基于高斯偽譜法的二級助推戰術火箭多階段軌跡優化
2019-03-13 07:03:06劉超越張成
兵工學報 2019年2期
劉超越, 張成
(北京理工大學 宇航學院, 北京 100081)
0 引言
飛行器多階段軌跡規劃可以實現飛行器在不同飛行環境、不同飛行要求下的飛行狀態切換。在多階段軌跡規劃方面,航天工程中有許多應用研究,如商用飛機飛行規劃問題[1-3]、航向輔助軌道轉移問題[4]等。然而,多階段軌跡規劃在導彈彈道優化問題中的應用數量有限。文獻[5-6]對炮射滑翔制導導彈進行了多階段軌跡規劃,將整個彈道軌跡劃分為4個相互連接的飛行階段,利用高斯偽譜法(GPM)將軌跡規劃問題轉化為非線性規劃問題,實現了相應的飛行任務。
二級助推戰術火箭與炮射滑翔制導導彈相比,具有速度快、突襲性好、射程遠等優點。根據其作戰任務,發射前必須確定一些關鍵變量[7-8],包括二級助推發動機的點火時間、制導啟動時間、制導階段的控制等。這些變量對彈道性能有很大影響,如射程、攻擊速度、攻擊角度等。
上述關鍵變量的確定過程可以看作是一個終端時刻自由、終端狀態固定且帶有路徑約束的多階段、非線性最優控制問題。求解最優控制問題的數值方法很多,一般分為間接法和直接法[9]。間接法將最優控制問題轉換為Hamilton邊值問題,通過數值方法求解,存在收斂域小、難以估計共軛變量初值等不足,且二級助推戰術火箭軌跡優化問題存在多個路徑約束,使間接法的推導過程十分復雜。直接法采用參數化方法,將連續空間的最優控制問題求解轉化為非線性規劃(NLP)問題,通過數值求解NLP問題獲得最優解。由于直接法克服了間接法的諸多不足,目前在飛行器軌跡優化領域得到了更廣泛應用[10]。
本文研究的GPM是直接法的一種,它采用全局插值多項式在一系列勒讓德- 高斯 (LG)點上近似狀態變量和控制變量。與一般的配點法相比,GPM能夠以較少節點獲得較高的求解精度,同時,根據GPM共軛變量映射定理[11-13],采用GPM轉化得到NLP問題的庫恩- 塔克條件(KKT)與原最優控制問題1階最優必要條件的離散形式具有一致性。因此,GPM因其高效、快速收斂和避免顯式數值積分等優點,在求解最優控制問題方面得到了廣泛應用[14-15]。
文獻[16]研究了GPM在二級助推導彈多階段軌跡規劃問題中的應用,得到了最大縱向航程和最大橫向航程兩種最優軌跡,但二級助推發動機的點火時間、制導啟動時間以及初始彈道傾角并不能根據飛行任務而改變,無法很好地利用二級助推導彈的優勢,對不同的飛行任務適應性也相對較弱。文獻[17]研究了二級助推導彈的多階段軌跡規劃問題,并確定了二級助推發動機的點火時間、制導啟動時間等關鍵變量,但其研究僅在縱向平面內進行,無法進一步考慮導彈攻擊目標過程中對禁飛區等戰場環境約束區的規避情況。
為了較好地模擬導彈飛行過程中的真實飛行環境,需要考慮飛行過程中的協同禁飛區、敵方火力覆蓋區等戰場環境約束。然而,使用GPM解決復雜約束下的多階段軌跡規劃問題時,出現以下困難:1)在區間內部,離散節點的分布相對較稀疏,使得規劃軌跡在戰場環境約束區附近精度較低,從而降低了高精度軌跡的求解效率;2)不正確的初值猜測可能導致最優解局部收斂甚至發散。針對以上兩個問題,本文提出了基于準接觸點的制導攻擊段分段策略,以提高規劃軌跡在戰場環境約束區的求解精度和求解效率。同時,提出了基于初值生成器的迭代策略,以提高最優解的收斂速度和可行性。
本文以二級助推戰術火箭為研究對象,建立戰術火箭對地攻擊的數學模型,將其描述為帶有路徑約束的多階段最優控制問題;利用GPM將該最優控制問題的變量進行離散化;結合基于準接觸點的制導攻擊段分段策略對彈道進一步分段;利用基于初值生成器的迭代策略,求解戰場環境約束等多種約束條件下二級助推戰術火箭的多階段軌跡優化問題,同時確定二級助推發動機的點火時間、制導啟動時間、初始彈道傾角、制導階段的控制等關鍵變量。
1 二級助推戰術火箭對地攻擊數學模型
1.1 戰術火箭3自由度質點運動學模型
在戰術火箭對地攻擊任務中,戰術火箭的運動主要以航跡控制為主,因此采用三維空間的3自由度質點模型即可滿足要求。
戰術火箭在地面坐標系下的質點運動方程為
(1)
式中:(x,y,z)為戰術火箭在地面坐標系中的位置坐標;v為戰術火箭的飛行速度;θ為彈道傾角;ψv為彈道偏角;m為戰術火箭質量;P為發動機推力;Fx為阻力;Fy為升力;Fz為側向力;η為燃料的質量秒流量;α為攻角;β為側滑角。定義狀態向量x=[v,θ,ψv,x,y,z,m]T,控制向量u=[α,β]T。
戰術火箭在飛行過程中受到的空氣阻力、升力和側向力的計算公式為
(2)
式中:0.5ρv2為動壓;ρ為大氣密度;S為戰術火箭參考橫截面積;Cd、Cl和Cc分別為阻力系數、升力系數和側向力系數,三者均為攻角、側滑角和馬赫數的函數。
氣動數據的擬合效果會對飛行軌跡設計產生重要影響。對于戰術火箭,阻力系數可看作是關于α和β的二次函數,升力系數可看作是關于α的線性函數,側向力系數可看作是關于β的線性函數。將本文中戰術火箭的氣動數據擬合,得到的擬合結果為
(3)
式中:Ma為馬赫數;a1=-0.108 8,a2=10.740 0,a3=0.217 1;b1=-0.985 5,b2=10.040 0;c1=-0.985 5,c2=10.040 0.
戰術火箭在大氣層內飛行,將標準大氣密度ρ、聲速c進行精確擬合:
(4)
式中:T為大氣溫度,T=292.6-0.010 39y+4.497×10-7y2-6.639×10-12y3.
1.2 彈道階段的劃分
二級助推戰術火箭的飛行過程可以分為4個階段:發射段、爬升段、續航段和制導攻擊段,如圖1所示。在不同的飛行階段,飛行參數以及運動學模型有所不同。每個階段的具體表述如下:

圖1 彈道分段Fig.1 Division of trajectory
1)發射段:始于發射點,結束于1級發動機的關機點,為無控飛行狀態。1級發動機可為戰術火箭在飛行初期提供較高的飛行速度。發射段時長固定,為1級發動機的工作時間,設為[t0,t1]。
2)爬升段:始于1級發動機的關機點,結束于2級發動機的點火點。1級發動機工作結束后,火箭進入爬升段,繼續以無控飛行狀態爬升。爬升段連接發射段與續航段,目的是將戰術火箭續航段的開始時刻調整至最佳時機。因此,爬升段的工作時間不固定,設為[t1,t2]。
3)續航段:始于2級發動機的點火點,結束于2級發動機的關機點,為無控飛行狀態。在續航段,2級發動機工作將戰術火箭姿態和速度調整至最佳狀態,為適應戰場環境、攻擊目標做好充分準備。續航段時長固定,為2級發動機的工作時間,設為[t2,t3]。
4)制導攻擊段:始于2級發動機的關機點,結束于目標點。在制導攻擊段,戰術火箭通過舵的控制,不斷修正飛行路徑,在滿足復雜戰場約束情況下,精確攻擊目標。制導攻擊段的工作時間不固定,設為[t3,t4]。
1.3 約束條件
戰術火箭的對地攻擊軌跡需要滿足下列約束條件:
1.3.1 邊值約束
1.3.1.1 初值約束
(5)
式中:t0為發射時刻;(x0,y0,z0)為發射點坐標;θ(t0)為初始彈道傾角,是軌跡優化問題中的離散變量,需要根據不同的任務確定最優值。
1.3.1.2 終端約束
為了保證戰術火箭的殺傷效能,需要戰術火箭攻擊目標時具有較高的速度與較大的落角,因此軌跡優化問題的終端約束為
(6)
式中:tf為終端時刻;vfmin和θfmin分別為終端最小攻擊速度和最小落角;(xt,0,yt)為目標坐標。
1.3.2 多階段約束
由于在整個彈道的不同階段,戰術火箭的工作情況不同,需要施加不同約束。另外,戰術火箭質量隨著1級發動機及2級發動機的工作發生變化。
1)發射段
(7)
2)爬升段
(8)
3)續航段
(9)
4)制導攻擊段
(10)
式中:P1、η1和P2、η2分別為1級發動機和2級發動機的推力、質量秒流量;αmax和αmin分別為攻角可行域的上限和下限;βmax和βmin分別為側滑角可行域的上限和下限。
1.3.3 戰場環境約束
戰術火箭在攻擊目標過程中,需要規避協同禁飛區和敵方火力覆蓋區等戰場環境約束區域[18],提高戰術火箭的生存能力和攻擊目標的有效性。
對于協同禁飛區,其上方很大高度范圍之內戰術火箭都是無法穿越的,因此本文采用無限高的圓柱體模型,所規劃的軌跡不能與該圓柱相交。約束條件式為
‖(x(t)-xnf,i,z(t)-znf,i)‖2≥rnf,i,
i=1,2,…,Nnf,
(11)
式中:‖·‖2為兩點之間的距離;(xnf,i,0,znf,i)和rnf,i分別為第i個協同禁飛區的中心坐標及半徑。
敵方火力覆蓋區的作用范圍可近似看作半球,因此相應的約束條件式為
‖(x(t)-xfc,i,y(t)-yfc,i,z(t)-zfc,i)‖2≥rfc,i,
i=1,2,…,Nfc,
(12)
式中:(xfc,i,yfc,i,zfc,i)和rfc,i分別為第i個敵方火力覆蓋區的中心坐標及半徑。
1.3.4 過載約束
為了確保戰術火箭飛行過程中的結構安全,需要考慮過載約束:
(13)
式中:nl為過載;nlmax和nlmin分別為過載約束的上限和下限。
1.3.5 內點約束
在多階段的軌跡規劃問題中,需要確保每一階段和下一階段的時間、狀態等是緊密連接的。因此,需要在階段邊界上施加強制連接條件,即
(14)
式中:k(k=1,2,…,K)為階段數;K為所有階段的個數;tP1和tP2分別為1級發動機和2級發動機的工作時間。
1.4 目標函數
考慮到戰術火箭執行攻擊目標任務時兼備時間較短和控制量較省的性能,目標函數由兩部分構成:1)總飛行時間的最小化;2)飛行過程中控制量的最小化。本文中,控制量是指攻角和側滑角,為了使積分項處于相同的數量級,對攻角和側滑角進行歸一化處理。因此,目標函數可以描述為
(15)
式中:λ為調整總飛行時間和總控制量在目標函數中所占權重的權重因子。
1.5 最優控制問題框架
將軌跡規劃問題轉化為最優控制問題:尋找控制變量u=[α,β]T,最小化積分型性能指標:
(16)
式中:x=[v,θ,ψv,x,y,z,m]T∈R7為狀態變量;t∈[t0,tf],終端時間tf自由;L為目標函數(15)式的被積函數。滿足如下運動學微分方程約束(見(1)式):

(17)
邊界條件(見(5)式和(6)式):
Bmin≤B(x(t0),x(tf),t0,tf)≤Bmax,
(18)
式中:B為邊值約束的簡化形式;約束的上限和下限符號分別為Bmax和Bmin. 路徑約束(見(11)式~(13)式):
Cmin≤C(x(t),u(t),P,η)≤Cmax,
(19)
式中:C為路徑約束的簡化形式;約束的上限和下限符號分別為Cmax和Cmin.
2 多階段最優控制問題離散化
GPM將最優控制問題的狀態變量和控制變量在一系列LG點上離散,并以離散點為節點構造拉格朗日插值多項式來逼近狀態變量和控制變量。通過對全局插值多項式求導來近似狀態變量對時間的導數,從而將微分方程約束轉換為一組代數約束。性能指標中的積分項由高斯積分計算。終端狀態由初始狀態加右端函數在整個過程的積分獲得。經上述變換,可將最優控制問題轉化為具有一系列代數約束的NLP[19-20]。
2.1 時域變換
在前邊介紹的多階段軌跡優化問題中,時間間隔t∈[t0,tf]被劃分成K個階段Sk=[tk-1,tk],k=1,2,…,K. 采用GPM計算最優控制問題時,需要通過(20)式將每段時間區間轉換到[-1,1]:
(20)
2.2 狀態變量與控制變量的插值近似
GPM需要在一系列離散點上對狀態變量和控制變量進行全局插值多項式逼近。在Sk中,采用拉格朗日插值多項式作為基函數來近似狀態變量和控制變量:
(21)
(22)

2.3 微分方程的約束轉換為代數約束
對全局插值多項式(21)式微分后,代入運動學微分方程(17)式中,并在LG點上離散,可得
(23)

2.4 約束條件離散化
邊界約束(見(18)式)表示為
(24)
在LG點對路徑約束(見(19)式)進行離散化處理,得
(25)
則內點約束(14)式可表示為
(26)
最后,目標函數(16)式可用高斯求積公式進行離散化表示:
(27)

至此,多階段連續最優控制問題被轉化為離散參數的NLP問題,其標準形式為
(28)
式中:F(z)為性能指標函數;ge(z)為不等式約束;hf(z)為等式約束;p、q分別為不等式約束和等式約束的個數;決策向量z=[(z(1))T,(z(2))T,…,(z(k))T,…,(z(K))T]T,包括離散狀態量、離散控制量、各階段間的連接時刻和終端時刻,

(29)
由于IPOPT求解器采用內點算法,可以處理具有大量等式和不等式約束的大規模稀疏非凸問題。為了解決NLP,本文采用開源的NLP求解器IPOPT.
3 最優軌跡的求解策略
3.1 基于準接觸點的制導攻擊段分段策略
GPM是將連續最優控制問題離散化后進而求解的數值方法,LG點為勒讓德多項式的根。由LG點的分布規律可知:越靠近區間邊界處LG點越密集;在區間的內部則LG點相對稀疏。作為一種路徑約束,戰場環境約束若處于規劃軌跡的區間邊界處,則戰場約束區附近的規劃軌跡精確度較高;戰場環境約束若處于規劃軌跡的區間內部,則戰場約束區附近的規劃軌跡精確度會降低;甚至,當區間內部LG點密度較低時,出現規劃軌跡與禁飛區或敵方火力覆蓋區相交的情況,如圖2所示。因此,戰場環境約束處于規劃軌跡的區間內部時,較難得到高精度的解。
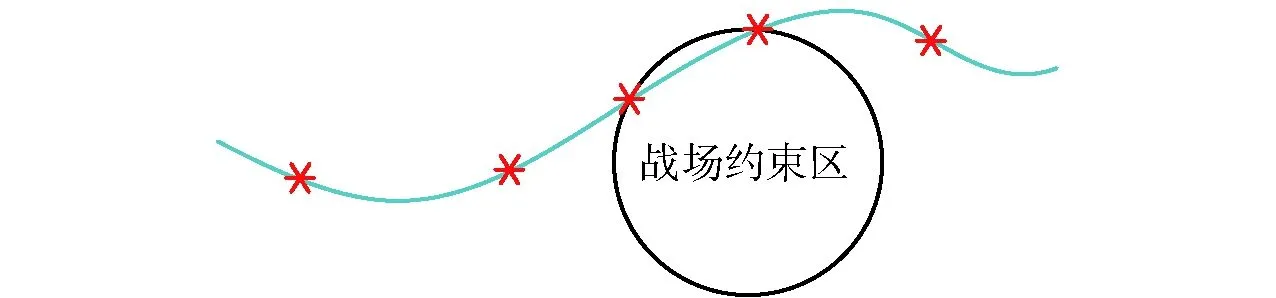
圖2 軌跡與戰場約束區相交Fig.2 Intersection between trajectory and battlefield constraint region
在本文所述戰術火箭攻擊目標的飛行過程中,發射段、爬升段和續航段距離發射點比較近,一般不會受到禁飛區、敵方火力覆蓋區的干擾,因此,本文采用以準接觸點為分段節點將制導攻擊段進一步分段的策略[21],以提高戰場約束區附近規劃軌跡的精確度,進而提高高精度最優軌跡的求解效率。
準接觸點根據制導攻擊階段細分前預生成的規劃軌跡來估計:制導攻擊階段細分前,選擇較少的LG點快速解算得到最優軌跡,則戰場約束區的邊界會被最優規劃軌跡分成一個優弧和一個劣弧,如圖2所示;理論上,為了滿足快速攻擊和較少控制量的要求,最終高精度規劃軌跡應沿戰場約束區的邊界飛行。顯然,準接觸點應該選取于戰場約束區邊界圓的劣弧上。為了有利于產生更平滑的軌跡并且減輕對機動性的需求,準接觸點選取為劣弧中點。以準接觸點為分段節點將制導攻擊階段進一步分段后,戰場約束區附近的軌跡與LG點分布情況如圖3所示。

圖3 采用制導攻擊段分段策略時戰場約束區附近軌跡Fig.3 Trajectory near battlefield constraint region for using the guided attacking segment subdivision strategy
3.2 基于初值生成器的迭代策略
在GPM實際應用中發現,不恰當的初值可能使問題收斂到不可行解[22-23]。針對這一問題,本文提出了改進的最優軌跡求解策略,即構造設計變量初值生成器,利用GPM能以較少節點獲得較高精度的優點,提出如下多步迭代優化求解步驟:
步驟1對于未對制導攻擊段進行階段細分前的軌跡規劃問題,先在4個飛行階段采用較少的離散點,快速計算近似的最優軌跡和控制變量。
步驟2利用3.1節所述準接觸點選取方法,根據步驟1求出的最優軌跡選取合適的準接觸點;以選取的準接觸點為分段節點,對制導攻擊段進行進一步細分,得到最終的全彈道多階段軌跡優化問題模型。
步驟3以步驟1得到的最優軌跡和控制量為參考,以較少的離散點計算步驟2得到的軌跡優化問題,得出近似最優軌跡和控制變量,通過插值獲得更多離散點。
步驟4將步驟3獲得的變量值作為初值重新求解,將得到的最優變量代回動力學微分方程組(1)式中測算誤差;循環執行此步,直至得到足夠高精度的解。
4 仿真驗證與結果分析
4.1 仿真參數與結果
仿真中戰術火箭的彈體參數以及約束的參數值分別如表1和表2所示。

表1 彈體參數表

表2 約束參數表
構建仿真場景如下:戰術火箭從發射點(x0,y0,z0)處,以某一彈道傾角發射,初始速度v0=10 m/s,彈道偏角ψv=0°,經歷發射段、爬升段、續航段和制導攻擊段后攻擊位于(300 km,0 km,150 km)處的地面固定目標;在飛行過程中部署一個圓柱狀協同禁飛區和一個半球狀敵方火力覆蓋區。構建兩種不同仿真場景,每個場景的發射點位置、戰場約束區中心位置以及半徑如表3所示。
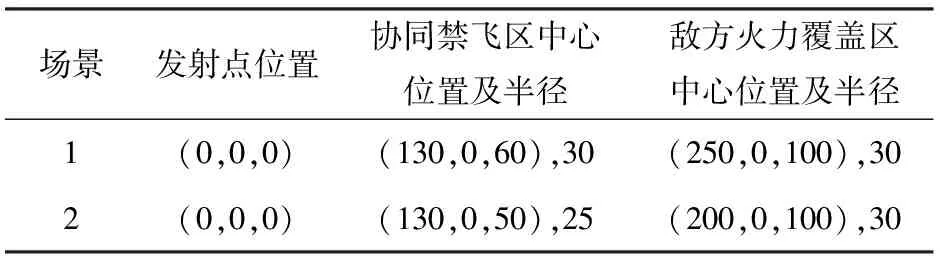
表3 仿真場景
為了使飛行任務兼備時間較短和能量較省的特點,令目標函數中的權重因子λ=2. 對構建的每個場景,在基于初值生成器的迭代策略下,分別針對制導攻擊段分段、不分段兩種情形,在相同的高求解精度以及分配相同總LG點個數情況下進行求解。計算在PC機上進行,CPU為Intel Core i7-3.6 GHz,應用基于MATLAB環境下的IPOPT軟件包對NLP問題進行求解。仿真結果如圖4~圖9所示。
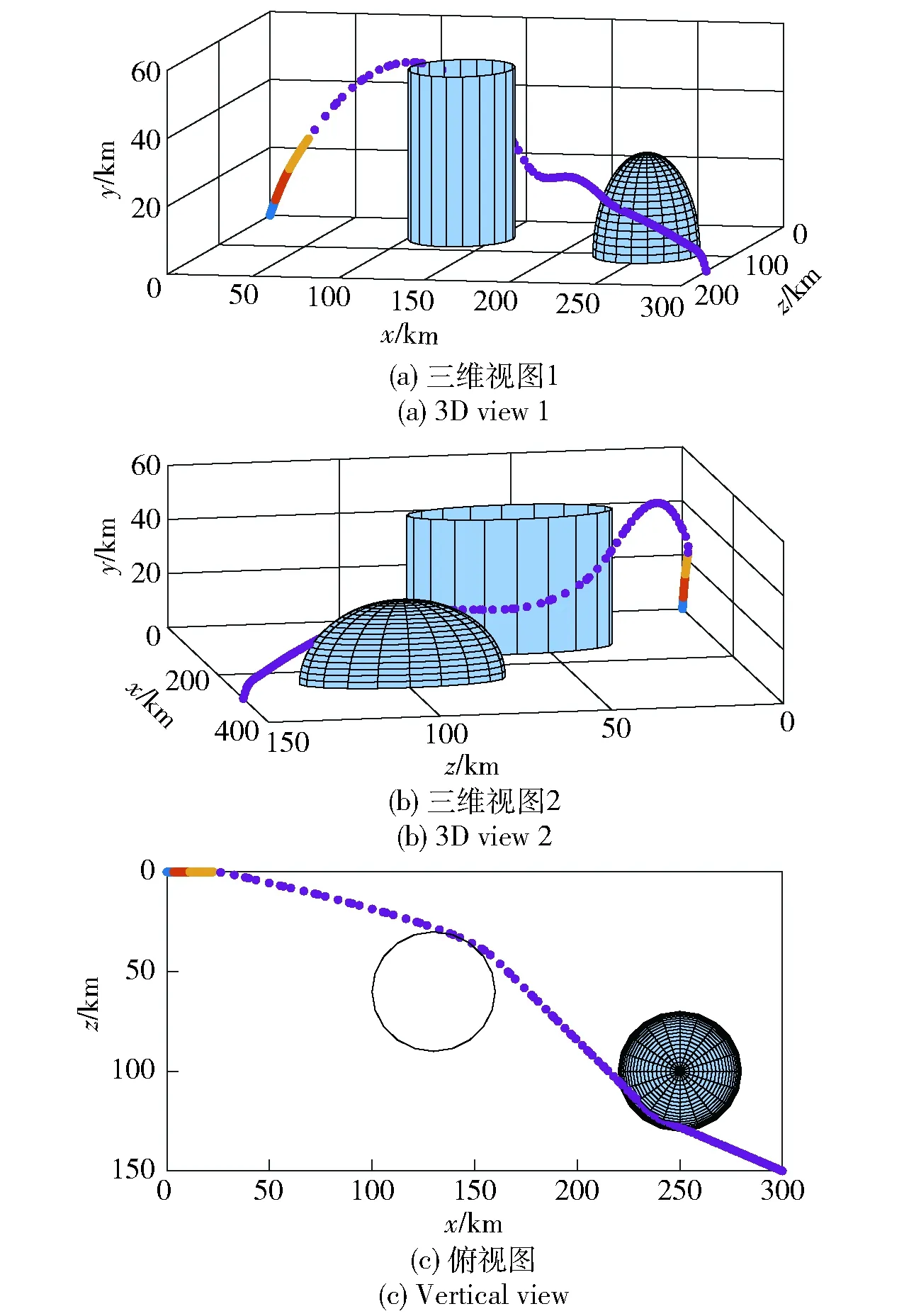
圖4 場景1不采用制導攻擊段分段策略時最優軌跡Fig.4 Optimal trajectory without the guided attacking segment subdivision in Scene 1
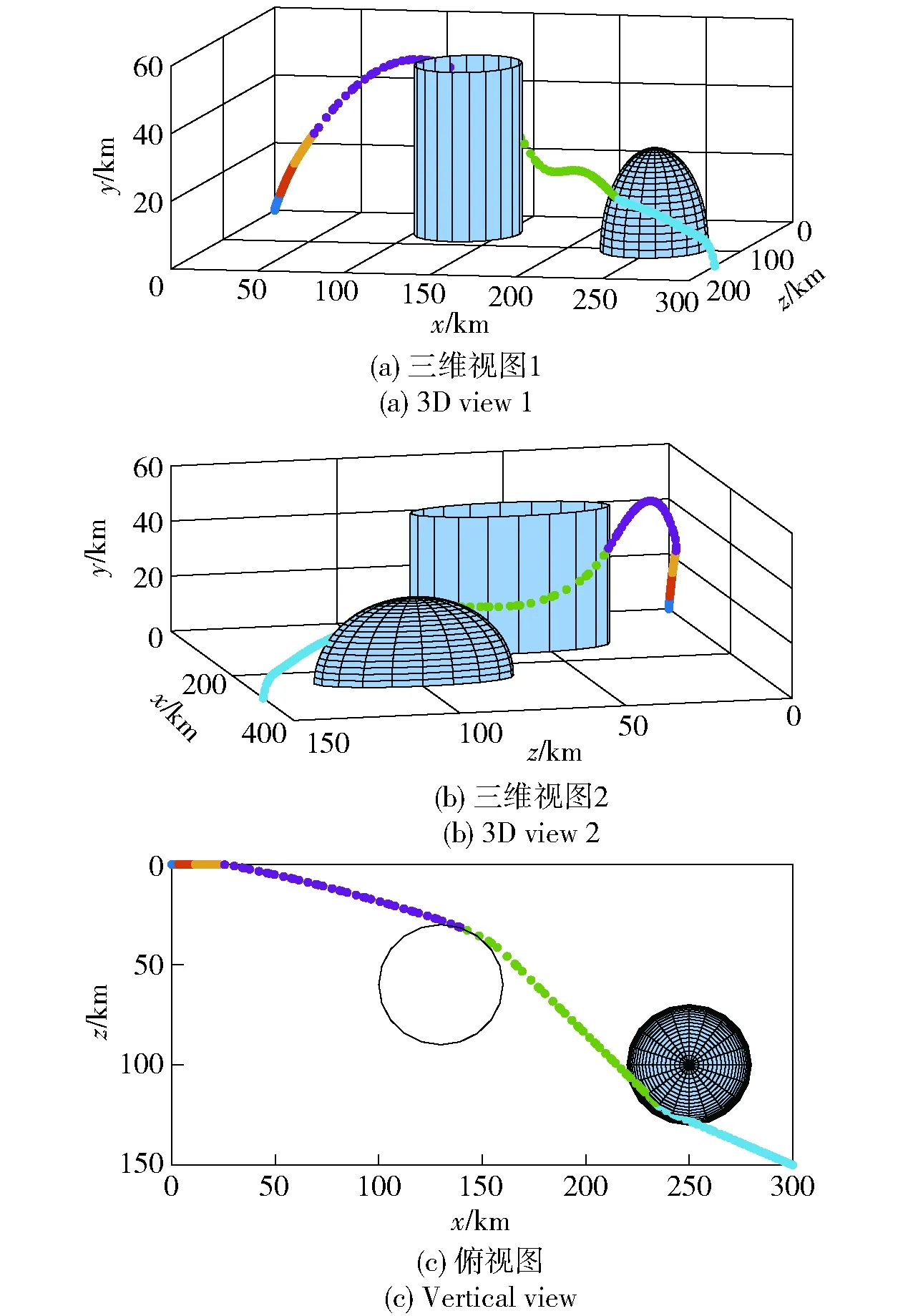
圖5 場景1采用制導攻擊段分段策略時最優軌跡Fig.5 Optimal trajectory with the guided attacking segment subdivision in Scene 1

圖6 場景2不采用制導攻擊段分段策略時最優軌跡Fig.6 Optimal trajectory without the guided attacking segment subdivision in Scene 2

圖7 場景2采用制導攻擊段分段策略時最優軌跡Fig.7 Optimal trajectory with the guided attacking segment subdivision in Scene 2

圖8 場景1戰術火箭飛行參數Fig.8 Flight parameters of tactical rocket in Scene 1
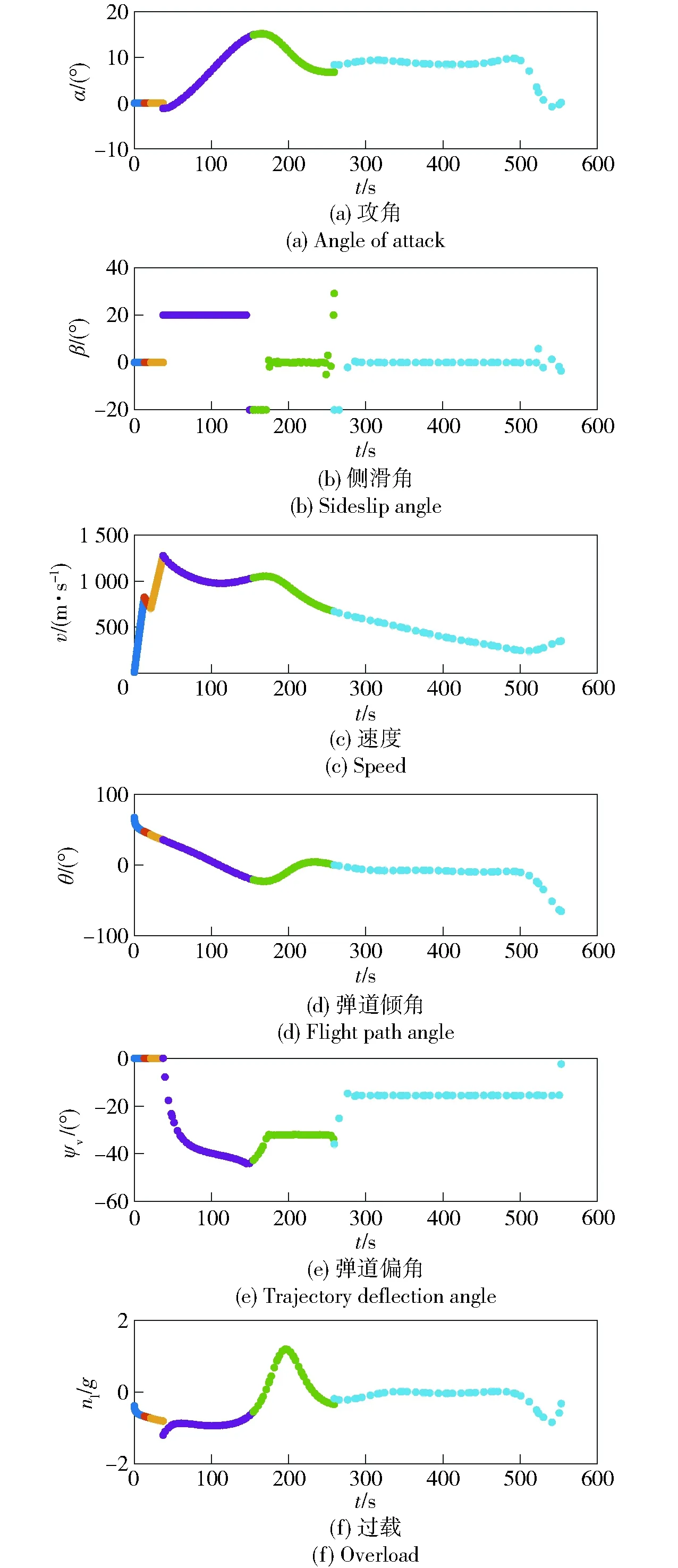
圖9 場景2戰術火箭飛行參數Fig.9 Flight parameters of tactical rocket in Scene 2
圖4、圖6分別為不采用制導攻擊段分段策略時,場景1、場景2戰術火箭攻擊目標的最優軌跡;圖5、圖7分別為采用制導攻擊段分段策略時,場景1、場景2戰術火箭攻擊目標的最優軌跡。由圖4、圖5和圖6、圖7對比可知,采用制導攻擊段分段策略時求得的最優軌跡與不采用時一致,并且都能夠避開協同禁飛區、敵方火力覆蓋區,精準擊中地面固定目標。
圖8、圖9分別為場景1、場景2對應的飛行參數曲線。從圖8(a)、圖9(a)中可以看出:在彈道最高點附近時,由于空氣密度較小,攻角迅速增大以產生足夠大的控制能力;其后隨著飛行高度的降低,空氣密度隨之增加,攻角也逐漸減小;在彈道末端,為了獲得期望的落角,攻角迅速減小。從圖8(b)、圖9(b)中可以看出,進入制導攻擊階段后,側滑角較快趨于0°并保持至攻擊目標時刻,達到了控制量較省的目的。從圖8(f)、圖9(f)中可以看出,整個飛行過程中的過載滿足約束。
進一步增加仿真場景3、場景4如表4所示。分別對每個仿真場景在是否采用制導攻擊段分段策略以及是否采用基于初值生成器的迭代策略不同條件下進行仿真驗證。每個仿真場景的仿真結果關鍵參數如表5所示;每個仿真場景在不同仿真條件下求解的時間如表6所示。

表4 仿真場景
由表5可知:戰術火箭的最優初始彈道傾角和爬升段時長隨不同的仿真場景下而變化,體現了二級助推戰術火箭對不同發射地點、不同作戰場景的適應性;4種仿真場景下,戰術火箭的落速和落角均滿足表2所設定的約束條件。

表5 仿真結果
由表6統計可知:當得到相同精度的解且總的LG點個數相同時,采用制導攻擊段分段策略進行計算耗時比不采用分段策略的計算耗時短;同時,采用基于初值生成器的迭代策略進行計算耗時比不采用迭代策略耗時短。由此可知,采用以準接觸點為分段節點對制導攻擊段進行分段的策略,可以在戰場約束區附近分配密度較高的LG點,有利于較快求得高精度的解;基于初值生成器的迭代策略可以加快求解的收斂速度,縮短求解時間。

表6 仿真計算時間
4.2 仿真結果可行性驗證
為了驗證計算結果的可行性,將4個仿真場景分別求解后,最優控制量代入運動學微分方程中進行積分,并將得到的狀態參數值分別與本文方法求得的最優狀態量值進行對比,分析誤差范圍。4組結果中,相同時間插值點處的狀態量絕對誤差的最大值散點圖如圖10所示。由圖10可見,GPM得到的最優解與數值積分結果的誤差均在允許范圍之內,從而驗證了優化結果的可行性。

圖10 誤差散點圖Fig.10 Error scatter figure
5 結論
本文研究了GPM在二級助推戰術火箭多階段軌跡優化設計中的應用,并提出了基于初值生成器的迭代策略以及基于準接觸點的制導攻擊段分段策略。仿真驗證中對4種不同仿真場景下算法的時效性和可行性進行了分析。結果表明,采用該優化策略時,GPM能夠保證較高的求解精度,并有效地提高優化軌跡的求解效率。
