基于結構-語義圖的短文本分類
2019-03-12 12:27:50胡代艷
現代計算機 2019年5期
胡代艷
(四川大學計算機學院,成都 610065)
1 研究現狀
考慮到短文本的特點,首先,短文本沒有足夠的上下文信息也沒有足夠的統計信息量;其次,也由于沒有足夠的信息量,難以識別和處理短文本中的語義模糊。所以處理短文本分類的方法主要著重于擴展文本特征,現有的短文本分類算法主要從兩個方面來豐富文本。第一類是基于內部資源的方法,通過使用規則或隱藏在當前短文本中的統計信息來擴展特征空間,S.Zhang[1]等提出了一種基于“信息路徑”的方法,利用短文本中子序列的相關性傳遞來進行分類,該方法不需要外部知識庫的復制,但是過于依賴數據集,如果數據集中沒有相應的信息的路徑,將會影響分類結果,張勇[2]提出基于詞性的特征選擇方法結合LDA主題模型的方式來進行文本分類,第二類是基于外部資源的方法,基于外部資源的分類方法又包含基于搜索引擎和大規模語料庫兩類,其中Sahami M[3]通過搜索引擎將短文本作為關鍵字進行檢索,用搜索結果對短文本進行擴充,由于該方法依賴于搜索引擎的匹配規則,對分類結果的影響較大,同時搜索過程會消耗大量的時間,實時性較差;另一種是基于大規模語料庫,如維基百科、Probase[4],M.Shirakawa[5]提出了一種基于維基百科的語義相似度測量方法,它將維基百科中的實體添加到文本中作為其語義表示,并使用實體向量來計算語義相似性,Peipei Li[6]通過Probase引入更多的語義來彌補數據稀疏性,通過最大概率的概念簇來消除歧義,Wen Hua[7]利用Probase提供的語義知識,用知識密集型方法重新定義了文本分段,詞性標記和概念標記。近年來,也有學者對圖結構文本表示方法進行了嘗試和研究。如Svetlana Hensman[8]提出基于輔助詞典Verb Net和Word Net的文本概念圖表示模型。Uchida H[9]提出了用于多文檔摘要提取的文檔圖模型表示方法。Schenk?er A[10]提出了一種較為簡單的基于圖模型的文檔表示方法,但是他們的模型主要建立在文本特征詞條的位置布爾關聯的基礎上,并沒有考慮相鄰詞間不同詞性的相互影響。
2 基于結構-語義圖的算法
隨著科技的發展,互聯網上的信息越來越豐富,但是網上的數據主要是由自然語言表示的。那么如何衡量兩個文本的相似性?例如“the President of America”和“Chief Executive”沒有相同的單詞,但是這兩者表示了相似的含義,它們均是指美國總統,這就上升到了概念層次,不止在詞語層面來考慮兩者的相似性,由此本文引入了概念語義網絡Probase;又如“band for wed?ding”和“wedding band”由于詞序不同,這兩者所表達的含義也不同,前者是婚禮樂隊而后者是結婚戒指,又如“watch harrybotter”和“read harrybotter”,對于 Harrybot?ter而言,前者是電影而后者是書籍,說明了詞與詞之間的相互影響。針對上述短文本中內部結構對語義的影響,結合外部語義網絡來提高短文本的分類性能。本文所提出的短文本分類算法步驟如圖1所示。

圖1 短文本分類算法流程圖
2.1 基于Proobbaassee的語義擴展
Probase是由微軟開發的概念知識庫,該知識庫中的數據是通過動態的無監督機器學習算法從大量的網頁中學習得到的,其中包含了540萬個概念,相較于現有的知識庫(如Freebase約有2000個概念,CYC約包含12萬個概念),Probase蘊含的知識更加豐富,并且以概率的形式來表示實例和概念之間的相關性,這樣能夠更為直觀地表示事物之間的關聯度。于是本文選擇用Probase知識庫來對短文本進行語義擴展。在Probase中用概率來表示實例和概念之間的典型性,如公式(1)和(2)所示。

本文的短文本分類算法通過圖結構來保留短文本中的內部結構,同時引入Probase對短文本進行語義擴充。在短文本的組成中,名詞、形容詞、動詞等詞性的詞語對文本的語義分析有重要作用,但是在Probase中只包含了名詞詞性的詞語,但是為了保留其他詞性的語義特征,通過大量語料,提取名詞和動詞以及名詞和形容詞的常用搭配生成了相應的動詞|形容詞-概念詞典vadj-C。所以對于一個給定的短文本,可以用特征向量Vd={ }T1,T2,…,Tm={tij|1≤i≤m,1≤j≤ni}表示,其中Ti表示文檔d中第i個句子,tij為名詞、動詞和形容詞詞性的單詞或短語。
(1)基于Probase的術語識別
為了識別短文本中的術語,首先使用斯坦福自然語言處理工具Stanford CoreNLP對短文本進行語法分析以及去除停用詞,然后通過逆向最大匹配算法(BMM)獲取所有的術語,并保留語序,如下語句(識別出的術語用下劃線標記)。
Apple had agreed to license certain parts of its GUI to Microsoft for use in Windows 1.0.
接下來,對于識別出來的術語,我們需要定義的規則來區分名詞術語的類型,如公式(3)所示,其中|I(t)|表示術語t在Probase的concept中出現的頻率,|C(t)|表示術語t在Probase的instance中出現的頻率,,由此短文本的特征空間可以表示為

(2)基于概念簇的特征擴展
在上一個步驟中,獲取到了所有的術語,并區分了其類型,對于instance類型的術語可以通過Probase獲取其Top10的概念生成名詞相應的概念特征向量,對于名詞和形容詞詞性的術語通過詞典vadj-C獲取其Top10的概念生成相應的概念特征向量,短文本的特征向量可表示為然后利用概念聚類算法[11]對概念進行聚類生成概念簇,一個概念簇是由一個概念集合構成的,對于一個概念簇 VCL={C1,C2,…,Cn},第 i個概念 Ci在該概念簇中的權重 wi=p(,最終獲得短文本的特征向量可表示為公式(4)。

2.2 結構--語義圖的構建
傳統的基于統計的文本分類方法由于沒有保留文本本身的結構信息,可能造成語義缺失。文本結構信息如術語出現的先后順序,同個文本中句子間的聯系等。對于文本而言,不同的語序,不同的文字組織結構可能會產生完全不同的語義。本文利用圖結構來保留短文本的內部結構信息,一個圖結構是由節點、邊、邊與邊之間的權重組成的結構。將文本與圖結構相對應,將文本的特征抽象為節點,特征之間的鄰接關系或句子與句子之間的關聯關系抽象為邊,特征與特征間的語義相關性則為邊與邊間的權重。
算法1:結構-語義圖的構建算法
輸入:短文本的概念簇特征向量Vd;
輸出:短文本di的圖結構
算法:
1. 將短文本按句子劃分得到序列S={S1,S2,…,Sk};
4. 初始化節點集合Vdi,邊集合Edi和權值集合Wdi;
5. While S序列中還有未處理的句子
6. 將句子si的特征作為節點添加到圖結構中,節點的權值為該特征的權值wj;
7. 將句子中的詞序關系作為邊添加到圖結構中,如 clij和 clij+1的詞序關系由 ej,j+1表示,該邊的權值為 clij和clij+1語義相關度wij;
8.End While
上文描述了圖模型的構建方法,并將短文本的結構-語義圖存儲在文件中,構建好了結構-語義圖模型后,通過比較計算兩個圖結構之間的相似度,構造分類器完成分類。
3 實驗結果與分析
3.1 實驗數據
實驗數據主要來自于TagMyNews,該數據集是從流行新聞網站(nyt.com,usatoday.com和reuters.com)的RSS提要中提取的32k英文新聞,包含了32600篇英文RSS新聞,包含了7個類別,每篇文檔由標題和描述組成,平均文檔長度為14.9。

表1 實驗數據集
3.2 實驗分析
本文主要以精確率和召回率作為評價指標,根據分類器在測試集上的預測結果分為4類:
●TP:將正類預測為正類數;
●FN:將正類預測為負類數;
●FP:將負類預測為正類數;
●TN:將負類預測為負類數。
兩種評價指標的定義如下:
精確率:

召回率:

其中召回率用于衡量分類器是否能找全該類的樣本,精確率用于衡量分類器的精確性,為了兼顧兩個評價指標,引入F1值:
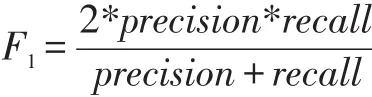
本次實驗采用了與SVM算法的對比實驗,實驗結果如圖 2、3、4 所示。
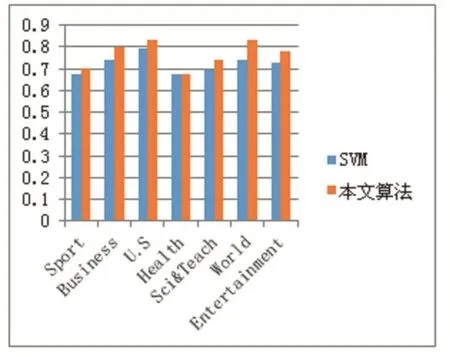
圖2 精確率對比

圖3 召回率對比

圖4 F1平均值比較
通過以上的對比實驗可以發現,基于結構-語義圖的分類器相較于基于向量空間模型的SVM算法,具有更好的性能,F1值有所提高。從實驗結果來看,本文提出的算法在短文本分類的效果上有所提升,由此可見,在引入外部語料庫的同時,用圖結構保留短文本的內部結構信息,充分利用了內外部信息對短文本的特征進行擴充,是有助于提高短文本分類的性能的,同時也說明了本文提出的基于結構-語義圖的短文本分類算法的合理性。
4 結語
本文針對短文本分類,提出并設計了結構-語義圖的短文本分類框架。該框架針對短文本的特征,用圖結構最大限度的保留了短文本的內部結構信息,其中考慮了不同詞性的相鄰詞對名詞語義的影響,同時本文引入了第三方語料庫Probase來擴充短文本的特征,結合內部結構和外部語義網絡,在保留內部結構的同時引入豐富的知識來提高短文本分類準確性。從實驗結果來看,在短文本分類的性能上有所提高,但是在圖結構的處理上還有一些問題,如短文本中提取出的特征點較少會使得圖結構之間的重疊部分較小,因此還需在圖結構上進一步優化。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
