基于共享內存優化算法的用采終端實時庫設計實現
2019-03-06 08:24:34曹子濤許金宇
自動化與儀表 2019年2期
關鍵詞:方法
曹子濤,許金宇,熊 劍
(國電南瑞科技股份有限公司,南京211106)
隨著智能電網和智慧城市的快速發展, 以及“電,水,氣,熱四表合一”的試點應用,國家電網公司大力推進智能用電信息采集系統的建設。 面對日趨增加的各類應用,以及物聯網、大數據、人工智能等技術的發展趨勢,大量數據存儲和計算能力成為越來越重要的問題[1-2],對用采終端的數據采集存儲的實時性、高效性提出了更高的要求。 傳統的關系型歷史數據庫需要對磁盤文件進行讀寫操作,運行效率低,無法滿足要求,因此需要高效的實時數據庫進行支撐[3]。
用電信息采集終端(簡稱用采終端)遵循DL/T 698.45《電能信息采集與管理系統 第4-5 部分:通信協議—面向對象的數據交換協議》電力行業標準,其中描述的實時數據可以分為結構化數據和非結構化數據2 類。 結構化數據主要指固定長度和類型的數據,有采集量、參數、控制命令等;非結構化數據主要指長度不定的數據如字節序列、文件等。
目前,針對用采終端設計的實時庫較少,同時未考慮對于結構化數據和非結構化數據的區分,因而不能充分的滿足性能最優和占用空間最小。 文獻[4-5]未對用采終端實時庫的實現做深入闡述,未對性能和空間利用率進行研究;文獻[6]僅介紹了哈希Hash 索引技術, 未指出內存定位和管理等方法;文獻[7]僅給出了粗略的方案設計。 在此所設計的實時庫針對這2 類數據的不同特點采用不同的設計方法,以最大化提高運行效率和內存空間利用率。
1 用采終端實時庫需求分析
用電信息采集終端是執行電能信息采集、轉發控制命令、數據管理、數據雙向傳輸的設備。 數據的采集和管理是用采終端的核心功能,其數據包括實時數據、參數數據、轉發數據、控制命令、事件信息、歷史數據等。 其中,參數數據、計算數據、采集數據等采集終端的核心任務數據,由于對實時性要求較高,需要存入實時庫以便不同的進程進行高效的訪問與更新。
用電信息采集終端往往需要連接大量的電能表和采集器, 其連接方式多種多樣 (電力線載波、RS485、微功率無線),而且采集設備的地理位置分布廣泛,同時要面對各種各樣的用戶類型,包括大型專變、小型專變、單三相一般用戶等[4]。實時、高效地處理如此大量繁雜的數據是用采終端要解決的核心問題。
用采終端的內存容量較為有限,同時內存的使用率對于整個系統的運行情況有著非常重要的影響, 過高的內存使用率會大大降低系統運行速度,因此對于大量數據的處理,在不降低效率的同時盡可能的節省內存空間是非常必要的。
2 用采終端實時庫關鍵技術分析與設計
2.1 用采終端實時庫軟件架構
實時庫位于用采終端的軟件架構中的位置如圖1 所示。 圖中,實時數據庫位于平臺業務層,管理數據采集、任務調度、通信管理等數據的交換。
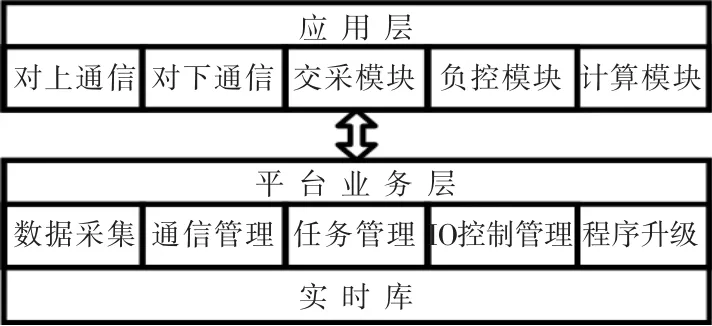
圖1 實時庫架構Fig.1 Real-time database framework
2.2 實時庫索引技術分析與設計
提高實時庫的訪問速度的關鍵在于索引,建立合理的索引可以避免遍歷查找,從而提高實時庫的檢索效率。 實時庫常用的索引包括數組、自平衡二叉樹(AVL)、B/B+樹、T 樹、Hash 索引等。 AVL,B/B+樹、T 樹等算法,在性能或者空間利用率上不太適合隨機散列查找[6],而考慮到用采系統實時庫自身數據類型不固定、隨機查找為主的特點,采用Hash 索引作為用采系統實時庫的索引機制具備最好的時間和空間的平衡性。 另外,在Hash 索引的基礎上,使用Hash 桶來進一步提高查找效率, 同時實現Hash 值的防碰撞功能。
2.3 實時庫的共享內存管理技術分析與設計
使用共享內存是實時庫的必然選擇。 在UNIX中,主要包括進程間通信IPC(inter-process communication)和可移植操作系統接口POSIX(portable operating system interface of UNIX)2 種方法實現[7]。 由于IPC 方法允許使用的內存容量比較有限,考慮到對大量數據的存儲要求,故在此采用POSIX 標準的基于文件映射的共享內存,在擴大一定容量的基礎上而又不損失性能。
如果使用的共享內存超出系統內存容量,POSIX 標準的共享內存會使用磁盤文件進行緩存,一定程度上降低了效率,因此需要盡可能地在不損失效率的情況下節約內存空間。
另外, 由于非結構化數據的長度不統一性,插入記錄時每次會計算分配的地址,從而會有一定的計算耗時, 而如果全部按照統一的長度進行存儲,又會造成較多的內存空間浪費。 因此,針對長度固定和長度不固定的數據進行區分設計,可以較好地解決性能和空間的平衡問題。
3 內存數據庫的實現
3.1 防碰撞的Hash 桶索引技術實現
每張實時庫的表對應另外一個Hash 桶索引表。 選取一個或者多個域作為記錄的關鍵字,內部有N 個桶來存放外部節點信息, 檢索時Hash 函數計算該關鍵字對應的Hash 值, 并將該關鍵字節點根據特定的規則分別放入對應的Hash 桶中。 檢索時,首先根據關鍵字計算獲取該關鍵字位于哪個桶中,然后進行匹配計算比較Hash 值,同時為了防止碰撞的產生,在Hash 值匹配的情況下,會再次比較關鍵字本身的值,從而確保在Hash 值碰撞時, 仍然可以準確查找到關鍵字對應的值。Hash 索引表中存放地址偏移,在訪問記錄時,根據關鍵字查找到對應的內存地址偏移即可高效的訪問數據。Hash桶處理過程如圖2 所示。
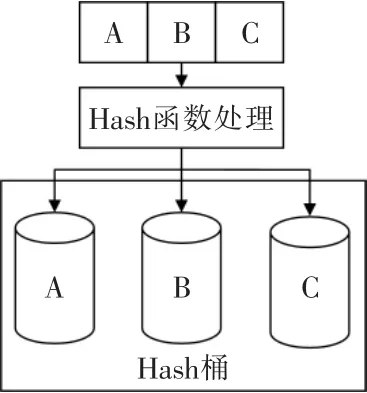
圖2 Hash 桶Fig.2 Hash buckets
3.2 內存直接定位和管理技術實現
記錄的內存地址訪問速度是提高效率的關鍵。在DL/T 698.45 中, 記錄鍵值是對象描述符OAD(object attribute descriptor),即數據的唯一標識。 而Hash 表中存儲的記錄的關鍵字就是OAD, 因此需要根據OAD 在Hash 表中查找到對應的內存地址偏移,以實現內存的直接定位,而對于結構化數據和非結構化數據分別使用不同的地址分配和和訪問方法, 結構化數據使用靜態鏈表索引的映射,非結構化數據采用增加記錄信息頭的方法。
3.2.1 結構化數據
對于結構化數據,由于每條記錄的長度均都一致, 因此每條記錄的起始地址的間隔都是固定的。靜態鏈表的索引可以滿足該特點,把對靜態鏈表插入時分配的位置索引映射到實時庫的表中,就可以滿足內存地址的分配和訪問功能。
在Hash 表中存放記錄對應的靜態鏈表的索引, 訪問時從Hash 表中查找到該記錄對應的索引值,從而直接根據索引乘以每條記錄的長度計算出內存地址。 結構化數據內存結構如圖3 所示。

圖3 結構化數據內存結構Fig.3 Structured data memory structure
3.2.2 非結構化數據
(1)內存管理方法
對于非結構化數據,由于每條記錄的長度不固定,如果采用靜態鏈表映射的方法,每條記錄都按照統一的長度,則在分配內存的時候會造成極大的空間浪費。 同時,對于插入、刪除操作的內存分配可能導致記錄覆蓋等問題,要解決該問題會導致程序處理過于復雜,降低了程序的執行效率,因此設計了一種內存管理的方法。
在每條記錄前存儲本條記錄的信息頭,在預先分配的表空間范圍內對數據進行管理。 其中,信息頭包含了以下信息:當前數據塊的長度、當前數據塊是否空閑、前一個數據塊的長度等。
在插入記錄時,會遍歷空閑的內存空間,直到找到滿足記錄長度的空閑內存空間段, 占用該空間,并返回該空間起始地址,同時分配剩余的空間為空閑的內存空間, 在信息頭內記錄數據長度,同時置為占用狀態。
在刪除記錄時,首先檢查相鄰的內存空間是否也是空閑的,如果是則先合并空閑空間,再把對應信息頭置為空閑狀態。
在Hash 表中存放記錄對應的內存偏移量,訪問時從Hash 表中查找到該記錄對應的地址偏移量, 直接用起始地址加上偏移量計算出內存地址。非結構化數據內存結構如圖4 所示。

圖4 非結構化數據內存結構Fig.4 Unstructured data memory structure
(2)內存碎片整理與備份
對于非結構化數據,由于長期頻繁的插入刪除操作可能會造成內存碎片的問題,降低了內存的使用率,因此需要內存碎片整理功能,釋放與合并所有無法被利用的碎片空間,同時拷貝和移動相應的記錄。
考慮到對內存數據的拷貝和移動有可能會出現錯誤或者異常,因此對移動數據在移動前備份在共享內存中,在發生異常時可以立即快速恢復。
另外,由于整理后的記錄的內存地址偏移量可能會改變, 因此內存整理后的原有的Hash 表中的偏移量需要更新,而原實時庫的訪問在更新后不會受到任何影響。 偏移地址的更新過程如圖5 所示。
4 試驗測試
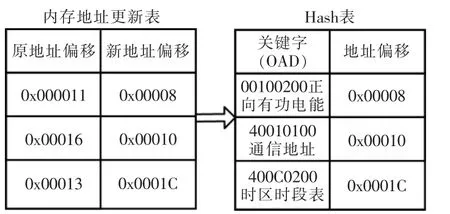
圖5 偏移地址更新Fig.5 Offset address update
為了體現區分結構化數據和非結構化數據不同的設計在效率和占用空間方面各自的性能差異,選取電能量相關數據,對這2 種數據設計了7 種測試方法:總共10 張用采終端的實時庫表,每次對每張表插入、讀取、更新、刪除記錄5000 條,共執行100 次,記錄平均耗時和使用的內存空間。 7 種方法具體如下:
測試1 結構化數據采用非結構化數據的使用方法;
測試2 結構化數據采用結構化數據的使用方法;
測試3 非結構化數據采用結構化數據的使用方法;
測試4 非結構化數據采用非結構化數據的使用方法;
測試5 混合數據全部采用結構化數據的使用方法;
測試6 混合數據全部采用非結構化數據的使用方法;
測試7 混合數據區分采用對應數據的使用方法。
這7 種方法的測試結果包括每張表的平均耗時、使用的總內存空間,具體數據見表1。
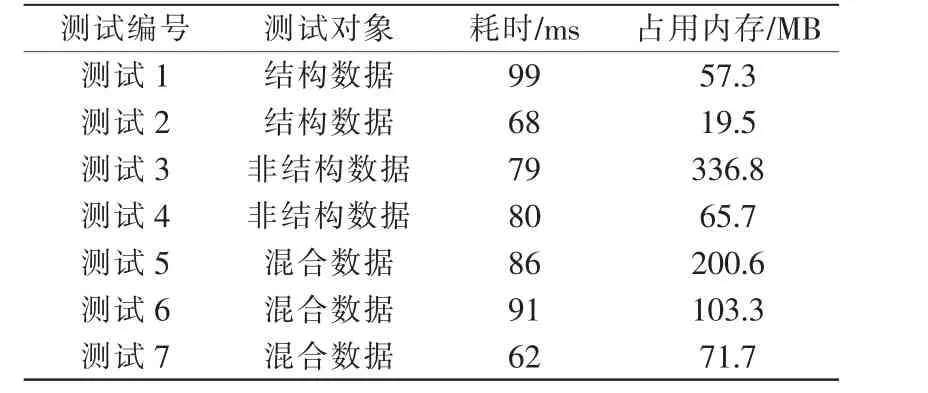
表1 實時庫測試結果Tab.1 Test results of real-time database
實際測試結果表明,結構化數據采用結構化數據的存取方法在時間和空間上均表現更優,而非結構化數據采用非結構化數據的存取方法,在空間的利用率上提升非常明顯,效率上和使用結構化的存取方法幾乎相當,因此使用該方法更優。 而對于同時存在結構化數據和非結構化數據的混合數據,分別使用對應數據的存取方法無論在時間還是空間上都比不加區分的方法更優。
5 結語
詳細闡述了用采終端非關系型實時庫的實現方案, 關鍵在于使用防碰撞的Hash 桶索引表存放地址偏移的直接定位技術,和區分結構數據與非結構數據的內存管理技術, 滿足了實時庫的實時性、高效性,同時實現了對有限內存空間在大量數據處理中的最大化利用。 該實時數據庫已在YDT100 系列用采終端實際應用。 對于未來的大數據分析、物聯網等智能用電技術的發展趨勢,用采終端的實時庫后續需要考慮用電采集系統的分布式遠程交互和大數據分析等功能升級[8-10]。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
