基于偏序拓撲圖的帕金森病語音障礙分析方法
2019-03-18 09:00:26蔣培培張曉娟
中國生物醫學工程學報 2019年1期
張 濤 蔣培培 李 林 張曉娟
1(燕山大學信息科學與工程學院,河北 秦皇島 066004)2(開灤精神衛生中心, 河北 唐山 063001)
引言
帕金森病(Parkinson′s disease, PD)是人類常見的神經退行性疾病之一,目前該病的平均發病年齡是55歲,且發病率隨著年齡的增長而升高[1]。在45歲和65歲以上人群中,帕金森病的發病率分別為0.4%和1.7%。預計到2030年,全球大約將有3 000萬帕金森病人,其中中國大約有1 500萬人。
帕金森病的病因尚未完全明確[2],目前所有針對帕金森病的治療都是控制病情的發展,而無法從根本上治愈。因此,帕金森病的早期診斷無論對于家庭還是社會均具有重大意義。在帕金森病的各種早期表現中,語音障礙為典型癥狀之一,大約90%的帕金森病人會出現某種程度的語音障礙[3],且語音采集可通過電話等多種方式進行遠距離傳輸,易于實現遠程診斷。這使得基于語音障礙檢測的帕金森病診斷方法得到了極大的關注。
2007年開始,牛津大學的Little等對此進行了一系列的研究[4-5],并利用模式識別方法對基于語音障礙的帕金森病診斷進行了分析,奠定了模式識別方法在語音障礙的帕金森病機器診斷中應用的理論基礎。當前信息處理領域的帕金森病語音障礙研究主要集中在數據采集、特征選擇和分類診斷等3個方面。
2007年,Little在信息采集上建立了第一個帕金森病語音障礙數據集OPDD(Oxford Parkinson′s Disease Dataset)[4];2010年,通過電話進行信號采集的遠程帕金森病數據集PTDS(Parkinsons Telemonitoring Data Set)成型[5]。2013年,Betul提出集成元音、單詞與句子的多類型測試方法[6];2016年,Orozcoarroyave在研究中發現英文發音進行檢測的局限性,提出針對西班牙語、德語和捷克語的采集方法[7]等。張濤提出了元音分類度的帕金森病語音采集方法[8],確立了更符合中國人發音特點的語音采集方案。
在特征分析與特征提取上,目前主要有Das等使用粗糙集方法進行特征選擇[9],以及Frid利用卷積網絡的自學習特性進行特征選擇[10]。他們通過對特征的分析和提取,降低數據集的維數并形成分類規則,從而降低分類的復雜度,提高分類結果的邏輯性,為帕金森病數據集從分類向知識發現過渡做了有益的嘗試。
在分類診斷上,基于不同分類原理的分類器被設計出來用于帕金森病數據集的分類。比如:樸素貝葉斯[11]方法、隨機森林方法[12]、支持向量機[5]、神經網絡等均被用于語音障礙的帕金森病診斷。除此之外,Ali利用深度置信網絡將帕金森病的特征選擇與診斷結合起來[13],張濤則利用可視化分析將帕金森病特征選擇、特征融合與診斷融為一體[14],為基于語音障礙的帕金森病的發現奠定了理論基礎。
以上分類器雖然在分類精度上達到了較高水平,但由于其均以概率或測量模型為基礎,難以做到數據的知識性表示。本研究從知識結構的概念分析出發,結合形式概念分析[15-16]中的概念分析方法,提出偏序拓撲圖的可視化層次表示方法,并將其用于帕金森病的語音障礙分析,嘗試從充要條件的角度,將帕金森病語音障礙分析與診斷進行結合,為在認知計算領域進行帕金森病分析奠定基礎。
1 方法
1.1 形式概念分析基礎
形式概念分析以形式背景為分析對象,對其進行定義。
定義1:形式背景可以用三元組K:=(G,M,I)表示,其中G表示所有對象的集合,M表示所有屬性的集合,I?G×M表示對象與屬性之間的關系,G×M表示的是集合G與集合M的笛卡爾積。
定義2:如果K:=(G,M,I)是一個形式背景,A?G,B?M,有
f(A)={m∈M|?g∈A,(g,m)∈I}
g(B)={g∈G|?m∈B,(g,m)∈I}
如果A、B滿足f(A)=B和g(B)=A,則稱二元組(A,B)是形式背景K中的一個概念,并將A稱為概念(A,B)的外延,B稱為概念(A,B)的內涵。
在形式背景表示方法中,屬性拓撲作為一種基于圖論的表示方法,在概念可視化、高速概念計算、關聯規則分析等方面表現出了獨特的優勢,其定義[17-19]為
定義3: 屬性拓撲。對于二值形式背景K:=(G,M,I),其屬性拓撲可以定義為AT=(V,E)。其中,V=M為拓撲的頂點集合,E為拓撲中邊的集合,有
(1)
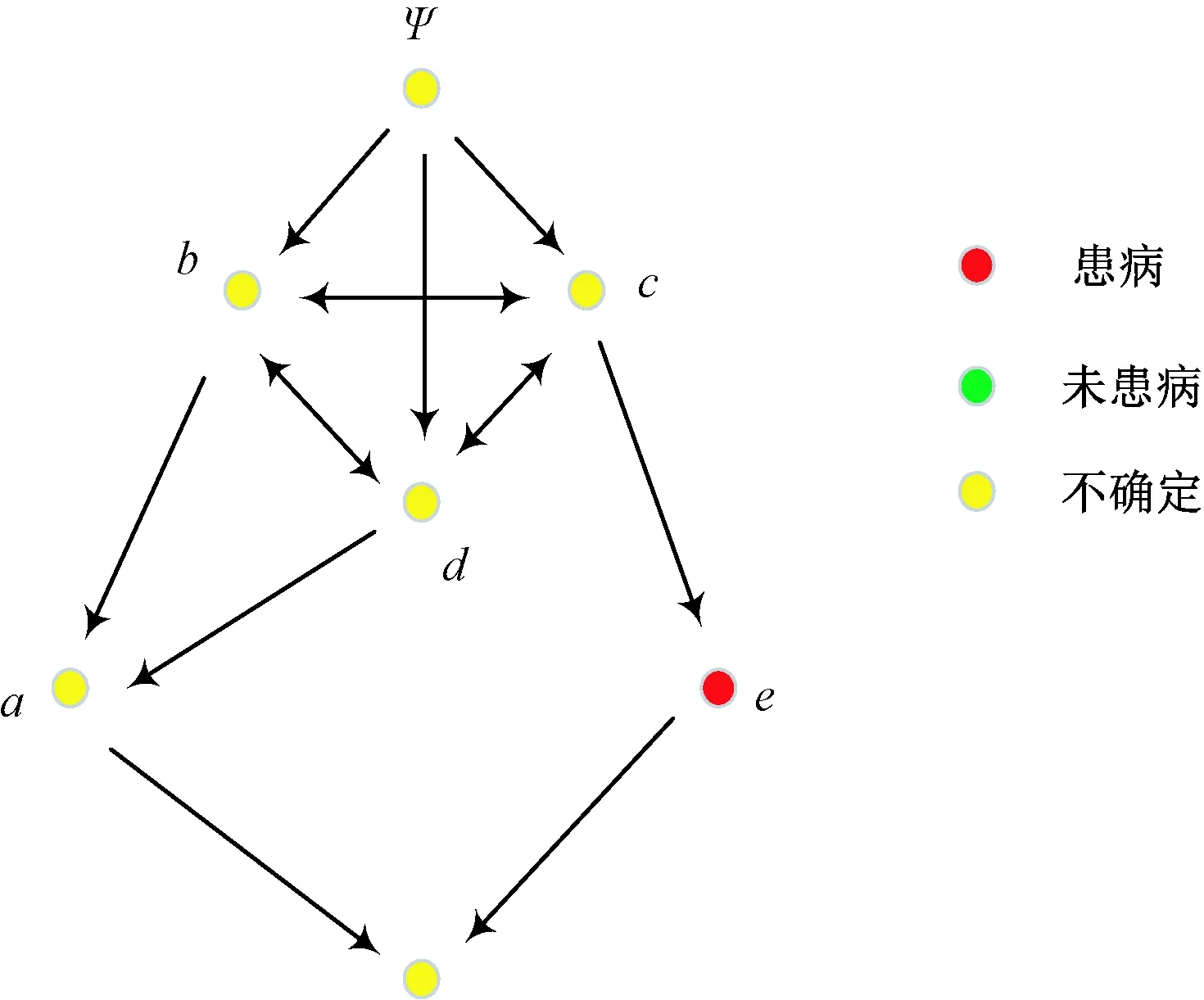
形式背景“急性炎癥”[20](acute inflammations,不含temperature of patient與nephritis of renal pelvis origin項)如表1所示,經過凈化后[21]對應的屬性拓撲圖如圖1所示。在圖1中,由于屬性f為決策屬性,暫不參與運算。
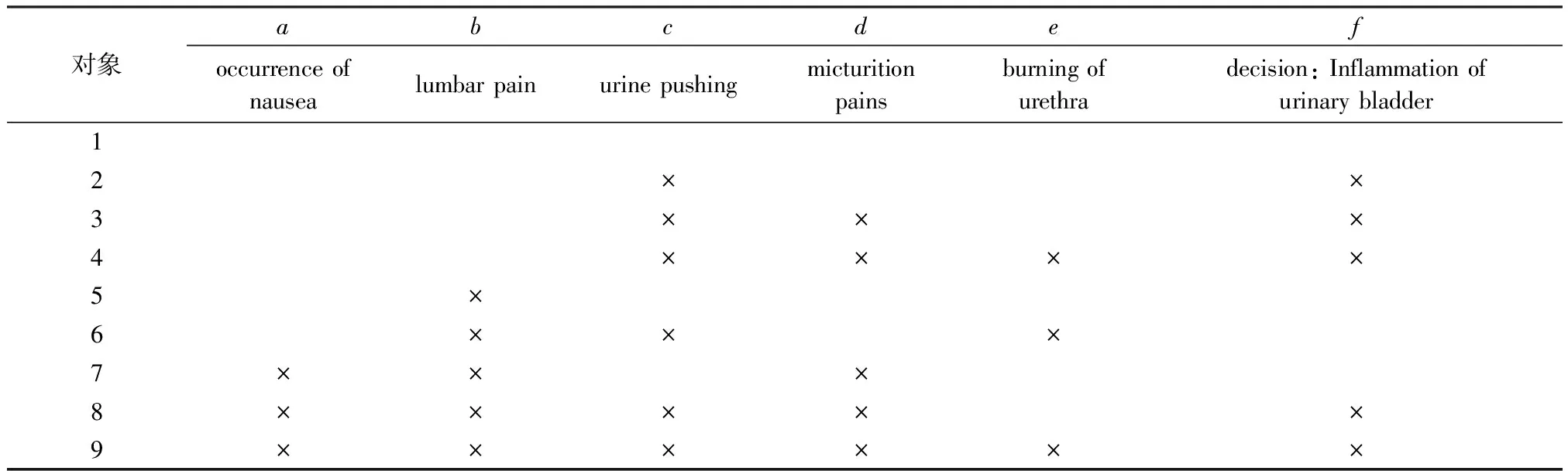
表1 “急性炎癥”形式背景Tab.1 Formal context named “Acute Inflammations”
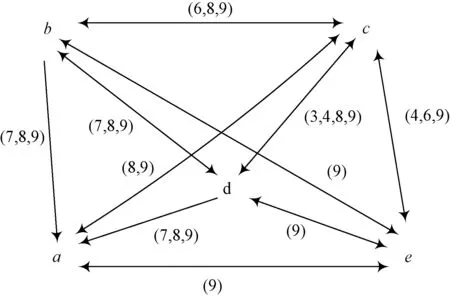
圖1 表1形式背景的屬性拓撲圖Fig.1 Attribute topology of Tab. 1
1.2 偏序拓撲圖表示
屬性拓撲側重于形式概念發現的本體論研究,但由于其連接關系中沒有層次化概念,在知識結構的可視化表示中缺乏條理性。因此,本研究將屬性偏序圖與屬性拓撲圖結合,提出偏序拓撲圖(partial order topological graph,POT graph)的形式背景表示方法,在屬性拓撲本體分析的基礎上突出層次性。
設偏序拓撲圖為PT={Vp,Ep},其中Vp={Ψ,V,E},且Ψ′=A,E′=?。
顯然,在形式背景中,有
?m∈M,Ψ→m
?m∈M,m→E
式中,符號→表示伴生關系[21]。
由偏序理論可知,Ψ為屬性拓撲的上確界,稱為拓撲起點;E為屬性拓撲的下確界,稱為拓撲終點。根據屬性拓撲定義,其與其他頂點集合的權值為
從構造角度,起點Ψ和終點E的引入是為了在屬性拓撲中引入整體偏序特性,為后期的路徑搜索等算法提供明確的開始和結束標記,對知識發現和分類而言不具有實際意義,其加入對于原有的屬性拓撲的性質不構成影響。因此,可對起點Ψ和終點E涉及的連接做修正。
設與起點Ψ和終點E直接相連的頂點集合分別用起點集A和終點集B表示。A和B的選擇有兩種情況,描述如下:
1)不存在伴生屬性,即屬性拓撲中所有的屬性均為頂層屬性。令A=M且B=M,即?mi∈M構造起點到mi的單向出邊和mi到終點的單向出邊,即屬性拓撲的全部屬性既可以作為路徑的起點,又可以作為路徑的終點。
2)存在伴生屬性。令A為頂層屬性集,B為伴生屬性集,即構造起點到各個頂層屬性的單向出邊和各個伴生屬性到終點的單向出邊,可保證每一條路徑均以某一個頂層屬性為起點,以某一個伴生屬性為終點。
除了頂點集合外,由偏序理論可知,偏序過程具有傳遞性,即若存在a→b→c,則有a→c。因此,對于伴生屬性,只需保留伴生關系,其他連接均可不再考慮,即對式(1)修正如下:
(2)
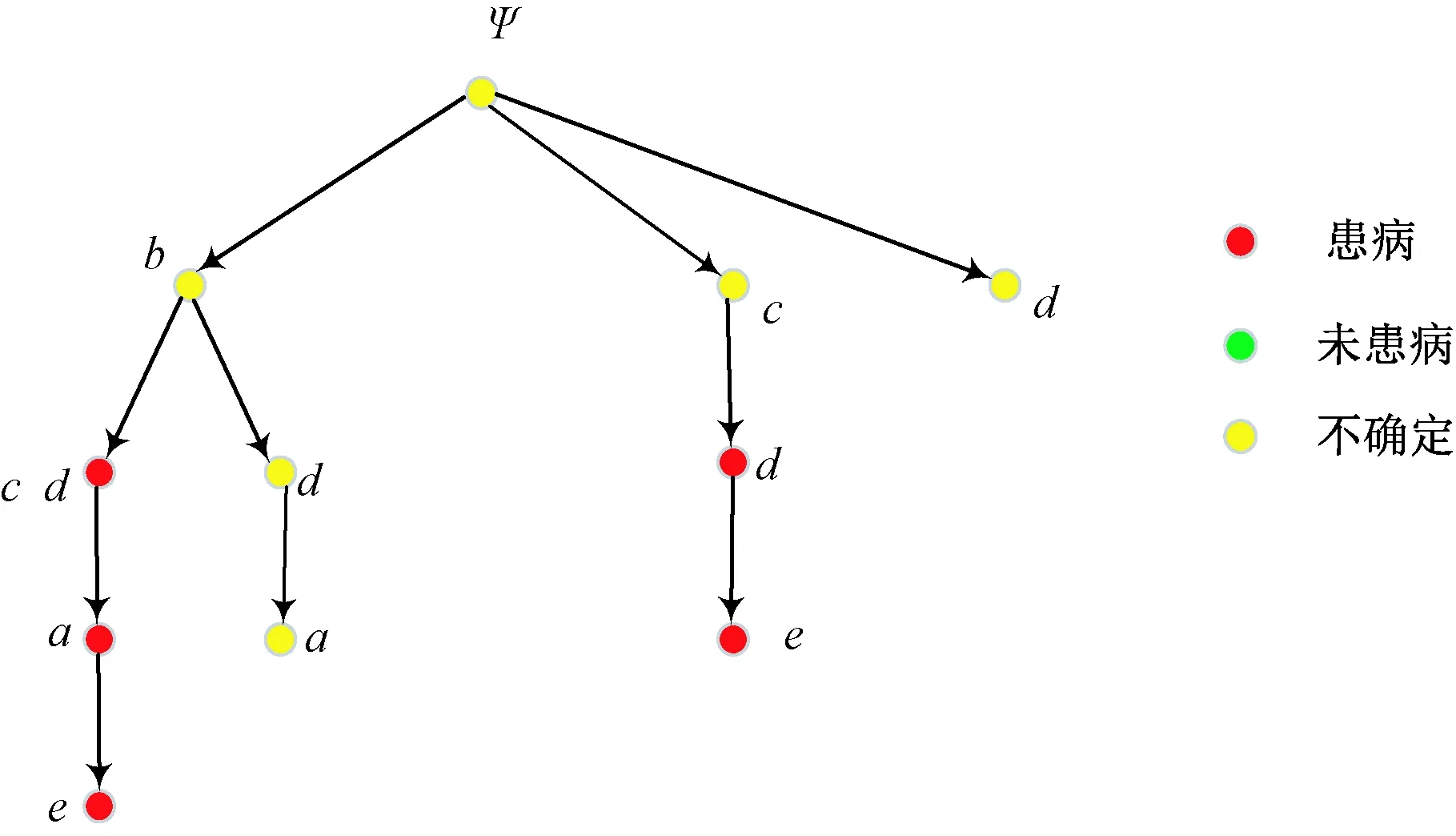
經過偏序化后的屬性拓撲為偏序拓撲,其在保留屬性拓撲基本結構的同時,強化了屬性偏序結構,為將屬性拓撲的本體表示和屬性偏序的關聯表示融合提供了條件。表1形式背景的偏序拓撲表示如圖2所示。
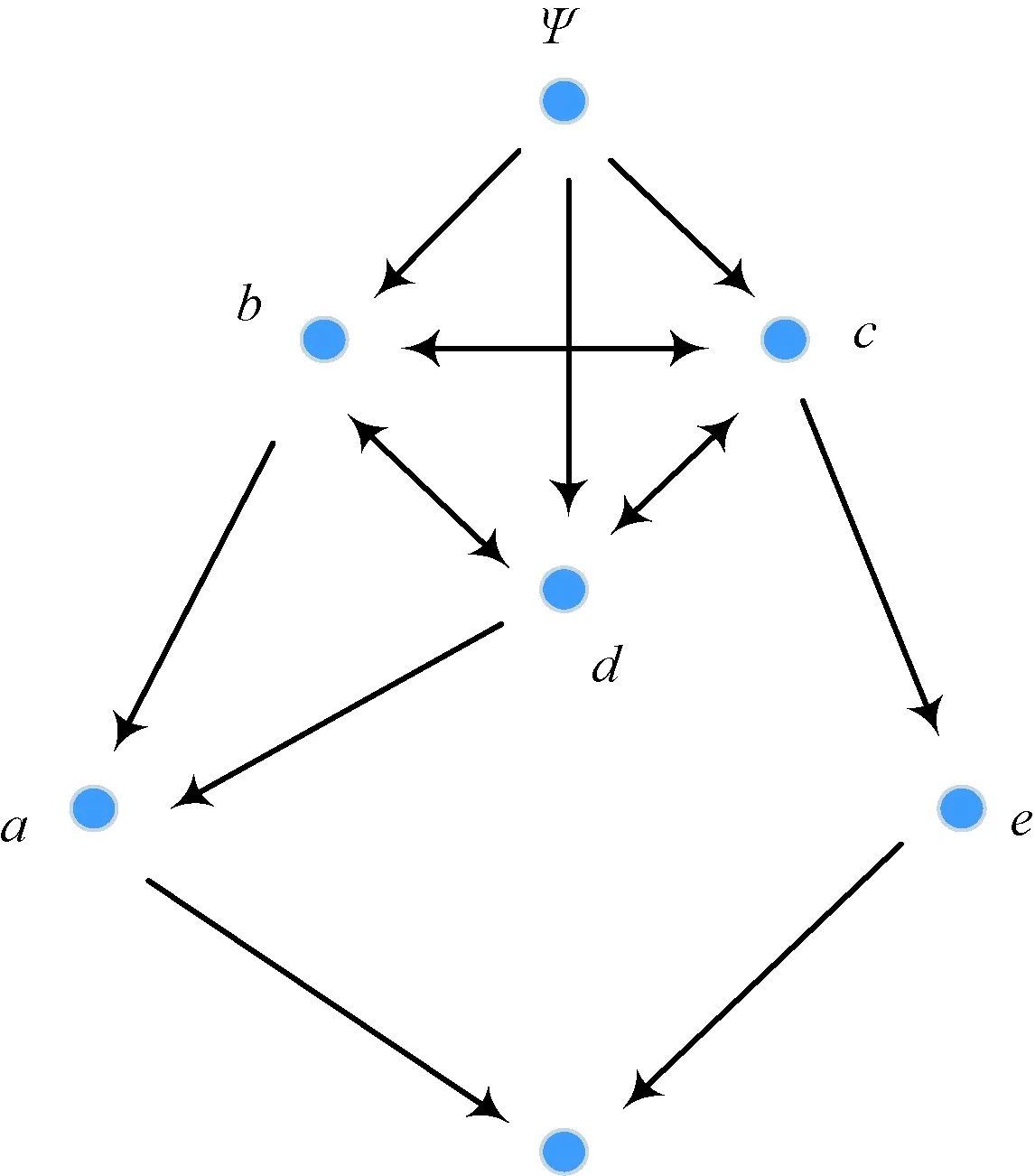
圖2 表1形式背景的偏序拓撲表示Fig.2 POT graph of Tab. 1
1.3 偏序拓撲的關聯規則與本體發現
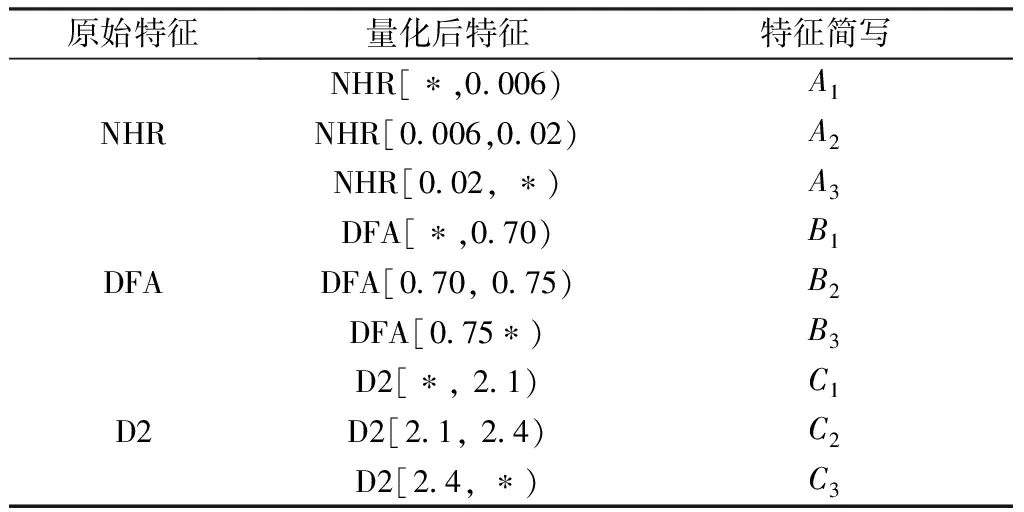
為了提取形式背景的本體,首先需要對偏序拓撲完成形式概念發現。根據屬性拓撲理論,在知識發現過程中,偏序拓撲中的頂層屬性具有獨立成為內涵的能力[17]。對于伴生屬性,根據伴生層次可將其分解為多級伴生關系。根據屬性偏序理論可知,偏序拓撲中相同層的屬性間存在著覆蓋能力區分[22],根據覆蓋能力可將相同層屬性進行排序。在偏序拓撲中,結合其拓撲性與偏序性,設a,b∈M,則其排序規則如下:
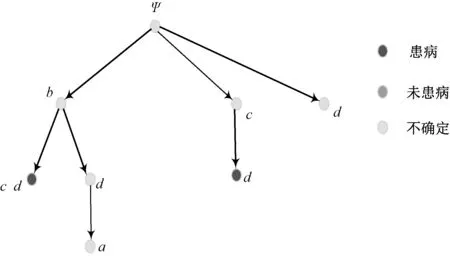
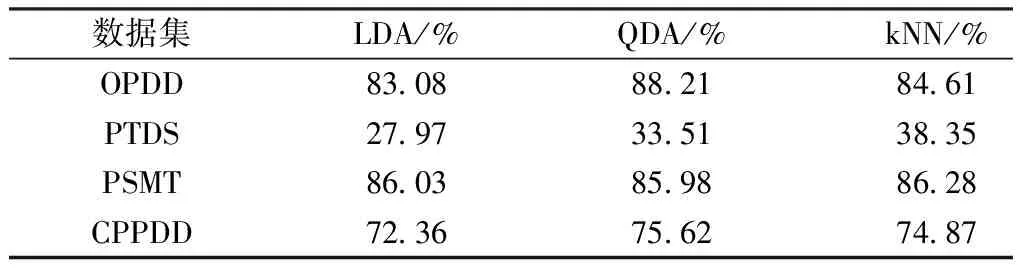
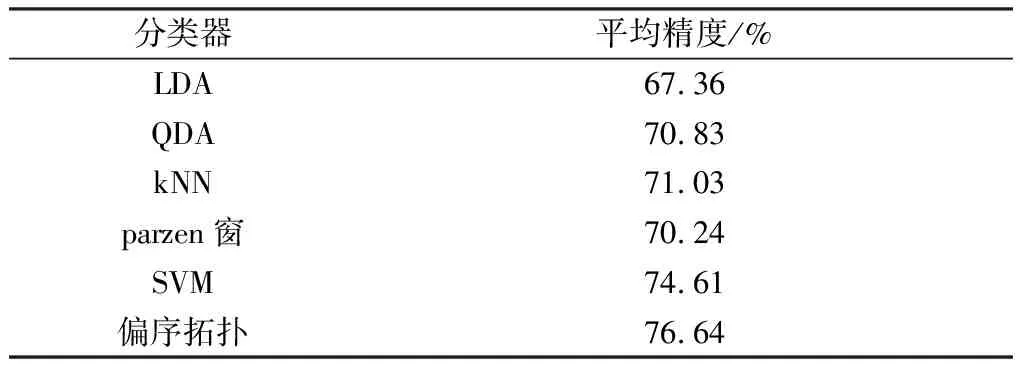
1)若a→b,則Sort(a) 2)若a、b同層且Degree(a)≥Degree(b),則Sort(a) 其中,Sort(*)表示排序后的序號位置。顯然,根據此規則排序后,任意屬性的所有父屬性一定位于該屬性之前。 設屬性集M排序后的集合為M={m1,m2,…,mm}。對于確定頂點排序的偏序拓撲,可通過以下過程完成概念樹的生成。 步驟1:訪問初始頂點v,形成規則樹的根root,并標記頂點v為已訪問。 步驟2:頂點v入隊列。 步驟3:當隊列非空時則繼續執行,否則算法結束。 步驟4:出隊列取隊頭頂點u,形成當前樹的節點Tnode。 步驟5:查找頂點u的第一個鄰接頂點w。 步驟6:若頂點u的鄰接頂點w存在且是非終點屬性,則繼續執行,否則轉到步驟3。 步驟7:若頂點w的父屬性已經存在于T中,則繼續,否則轉至步驟9。 步驟8:將w加入隊列。判斷其加入w后對象集合是否發生變化,若集合不變,則Tnode.data=Tnode.data*w。 步驟9:查找頂點u的w鄰接頂點后的下一個鄰接頂點w,轉到步驟6。 根據以上過程,可生成概念樹表示,圖2的概念樹如圖3所示。在概念樹中,根節點至樹中每一個節點的路徑均為一個形式概念。將概念樹中具有相同意義的節點進行合并,即為經典的概念格表示。 圖3 圖2的概念樹Fig.3 The concept tree of Fig.2 為了便于可視化分類,本研究將可視化模式識別中色度圖理論[23]引入決策形式背景表示,形成類別偏序拓撲表示圖。在該圖中,通過基色與混合色,表示形式背景中類別的傳遞與變化情況,進而直觀表示屬性在分類意義下的可約關系。 以表1所示背景為例,當考慮決策屬性f時形成決策形式背景。在對該決策形式背景進行著色時,設患病采用紅色基色表示,未患病采用綠色基色表示,不確定類別采用黃色,則圖2所示偏序拓撲的著色情況如圖4所示。 圖4 圖2的類別偏序拓撲表示Fig.4 Category POT graph of Fig.2 在類別偏序拓撲中,節點對象集合的關注點由單個對象泛化至對象的類別,是對象集合中類別的分布表示,因此更適合以分類為目的的數據形式化表示。同時,由于類別偏序拓撲關注節點的類別可分性,因此可將屬性分為可分屬性與不可分屬性。 定義1:可分屬性。對于屬性a,若?o∈a′,有oId1,則條件屬性a為決策屬性d1的可分屬性。 定義2:不可分屬性。對于屬性a,若?o1,o2∈a′,有o1Id1且o2Id2,則條件屬性a為不可分屬性。 根據色度圖理論可知,在類別偏序拓撲中,基色節點表示可分屬性,混色節點表示不可分屬性。因此,可通過類別偏序拓撲,直觀觀察形式背景中各屬性的類別分布狀況。在此基礎上,可得如下性質: 性質1:獨有屬性一定是可分屬性。 證明:由可分屬性和獨有屬性的定義可知,獨有屬性必然為可分屬性。 性質2:在偏序拓撲中,若有a,b∈M且a→b,則必有lab(b)?lab(a)。函數lab(·)表示對外延取類別標簽。 證明:對于形式背景的偏序拓撲表示,由其偏序特性可知,若有a,b∈M且a→b,根據伴生屬性定義,則有a′?b′。因此,lab(b)?lab(a)。 性質1和性質2是類別偏序拓撲中關于類別傳遞性的基本描述。由此可知,對于偏序拓撲,自底向上則為普偏性增強過程,自頂向下是特異性增強過程。若屬性a為可分屬性,則對于B={b|a→b,b∈M},均為可分屬性。因此,在自頂向下的分析過程中,對于模式分類,在不考慮數據頻繁模式且關注分類實時性的情況下,可采用自底向上的普遍性增強分類器設計方式。 對于強調數據可靠性的場合,屬性的頻繁度越高,意味著出現瑕疵數據的概率越小,因此可采用自頂向下的方法進行分類規則的提取,以增強分類結果的可靠性。同時,對普遍性高的屬性進行優先處理,符合屬性拓撲理論中的概念搜索思想,可以在分類過程中實現知識發現過程。 對于決策形式背景,可同樣采用色度法對其進行著色。對圖3進行著色后,其表示如圖5所示。 圖5 著色概念樹Fig.5 Coloring concept tree 從認知角度看,概念樹中路徑的集合反映了對當前數據完整的知識學習過程,但從粒計算和分類角度看,則存在著信息的過學習現象。因此,本項目在前期概念追溯思想的基礎上,針對決策形式背景,提出概念樹的約簡過程。 設概念集合C={(A1,B1),(A2,B2),… }是概念(A,B)的直接超概念集合,即對于任意i,有A?Ai等價于Bi?B。因此,集合C在層次序上位于概念(A,B)的上層,可表示為(A,B)≤(A2,B2)。概念(A,B)外延的信息類別為 lA={lab(a1),a1∈A} 因此,lA表示了概念(A,B)中的類別集合。則集合C中每一個概念(Ai,Bi)的外延信息類別可表示為 lAi=uion{lab(a1),a1∈Ai} 若有對于任意Ai,均滿足lAi=lA。從知識意義上看,由(Ai,Bi)(A,B)的屬性增加并未帶來知識容量的增加。因此,可以節點的類別標簽為基礎,完成對概念樹的約簡。結合分類原理,若屬性a→類別ai,則任何包含屬性a的概念必屬于ai類。因此,對于以分類為目的的數據分析過程,步驟7和8可修改如下: 步驟7:若頂點w的父屬性已經存在于T中,則w加入樹T中,其父節點為Tnode;否則轉至步驟9。 步驟8: 判斷加入w后對象集合是否類別唯一。若類別不唯一,頂點w入隊列;若類別唯一,則將w及其伴生屬性在M中刪除。 根據修改后的算法,圖5對應的約簡概念樹如圖6所示。 圖6 約簡概念樹Fig.6 Brief concept tree 由圖6可知,對于急性驗證中膀胱炎(inflammation of urinary bladder)的判斷,可采用有b癥狀(lumbar pain)下c、d癥狀(urine pushing, micturition pains)同時出現或c癥狀(urine pushing)下d癥狀(micturition pains)出現作為診斷依據。 約簡概念樹的形成,在不影響分類和知識發現的前提下,不但節省了數據的存儲空間,同時簡化了計算過程,為基于偏序拓撲的模式分類與知識發現統一框架奠定了理論基礎。在約簡概念樹中,對于可分概念,可以直接進行分類;而對于不可分概念,則可以經過屬性疊加增強其分類性能,或利用主動生長方式[24]進行模糊分類。 表3 CPPDD與國際主流數據集對比Tab.3 Comparison between CPPDD and the classic international datasets 1.5.1帕金森語音概念分析實驗 為了驗證所提出方法對帕金森語音特征在概念提取上的有效性,采用牛津帕金森語音數據集OPDD(http://archive.ics.uci.edu/ml/datasets/Parkinsons)進行數據分析。 在OPDD的22個特征中,通過前期的分析可知,NHR、DFA和D2是最具有代表性的3個語音特征[25]。考慮到數據規模的可表示性,本實驗僅選擇這3個語音特征作為分析屬性。在OPDD數據中,隨機選擇10位測試者,每個測試者選擇一段語音進行NHR、DFA和D2特征分析,患病樣本與健康樣本比例為1∶1。分析集合如表2所示,其中name為受試者語音編號,NHR、DFA、D2分別為受試者語音所提取的特征,status為標簽數據,表明受試者是否患病。 表2 OPDD數據子集Tab.2 Subset of OPDD data 1.5.2帕金森病診斷精度實驗 為了全面測試本方法的有效性,采用多數據集、多分類器對比測試的方法進行。所采用的帕金森病數據集包括當前國際主流帕金森數據集OPDD、PTDS、PSMT(Parkinson Speech Dataset with Multiple Types of Sound Recordings Data Set)和本課題組采集的漢語發音的帕金森病語音數據集CPPDD(Chinese Pronunciation Parkinson detection dataset)。 CPPDD以元音分離度方法為基本方法[8]進行采集。為了滿足采集要求,分別構建了易用性語音采集平臺、語音信號處理工具箱和語音數據管理系統3個基礎工具,其工作界面如圖7所示。 圖7 語音采集平臺軟件界面。(a)語音采集;(b)語音信號處理;(c)語音數據管理Fig.7 The platform software interface of voice acquisition. (a) Voice acquisition; (b) Voice signal processing; (c) Voice data management 數據采集工作主要在唐山工人醫院和開灤精神衛生中心展開,共采集到語音樣本35人,其中帕金森患者20人,健康人15人,男女比例21∶14,年齡分布42~75歲,受試均簽署知情同意書。采集到的原始數據和所提取的特征均保存于數據集中。表3對比了本數據集與當前國際主流帕金森數據集OPDD、PTDS、PSMT。為了對比測試結果,實驗中均采用數據集中的語音特征作為分類診斷依據。 表5 二值化后的帕金森數據集Tab.5 Binarized Parkinson datasets 表4帕金森數據集量化區間及特征簡寫 Tab.4QuantizationintervalandfeatureabbreviationofParkinsondatasets 原始特征量化后特征特征簡寫NHRNHR[?,0.006)A1NHR[0.006,0.02)A2NHR[0.02, ?)A3DFADFA[?,0.70)B1DFA[0.70, 0.75)B2DFA[0.75?)B3D2D2[?, 2.1)C1D2[2.1, 2.4)C2D2[2.4, ?)C3 為了客觀地評價本研究所設計分類器的分類性能,利用LDA、QDA、kNN、parzen窗、SVM等經典分類器作為對比測試方法。不同的分類器在不同的數據集上進行應用,通過對比分類精度,評估本方法與經典方法的性能差異。為了保證測試結果的客觀性,本實驗中的參考分類器均采用PRTools中的軟件包完成。 在表2所示的OPDD數據子集下,利用可視化離散方法[26]對該數據集進行離散化,形成標準的二值形式背景,各特征離散所用的區間及簡寫如表4所示。以表4為量化間隔對帕金森數據進行離散化,形成的二值形式背景如表5所示。 圖8 帕金森數據類別偏序拓撲Fig.8 The category POT of Parkinson data 將離散化后的二值形式背景進行拓撲表示和概念計算,其類別偏序拓撲與類別著色概念樹分別如圖8、9所示。在該圖中,紅色點表示決策屬性status=1(帕金森病患者)對應的屬性,綠色點表示決策屬性status=0(健康人)對應的屬性,黃色點表示該屬性為混合類別,無法判斷結果。為了清晰起見,偏序拓撲并未標注屬性間的具體連接內容,概念樹僅標注了內涵增量組合,并未對外延進行標注。 圖9 帕金森數據類別著色概念樹Fig.9 The category coloring concept tree of Parkinson data 數據集LDA/%QDA/%kNN/%parzen窗/%SVM/%偏序拓撲/%OPDD83.0888.2184.6185.1388.7290.13PTDS27.9733.5138.3540.4141.8750.12PSMT86.0385.9886.2884.5688.9285.98CPPDD72.3675.6274.8770.8778.9280.34 著色概念樹清晰地表明當前數據集下語音特征與帕金森病之間的關系。若受試者D2特征值較小(屬性C1)或NHR中等(屬性A2),可以認為該受試者沒有帕金森病;如果受試者出現NHR較大(屬性A3)、DFA較大(屬性B3)或D2特征中等(屬性C2)時,可認為其患有帕金森病;其他情況(A1,B2,C3)靠單獨一個指標無法確定,需要多個特征聯合判斷。該結論與當前醫學上關于帕金森病語音障礙研究具有一定的吻合度。 在測試本方法的有效性中,基于偏序拓撲圖的帕金森病語音障礙分析和LDA、QDA、kNN、parzen窗、SVM等經典分類器,在不同的數據集上應用的分類結果如表6所示。結果表明,在數據集OPDD、PTDS、CPPDD中,所提出的方法與其他經典方法相比,其分類精度明顯高于其他分類器。在同一分類器下,OPDD與PSMT數據集下的分類精度一般高于CPPDD的分類精度。 為了清晰地表示實驗結果,從數據集和分類器兩個角度進行對比,如圖10、11所示。 基于以上數據結果,不同分類器在不同的帕金森病語音數據集下的平均分類精度如表7所示,其中本研究的基于偏序拓撲圖的帕金森病語音障礙分析的平均分類精度達到76.64%,比其他分類方法中最佳的SVM分類器(74.61%)高出2.72%的診斷精度。 分別從相同分類器下不同數據集的分類精度和相同數據集下不同分類器分類精度,對本研究的實驗結果進行討論。 相同分類器下,不同數據集的分類精度不盡相同。在本研究中,共采用OPDD、PTDS、PSMT 3個英語發音的國際公開數據集和漢語發音的帕金森病語音數據集CPPDD進行分析。 圖10 相同方法下不同數據集的實驗精度對比Fig.10 Comparison of experimental accuracy of different datasets with the same method 圖11 相同分類器下不同數據集的分類精度對比Fig.11 Comparison of classification accuracy of different datasets with the same classifier Tab.7Theaverageclassificationaccuracyofdifferentclassifiers 分類器平均精度/%LDA67.36QDA70.83kNN71.03parzen窗70.24SVM74.61偏序拓撲76.64 OPDD為經典的帕金森病語音數據集,是經過特征提取的帕金森病語音特征集合,也是目前大多數研究人員常用的帕金森病語音數據集。由表6可知,該數據集目前分類精度普遍高于80%,主流的SVM方法達到了88.72%,而本研究的偏序拓撲方法分類精度達到了90.13%。該數據集分類精度高的原因在于其為二分類數據(僅包括健康、患病兩類),且在特征提取之前經過了預處理。 PTDS為遠程采集數據集,語音信號經過電信線路的傳輸,損失了部分具有診斷意義的高頻信息,且該數據集根據帕金森病的患病嚴重程度分為5級。信息損失與分類類別的增加造成了分類困難,故各分類器在該數據集下的表現均不盡人意。與此同時,該數據集的數據混疊為分類器的性能提供了更好的區分條件。在本實驗中,偏序拓撲由于具備局部數據分析能力,使得其分類精度達到50.12%,遠高于其他分類器的分類精度。 PSMT數據集的特點在于其提供的是原始語音與語音特征混合的數據集,因此該數據集可以測試在未經過預處理過程下的分類器對噪聲的敏感程度。偏序拓撲方法對該數據集的分類精度僅達到了平均水平,這主要是由于在數據離散化過程中未能有效去除噪聲干擾,從而降低了數據分類精度。 CPPDD是目前為數不多的漢語發音數據集,且該數據集目前所有語音未經過預處理。從整體上看,對于相同的分類器而言,CPPDD的分類精度要低于英語發音的OPDD與PSMT數據集。這說明,漢語發音的復雜性與帕金森病的診斷精度之間存在一定的相關性,下一步需要針對漢語發音進行專門的算法優化。 綜上所述,對于不同的數據集而言,經過數據預處理的CPDD分類性能最優,能提供語音和特征雙重數據的PSMT次之,漢語發音數據集CPPDD需要進一步地優化算法以提升其整體精度,而PTDS數據集本身的不可分性可用于測試分類器對局部數據的處理程度。結合中國目前帕金森病患病人數的實際情況,針對性地研究漢語為母語的帕金森病語音障礙診斷,無論對于理論研究還是臨床研究均具有重要的意義。 對于同樣的數據集而言,不同的分類方法得到的分類精度不同。由表7可知,本研究所提出的概念分析方法基本達到了主流分類器的分類精度。 橫向分析各分類器的差別,其主要原因在于帕金森數據集為典型的非線性高維復雜數據,因此以LDA為代表的線性分類器無法完成高精度的分類界面描述;而QDA作為非線性分類器,雖然分類精度有所提高,但仍受二次方程的約束;kNN分類器基于樣本的近鄰測量,其分類精度依賴于鄰近樣本的混疊程度,由于帕金森數據集在局部混疊嚴重,因此分類性能一般;SVM作為核方法的代表,因其高維映射的非線性分類特性,使得其在經典分類器中分類性能達到了最優。概念分析分類器作為一種新型分類器,通過離散化過程完成對原有數據的局部化,再通過概念計算過程完成高維非線性映射,且其升維過程并不受核函數等函數形式限制,因此其性能高于經典的SVM分類器,可以獲得更高的分類精度。 綜合以上分析可知,針對帕金森病的語音數據集的非線性特性,需要一種基于非測量機制的非線性分類器進行分類處理。而偏序拓撲本身的局部離散化和概念計算,使得其在帕金森病的語音障礙分類中平均分類精度達到最優。同時,偏序拓撲特有的結構分析特性,為語音障礙與帕金森病間的因果分析與推理奠定了基礎。 本研究針對帕金森病的語音障礙診斷,設計了一種基于偏序拓撲的概念計算分析與分類方法。該方法利用偏序拓撲的層次結構對帕金森病的數據特征進行表示,并利用形式概念分析中形式概念的思想進行特征的二次組合與升維,從而在概念分析的基礎上獲得分類診斷性能。實驗表明,偏序拓撲可以對帕金森病特征進行層次化表示,并且其分類精度與經典分類器相當。 但對于大規模數據集,偏序拓撲在可視化方面仍需精簡,且概念計算本身帶來的時間消耗是本方法的缺點,也是下一步要重點研究的問題。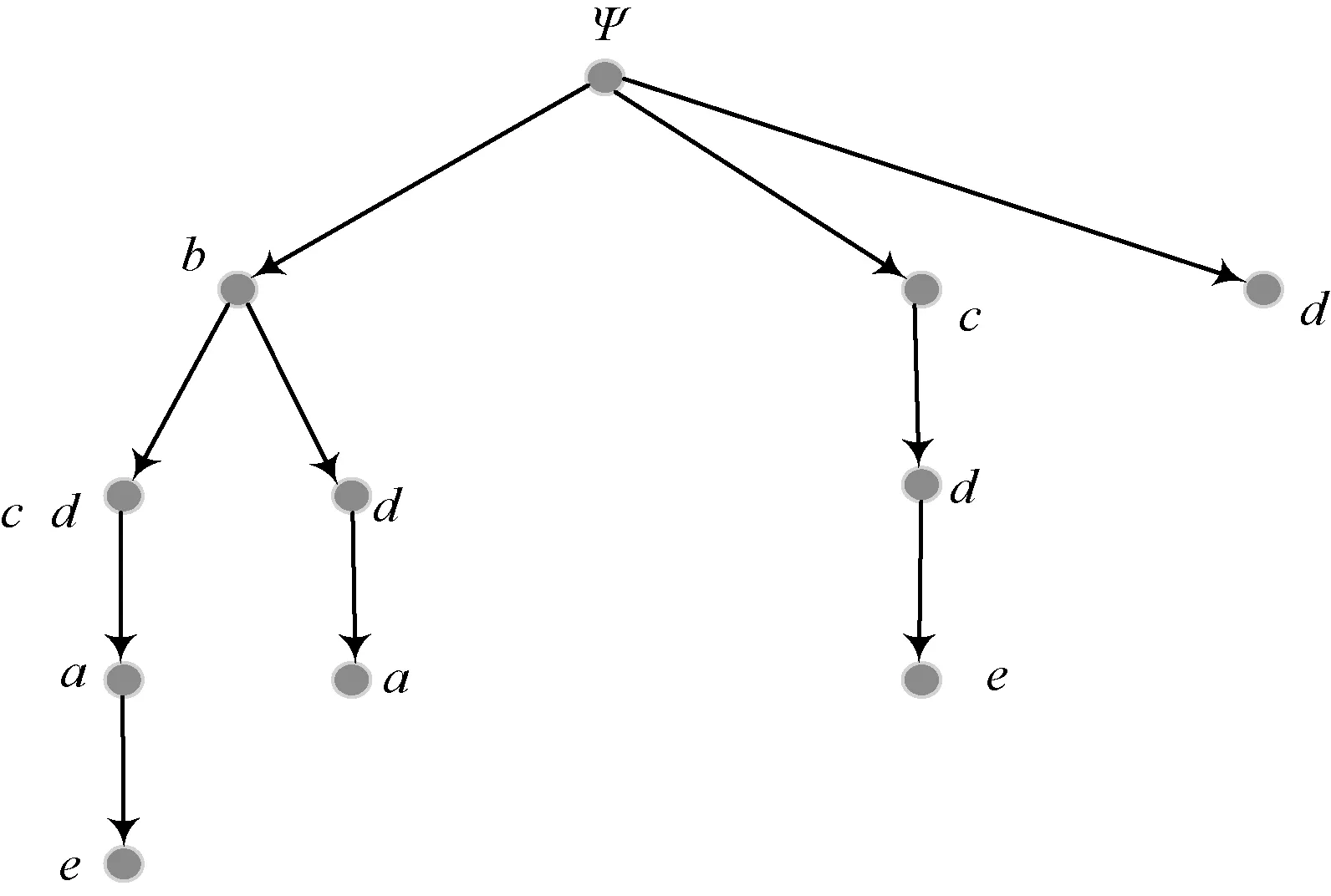
1.4 可視化分類與知識發現
1.5 數據與對比方法
2 結果
2.1 帕金森語音特征的概念分析
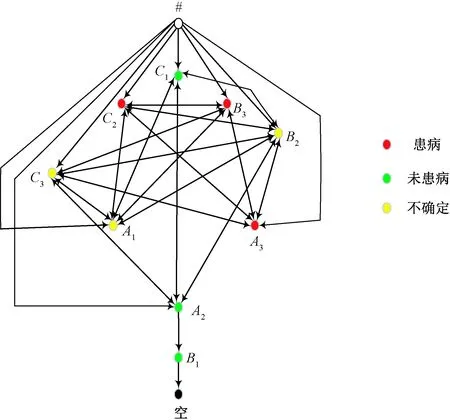
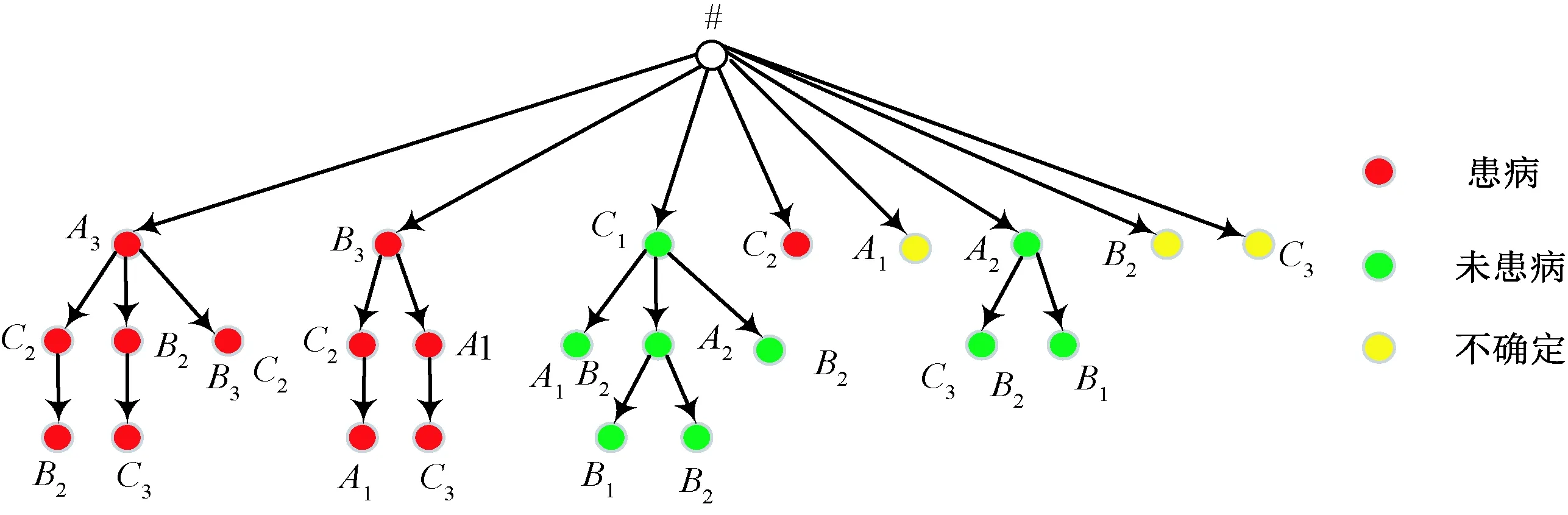
2.2 帕金森病診斷精度的實驗
3 討論
3.1 數據集分析
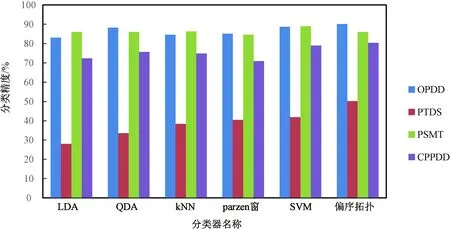
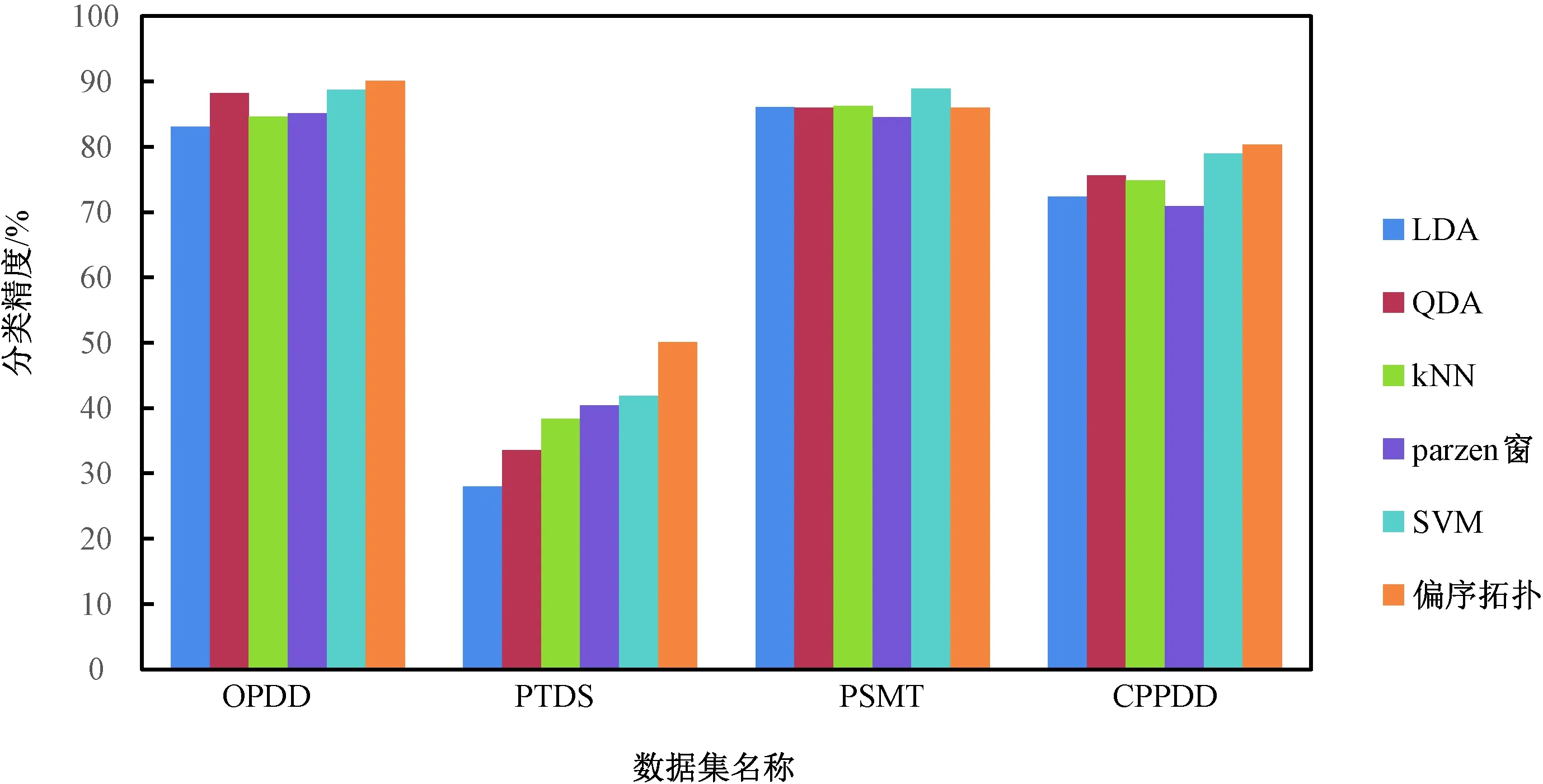
3.2 分類器分析
4 結論
猜你喜歡
保健醫苑(2022年6期)2022-07-08 01:25:28現代裝飾(2022年1期)2022-04-19 13:47:32數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56現代裝飾(2020年2期)2020-03-03 13:37:44中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32活力(2019年22期)2019-03-16 12:47:04中學生數理化·高一版(2018年9期)2018-10-09 06:46:48中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06中學生數理化·高一版(2017年9期)2017-12-19 12:15:14初中生世界·七年級(2017年9期)2017-10-13 22:27:46
