07-04 16:39:12
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
冰雪運動(2016年4期)2016-04-16 05:54:56
中國衛生(2015年8期)2015-11-12 13:15:20
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
劍南文學(2015年1期)2015-02-28 01:15:15
中國衛生(2014年7期)2014-11-10 02:33:12
