基于云芯一號的分布式文件系統設計與實現*
2019-03-22 08:36:30王界兵王文利董迪馬
網絡安全與數據管理 2019年3期
王界兵,王文利,董迪馬
(深圳前海信息技術有限公司,廣東 深圳 518000)
0 引言
網絡技術的飛速發展帶來了數據量的指數級增長,互聯網傳統的C/S架構(客戶端-服務器)也面臨著各類數據高峰和偶有發生的數據爆炸的挑戰。Google首席執行官于2006年8月9日在SES San Jose 2006搜索引擎大會上首次提出云計算[1]的概念,云計算技術應運而生,其中又以開源的分布式系統架構Hadoop[2]最為著名。自發布后世界上多數互聯網公司和數據庫廠商已支持使用,其中多家公司進行了更高效率的改進和研發[3]。
然而,隨著大數據現代化的逐步推進以及各類大數據處理技術的快速發展,現有的超大數據集甚至大數據集的應用程序在基于原有的低廉、低性能服務器及硬件上的Hadoop架構上的處理效率已大幅度降低。為了解決上述性能耗損的問題,各企業不得不重新購置高性能服務器、部署相關實驗環境,這無疑會帶來新的經濟挑戰和各類資源適配問題。
本文基于上述問題,提出基于自主研發的云芯一號DX硬件加速卡的分布式系統設計,在無需改變現有X86架構上進行硬件擴充和優化,并在此基礎上采用Hadoop分布式文件系統對大量數據進行處理。
1 相關技術簡介
1.1 Hadoop
眾所周知,Google研發的Apache Hadoop是基于Google云計算技術的開源實現,其獨特的分布式架構讓物理隔離上的低廉(low-cost)服務器可以通過互聯網傳輸自身的計算能力,并同時具有高可靠性、高擴展性、高效性、高容錯性、低成本等優點[4]。Hadoop的核心組件主要包括Google GFS、BigTable、MapReduce。其中,Google GFS也同時提供一定程度的容錯功能[5],其開源實現就是分布式存儲模型——HDFS[6](Hadoop Distributed File System)。在完成分布式數據庫和分布式文件系統后,一種分布式的計算模型——MapReduce也應運而生,其運行原理是將需要執行的任務進行分割并分配至各個節點,分配的任務由各個節點分別執行,最后將執行結果合并形成總體計算結果。接下來分別對HDFS和MapReduce兩個組件進行介紹。
1.2 分布式存儲模型(HDFS)
分布式存儲模型HDFS是Google File System(GFS)的開源實現[7]。作為最底層的組件,HDFS的體系結構是一個主從結構,如圖1所示。

圖1 HDFS架構圖
如圖1所示,在HDFS架構中,主節點Namenode只有一個,而從節點Datanode可以有一個或者很多個。主節點作為一個管理的主服務器,系統中文件的命名空間由其來管理,同時各終端對文件的訪問協調工作也由它負責。當存儲的文件通過用戶請求發送到HDFS中時,該文件被分成多個數據塊并將這些數據庫塊并行復制到多個DataNode數據節點中。分割的數據塊大小及數量是在創建文件時由客戶機決定的(可以通過配置進行適宜調整),最終由NameNode主節點來控制所有文件操作。在HDFS中,各類節點都可以部署在配置普通的硬件上,通常運行HDFS的服務器上運行Linux操作系統,其開源的屬性和對Hadoop的友好性是其他系統無法比擬。Hadoop基于最流行的Java語言來開發,且HDFS內部的所有通信都基于標準的TCP/IP協議,最大程度減輕了開發成本和部署成本。
1.3 分布式計算模型(MapReduce)
相比功能較為單一的文件系統HDFS來說,MapReduce則被稱為是到目前為止最為成功、最廣為接受和最易于使用的大數據并行處理技術。
簡單來說,MapReduce中的算法模型就是一種簡化并行計算的編程模型。繼承了分布式的設計理念的MapReduce將具體應用切分為多個小任務,分配至各個節點并行執行,利用集群服務器的并行計算能力來并行處理,完美解決了傳統單機環境中并行能力和計算能力不足的缺點[8]。
MapReduce的主要組成是函數性編程中的Map和Reduce函數,其中Map函數轉換一組數據為Key/Value列表,而Reduce函數則根據Map函數產生列表的Key值來縮減這個列表,再將最終生成的列表應用于另一個Reduce函數,得到相同的結果,具體流程如圖2所示。
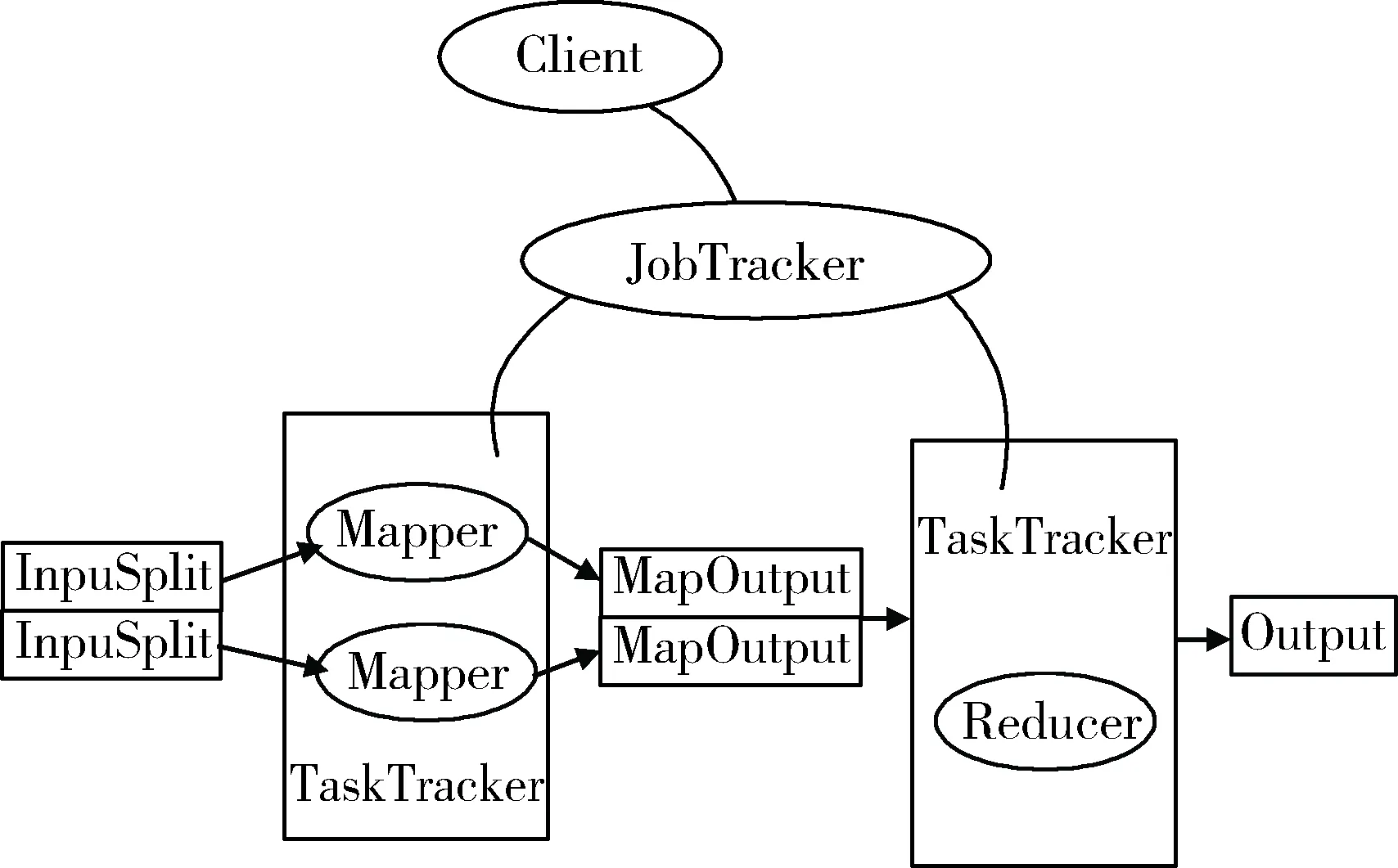
圖2 MapReduce數據處理流程圖
MapReduce中的每個元素都是被獨立操作的,且原始列表沒有被更改,然后再創建了一個新的列表來保存新的答案。基于以上原理,Map操作是可以高度并行的,這對高性能要求的應用以及并行計算領域的需求非常有用。而化簡操作指的是對一個列表的元素進行適當的合并。
2 云芯一號——DX SDK硬件加速卡
云芯一號是一張我們擁有自主知識產權的硬件加速卡,可以使用任何可用的12V PCle插槽供電,如圖3所示。云芯一號支持8路雙工收發器,可插入x8或更大的PCle 3.0插槽。所有和云芯一號之間的通信都通過PCle接口進行。

圖3 云芯一號硬件加速卡
在軟件架構方面,云芯一號主要由以下幾個軟件模塊組成,如圖4所示。

圖4 云芯一號軟件架構圖
具體結構如下:
(1)服務助理基礎設施(SAI):為其他模塊提供基礎服務。SAI由OS抽象層(OSAL)、日志和文件解析器組件組成。
(2)API層:云芯一號提供Raw加速(原始)API來連接用戶應用程序。Raw Acceleration API利用云芯一號上的所有功能,包括壓縮、加密、認證、RNG和PK操作。
(3)Frontsurf服務框架:Frontsurf Service Framework(FSF)為API層提供算法加速。所有與芯片組無關的代碼都位于FSF中,而所有與芯片組相關的代碼位于設備專用驅動程序中。FSF模塊管理所有使用設備特定驅動程序注冊的會話、密鑰和設備,從而實現硬件加速和軟件庫操作。FSF從API層檢索操作,將這些操作轉換為硬件命令,將命令提交給硬件,檢索完成的命令,并將完成的操作返回給API層。FSF還管理負載平衡、會話上下文和密鑰池。如果硬件不可用于數據操作,則FSF與軟件庫一起工作以提供軟件支持以進行各種操作,例如壓縮、認證、加密和PK操作。
(4)設備專用驅動程序:設備專用驅動程序(DSD)是一個與芯片組相關的模塊。設備專用驅動程序為Exar服務框架(ESF)提供統一的硬件接口。DSD將每個設備的特定結構格式轉換為ESF的統一結構。
目前,云芯一號支持用于XR9240協處理器的DSD,用于軟件庫的DSD以及用于傳統820x處理器的DSD。DSD的單個實例將管理系統中安裝的該類別的所有設備。
(5)軟件庫:軟件庫執行軟件中的壓縮、認證、加密和公鑰操作等操作。如果云芯一號發生錯誤或正在從錯誤中恢復,或者系統中沒有可操作的Exar設備,則軟件庫將作為設備特定的驅動程序來實現,以模擬硬件。
3 基于云芯一號的分布式文件系統
在分布式文件處理系統中,文件的存儲和傳輸性能是由組成該存儲系統的多個模塊相互作用所決定的。而傳統HDFS中,文件在存儲前并不會進行相關的壓縮,即使有也是依賴CPU進行軟壓縮處理。在基于云芯一號的分布式文件處理系統中,對文件進行分布式存儲前,將使用云芯一號對文件進行硬件壓縮,在大幅度減少了文件大小的同時避免了傳統存儲過程中因需要對文件壓縮而產生的CPU額外使用壓力。另外,通過硬件上的獨立壓縮,文件的安全性和完整性上也得到了穩定的提高。顯然,壓縮后的文件在磁盤中IO時間、HDFS的各個節點之間的傳輸時間得以大幅減少,其架構圖如圖5所示。

圖5 基于云芯一號的分布式文件系統
具體流程包括:
(1)客戶端將需要存儲的文件發送給云芯一號進行壓縮處理。
(2)云芯一號返回壓縮處理后的文件給HDFS Client。
(3)Client調用DistributedFileSystem的create方法創建一個新的文件。
(4)DistributedFileSystem通過RPC調用Name Node節點上的接口,創建一個沒有blocks關聯的新文件。創建前,Name Node會做各種校驗,如果校驗通過,Name Node就會記錄下新文件,否則就會拋出IO異常。
(5)前兩步結束后會返回FSDataOutputStream的對象,FSDataOutputStream被封裝成DFSOutputStream,DFSOutputStream可以協調Name Node和Data Node。客戶端開始寫數據到DFSOutputStream,同時DFSOutputStream會把數據切成一個個小packet,然后排成隊列data queue。
(6)DataStreamer會去處理接收data queue,它先問詢Name Node這個新的block最適合存儲的在哪幾個Data Node里,把它們排成一個pipeline。
(7)DFSOutputStream還有一個隊列叫ack queue,也是由packet組成的,等待Data Node的收到響應,當pipeline中的所有Data Node都表示已經收到的時候,akc-queue才會把對應的packet包移除掉。
(8)客戶端完成寫數據后,調用close方法關閉寫入流。
(9)DataStreamer把剩余的包都刷到pipeline里,然后等待ack信息,收到最后一個ack后,通知Data Node把文件標示為已完成。
4 實驗對比
通過上文描述,完成了基于云芯一號的分布式系統的設計和實現。接下來通過純壓縮測試對比實驗和HDFS數據存儲速度對比實驗來驗證所提出的分布式文件系統的性能和優越性。
4.1 純壓縮測試
純壓縮測試是為了對比傳統的基于CPU的各類HDFS軟壓縮特性和基于云芯一號芯片的硬件壓縮能力。為此測試了一組隨機大小(從最小數據大小7.27 MB到最大數據大小100 MB),總共88 132 MB的數據集的壓縮速度,測試環境如下:CPU:Intel(R) Core(TM) i5-4590 CPU @ 3.30 GHz;MEM:DDR3 -1 333 MHz 64 GB。
基于云芯一號的硬件壓縮的進程壓縮速度在1 508.7 MB/s(>1 500 MB/s)。與此同時,也將該數據集在傳統HDFS上的各類軟壓縮軟件上進行了相同實驗,得到壓縮性能對比表如表1所示。
從表1可以清楚地看出,基于硬件加速的云芯一號芯片在同樣大小的原始文件上,無論是壓縮速度、解壓速度還是壓縮后的文件大小都占據絕對的優勢地位,尤其是壓縮速度和解壓速度兩個指標更是較普通的軟件壓縮高10倍左右。為了更直觀地體現壓縮速度的對比性,將測試的隨機大小文件集群的壓縮速度進行了同一坐標對比,如圖6所示。
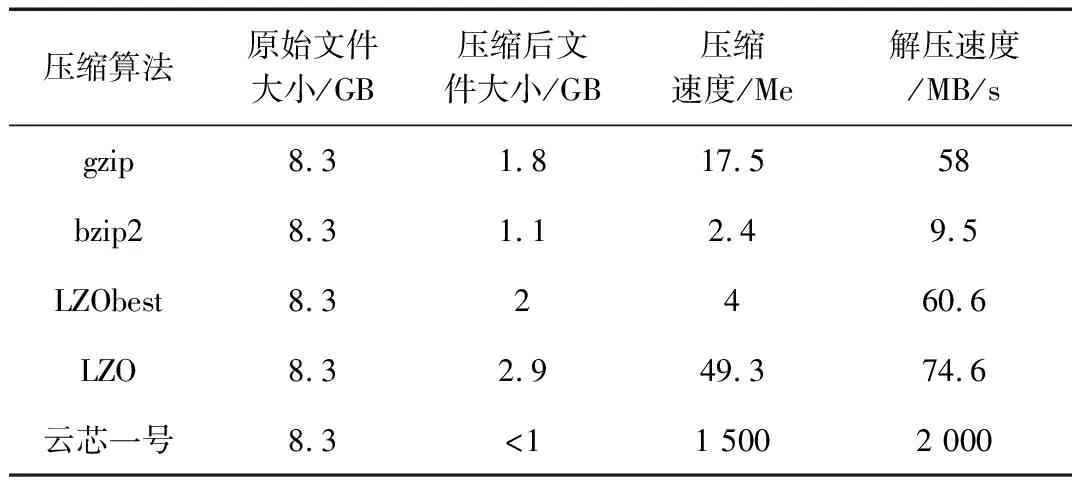
表1 各類壓縮軟件和云芯一號的文件壓縮性能對比
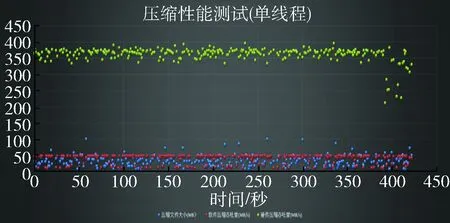
圖6 壓縮速度位于同一坐標上對比
4.2 HDFS寫入和讀取測試
在完成了純文件壓縮對比后,進行了在HDFS平臺下的各類文件基于不同壓縮渠道的寫入和讀取對比測試。
搭建了一個5節點的HDFS平臺,包括一個Client Node、一個Name Node、三個Data Node,其中云芯一號部署在Client Node上。分別測試了10 MB、100 MB、1 GB、10 GB的文件在不同壓縮方法下基于HDFS平臺的寫入和讀取速度,如圖7所示。

圖7 HDFS上基于各類壓縮方式上寫入讀取平均數據對比
選取了各類大小的文件,并測試了其在HDFS上經過各類壓縮方式后的寫入和讀取的速度,然后取其平均值。通過對比可知,基于云芯一號硬件加速卡的HDFS系統在各類大小文件的寫入和讀取速度上都遠遠優于傳統的軟件壓縮方式。從而在分布式文件系統的最基礎的功能上完成了實質性的優化和性能提升。
5 結論
本文著力于提高分布式文件處理的效率和性能,在從數據結構以及算法應用上進行優化外,也思考從數據處理的平臺和依托的硬件環境進行思考和創新。因此,本文提出基于云芯一號硬件加速卡的分布式系統設計,在傳統的X86架構上進行硬件擴充和優化,在此基礎上采用Hadoop分布式文件系統對大量數據進行處理。通過不同環境的實驗結果對比,得出無論是在純文件壓縮上還是HDFS平臺中文件的寫入讀取速度上,本文提出的系統在性能上都遠遠優于傳統壓縮方式,為后續工作帶了更好的創新方向和架構支撐。
