系統虛擬化環境下客戶機系統調用信息捕獲與分析①
2019-03-11 06:02:14崔超遠李勇鋼
計算機系統應用 2019年3期
寧 強,崔超遠,李勇鋼
1(中國科學院 合肥物質科學研究院 智能機械研究所,合肥 230031)
2(中國科學技術大學,合肥 230026)
系統調用被廣泛應用于進程行為分析和惡意軟件入侵檢測[1]等方面.系統調用信息的捕獲和分析是開展這些工作的關鍵.Ether[2]是一個基于硬件虛擬化的客戶機自省工具,其用來進行惡意軟件分析.Ether利用x86快速系統調用條目機制的特性,在系統調用執行期間,其系統調用攔截機制使用x86處理器上的特殊寄存器,在一個已有地址上產生頁錯誤.Ether通過接收該地址上產生頁錯誤的信號判斷一個系統調用的產生.Nitro[3]同樣也是一個使用硬件虛擬化擴展的用于客戶機自省的開源項目,它在 KVM[4](Kernel Virtual Machine,內核虛擬機)平臺上實現.KVM由兩個部分組成,一個是基于QEMU[5]的用戶空間應用程序,一個是提供實際虛擬化功能的Linux內核模塊.Nitro將這兩部分進行了擴展,實現了系統調用的跟蹤和監控.目前捕獲系統調用的同類方法由于不能預知每個客戶機操作系統的類型及其運行的應用,無法制定統一的系統調用信息捕獲和解析規則,故僅能獲取系統調用原始信息,無法解析參數和返回值等重要信息.此外,現有方法沒有考慮到捕獲系統調用的性能開銷問題,沒有對系統調用以進程為劃分界限進行分類.由于不同系統調用的參數類型不同,參數解析面臨很大的困難.針對以上問題,本文在KVM虛擬化平臺上建立了一個實時捕獲和分析客戶機內系統調用的系統.該系統根據不同系統調用建立相應的分析規則,實現了對系統調用序列的捕獲以及對參數和返回值的解析.通過exit()系統調用判斷出進程的終止操作,并將進程從監視目標中移除,從而區分系統調用序列所屬的不同進程.
1 系統設計
1.1 設計目標
系統調用監視系統旨在利用虛擬化技術[6]在客戶機外部實現對其內部系統調用序列進行實時捕獲,并對參數和返回值進行解析.同時,不對宿主機和客戶機帶來太大的性能開銷.因此設計目標包括以下三個方面:
(1)實現對系統調用參數和返回值的快速捕獲.基于此點要求,需要在處理系統調用引發異常時,對系統調用進入和退出指令進行模擬;然后在模擬過程中獲取客戶機VCPU信息,從中提取參數和返回值的原始信息(即二進制信息);
(2)將低層次的系統調用信息還原成高層次語義[7].即在捕獲到系統調用的二進制信息后,使用內核自省工具libvmi[8]將其解析為高層次語義信息;
(3)引入較小的性能開銷.在確保快速捕獲系統調用參數和返回值的前提下,使用線程池技術快速獲取并解析多個VCPU的二進制信息,盡量減小對宿主機和客戶機帶來的性能開銷.
1.2 系統總體架構
系統總體架構如圖1所示,主要由KVM內核功能擴展模塊、監聽模塊、信息處理模塊和參數解析模塊四部分組成.系統運行過程中,監聽模塊將修改硬件規范使系統調用陷入的指令發送給KVM內核功能擴展模塊,然后KVM內核功能擴展模塊將捕獲到的系統調用低層次語義信息發送給監聽模塊.信息處理模塊將低層次語義信息轉化為系統調用名和系統調用號這些高層次語義信息.參數解析模塊完成系統調用參數的解析.

圖1 系統架構
實現該系統需要解決模擬指令的重寫、語義的轉換和進程的區分三個關鍵問題.在由快速系統調用指令引起的異常發生時,VMM[9](Virtual Machine Monitor,虛擬機監控器)捕獲該異常進行處理后對指令進行模擬.模擬指令需要解決的首要問題就是對指令進行重寫,重寫后的指令一方面要維持原有指令的功能,另一方面要滿足捕獲系統調用的需求,即得到VCPU寄存器信息.解決模擬指令重寫的方法是在KVM模擬指令的函數(如em_syscall())中加入kvm_arch_vcpu_ioctl_get_regs()函數和kvm_arch_vcpu_ioctl_get_sregs()函數來獲取通用寄存器信息和特殊寄存器信息,這些信息對應了系統調用的參數和返回值.語義的轉換包含兩方面,一個是解析系統調用名,方法是獲取其在內核符號表中的虛擬地址,然后使用libvmi的translate_v2ksym()進行解析,另一個是解析系統調用參數,針對字符串類型的參數,需使用libvmi的read_str_va()進行解析.捕獲系統調用時需要區分已終止的進程和正在運行的進程,其目的在于防止重復捕獲同名同號新舊進程的系統調用造成新進程系統調用序列不再準確,提高捕獲效率,解決進程區分問題的方法是識別進程是否調用了exit()或exit_group()函數.
2 系統實現
2.1 系統調用的捕獲
當前基于x86架構的操作系統大多使用基于syscall指令和基于sysenter指令的快速系統調用.針對這兩種類型的系統調用需要采用不同的捕獲方法.
客戶機正常執行時syscall指令不會陷入到VMM中,因此無法實現對基于syscall指令系統調用的捕獲.根據Intel軟件開發手冊上的硬件規范可知,在將EFER寄存器的SCE標志位置0時執行syscall指令,系統會發生UD未定義的無效操作碼異常陷入,這樣就成功實現了對基于syscall指令系統調用的捕獲.
基于sysenter指令的系統調用同樣依賴于一組MSR特殊寄存器,分別是SYSENTER_CS_MSR,SYSENTER_ESP_MSR 和 SYSENTER_EIP_MSR.為了使客戶機系統在執行sysenter指令時能陷入到VMM中,需要修改相關的硬件規范.基于sysenter指令的系統調用入口地址保存在上述MSR寄存器中,因此可以先將MSR寄存器原始值先保存起來,然后裝入一組NULL非法值,系統在執行sysenter指令時由于找不到系統調用入口地址會產生GP通用保護錯異常陷入,這樣就成功實現了對基于sysenter指令系統調用的捕獲.
在客戶機運行時,用戶模式下的監聽模塊首先將設置系統調用捕獲的指令通過/dev/kvm設備文件的iotcl調用發送給KVM內核模塊,當客戶機內的程序執行系統調用時發生異常陷入到VMM,KVM內核模塊捕獲到系統調用并將信息返回給監聽模塊,監聽模塊收到事件信息后停止監聽并關閉/dev/kvm設備文件的ioctl調用.
2.2 模擬指令的重寫
對于VM中發生的異常,必須要識別出該異常是由于客戶機正常執行過程中引起的還是由于改變了系統調用指令正常執行條件引起的.為此本文在內核處理異常的代碼中加入了對客戶機異常的判斷,其原理是判斷發生異常時VCPU的狀態,即:使用is_invalid_opcode()識別無效操作碼異常,若異常在客戶模式下產生,則是正常情況下產生的異常,就使用kvm_queue_exception()將異常注入到 Guest OS 中處理;否則,使用emulate_instruction()對引起異常的系統調用指令進行模擬,最后返回 Guest OS.使用 is_general_protection()識別通用保護異常,若異常發生時VCPU處于sysenter_sysexit狀態,則模擬系統調用指令,最后返回Guest OS;否則是正常情況下產生的異常,將異常注入到Guest OS 中處理.
異常識別和處理的方法如算法1所示.第1-6行用于識別和處理無效操作碼異常.第7-12行用于識別和處理通用保護異常.

算法1.異常識別和處理算法輸入:異常信息intr_info,客戶機虛擬CPU信息vcpu輸出:順利處理完異常,返回 11. IF(is_invalid_opcode(intr_info))2. IF(is_guest_mode(vcpu))3. kvm_queue_exception(vcpu);4. RETURN 1;5. ELSE emulate_instruction(vcpu);6. RETURN 1;7. ELSE IF(is_general_protection(intr_info))8. IF(is_sysenter_sysexit(vcpu))9. emulate_instruction(vcpu);10. RETURN 1;11. ELSE kvm_queue_exception(vcpu);12. RETURN 1;
模擬指令是處理異常中的關鍵環節,對該指令的重寫是獲取系統調用信息的關鍵因素.客戶機在執行完若干條傳遞系統調用參數的傳送指令后執行sysenter快速系統調用指令從用戶態快速進入內核態,進入內核態后執行wrmsr特權指令實現MSRs寄存器的初始化工作.由于修改了硬件規范,因此在執行wrmsr特權指令時客戶機會產生異常陷入到VMM中,為了恢復客戶機系統調用的正常執行,VMM需要對系統調用指令進行模擬.對模擬指令進行重寫有兩個目的,一個是重寫模擬sysenter進入指令獲取系統調用的參數,另一個是重寫模擬sysexit退出指令獲取系統調用的返回值,重寫的方法是在內核代碼arch/x86/kvm/emulate.c下的em_sysenter()和em_sysexit()函數中添加kvm_arch_vcpu_ioctl_get_regs()函數和kvm_arch_vcpu_ioctl_get_sregs()函數.
2.3 語義的轉換
語義的轉換是將內核擴展模塊捕獲到的系統調用低層次語義信息轉換為高層次語義信息,信息處理模塊完成對系統調用名和系統調用號的解析,參數解析模塊完成對系統調用參數的解析.實現語義的轉換必須要不斷向KVM內核模塊發送獲取VCPU事件信息的請求,在客戶機中有多個VCPU的情況下,如果只創建一個線程來監聽多個VCPU的事件信息,那么每捕獲到一個VCPU上的系統調用就需要暫停一次客戶機,客戶機暫停時間相應地增長了;如果針對每個VCPU創建一個監聽線程,那么客戶機暫停時間將縮短為多個監聽線程中耗時最長的一個,相比于單監聽線程客戶機性能得到了提升.本文在監聽模塊中使用了線程池技術,其原理是引入concurrent.futures模塊,該模塊可實現并行計算,即使用ThreadPoolExecutor類把監聽多個VCPU事件信息的工作分配給多個Python線程處理,進而實現系統調用二進制信息的快速獲取和解析,降低了客戶機暫停時間,提升了客戶機的性能.
2.3.1 系統調用名和系統調用號解析
在內核中維護著一張符號表System.map被稱作內核符號表,該表記錄了內核中所有符號(函數,全局變量等)的地址及名稱,這其中就包括系統調用表和系統調用名的地址和名稱.系統調用表sys_call_table中各表項是指向實現各種系統調用的內核函數的函數指針,系統調用執行時,系統調用處理程序會讀取rax寄存器來獲取系統調用號,將其乘以4(32位下為4,64位下為8)生成偏移地址,然后以sys_call_table為基址,基址加上偏移地址可得系統調用表項地址,使用libvmi對表項地址進行解析可得系統調用服務例程地址,最后使用libvmi解析服務例程地址可得系統調用名.
解析系統調用名的方法如算法2所示.第1行定義了64位下系統調用表項大小.第2行根據系統調用號rax計算系統調用表項的地址.第3行使用libvmi的read_addr_va()解析表項地址得到系統調用服務例程地址.第4行使用libvmi的translate_v2ksm()解析系統調用服務例程地址得到系統調用名.第5行返回系統調用名.
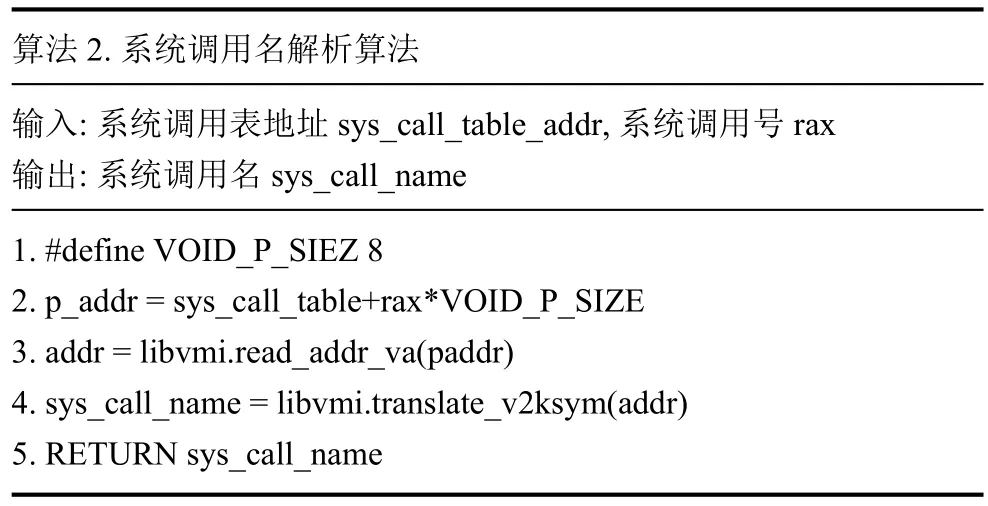
算法2.系統調用名解析算法輸入:系統調用表地址sys_call_table_addr,系統調用號rax輸出:系統調用名sys_call_name 1.#define VOID_P_SIEZ 8 2.p_addr = sys_call_table+rax*VOID_P_SIZE 3.addr = libvmi.read_addr_va(paddr)4.sys_call_name = libvmi.translate_v2ksym(addr)5.RETURN sys_call_name
2.3.2 系統調用參數解析
基于syscall指令的系統調用其參數存放在rdi、rsi、rdx、r10、r8 和 r9 寄存器中,而基于 sysenter指令的系統調用其參數存放在rbx、rcx、rdx、rsi、rdi、rbp中.不同的系統調用參數個數和類型也不同,為了解決系統調用參數解析困難的問題,設計了參數解析模塊.該模塊根據不同類型的系統調用設置了相應的系統調用參數處理規則.例如,針對文件進行操作的open和access系統調用,其第一個參數是所要操作文件的文件名,對該參數的處理規則就是將存放參數的寄存器中的地址信息轉換為文件名對應的字符串,轉換方法為使用libvmi的read_str_va()函數.
2.4 進程區分
現有的系統調用捕獲方法在運行系統調用監控程序時,沒有考慮到進程終結的問題,即不能判斷已經退出的進程,并將屬于該進程的系統調用序列從整個系統調用的序列中剔除.這樣就會存在兩個弊端:第一,存在與已退出舊進程同名同號的新進程,由于監控程序無法判斷舊進程的退出,故會重新掃描舊進程的系統調用序列并加入新進程的系統調用序列,造成新進程系統調用序列不再準確.第二,對于監控程序捕獲到的多個進程的系統調用序列,在上述情況下,每個進程的系統調用序列都不再準確,監控程序所捕獲到的以一個進程系統調用序列為單位的總系統調用序列相應地也不再準確.以上存在的弊端會嚴重降低系統調用序列捕獲的準確率,對宿主機的性能也會產生影響.
針對以上問題,我們需要在捕獲系統調用時及時判斷進程是否退出,如果進程退出,就將屬于該進程的系統調用序列從總的系統調用序列中移除.在操作系統中,進程退出一般會顯式或隱式地調用exit()或exit_group()函數,兩者的區別在于前者只退出該進程,而后者是退出屬于該進程組的所有進程,兩者最后都會調用內核中的do_exit()函數(位于kernel/exit.c函數中).在捕獲系統調用時,判斷進程是否會調用此函數,如果調用了,說明進程已經退出,將其從總的系統調用序列中移除并寫到文件中.
3 實驗與分析
3.1 實驗環境
本實驗是在Linux操作系統下進行的,以KVM作為虛擬化平臺,設計并實現了系統調用監控系統,Qemu版本為2.8;宿主機操作系統版本為ubuntu-16.04-desktop-amd64,內核版本為 4.9,CPU采用24核Intel(R)Xeon(R)CPU E5-2620 v2 @ 2.10 GHz;客戶機操作系統版本為ubuntu-12.04-server-amd64,內核版本為 3.2.0-23-generic,VCPU 為單核,內存為 1 GB.
3.2 實驗結果與分析
3.2.1 系統調用捕獲分析
從宿主機中捕獲的客戶機系統調用序列如圖2所示(左側是客戶機外部視圖,右側是客戶機內部視圖),通過交叉視圖對比發現,客戶機內外系統調用序列完全一致,說明在客戶機外部可以捕獲到客戶機內完整的系統調用序列.

圖2 系統調用序列的捕獲
由于解析的系統調用序列較長,所以此處僅選擇部分解析的系統調用序列進行分析,客戶機內外系統調用參數和返回值對比如圖3所示.

圖3 系統調用參數和返回值
Open系統調用第一個參數為打開文件的路徑名.由內外視圖對比可以發現,open分別打開了/etc/ld.so.cache 和/lib/x86_64-linux-gnu/libc.so.6 文件,這兩個文件分別表示Linux動態共享庫緩存文件和Glibc動態庫文件.O_RDONLY表示以只讀方式打開文件,O_CLOEXEC表示在進程執行exec系統調用時關閉此打開的文件描述符,兩者進行或操作后值為0x80000.客戶機內外部得到的返回值都為3.對比發現,客戶機外部捕獲到的open系統調用參數和返回值是正確的.
Access系統調用是檢查調用進程是否可以對指定的文件執行某種操作.由圖可見,客戶機進程調用了access來確定/etc/ld.so.nohwcap文件是否存在,F_OK在頭文件unistd.h中的預定義為0.對比發現,客戶機外部捕獲到的access系統調用參數和返回值是正確的.
Mmap系統調用是將一個文件或者其它對象映射進內存.其第3個參數PROT_READ和第4個參數MAP_PRIVATE在sys/types.h中分別定義為1和2,其余參數也一致.但是得到的返回值有差異,這是由于strace改變了原來系統調用的走向,使得返回值發生了改變.為了驗證客戶機外部得到的mmap返回值是否正確,本文選擇在測試程序運行過程中輸出mmap的返回值,如圖4所示.對比發現,客戶機外部捕獲到的mmap、open和write系統調用參數和返回值是正確的.
由于本系統對模擬系統調用進入的指令進行重寫,捕獲到了參數,并對參數進行解析將低層次語義信息轉換為高層次語義信息.對模擬系統調用退出的指令進行重寫,捕獲到了返回值.以上實驗數據充分說明本系統在捕獲系統調用方面具有高效性和準確性的特點.

圖4 mmap、open 和 write 參數返回值
3.2.2 性能分析
本文實驗使用了Nbench工具分別對宿主機和客戶機的性能進行了分析.Nbench是一個簡單的用于測試處理器和存儲器性能的基準測試工具,它的測試結果主要分為MEM、INT和FP,MEM指數主要體現處理器總線、CACHE和存儲器性能,INT指整數處理性能,FP指雙精度浮點性能.測試所得數據能夠反映宿主機和客戶機在不同狀態下的性能,即原始狀態的性能①、運行監控程序獲取系統調用原始信息的性能②和對信息進行處理時的性能③,宿主機性能比較如圖5所示,客戶機性能比較如圖6所示.

圖5 宿主機性能比較
根據圖5,可以發現運行系統調用監控程序對宿主機并沒有什么影響,主要是由于宿主機只負責和客戶機進行交互操作以及系統調用信息的處理等操作,而這些操作主要涉及處理器的計算和內存的讀寫,所以性能下降不是很明顯.

圖6 客戶機性能比較
根據圖6,可以發現監控程序在只捕獲客戶機系統調用原始信息的情況下,即運行Nitro的情況下,客戶機的性能下降較小.當監控程序需要對系統調用信息進行處理,也就是需要解析系統調用參數和返回值、進程信息的時候,客戶機的性能下降較多,主要是由于客戶機在調用系統調用退出命令時陷入到VMM中,陷入期間宿主機獲取并解析系統調用參數,客戶機調用系統調用退出命令時再次陷入VMM中,陷入期間宿主機獲取系統調用返回值,這兩步造成客戶機陷入時間過長.針對MEM、INT和FP測試結果,客戶機原始性能指數分別為22.7、29.1和45.7,開啟信息處理之后客戶機的性能指數分別為2.8、2.5和2.7,性能開銷比例分別為 8.1=22.7/2.8、11.64=29.1/2.5和16.9=45.7/2.7.
綜上分析可知,性能開銷在可接受的范圍內,并且在只獲取系統調用原始信息的情況下,性能開銷比例只有1到1.5左右,性能要優于熊海泉等人提出的非陷入系統調用指令捕獲方法[10],其方法首先在VMM中通過監測CR3的更新來識別客戶機內的當前進程,隨后通過修改硬件規范實現對基于sysenter和基于syscall指令系統調用的捕獲,最后基于netlink機制輸出系統調用信息.VMM在創建netlink連接向用戶空間發送系統調用信息時客戶機處于暫停狀態,額外增加了客戶機的性能開銷,其方法對基于sysenter指令系統調用捕獲的開銷比例為2.608=1238.8/475.0,對基于syscall指令系統調用捕獲的開銷比例為2.195=1213.3/552.8.本監控系統性能優于其他方法的原因是在實現仿真指令的重寫過程中即獲取到了系統調用信息并實時傳遞給用戶空間,同時考慮到客戶機存在多VCPU的情況,引入了線程池技術實現系統調用信息的快速捕獲和解析,大大提升了客戶機的性能.
4 結束語
為了解決捕獲客戶機系統調用時無法解析系統調用參數和返回值的問題,本文在KVM虛擬化平臺上設計并實現了一個系統調用監控系統.系統采用了模塊化的設計,內核功能擴展模塊和用戶空間模塊相互配合.該系統不僅可以實時捕獲客戶機內的系統調用序列,同時還可以解析系統調用的參數和返回值,將系統調用的原始信息轉換為高層次語義信息.
目前該系統在解析系統調用原始信息時對客戶機帶來的性能開銷較大,對用戶的使用有些影響.此外,系統未涉及針對基于系統調用的惡意軟件的分析,這些將是我們未來的研究工作.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中國外匯(2019年20期)2019-11-25 09:54:58
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
民主與科學(2014年3期)2014-02-28 11:23:03
機電信息(2014年27期)2014-02-27 15:53:56
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
