基于神經網絡Q-learning算法的智能車路徑規劃*
2019-03-14 03:36:48衛玉梁靳伍銀
火力與指揮控制 2019年2期
衛玉梁,靳伍銀
(蘭州理工大學機電工程學院,蘭州 730050)
0 引言
機器學習分為監督學習、無監督學習以及強化學習3種,其中強化學習是以環境反饋為學習策略的機器學習方法[1-2]。蒙特卡羅算法、Q學習算法、模擬退火法、遺傳算法等都屬于強化學習[3];由Watikins提出的Q-learning算法是強化學習算法中應用較為廣泛的一種,其特點是不依賴于環境的先驗模型[4-5]。因此,Q強化學習算法是一種無模型的在線學習算法[6]。本文采用Q強化學習算法來解決智能小車在行走過程中,特別是在環境中設置除起點和目標位置以外,還有其他路障時的路徑規劃和規避問題。由于Q學習算法的量化過程會影響到最終的實驗效果,從而采用RBF網絡對Q強化學習算法進行優化,提高Q學習算法效果,加強智能小車的自治導航能力。
1 Q-learning算法原理
Q學習算法是一種類似于動態規劃的強化學習方法[7]。可以為智能系統提供一種學習能力,通過這種能力可以使系統在馬爾科夫環境中利用經歷的動作序列選擇最優動作集,而且這種能力不依賴于馬爾科夫環境的模型[8]。所以Q-learning學習算法也是馬爾科夫決策過程MDP(Markov Decision Process)的另一種表達形式[9]。
首先將小車路徑規劃問題建模為有限的、離散的MDP,用數組{S,A,R,P}表示,其中 S 為小車的位置狀態空間,A為小車可用控制指令組成的動作空間,R為對應狀態的獎賞回報,P為狀態之間的轉移概率。

圖1 強化學習框圖
強化學習框圖如圖1所示,智能小車路徑規劃決策系統每步可在有限動作集合中選取某一動作,并將這個動作作用于環境中,環境接受該動作后狀態發生轉移,同時給出獎賞R。例如,小車路徑規劃決策系統在t時刻選擇動作at,環境接受這個動作后由狀態st轉移到st+1。
上述R及st+1的概率分布取決于at及st。環境狀態st以如下概率變化到st+1:

定義表示狀態st的值函數,用來從長期的觀點確定并選擇最優動作,在策略π的作用下:


式(3)表明策略π*能夠使值函數Vπ(s)取得最大值。
定義動作值函數Q如下:


又根據式(3),可得:
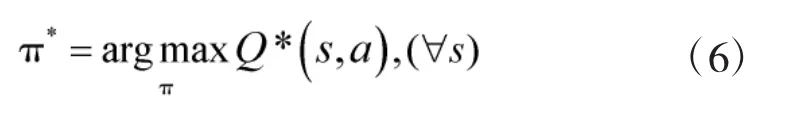
上式表明,在路徑規劃時僅需要對現在的狀態Q(s,a)的局部值不斷作出反應,就可以選擇出全局最優的移動策略。其迭代公式為:

2 神經網絡的Q-learning算法實現
傳統Q學習算法的流程如圖2所示:隨機初始化 Q(s,a)值根據當前 Q 和位置 st,使用一種策略,得到并進行動作at,到達新的位置st+1,獲得獎勵R更新之前位置的Q值。當達到目標狀態時,此次迭代過程結束。

圖2 傳統Q學習算法的流程
本文利用RBF網絡較強的函數逼近能力,實現Q-learning的動作值函數Q進行逼近,網絡結構如圖3所示。

圖3 基于RBF的Q算法網絡結構

第2層為隱層,在這一層當中,每一個節點采用P維高斯函數,第K個RBF節點的表達式為:


3 基于Q學習算法智能小車路徑規劃
Q強化學習系統結構如圖4所示,在圖4中,整個系統只有一個決策單元,這個單元承擔著馬爾科夫過程中的動作獎賞R的評價和動作的選擇任務。

圖4 Q強化學習系統結構
綜上所述,Q學習算法在對智能小車的路徑進行規劃時,不依賴于環境的初始環境,而是在動態環境中實現其路徑的規劃。為了實施并且準確獲取其所處的環境的動態數據信息,判斷環境的實際狀況,在智能小車上配置有4個距離的傳感器,用于檢測智能小車與路障之間的距離等,然后通過數據采集電路將這4個傳感器獲得的位置等信息傳遞到核心芯片,由其計算所得的結果作為系統的輸入,即小車在每個S環境時可作出的動作指令集合為向4個方向的移動,即A={上,下,左,右}系統工作流程如下:
1)對工作環境st進行觀測;
2)選定一個動作a并執行;
3)對下一個環境st+1進行觀測;
4)接收強化信息rt;
5)調整Q值。
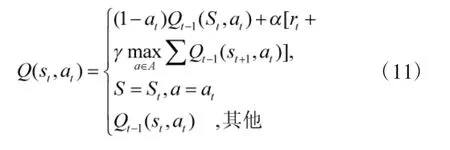
4 仿真實驗及結果分析
4.1 基于Q-learning智能小車路徑規劃算法仿真GUI仿真系統
為了驗證本文所采用算法的有效性及相對于其他算法的優越性,基于MATLAB平臺建立了Q-learning智能小車路徑規劃算法GUI仿真系統,其界面如圖5所示。
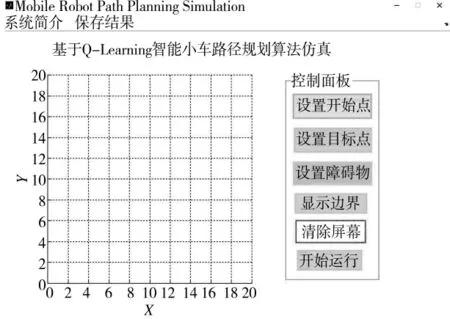
圖5 小車路徑規劃GUI仿真系統
系統中主要包含了“顯示”和“設置”兩大塊,通過右邊的“設置”來定義仿真過程中的智能小車的起點、終點以及運動過程中的各種路障。在界面的任務欄上同時設置了系統簡介以及保存結果兩個功能選項。
4.2 仿真結果
本文中在簡單路障和復雜路障兩種環境下進行仿真研究,同時加入基于勢場的Q學習算法作為比較,具體仿真結果如圖6和下頁圖7所示。
1)簡單路障下的路徑規劃效果
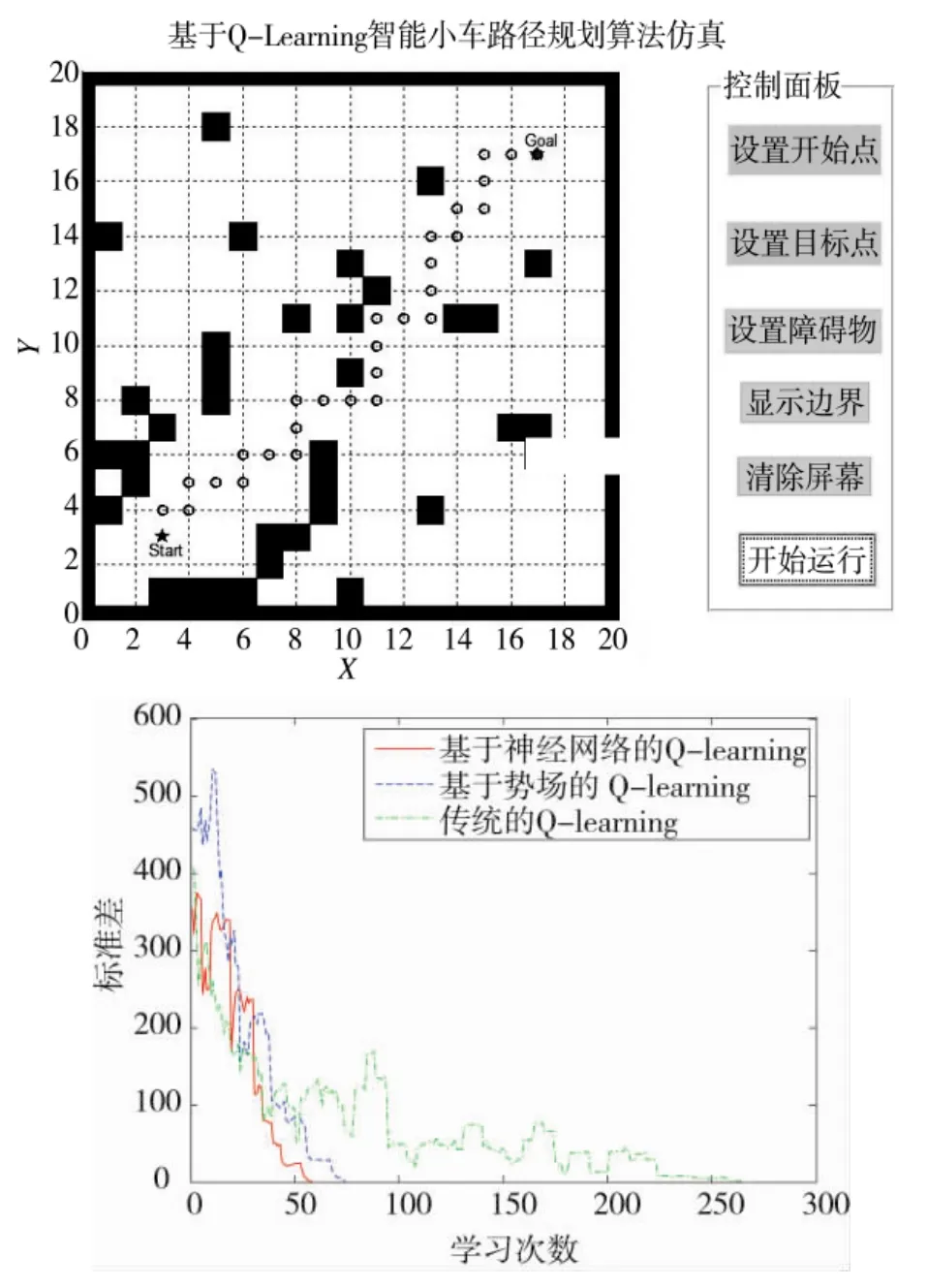
圖6 簡單路障下的路徑規劃效果
2)復雜路障下的路徑規劃效果
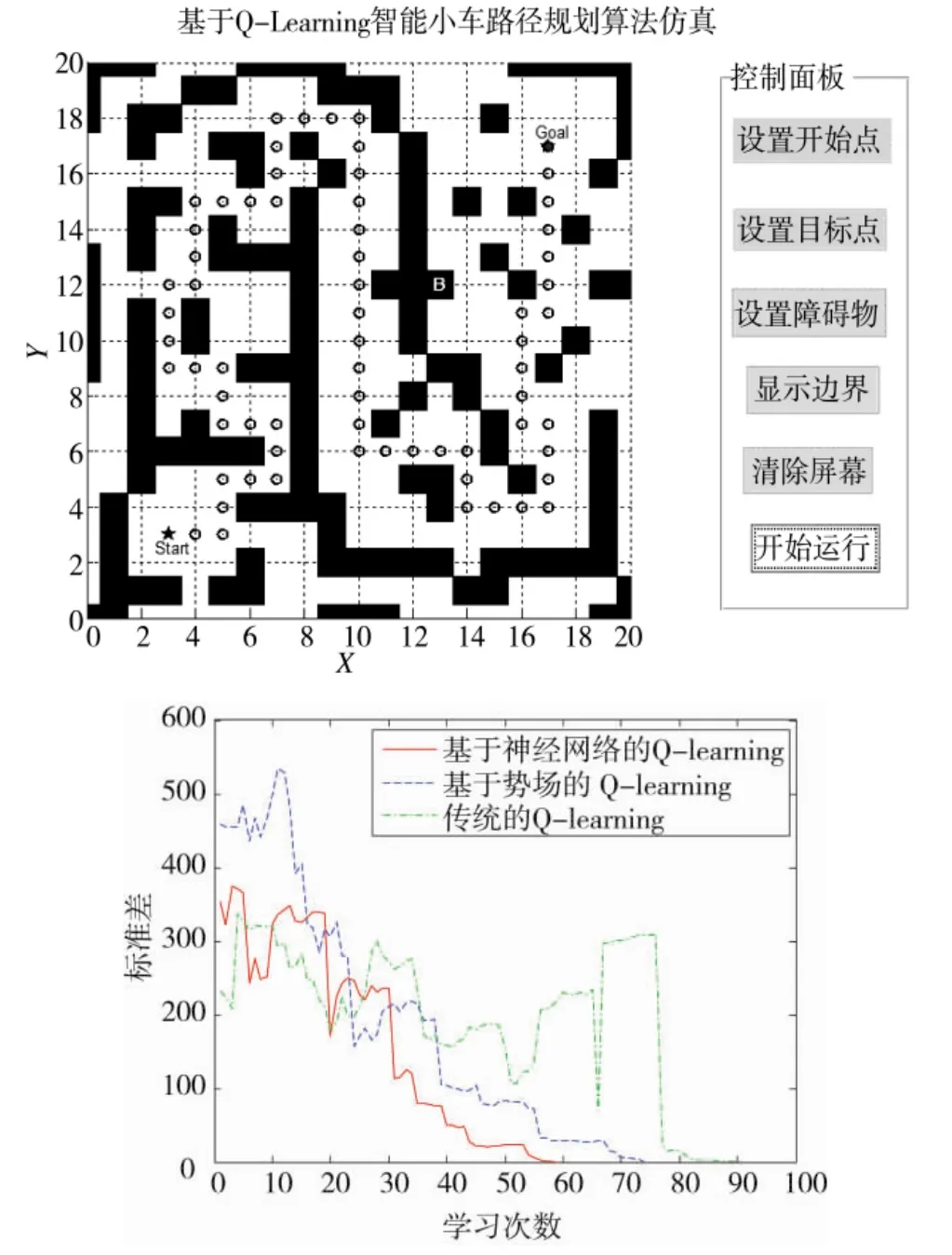
圖7 復雜路障下的路徑規劃效果
上述仿真結果表明,本文所提出的算法能夠實現智能小車行走過程中的全局路徑規劃,對在環境中設置有除起點和目標位置以外的路徑規劃和路障規避問題有著良好的表現。同時對于Q算法而言,本文所采用的基于神經網絡Q-learning算法無論是在相對簡單或是相對復雜的環境中,其效率均為最高,收斂速度也最快,其次是基于勢場的Q-learning算法,傳統的Q-learning算法收斂速度最慢、效果最差。
5 結論
本文針對智能小車行走過程中的全局路徑規劃和路障規避問題,提出了一種基于神經網絡Q強化學習算法。利用MATLAB開發了基于神經網絡Q-learning強化學習算法智能小車全局路徑規劃和路障規避仿真平臺,仿真結果表明:
1)本文所提出的算法能夠實現智能小車行走過程中的全局路徑規劃,對在環境中設置有除起點和目標位置以外的路徑規劃和路障規避問題有著良好的表現。
2)基于RBF網絡逼近的Q-learning算法相對與其他兩種算法其效率最高,收斂速度最快,大大地提高路徑規劃的效果和收斂速度。
3)基于Q學習算法的策略能使智能小車獲取自學習功能,增強了其自導航的能力。為移動機器人、無人車等在貨物運輸、智能駕駛以及軍事方面的應用提供了一定的參考意義。
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國衛生(2016年2期)2016-11-12 13:22:16
