程序分析研究進展*
2019-03-01 10:42:32玄躋峰熊英飛王千祥竇文生陳振邦陳立前
軟件學報 2019年1期
張 健,張 超,玄躋峰,熊英飛,王千祥,梁 彬,李 煉,竇文生,陳振邦,陳立前,蔡 彥
1(計算機科學國家重點實驗室(中國科學院 軟件研究所),北京 100190)
2(中國科學院大學,北京 100049)
3(清華大學 網絡科學與網絡空間研究院,北京 100084)
4(武漢大學 計算機學院,湖北 武漢 430072)
5(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
6(華為技術有限公司,北京 100095)
7(中國人民大學 信息學院,北京 100872)
8(中國科學院 計算技術研究所,北京 100190)
9(國防科技大學 計算機學院,湖南 長沙 410073)
隨著信息化的不斷發展,軟件對人們生活的影響越來越大,在國民經濟和國防建設中具有越來越重要的地位.如何提高軟件質量,保證其行為的可信性,是學術界和工業界共同關注的重要問題.要解決該問題,應加強軟件開發過程管理,在全生命周期采取各種方法和技術提升軟件質量.由于軟件系統的復雜性,在編碼實現完成之后,甚至在軟件產品發布、被廣泛使用之后,往往還有各種各樣的缺陷和漏洞.各種軟件測試和分析技術,是發現這些缺陷、漏洞的有效手段.
不同于很多黑盒測試方法,軟件分析技術可深入軟件系統內部,細致地考察其結構及各個組成部分,進而發現其各種特性,如性能、正確性、安全性等.軟件分析已逐漸發展成為程序語言和軟件工程領域的一個重要研究方向,并已影響到信息安全等相關領域.進入 21世紀以來,該方向進展顯著,研究成果不斷涌現.軟件分析不僅可用來發現軟件中的缺陷、漏洞,還可用于軟件理解、修復以及測試用例生成等方面[1].
軟件包含程序和文檔.由于篇幅所限,本文主要介紹程序分析方面的研究,特別是最近 10余年該方向的一些重要工作.本文將介紹程序分析的基本概念(分析對象、難度、評價等)、主要的基礎性分析技術、針對不同類型分析對象的分析方法等.最后,簡要提及一些挑戰性問題以及新興的研究方向.
1 程序分析簡介
本節介紹程序分析的基本概念、程序及其性質多樣性等,進而解釋程序分析的難度及其評價.
1.1 基本概念
程序分析指的是:對計算機程序進行自動化的處理,以確認或發現其特性,比如性能、正確性、安全性等[2].程序分析的結果可用于編譯優化、提供警告信息等,比如被分析程序在某處可能出現指針為空、數組下標越界的情形等.
傳統上,程序分析包括各種靜態分析技術(類型檢查、數據流分析、指向分析等)與動態分析技術:所謂的靜態分析,是指對程序代碼進行自動化的掃描、分析,而不必運行程序;與靜態分析相對應的是動態分析技術,其利用程序運行過程中的動態信息,分析其行為和特性.
與程序分析密切相關的兩類方法是形式驗證及測試:前者試圖通過形式化方法,嚴格證明程序具有某種性質,目前,其自動化程度尚有不足,難于實用;測試方法多種多樣,在實際工程中廣泛使用,這些方法也是以發現程序中的缺陷為目的,它們一般都需要人們提供輸入數據,以便運行程序,觀察其輸出結果.
1.2 程序及其性質的多樣性
程序分析內涵比較豐富,具有多樣性.
1) 被分析對象的多樣性
程序分析的對象既可以是源代碼,也可以是二進制可執行代碼.對于源程序,根據其實現語言不同,可能需要不同的分析技術.比如,C程序和 Java程序的分析,其技術可能就不一樣:后者需要處理一些面向對象的結構.即使是同一種高級語言編寫的程序,也可能具有不同的特性.比如,程序中是否有比較多的指針?是否使用并發控制結構、通信機制?是否有大量的數值計算.從規模看,被分析的程序可以是幾百行的代碼,也可以是幾十萬行乃至于上千萬行代碼.
2) 程序性質的多樣性
對不同類型的程序,在不同的應用環境下,人們關注的性質也不一樣.以 C程序為例,很多 C程序會用到指針,用于動態分配、釋放內存.對這樣的程序,人們會關注空指針、內存泄漏等問題.但對某些嵌入式系統來說,程序中很少動態分配內存空間,卻可能要處理中斷.另外一些 C程序可能有大量的數值(浮點數)計算,程序員可能更關注其中是否存在溢出問題.
1.3 程序分析的難度及評價
由于程序語言的復雜性、程序性質的多樣性,自動化的程序分析往往具有相當大的難度.根據Rice定理:對于程序行為的任何非平凡屬性,都不存在可以檢查該屬性的通用算法[3].也就是說,大量的程序分析問題都是不可判定的.比如,一般情況下,程序的終止性就是不可判定的.也就是說,不存在一種算法,它能判斷任何給定的程序是否總能終止.程序路徑的可行性(path feasibility)也是不可判定的[4].如果存在輸入數據使得程序沿著一條路徑執行,程序中該路徑被稱為是可行的(feasible).沒有一種算法,它能判斷程序中某條給定路徑是否可行.最近,Cousot等人[5]從抽象解釋的角度形式化地證明了:從可計算性角度看,相比程序驗證(只需要檢查一個給定的程序不變式是否正確),程序分析(需要綜合出正確的程序不變式)是一個更難的問題.具體而言:對于證明有窮域上的程序斷言,程序分析與程序驗證是等價的問題;但是對于無窮域上的斷言,程序分析比程序驗證更難.
鑒于程序分析的理論難度以及被分析程序的復雜度,我們往往不要求對程序進行完全精確的分析.這就可能帶來誤報(false positive)、漏報(false negative)等問題:前者指的是報警信息指出的缺陷實際上不存在、不可能發生;后者指的是程序中存在的某個缺陷,沒有被程序分析工具所發現.
對程序分析技術或工具進行評價,不僅要看其分析對象的規模、復雜度,分析過程的效率,還要看其對用戶的要求,發現缺陷的嚴重程度,以及誤報率、漏報率等.
2 程序分析方法和技術
本節主要介紹一些近期有重要進展的程序分析方法和技術,包括抽象解釋、數據流分析、基于摘要的過程間分析、符號執行、動態分析、基于機器學習的程序分析等.這6項方法和技術的關系如圖1所示.
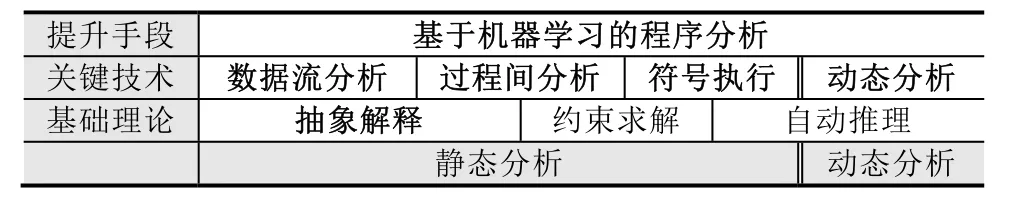
Fig.1 Main program analysis techniques圖1 主要的程序分析技術
程序分析總體可以分為靜態分析和動態分析,涉及的基礎理論包括抽象解釋、約束求解、自動推理等.而靜態分析的關鍵技術包括數據流分析、過程間分析、符號執行等.最后,近期機器學習技術被用于提升各種不同的程序分析技術.
除了這 6種基本程序分析技術之外,還有一些其他廣泛使用的程序分析技術也在近期有顯著進展,如污點分析、模型檢驗、編程規則檢查[6]等,由于受篇幅所限,本文將不再對這些技術進行詳述.
2.1 抽象解釋
抽象解釋是一種對程序語義進行可靠抽象(或近似)的通用理論[7].該理論為程序分析的設計和構建提供了一個通用的框架[8],并從理論上保證了所構建的程序分析的終止性和可靠性(即考慮了所有的程序行為).基于抽象解釋來設計程序分析,本質上是通過對程序語義進行不同程度的抽象,以在分析精度和計算效率之間取得權衡.這種由某種語義抽象及其上的操作所構成的數學結構稱為抽象域.抽象解釋采用 Galois連接來刻畫具體域與抽象域之間的關系.設〈D,?〉和〈D#,?#〉是兩個給定的偏序集,函數α:D→D#及γ:D#→D構成的函數對(α,γ)稱為D與D#之間的 Galois連接,當且僅當?x∈D,x#∈D#,α(x)?#x#?x?γ(x#),其中,〈D,?〉稱為具體域,〈D#,?#〉稱為抽象域,α稱為抽象化函數,γ稱為具體化函數.由定義中的性質α(x)?#x#(亦即x?γ(x#))可知,x#是x的可靠抽象(又稱上近似).給定具體域〈D,?〉和抽象域〈D#,?#〉之間的 Galois 連接(α,γ),對于具體域D上的函數f和抽象域D#上的函數f#,當?x#∈D#,(f?γ)(x#)?(γ?f#)(x#)時,我們稱f#是f的可靠抽象.抽象解釋理論的一個重要思想是,通過在抽象域上計算程序的抽象不動點來表達程序的抽象語義.在程序分析中,程序狀態集合通過抽象域中的域元素來近似,而程序語義動作(如賦值、條件測試等)通過抽象域中的域操作(如遷移函數)來可靠建模.此外,為了加速抽象域上不動點迭代的收斂速度并保證不動點迭代的終止性,抽象解釋框架提供了加寬算子(widening).抽象解釋框架能夠保證抽象域上迭代求得的抽象不動點是程序最小不動點(對應程序的具體聚集語義)的上近似.換言之,抽象解釋提供了嚴格的理論來保證基于上近似抽象的推理的可靠性,即:所有基于上近似抽象推理得出的性質,在原程序中也必然成立.但是,由于抽象帶來的精度損失,不保證所有在原程序中成立的性質都能基于上近似抽象推理得到.
抽象域是抽象解釋框架下的核心要素,一般是面向某類特定性質設計的.到目前為止,已出現了數十種面向不同性質的抽象域.其中,具有代表性的抽象域包括區間抽象域、八邊形抽象域、多面體抽象域等數值抽象域.此外,還出現了若干開源的抽象域庫,如APRON[9]、ELINA[10]、PPL[11]等.基于抽象解釋的程序分析工具也不斷涌現,出現了 PolySpace[12]、Astrée[13]等商業化工具和 Frama-C Value Analysis[14]、CCCheck(code contract static checker)[15]、Interproc[16]等學術界工具.隨著這些工具的日益完善,抽象解釋在工業界大規模軟件,尤其是嵌入式軟件的分析與驗證中得到了成功應用.典型的應用案例是,Astrée成功應用于空客A340(約13.2萬行C代碼)、A380(約35萬行C代碼)等系列飛機飛行控制軟件的自動分析并實現了分析的零誤報[17].最近,Astrée的擴展版本AstréeA支持多線程C程序中運行時錯誤、數據競爭、死鎖等的檢測,并成功應用于ARINC 653航空電子應用軟件(約220萬行代碼)的分析[18].總體而言,基于抽象解釋的程序分析主要面臨提高分析精度、可擴展性兩方面的挑戰.
在提高分析精度方面,基于加寬的不動點迭代過程所導致的分析精度損失問題和抽象域本身表達能力的局限性是當前面臨的主要問題.
· 在緩解加寬所導致的精度損失方面,近年來的研究進展大致可以分為兩種思路:(1) 使用基于策略迭代[19]或抽象加速[20]的不動點迭代過程來取代傳統的基于加寬的不動點迭代過程,以獲得更精確的分析結果,但是,該方法只適用于一些特殊類別的程序和抽象域;(2) 改進加寬/變窄算子及其迭代序列,如結合加寬變窄算子的交疊迭代策略[21].
· 在彌補抽象域本身表達能力的局限性方面,最近的研究進展可分為3類:(1) 將符號化方法與抽象方法結合起來,利用SMT求解器[22,23]、插值[24]等技術來計算程序中語句遷移函數的最佳抽象,以改進抽象域在語句遷移函數上的精度損失;(2) 提高抽象域的析取表達能力,如基于區間線性代數、絕對值約束、集合差、非格結構、決策樹等方法構造的非凸抽象域[25,26];(3) 提高抽象域的非線性表達能力,如基于組合遞推分析[27,28]將符號化分析與抽象解釋結合起來以生成多項式、指數、對數等形式非線性不變式,基于橢圓冪集來生成二次不變式[29]等.
在提高可擴展性方面,如何有效降低分析過程中抽象狀態表示與計算的時空開銷是目前考慮的主要問題.在這方面,最近的研究進展包括:
· 利用變量訪問的局部性原理,降低當前抽象環境中所涉及的變量維數,并根據數據流依賴的稀疏性,降低抽象狀態的存儲開銷和傳播開銷.基于該思想,最近,Oh等人提出了一種通用的全局稀疏分析框架,在不損失分析精度的前提下能夠顯著降低時空開銷,并在靜態分析工具Sparrow上進行了應用,取得了顯著的可擴展性提升效果[30,31];
· 利用矩陣分解等在線分解優化策略來對抽象域操作的算法進行優化.基于該思想,最近,Singh等人[32,33]對常用的八邊形抽象域、多面體抽象域的實現進行了優化,優化后,分析的性能取得了顯著的提升,性能提升最大的達 140多倍;在此基礎上,Singh等人還提出了一種通用的基于分解的優化策略[34],能夠在不改變基抽象域的基礎上自動實現基于分解的優化,從而無需人工重新實現基抽象域,并基于這一思想實現了開源抽象域庫ELINA.這種基于在線分解的方法不會造成精度損失.
最近,Singh等人[35]還提出了一種基于強化學習來加速靜態程序分析的方法,在每次迭代過程中,利用強化學習來決策選擇哪個轉換子,以在精度和不動點迭代收斂速度之間進行權衡.在抽象域編碼實現上,Becchi等人[36]最近改進了未必封閉多面體域(支持嚴格不等式約束)的雙重描述法,在表示中避免了松弛變量的引入,極大地提高了分析效率,并開發了多面體域的開源實現PPLite.
此外,將抽象解釋應用到特定類型程序或特定性質的分析驗證方面的研究也取得了不少進展,主要的關注點包括復雜數據結構自動分析的支持、不同譜系目標程序的支持、活性性質分析的支持.在復雜數據結構的自動分析方面,最近的研究重點關注針對數組內容的精確分析[37]、混雜數據結構的建模[38]、數值與形態混合的程序分析[39,40]、關系型形態分析[41].在支持不同譜系目標程序方面,最近的研究重點關注多線程程序的自動分析[18]、中斷驅動型程序的自動分析[42,43]、概率程序的分析[44,45]、操作系統代碼的安全和功能性分析[38,46]、JavaScript等動態語言的分析[47]、二進制代碼的分析[48]、Web應用程序的安全性分析[49].在目標性質支持方面,近年來,在抽象解釋領域出現了一些新的用來分析時序性質和終止性的方法[50-52].
未來,抽象解釋技術將進一步在新的架構、語言、應用等實際需求驅動下不斷發展.值得關注的方向包括對弱內存模型的分析驗證[53,54]、神經網絡的分析與驗證[55,56]、大數據處理相關錯誤的分析[57]、Python程序的自動分析[58]等.與約束求解、自動推理、人工智能等基礎支撐技術的緊密結合,將是抽象解釋后續的研究趨勢之一[59-61].同時,降低誤報率將依然是基于抽象解釋的程序分析技術拓展實際應用的研究挑戰和重點.
2.2 數據流分析
數據流分析通過分析程序狀態信息在控制流圖中的傳播來計算每個靜態程序點(語句)在運行時可能出現的狀態.經典的數據流分析理論[62]用有限高度的格〈L,?〉來抽象表示所有可能狀態的集合,并對每個程序語句定義一個單調的轉移函數(transfer function),以計算其對程序狀態的更新.數據流分析可以是前向或后向,對應程序狀態信息在控制流圖中的前向或后向傳播.在程序控制流圖中,多個分支交匯的程序點狀態為其所有前驅(或后繼,如果是后向傳播)程序點狀態的?,表示不同執行路徑下可能出現的所有程序狀態.
數據流分析為抽象解釋的一個特例,其計算的狀態信息(抽象域)局限于有限高度的格〈L,?〉.數據流分析已經在編譯器實現中得到廣泛應用,常見的應用包括常數傳播分析、部分冗余分析等.相比于通用的抽象解釋理論,經典數據流分析的實現可以通過一個迭代計算框架來計算所有語句的輸出直至不動點.單調性和格的有限高度保證了數據流分析迭代計算框架的收斂性,而無需引入加寬算子.編譯器中的數據流分析多為過程內數據流分析,全局過程間的分析可以使用基于摘要的方法,通過對函數自動分析摘要得以實現.近年來,對數據流分析方向的應用已不僅僅局限于編譯優化,研究者們也提出了多種方法來高效實現過程間的上下文敏感的數據流分析,主要包括如下兩種方法.
1) IFDS/IDE數據流分析框架
IFDS分析框架由Reps等人[63]于1995年提出.IFDS將抽象域(即數據流分析計算的狀態信息)為滿足分配性的有限集合的一大類數據流分析問題轉換為一個圖可達問題,從而能夠有效地進行上下文敏感的過程間分析.IFDS框架基于程序過程間控制流圖定義了一個超級流圖(supergraph),其中,每個節點對應在一個程序點的抽象域中的一個元素;而節點間的邊表示該元素在過程間控制流圖的傳播,對應著數據流分析中的轉移函數.通過求解是否存在從程序入口到每個程序點的一個可達路徑,我們可以得到該程序點的狀態信息.基于該分析方法的框架已經實現于開源分析系統,如Soot[64]和Wala[65]中,并廣泛用于包括Android污點分析[66]在內的多種應用中.
Reps等人[67]后續進一步擴展了該框架,通過已有抽象域為環境而計算得到新的屬性,用于過程間常數傳播等應用中,并形式化定義了上述圖可達問題為上下文無關文法圖可達問題.上下文無關文法圖可達問題對圖中的邊進行標號,圖中任意兩點可達需要兩點間的一條路徑上的標號串滿足事先定義的上下文無關文法.多種不同程序分析問題均可表示為對上下文無關文法圖可達問題的求解.近年來,包括指針分析[68,69]、并行程序分析[70,71]等多種分析技術均通過求解上下文無關文法圖可達問題來有效地加以實現.
2) 基于值流圖的稀疏數據流分析方法
傳統的數據流分析在程序控制流圖上將所需計算的狀態信息在每個程序點傳播得到最終分析結果.此過程通常存在較多冗余操作,對效率,特別是過程間數據流分析效率會有很大影響.為了進一步提高數據流分析的效率,近年來,研究者們提出了多種稀疏的分析方法,從而無需計算狀態信息在每個程序點的傳播即可得到與數據流分析相同的結果.該類分析技術[72-76]通過一個稀疏的值流圖(value flow graph)直接表示程序變量的依賴關系,從而使得狀態信息可以有效地在該稀疏的值流圖上傳播.該值流圖保證了狀態信息可以有效地傳播到其需要使用該信息的程序點,并避免了在無效程序點的冗余傳播,可大幅度提高效率.
2.3 基于摘要的過程間分析
摘要(summary)是可復用的程序模塊分析結果,能夠簡要地刻畫模塊的外部行為.創建摘要和利用摘要開展分析的過程稱為摘要分析.在編寫程序的過程中,一個程序模塊往往需要調用其他程序模塊.對主調(caller)模塊的分析必然涉及到對被調模塊(callee)的分析.與復用被調模塊代碼可提高軟件生產效率類似,摘要分析期望復用被調模塊的分析結果也能提高分析主調模塊的效率.通過基于摘要的程序分析技術,我們將被復用模塊的分析結果被構造成為摘要,并在分析主調模塊時對其實例化,以加快分析速度.
傳統摘要分析的研究主要關注模塊化(modular)分析,即:在分析過程中將軟件劃分為多個模塊,對各個模塊分別分析和創建摘要,然后合并摘要獲得整體的分析結果.這樣,在分析過程中創建摘要的技術也稱為在線摘要技術.摘要分析在最近 10年的主要進展是離線摘要技術,即:在程序分析之前對常用代碼庫生成摘要,從而加快使用這些代碼庫的客戶端的分析速度.離線摘要根據其自動化程度的不同,可以分成人工編寫摘要和自動生成摘要,分別在接下來的兩小節中加以介紹.
1) 人工編寫摘要
對于程序中一些難以分析的代碼,例如第三方的庫和系統代碼等,可采用人工編寫摘要的方式近似代碼的行為.這種技術原先應用于程序驗證中,比如ESC/Java通過用戶提供的前置條件和后置條件來對程序進行模塊化驗證.FlowDroid[66]在處理調用系統代碼和調用其他組件時,采用由人工來編寫的近似摘要.這樣的摘要能夠模擬被調模塊中的常見數據流路徑.這種方式沒有考慮到用戶編寫的代碼對被調模塊的影響.Ali和Lhoták[77,78]提出了一種對庫建立輕量級的上近似摘要.這種摘要的建立,需要代碼庫滿足分離編譯假設(separate compilation assumption),無需應用代碼即可編譯代碼庫.Java代碼庫普遍滿足這項假設.在該假設約束下的Java標準庫被簡化為一個人工編寫的占位庫,而這個占位庫的文件僅有80KB大小,遠小于Java標準庫的原本大小.Ali和Lhoták[77,78]的方法改造了現有的全程序調用圖構造算法,以占位庫作為所有庫函數的替代品,所有應用代碼與庫函數代碼間的調用關系被簡化為應用代碼與占位庫間的調用關系.該方法既提升了效率(10倍以上),又保證了正確性,并且有足夠的精確度.
2) 自動生成摘要
在程序分析過程前創建摘要,通常是對程序常用的模塊(如 Java代碼庫)進行摘要分析,隨后加速客戶代碼的分析.諸多的未知信息[79]和代碼庫太大造成算法難以擴展.Cousot[80]從理論上總結了創建模塊摘要的各種方式.該工作首先分析了創建模塊摘要的主要問題是處理模塊間的環形依賴.在沒有環形依賴時,我們可以按照依賴關系給模塊排一個順序,每個模塊只依賴于之前的模塊,然后按順序依次分析.但是,由于環形依賴的存在,所有環形依賴的模塊就只能被當作一個模塊分析,使得創建模塊的摘要無法進行.文獻[80]針對環形依賴給出了3種解決方案.
· 基于簡化的分析:這個方案的思路是針對環形依賴導致的大模塊上的分析通過標準的編譯技術(如partial evaluation)進行化簡,提高分析速度.每個模塊上的分析程序可以被當成是一個函數,然后,把這些函數看成是標準程序之后就可以應用普通的程序分析進行化簡了;
· 最壞情況分析:每個模塊分別分析,對于該模塊所依賴的其他模塊作最壞情況假設.這樣的分析會導致不精確,并且在多數情況下嚴重不精確;
· 符號化關系型分析:把未知的信息做成符號化信息,然后把程序分析轉變成符號化分析.所有與符號化相關的部分不進行計算.
Smaragdakis等人[81]提出了針對所有流不敏感指針分析的代碼庫預處理技術,屬于基于簡化的分析.該工作發現:當代碼中存在符合圖代碼模式時,將模式中的冗余語句刪除,進而避免冗余運算,加速代碼分析.Rountev和Ryder[82]提出了另一種代碼庫的簡化方式,對庫的摘要就是把庫里面所有的賦值語句提取出來.這個摘要本身只是省掉了語法分析的時間.然后在摘要上進行了兩個優化.
a)對于連續賦值,比如a=b;c=a;去掉中間變量,替換成c=b;
b)去掉與客戶端無關的賦值語句.
這兩個優化能省掉4%~69%的時間.該方法僅支持上下文不敏感且流不敏感的分析.
Rountev等人[83,84]提出的構件級別分析(component-level analysis)對代碼庫的IFDS/IDE框架進行了摘要分析.該方法采用 Sharir和 Pnueli[85]提出的函數型分析方法,為過程內的數據流和過程間的部分數據流建立了摘要.對于過程間邊相關的未知量,即虛函數調用(virtual function)和回調點(callback site),該方法在計算過程中不予考慮.該方法只考慮了函數中的局部變量.StubDroid[86]在 FlowDroid的基礎上采用了構件級別分析對庫進行了自動分析,支持多層字段敏感性,無需手動編寫摘要.
Tang等人[87]提出了條件可達性,解決了傳統摘要無法描述的回調函數問題.具體而言,該工作考慮了過程間的數據依賴分析.當代碼庫存在回調函數時,部分信息缺失導致已有方法難以為代碼庫建立有效的摘要.為了處理回調函數帶來的影響,該工作提出了基于樹-鄰接語言的可達性的摘要分析技術.注意到包含回調函數信息的可達性關系(稱為“條件可達性關系”)可用于加速用戶代碼的分析.為描述條件可達性關系,該工作引入了原本用于描述自然語言語法的形式語言——樹-鄰接語言,提出了樹-鄰接語言的可達性分析技術.樹-鄰接語言可達性擴展了表達兩點間可達關系的傳統上下文無關語言可達性,具有表達 4個點之間的可達關系的能力,從而更自然地描述了上述條件可達性關系.實驗結果表明:建立基于樹-鄰接語言的可達性摘要可以在合理的時間內完成,該技術所建立的摘要可以使得對用戶代碼分析的效率平均提高約8倍.在后續工作中[88],Tang等人進一步將該方法擴展到了 Dyck-CFL可達性分析上.該方法通過直接在較為通用的 CFL可達性分析過程[67]中引入帶條件邊,使得大量基于CFL可達性的分析就可以直接支持條件摘要.同時,該方法引入橋接邊來避免條件組合爆炸的問題.通過這些處理,該方法避免了原有的 Dyck-CFL分析中摘要不完整和分析效率不高的問題.實驗結果表明,其分析速度相比樹-鄰接語言進一步提升了3倍多.
由于模塊含有大量的未知量,建立考慮所有情況的摘要在許多分析任務中非常困難.所以,一些工作通過動態程序分析或訓練的方式建立了部分摘要.Palepu等人[89]提出了加速程序分析速度的動態依賴摘要技術(dynamic dependence summary),提前創建軟件庫的摘要,用來快速創建程序切片.盡管得到的是不充分的摘要,導致生成的程序切片并不保證完全正確,然而在程序測試的實踐中能夠找到大部分的錯誤.Kulkarni等人[90]采用跨程序的訓練辦法為代碼庫建立不完整的摘要,以提高客戶代碼的分析速度.該方法基于 Datalog語言,有效地對中間計算過程進行剪枝,并將剪枝結果記錄于摘要中.同時,該方法還對 Datalog語言進行改造,使得利用摘要進行分析時可以跳過中間計算過程.該方法保證正確性的方式是人工編寫時間復雜度較低的規則,判斷訓練得到的摘要是否能夠保證正確:如果不能保證正確性,則不采用摘要來進行計算.
上述工作都是針對整個代碼庫進行摘要分析.當精度要求較高時,分析完整的代碼庫比較困難.部分工作只對單個函數進行分析.Yorsh等人[91]提出的框架可以為函數建立精確而簡練的函數摘要.在不同上下文環境中,采用函數摘要與重新分析函數所得到的最終結果相同,從而保證精確性.框架中采用有限顯式輸入輸出表來表示摘要,并通過摘要組合操作,使得不同上下文之下分析過程的相似之處得以合并為更加簡練的形式,從而利用有限的數據結構表達無限可能的函數行為.該框架采用了微轉換子,微轉換子可以編碼的問題包括IFDS/IDE問題.該框架還可以解決模塊的線性常量傳播問題和模塊的類型狀態[92]檢驗問題.
Dillig等人[93]的工作是針對C的上下文敏感、流敏感、不考慮字段的函數指向分析.核心問題是分析一個函數時,如何考慮所有可能的調用上下文.解決方案是將函數參數所有可能的別名關系編碼到一個二部圖上,一邊是參數,另一邊是符號化的位置,表示彼此不交的內存地址集合,中間連上帶約束的邊,編碼了不同的別名關系.當遇到語句的轉移函數時則采用圖上再加一層的方法來保證流敏感性,這樣可以做到強更新.函數調用處理方面,需要計算出被調函數的別名情況,實例化主調函數的摘要,再把調用函數的圖和被調函數實例化的圖拼起來.通過不動點算法計算出一個上近似的結果.
2.4 符號執行
符號執行[94-97]是一種相對精確的程序分析技術.傳統的符號執行技術使用符號化輸入代替實際輸入以模擬執行(不實際執行)被分析程序,程序中的操作被轉化為相應的符號表達式操作.在遇到條件語句時,程序的執行也相應地分叉以探索每個分支,分支條件則被加入到當前路徑的路徑條件(path condition)中.通過調用 SAT/SMT求解器,對路徑條件的可滿足性進行求解來加以判斷:如果判定結果為可滿足,則說明路徑實際可行(存在具體輸入能夠讓程序產生此路徑);如果判定結果為不可滿足,則表明此路徑不可行,終止對該路徑的分析.
在約束條件可被判定的情況下,符號執行提供了一種系統遍歷程序路徑空間的手段.符號執行中的程序路徑精確刻畫了程序路徑上的信息,可基于路徑信息開展多種軟件驗證確認階段的活動,包括自動測試、缺陷查找以及部分的程序驗證等[98].理論上,相比于需要固定程序輸入的分析方法,符號執行通過符號分析,可覆蓋更多的程序行為.另一方面,符號執行技術依賴于 SAT/SMT技術,求解器的能力是決定符號執行效果的關鍵因素.符號執行中,程序路徑空間大小隨著程序規模的擴大而呈指數級增長.例如:單就串行程序而言,一個具有n個條件語句的程序段就有可能包含2n條路徑,這也是制約符號執行能力的關鍵因素.
最初,符號執行主要用于程序自動測試,但受制于當時的計算能力和求解技術與工具的能力,符號執行技術并沒有得到實際的應用.近年來,隨著計算能力的提高、SAT/SMT技術和工具的蓬勃發展[99-101],符號執行技術得到了長足的進步,出現了以動態符號執行(concolic testing)[102,103]為代表的一批新的符號執行方法或技術,以及以 SAGE[104]、KLEE[105]、SPF[106]、Pex[107]、S2E[108]為代表的符號執行工具.
不同于傳統的符號執行,動態符號執行[102,103]實際運行被分析的程序,在實際運行的同時收集運行路徑上的路徑條件,然后翻轉路徑條件得到新的路徑條件,通過對新的路徑條件進行求解得到新的程序輸入以再一次地運行被分析程序,從而探索與之前運行不同的程序路徑.由于在實際運行程序過程中,動態符號執行在碰到復雜或不可解的路徑條件時,可以使用實際值來簡化路徑條件.在碰到外部調用時,也可以通過實際執行來緩解外部調用的問題.因此,在方法層面,動態符號執行通過犧牲部分分析的可靠性來提高方法的可擴展性和可行性.
目前,符號執行技術仍然面臨提高可擴展性(scalability)與可行性(feasibility)這兩方面的挑戰:可擴展性挑戰是指如何在有限資源(比如時間、內存)的前提下提高符號執行的效率,更快地達成分析目標;可行性挑戰是指如何支持不同類型分析目標的符號執行,權衡分析的可靠性與精確性.已有的研究工作基本都是圍繞這兩個方面展開.
在可擴展性方面,路徑空間爆炸和約束求解是主要的兩大難題.在緩解路徑空間爆炸方面,目前已有的工作基本分為兩個思路:(1) 在具體目標下提供高效的搜索策略,使符號執行分析更快地達到目標,包括提高程序的覆蓋率[105,109-111]、判斷某個程序點是否可達[112]、產生滿足正規性質的程序路徑[113]、探索程序不同版本的差異部分[114,115]等;(2) 通過約束輸入范圍、削減或合并路徑來減小程序的路徑空間,包括基于輸入模版[116,117]、程序切片[118-121]、程序抽象(包括摘要技術)[122-129]、偏序約減[130,131]、條件合并[132,133]以及等價路徑約減[121,134-136]等一些方法.在約束求解方面,已有的工作也可分為兩個方面:(1) 在調用求解器之前對路徑條件的查詢進行優化,以減少求解器的調用次數或縮短求解時間,包括查詢緩存和重用[105,137-139]、基于約束獨立性的優化[103,105]、增量式求解[105,140]等;(2) 支持復雜程序特征的高效編碼,包括對機器數[104,105]、數組[100,105]、浮點[141-145]、字符串[146]、動態數據結構[147-149]等方面的支持.
在可行性方面,環境建模和多形態分析目標的支持是目前的主要問題.在環境建模方面,已有的工作基本都是在分析的精確性、可靠性、建模工作量以及可擴展性之間進行權衡和折中,包括手工建模[105,106]、自動合成[150]、動態執行[102]、全棧執行[108]等.在多形態分析目標方面,主要是應對多語言和多應用領域的復雜性,包括二進制程序[108,151,152]、腳本語言程序[153]、分布式程序[154]、數據庫操作程序[155]、無線傳感器網絡程序[156]、并發或并行程序[135,157,158]、嵌入式程序[159]、PLC程序[160]等符號執行方法.
同時,面向新的分析需求,也有一些新的符號執行技術出現,其中比較有代表性的是概率符號執行技術[161-163],其基本思想是:通過符號執行來得到程序的路徑,然后使用SMT解空間體積計算技術來計算每條路徑的路徑條件的解的個數,通過每條路徑對應的解的個數,可以計算每條路徑的概率.基于此,可以開展包括低概率缺陷查找、低概率路徑的測試用例生成、生成程序的性能分布[164]、刻畫代碼變遷[165]等活動.
隨著符號執行技術近些年的發展,符號執行技術在工業界也得到了實際的采納和應用,其中有代表性的工作有:微軟公司把自己開發的二進制動態符號執行工具SAGE用于Win 7的測試,發現了文件模糊測試中1/3的缺陷[166].由于SAGE通常是微軟公司最后使用的缺陷檢測工具,因此,這些由SAGE發現的缺陷,很多都沒有被之前在開發過程中使用的靜態分析工具、黑盒測試工具所發現.微軟公司多個開發小組已把SAGE作為日常工具在使用,SAGE目前也被商業化為微軟公司的安全風險檢測(microsoft security risk detection)服務.微軟公司在Visual Studio 2015中正式發布了基于動態符號執行的C#自動單元測試工具IntelliTest[167],可大幅度提高C#程序單元的測試效率.C程序符號執行工具KLEE[105]對GNU Coreutils程序集進行了自動測試,可自動達到94%的語句覆蓋率,并發現3個程序崩潰問題;Canalyze[168]在開源軟件中發現數百個真實缺陷,并在工業界嵌入式系統中發現兩個缺陷.2016年 8月,在美國DARPA舉辦的網絡空間安全競賽(CGC)中,最終排名前三的參賽隊伍全部使用了符號執行技術,用于自動發現并利用二進制程序中的漏洞.美國 GrammaTech公司開發的商業程序分析工具CodeSonar中也使用了符號執行技術,用以發現程序中的深層缺陷.
未來,符號執行技術將進一步在軟件工程、安全、系統、網絡等相關領域的實際需求驅動下不斷發展.面向大規模軟件的高效符號執行方法、技術和工具將是下一步研究所面臨的挑戰和重點.同時,符號執行搜索策略的更加智能化[169]也將是下一步的研究重點.此外,與其他技術在不同層面的密切結合[170-173],以進一步提高軟件分析效果,也將成為符號執行后續的研究趨勢之一.
2.5 動態分析
動態分析是指通過在指定測試用例下運行給定的程序,并分析程序運行過程或結果,用于缺陷檢測等.與靜態分析相比,動態分析能夠更好地處理編程語言中的動態屬性,例如指針、動態綁定、面向對象語言中的多態與繼承、線程交替等.動態分析在一定程度上彌補了靜態分析的不足之處.
基本的程序動態分析可以簡單地分為在線(online)動態分析與離線(offline)動態分析[1].在線動態分析是指在程序的運行過程中分析當前程序行為;而離線動態分析需要記錄程序的運行行為,在程序運行結束后再進行分析.兩者的基本思想都是通過對程序運行過程或者結果的分析,查找定位缺陷.具體來說,一方面可以將程序運行結果和預知結果對比,確定程序中是否含有缺陷;另一方面,可以通過插樁或其他監控技術分析程序的運行行為,查找錯誤的行為.前者很直觀,但是對于被觸發了卻沒有反映在輸出中的缺陷無法檢測;后者則可以直接觀察到程序中缺陷的觸發,即使該次觸發并沒有導致錯誤的輸出.但是后者需要提前定義錯誤的行為,其對于非常見的缺陷無法檢測.已有文獻中有大量這方面的介紹[174].
程序動態分析,從報告缺陷的準確性出發,也可以分為:(1) 缺陷動態檢測;(2) 缺陷動態預測.一般所指的缺陷動態查找方法是缺陷動態檢測,是指在程序的運行過程中某個缺陷已經發生了之后的檢測,即,缺陷已經反映在程序行為中或者運行結果中.其關注點是:如何設計檢測算法等,保證將所有已經發生的缺陷檢測出來.然而,程序中的不同缺陷不會都在有限的若干測試用例中被觸發.因此,為了提高缺陷動態檢測的有效性,需要從程序若干次運行中預測出該程序潛在的某些行為,并判斷這些潛在行為是否會觸發缺陷.這種方法稱為缺陷的動態預測.例如:某個程序中存在一個緩沖區溢出缺陷,該缺陷只有在輸入input大于128時發生.那么,如果我們可以從某個input不大于128的輸入下預測對應行為是一個潛在缺陷,其可能會在input大于128時發生.進一步地,我們可以構造一個滿足預測條件的輸入,再次運行程序去觸發(驗證)缺陷.缺陷的動態預測在并發程序的動態分析中經常用到,主要原因之一是:并發程序的運行除了與輸入有關外,還與程序中線程之間的調度有關.程序缺陷的動態預測還會涉及到一些其他技術,例如,測試用例生成、約束求解、缺陷重現、線程調度等,其分析過程與缺陷動態檢測相比更為復雜.
2.6 基于機器學習的程序分析
經典的程序分析技術提供相對精確的分析結果,但同時也帶來了包括路徑組合爆炸、誤報率較高等一系列在實踐中不可避免卻難以應對的問題.隨著近年來通用計算設備能力的提高,海量的程序執行數據被存儲和管理;研究者采用機器學習、統計分析等系列技術提升現有的程序分析能力.
現有的程序分析技術依賴于一定的啟發式策略,如符號執行技術中的深度(或廣度)優先搜索.在動態分析技術中,為了達到分析精度,這些策略可能帶來較高的計算成本.基于現有的標記數據(即已知分析結果的程序)建立學習模型,機器學習技術可以學習新的可自適應的策略,減少啟發式策略帶來的成本消耗.Li等人[144]為了解決符號執行中的路徑可達性問題,以最小化不滿足性為目標,建立機器學習模型 MLB,以減少經典的約束求解方案在求解非線性約束及函數調用時的不足.Kong等人[175]面向自動機驗證,研究了多個隨機測試與符號執行技術的整合策略,通過調整狀態轉移概率優化動態符號執行.Wang等人[172]提出了基于馬爾可夫過程的動態符號執行方法,以達到應用符號執行獲得精確分析結果和應用隨機測試覆蓋搜索空間的平衡.該方法采用貪心算法獲得優化模型的解,以期找到對應于近似最優性能的策略.Chen等人[176]針對信息物理系統(cyber-physical system)的攻防模型,設計了基于程序變異的方案,獲得具有植入錯誤的模型訓練數據以避免人工建立模型的巨大成本.Xiong等人[177]提出了基于概率程序合成框架 L2S.該框架整合了包括程序合成的搜索空間、路徑和潛在解的概率估計方案,能夠按需地構建程序合成和修復技術,研究者可基于該框架深度定制和設計相關方法.
在靜態分析技術中,分析工具在獲得較高的分析精度的同時,往往帶來過高的誤報率.研究者建立了機器學習模型,以剔除潛在的誤報并減少靜態分析的成本.Heo等人[178]提出了基于異常點檢測技術來濾除靜態分析結果中的誤報.該方法提取代碼循環和函數調用中的特征,基于訓練數據建立學習模型,識別潛在的誤報并提升靜態分析的實用性.Chae等人[59]針對上下文敏感的指針分析,提出了基于分類器的自動特征抽取方案.該方案可有效提升現有的靜態分析技術.Oh等人[179,180]針對靜態分析的精度和計算成本,提出了基于貝葉斯優化的自適應學習方案,并以此建立面向數據流和上下文的部分靜態分析工具.Jeong等人[181]設計了數據驅動的上下文敏感的指針分析方案.該方案通過非線性的上下文選擇,建立了識別上下文敏感函數的學習方法.
3 面向特定軟件的程序分析技術
本節介紹程序分析技術在一些重點領域軟件的應用,包括移動應用軟件、并發軟件、分布式系統、二進制代碼等方面的重要應用.
3.1 移動應用軟件
近10年來,以智能手機為代表的智能終端以驚人的速度得以普及.目前,以Android和蘋果iOS系統為代表的智能手機數量和使用頻度已遠超個人計算機,成為最流行的個人電子設備.通過移動支付、購物和社交等各式各樣的移動應用,智能手機已經深度滲透進了人們的日常活動中.相應地,這些應用的運行狀態和廣大用戶的日常生活和工作有著直接的關系,也在很大程度上影響到了整個互聯網的運轉.為此,研究人員通過對移動應用軟件的程序分析,來檢測其是否具有所期望的以安全性為核心的各種特性.
1) 污點分析技術
由于智能手機的使用特點,移動應用的安全性分析常常可以歸結為應用代碼上跟蹤敏感數據流的動態/靜態污點分析(taint analysis)問題.
· 動態污點分析:最具代表性的 Android應用動態污點分析技術是 TaintDroid[182],其通過修改的 Dalvik Java虛擬機,在應用的Java字節碼的解釋執行過程中進行動態插樁,以實施對敏感數據的跟蹤分析.在TaintDroid的基礎上,研究人員還研發出了其他一些應用安全性分析和防護系統,如 AppFence[183]和DroidBox[184]等.Yan等人開發了一個基于全系統虛擬化的動態污點分析平臺 DroidScope[185],構建于CPU模擬器QEMU[186]之上,發展自面向桌面平臺的污點分析系統TEMU[187].DroidScope可在CPU指令模擬執行層面對運行于模擬器上的整個系統(包括 Android應用和操作系統)中的信息流進行跟蹤,但在較低層面實施污點分析不可避免地帶來一定的語義鴻溝(semantic gap),從而影響到污點分析工作的精度;
· 靜態污點分析:FlowDroid[66]是影響較大的基于Android的靜態污點分析工具.FlowDroid基于過程間控制流圖進行靜態的Jimple代碼模擬執行,根據Jimple指令的語義跟蹤敏感數據在潛在執行路徑上的傳播,從而檢測分析目標應用中可能存在的隱私泄露等危險操作.類似地,在Android應用Java字節碼層面進行靜態污點分析的系統還有 AndroidLeaks[188]和 Apposcopy[189]等.為了更精確地分析Android應用中的敏感信息流,DroidSafe[190]對 Android底層系統進行了建模,將其表示為與應用開發語言相匹配的Java程序,從而跟蹤分析涉及到系統底層的信息流.Jin等人[191]針對采用JavaScript來實現應用邏輯的HTML5混合型移動應用,設計實現了一種JavaScript代碼注入漏洞的靜態檢測方法,所采用的核心技術也是靜態污點分析.針對蘋果手機應用,PiOS[192]通過對iOS應用的Mach-O二進制可執行文件進行靜態數據流分析來檢測應用是否有泄露隱私的行為.
2) 面向移動應用特性的程序分析技術
與桌面應用的分析相比,移動應用的分析還會涉及到一些與移動平臺特性密切相關的分析任務,如組件間通信(inter-component communication)的分析[193]、電量過度消耗等資源泄露(resource leak)的檢測[194]、權限泄露(capability leak)[195]以及權限重代理(permission re-delegation)[196]的檢測防御等.
3) 移動應用分析輔助技術
為了達到較好的分析效果,僅僅關注于應用軟件分析技術本身是不夠的,研究人員還發展出一些分析輔助技術來進一步提升分析效果.為了在動態分析工作中獲得較高的覆蓋率,學術界研究出一些系統化的應用運行驅動技術,如 AndroidRipper[197]、Dynodroid[198]、AppDoctor[199]、EvoDroid[200]和 TrimDroid[201]等.為了較為方便地在真實 Android手機環境中部署分析機制,You等人提出一種稱為引用劫持(reference hijacking)的技術[202],可在不刷機、不 ROOT設備的情況下,將動態污點分析機制植入到底層系統庫中.與桌面平臺相比,移動平臺具有更為復雜的權限管理機制.PScout[203]使用靜態分析從 Android系統源代碼中抽取出應用編程 API所對應的權限規范,從而為 Android應用的安全分析提供了重要的支持.Android應用中存在有大量的隱式調用,導致靜態構建函數調用圖是一個非常具有挑戰性的任務.EdgeMiner[204]通過靜態分析Android的Framework層代碼來生成各個 API所導致的隱式控制流轉移的函數摘要,能夠被集成在已有的靜態分析工具中以提高Android應用分析的精度.對應用進行污點分析需要明確知道引入敏感數據的 Source點和會導致危險操作的Sink點,但現實中缺乏一個完全的Source/Sink點規范.Rasthofer等人[205]利用機器學習技術設計了一個支持向量機分類器以自動識別Android系統API中未知的Source點和Sink點.為了獲得可供分析的代碼,研究者還研發了一些從加殼后的Android應用中抽取Dex代碼的工具,代表性的有DexHunter[206]和PackerGrind[207].這些分析輔助技術對提高移動應用分析工作的效能具有重要的意義.
3.2 并發軟件
自從計算機進入并發處理時代,系統效率得到顯著提升.然而,并發程序(如多線程程序)的使用,導致并發問題(或者并發缺陷)的存在且難以解決.其難點是:并發程序在運行時,多個任務之間的交替運行空間巨大,而搜索該空間是NP難的.2007年圖靈獎、2013年圖靈獎、2016年哥德爾獎等都授予了為解決并發問題而做出突出貢獻的學者.他們提出的方法,例如模型檢驗[208]工具,雖然已成功用于很多并發程序(算法)的驗證,但是仍然無法應用到大規模真實程序中,從而失去了實際意義.2000年以來,多核處理器的快速發展使得大規模多線程程序被廣泛使用,尤其是近幾年來,大數據、云計算、高性能計算等產品的應用中,都使用了大量的基于線程的高并發處理,這進一步加劇了并發缺陷的嚴重性.
由于多線程程序運行時各個線程之間的交替執行(interleaving)[209-212]使其具有不確定性,傳統的單線程程序的測試方法無法用于測試多線程程序以找出并發缺陷.即使某個并發缺陷被檢測到一次,也很難被再一次檢測到或重現這個缺陷[213].因此,多線程程序中并發缺陷的檢測變得比較困難.也因此,近年來并發缺陷的相關研究也非常熱門.
并發缺陷的檢測包括靜態分析[214-216]、動態分析[217-221]以及二者結合的混合分析[222].靜態分析主要是檢測程序代碼(源代碼、中間代碼和二進制代碼等)中是否存在特定模式(即那些可能導致并發缺陷發生)的同步以及資源的訪問.雖然靜態分析能夠通過分析給定程序中所有的代碼來達到很大的覆蓋面,但是由于缺乏程序運行時的信息,尤其是多線程程序特有的交替運行信息,其檢測結果是非常不準確的[223].動態分析則是依賴于程序的具體運行去檢測并發缺陷,其檢測結果相對靜態分析會準確很多.但是一個多線程程序的運行依賴于其中所有線程的交替運行,而這種交替運行的空間是非常大的.因此,單次或有限次多線程程序的運行很難覆蓋該程序的所有其他運行情況[224].從而動態分析只能找到給定程序運行中的缺陷,包括潛在的缺陷.另外,動態分析會引起程序運行時的時間開銷,例如,在 C++程序上動態分析數據競爭時,其時間開銷很容易達到原有程序運行的100多倍[225].混合分析則是結合了靜態分析和動態分析各自的優點,其首先通過靜態分析找出所有潛在的缺陷,然后通過動態分析去驗證這些潛在的缺陷是否為真實的缺陷[222].但是,這種分析方法又受制于測試用例的生成.亦即:即使靜態分析中檢測到的一個潛在的缺陷是真實缺陷,但是怎樣通過動態分析去驗證它.因為一個缺陷的發生不僅取決于程序運行過程中線程之間的交替,還取決于運行該程序時相應的輸入是否可以導致該缺陷的發生[226].另外,如果潛在缺陷的數量非常龐大,則其需要大量地運行給定的程序才能確認每個潛在的缺陷.
1) 全面調度技術
動態分析依賴于程序的具體運行來檢測并發缺陷,因此其無法檢測那些沒有運行或者被隱藏的并發缺陷.引入隨機性則可以增加動態分析的檢測能力.ConTest[227]在程序運行時隨機加入噪音(例如隨機休眠某個線程一小段時間),使得一個程序在每次運行時,各個線程之間的交替產生差異.然而,這種差異只能導致很少的一部分并發缺陷被檢測到,無法讓那些很難檢測到的并發缺陷被檢測到.
PCT[228]和 RPro[229]是最新的兩種有概率保證的調度技術.PCT可使一個程序按照事先產生的隨機調度運行,而這些隨機調度在概率上可以保證動態分析檢測到每一個并發缺陷.但是PCT需要非常多的運行次數,因為其概率的保證是非常小的.因此,在規模稍大的程序上,PCT效果很差.RPro提出了缺陷半徑的概念,并結合實際,使其每次產生的調度只會在特定的程序運行范圍內,從而極大地提高了缺陷的檢測概率.從另一個角度來說,PCT是RPro以程序運行中所有事件數量為半徑時的一個特例.
2) 限定調度
完全探索一個并發程序所有可能的運行空間是 NP難的.近年來,研究人員提出了限定調度技術來緩解這一難題.CHESS[213]只完全遍歷程序中引發不確定運行的事件,包括線程同步以及對volatile變量的訪問等,且其只限定在給定的有限個調度點之內的事件.SKI[230]也采用了類似的思路,在系統內核中通過遍歷未知運行來找到并發缺陷.Maple[231]通過定義一些已知的模式來預測程序運行中的潛在并發錯誤.但這類工作在實際中的效果也不是很好.例如,一項最新的研究表明[232],這些工作(包括部分全面調度技術)還是會漏掉很多并發缺陷.
3) 啟發式調度
并發缺陷主要包括死鎖(deadlock)、數據競爭(data race)和原子性違反(atomicity violation)[233].不同的缺陷通常會有一些特別的檢查方法.
針對數據競爭檢測,FastTrack[234]舍棄了全面內存訪問追蹤,在保證可以在每個內存上檢測到第1個競爭的條件下,改進了檢測效率.DrFinder[235]通過預測并反轉同步的方法,提高數據競爭檢測的覆蓋面.CP[236]通過重新定義數據競爭的方法在一次運行中檢測到更多的數據競爭.但是這種方法只能保證在一個給定程序中只有一個數據競爭時是正確的.RaceMob[222]通過在程序的用戶端來確認給定的潛在數據競爭哪些是真實的,但其仍然需要靜態分析來首先找到潛在的數據競爭缺陷.為了解決動態分析的時間開銷,各種采樣的方法被用于數據競爭的檢測中.LiteRace[237]首先通過降低一個程序中經常被調用的方法的監控來減少時間開銷.Pacer[238]采用定期采樣的方法,使得采樣率和數據競爭的檢測率保持線性關系.Carisma[239]進一步對 Java程序中同一代碼產生的變量進行采樣,其在采樣率很低時,數據競爭的檢測效果較好.采樣分析雖然減少了時間開銷,但也降低了數據競爭的檢測數量,并且無法克服動態分析漏報的缺點.DataCollider[240]通過靜態采樣(代碼級別的采樣)來檢測數據競爭.其不但保證采樣率和數據競爭檢測率的線性關系(與 Pacer類似),而且時間開銷比 Pacer更少.但是DataCollider只能檢測到特定類型的數據競爭,即:兩次訪問中,寫操作數和另外一個讀或者寫操作數不一致的數據競爭.RaceFuzzer[241]在每一個潛在數據競爭發生的位置去調度(例如主動暫停)相關的線程來判斷這個潛在的數據競爭是否會被觸發.只有那些被觸發的數據競爭才會被報告出來.這種方法在一定程度上會檢測到更多的數據競爭,但其檢測能力仍然受制于所使用的調度算法.簡單的調度并不會增強數據競爭的檢測能力,而復雜的調度很難開發.這一點不僅僅針對于數據競爭的檢測,在死鎖等的檢測上也是如此[217,242].Huang等人[243]最近提出了干擾程序運行時的控制流來檢測到更多的數據競爭的方法.這種方法需要針對每一個潛在的數據競爭來解決相應的約束條件,使其在潛在數據競爭很多的時候,無法快速地解決相應的約束條件.CRSampler[244]采用了一種新型的針對硬件采樣的數據競爭定義方法,使其可以在時間開銷很低的情況下有效地檢測已部署程序中的數據競爭.AtexRace[245]則是一個針對跨運行和跨線程的數據競爭采樣技術,在大量測試用例條件下,其可以減少整個測試的時間開銷.
原子性違反檢測的難點,首先是如何確定程序中的內存訪問應該是原子執行的.一旦原子性區域被識別,其違反的檢測就會比較容易.AVIO[246]通過從正確運行的程序中檢測單個變量上兩條訪問指令上的原子性區域.MUVI[247]進一步考慮多變量的內存訪問中的原子性區域.AtomFuzzer[248]直接假設每種方法中的內存訪問是原子性的.AtomTracker[249]首次提出了不需要原子性標記且針對任意原子性區域、任意變量數下的原子性區域檢測方法.但是,AtomTracker需要運行一個程序多次,且不能含有錯誤運行.
死鎖不同于數據競爭和原子性違反,其涉及到線程之間的同步.同樣,死鎖一旦發生,則其很容易被檢測到.但是如何從一個沒有死鎖發生的程序中預測潛在死鎖,同樣是并發程序分析中的一個難題.其中的主要難題是如何高效地檢測死鎖.iGoodLock[242,250]提出了鎖依賴關系來表示程序中每個線程對鎖的獲取行為,并基于這些關系的集合來檢測死鎖.然而,在檢測過程中,由于需要生成大量的中間表示關系,iGoodLock會消耗很多內存,導致其效率低下.MagicLock[250,251]被認為是死鎖檢測方面截止目前最快的檢測方法.其將鎖依賴關系針對線程來分析存放,且提出了鎖依賴的等價關系與非等價關系以及一系列優化措施,使得死鎖的檢測效率大為提高.
4) 消除誤報與漏報
并發缺陷的檢測通常會有誤報[217,241].近年來,主動調度技術(active scheduling)被廣泛提及,并用于誤報消除.RaceFuzzer[241]和 AtomFuzzer[248]通過在有潛在缺陷的點插入調度點,并通過隨機調度來觸發預測缺陷.DeadlockFuzzer[242]采用了類似的想法來觸發死鎖.這些技術都受制于 Thrashing,使其觸發概率不高.Conlock[217,252]和 ASN[253]通過產生約束以及并發缺陷觸發的必要條件來觸發死鎖,在一定條件下,這兩種技術可以保證觸發真實死鎖.
另一方面,動態分析必然產生漏報,其中一個原因就是缺乏并發測試用例.ConTeGe[254]針對 Java庫程序,提出了一種簡單的包含兩個線程且針對單個共享變量的并發測試用例生成技術.CovCon[255]進一步考慮了并發覆蓋度,從而針對那些很少被覆蓋的代碼來生成(選擇)更多的測試用例.
3.3 分布式系統
隨著越來越多的數據與計算從本地向云端遷移,大規模分布式系統逐步得到廣泛使用,比如分布式存儲系統、分布式計算框架、同步服務、集群管理服務等.典型的大規模分布式系統包括 HDFS、Hbase、Hadoop、Spark、ZooKeeper、Mesos、YARN等.與傳統的單機系統相比,大規模分布式系統具有較好的可擴展性和容錯能力,獲得同樣計算能力的成本較低.因此,分布式系統在應對復雜業務場景以及單機無法完成的大規模計算任務時具有較大的優勢,已成為支撐大規模網絡應用不可或缺的一部分.大規模分布式系統已在大型互聯網公司,如阿里巴巴、谷歌、百度等得到廣泛應用.
大規模分布式系統必須管理大量分布式軟件組件、硬件及其配置,使得該類系統異常復雜.因而,大規模分布式系統不可避免地會發生故障,并影響到大量終端用戶,降低了它的可靠性和可用性[256].例如:2013年1月10日,由于一個客戶端與服務器的同步錯誤,Dropbox故障超過15個小時;2014年6月23與24日,Microsoft Lync與Exchange相繼故障,導致其部分用戶9小時無法訪問郵件系統;2017年2月,亞馬遜AWS服務宕機,造成許多基于亞馬遜云服務的互聯網應用無法正常工作.因此,分布式系統中缺陷理解、檢測及驗證技術成為當前研究的一個重點.
1) 分布式系統中缺陷的實證研究
近年來,為了提高復雜分布式系統的可靠性,研究人員對分布式系統中的各種缺陷進行實證研究以加深對這些缺陷的理解.CBS[257]針對6個開源分布式系統(Hadoop MapReduce、HDFS、Hbase、Cassandra、ZooKeeper和 Flume)中 3 655個致命缺陷進行綜合性分析研究,詳細總結了分布式系統中出現的各種缺陷類型,包括可靠性、性能、可用性、安全性、可擴展性等方面的缺陷,并形成一個開放的分布式系統缺陷數據集.但是,CBS沒有對分布式系統中不同類型的缺陷進行深入分析,比如缺陷模式等.因此,后續研究對分布式系統中特定類型的缺陷進行深入分析.TaxDC[258]深入分析了 4個開源分布式系統(Cassandra、Hadoop MapReduce、HBase和ZooKeeper)中的104個并發相關缺陷.Dai等人[259]對11個常用的云服務系統中156個超時(timeout)相關缺陷進行了分析,總結了若干超時相關缺陷模式.CREB[260]針對4個開源分布式系統(Cassandra、Hadoop MapReduce、HBase和ZooKeeper)中的103個與節點失效恢復相關的缺陷進行了深入分析,總結了分布式系統中若干節點失效恢復相關的缺陷模式.Guo等人[261]對分布式系統中的惡性失效恢復行為進行了歸類說明,認為失敗恢復應該遵守無害準則.Yuan等人[262]對發生在Cassandra、Hbase、HDFS、Hadoop MapReduce和Redis上的198個系統失效進行了深入分析,理解分布式系統中的故障最終會演變為用戶可見失敗的模式.Wang等人[263]詳細分析了幾十萬臺服務器上的 290 000個硬件失敗報告,發現了若干硬件失效模式.上述實證研究使得研究人員對分布式系統中不同類型的缺陷得到深入理解,為進一步分析、檢測相關缺陷提供支撐.
2) 基于動態/靜態分析的分布式系統缺陷檢測
由于分布式系統的復雜性,很少有動態/靜態分析工具直接檢測分布式系統特有的缺陷,比如由于消息引起的并發缺陷、節點失效引起的缺陷、超時相關缺陷等.得益于近年來對分布式系統中缺陷的深入分析,開發人員構建了一系列新的開發工具.DCatch[264]將分布式系統中并發缺陷歸結為節點本地的內存訪問沖突問題.DCatch通過記錄一次正確的執行中的關鍵事件(節點交互消息),建立起分布式系統中事件之間的偏序關系,靜態地對這些事件進行分析,識別并發的內存訪問沖突,發現可能的分布式系統并發缺陷.FCatch[265]識別在發生節點失效情況下可能的沖突操作,自動地預測與節點故障事件相關的缺陷.Aspirator[262]基于發現異常處理錯誤的缺陷模式,開發了一個基于規則的靜態檢查器,發現不恰當的異常處理機制導致的系統失效.D3S[266]通過在運行時檢查系統是否違反開發者指定的分布式屬性斷言來發現可能的問題,并提供導致問題的狀態序列來幫助開發者更快地解決問題.Xu等人[267]結合源代碼分析和信息檢索來解析控制日志,構建復合特征,然后使用機器學習的方法來分析這些特征,自動地檢測系統運行中的問題.Dinv[268]利用靜態和動態的程序分析方法來自動地推斷分布式系統中不同節點上變量之間的關系,從而幫助開發者揭露系統在運行時應當滿足的屬性.為了簡化失效重現場景,DEMi[269]通過動態偏序推理[270]和Delta debugging[271]來自動地削減分布式系統的錯誤執行序列,從而定位錯誤.
3) 分布式系統驗證與模型檢驗
大規模分布式系統由數量眾多的計算節點組成,運行不同的復雜協議.建立可驗證的分布式系統是避免錯誤的一個重要手段.Verdi[272]、IronFleet[273]和Chapar[274]通過利用證明框架Coq和TLA來建立可驗證的分布式系統協議.IronFleet結合TLA風格的狀態機精煉和霍爾邏輯驗證來構建實際的且能被證明正確的分布式系統.Verdi通過對各種網絡語義和不同的故障進行規范化,使得開發者在驗證分布式系統實現時可以選擇最合適的故障模型.比如,首先在一個理想化的故障模型上進行驗證,再將得到的正確性保證轉移到一個更加現實的故障模型上.Chapar利用Coq和Ocaml,模塊化地驗證Key-value存儲實現及客戶端程序的因果一致性.但是,通過驗證方法,以較小的性能開銷來構建可驗證的、真實的大規模系統還有一定困難.當前的研究也發現,形式化驗證過的分布式系統實現依然不是完全可靠的[275].
模型檢驗是分析現存分布式系統可靠性的重要手段.MODIST[276]系統化分析分布式系統在所有可能事件下的響應.利用模型檢驗的方法檢測分布式系統往往需要應對巨大的狀態空間.DEMETER[277]利用分布式系統的模塊具有良好定義接口的特性,對接口行為進行抽象,從而大大縮減了狀態空間.SAMC[278]攔截分布式系統中的不確定性事件并交換它們的順序.SAMC采用灰盒測試技術,在傳統黑盒模型檢驗的基礎上加入分布式系統的語義信息,從而縮減了狀態空間,盡可能地避免模型檢驗中的狀態爆炸問題.SDE[279]開發了一種新的算法,能夠顯著地消減測試中的冗余狀態,使得對分布式系統進行可擴展的符號執行成為可能.
4) 基于失效注入的分布式系統分析技術
在分布式系統中,計算節點可能由于硬件、斷電、操作系統錯誤等發生失效.分布式系統需要從節點失效中正確恢復,以保證系統的正確性.但是由于節點失效時機、失效恢復過程難以測試,研究人員開發了一系列工具分析分布式系統的失效恢復行為.SETSUD[280]利用對系統內部狀態的感知來精確地控制擾動的時序,暴露分布式系統中系統層面的缺陷.PreFail[281]是一個可編程的失敗注入工具,允許用戶自定義失敗注入策略.FATE and DESTINI[282]通過避免測試相同的恢復行為來盡可能地測試多種多樣的失敗場景.用戶可以通過Datalog來描述故障測試方法以及分布式系統恢復規范,從而系統化測試分布式系統中故障恢復邏輯.PACE[283]通過系統地生成和探索分布式系統執行中可能產生的文件信息,來檢測與所有副本同時失效相關的分布式系統漏洞.CORDS[284]通過注入文件系統錯誤檢測分布式系統的失效恢復能力.MOLLY[285]采用譜系驅動的故障注入方法來發現故障容忍的分布式數據管理系統中的缺陷.
3.4 二進制代碼
二進制分析是經久不衰的研究話題.盡管越來越多的程序是用解釋型語言(Python、JavaScript等)編寫,但是它們仍然需要二進制程序來解釋執行,或者通過即時編譯(JIT)技術轉換為二進制代碼執行.另一方面,傳統的操作系統等對性能要求較高的應用仍然是以 C/C++等編譯型語言編寫.此外,物聯網中大量設備的計算資源有限,運行的都是C等語言編寫的二進制程序.再者,從安全的角度來講,二進制程序中可能引入源碼中不存在的安全問題,例如Thompson提出的編譯器后門問題[286]、Xcode Ghost污染事件[287]等.
二進制分析的首要任務是反匯編,即識別二進制程序中的代碼和數據,解析函數間調用關系,及函數內的控制流圖.最直接的反匯編方法是線性掃描[288],通過逐條指令解碼的方式恢復代碼.更精確的方式是遞歸遍歷[289],根據指令的語義尋找下一條指令的位置并解碼.但是遞歸遍歷面臨著一個巨大的挑戰:靜態分析無法準確識別間接跳轉指令的跳轉目標.Cifuentes等人[290]基于程序切片技術將間接跳轉表進行規范化表示,根據一些啟發式特征識別間接跳轉語句的目標.Kinder通過在(不完整)控制流圖上進行數據流分析,進而完善控制流圖,再迭代式地進行數據流分析,逐步恢復程序的控制流圖[289,291].Xu等人[292]通過動態分析識別間接跳轉的目標,并采用強制執行的方式驅動程序探索所有路徑,從而構建相對完整的控制流圖.隨著人工智能技術的發展,研究人員也將深度學習技術應用到反匯編中,例如,Shin等人[293]通過RNN識別二進制程序中的函數邊界.然而,反匯編仍然是一個開放的難題,現有的方案仍然存在很多局限[294].
二進制分析面臨的另一個難題是高級語義恢復.恢復二進制程序語義可以用于多種安全應用,例如漏洞挖掘和安全防護.與源碼程序不同,二進制程序中大量信息缺失,例如函數和變量名、函數類型、數據結構定義、虛函數調用與類信息等.Chua等人[295]采用自然語言處理類似的技術識別二進制程序中的函數特征(參數類型及個數).Cifuentes等人[296]通過切片技術提取函數調用指令的操作數的規范化表示,根據啟發式特征識別虛函數調用點.Reps等人[297]通過識別程序中靜態已知的全局地址、棧偏移等識別全局變量和棧變量,通過數據流分析識別間接內存讀操作的返回結果等,實現對二進制程序中的內存訪問操作語義的識別.Jin等人[298]通過過程間數據流分析,跟蹤this指針的流向,識別候選的類成員函數及變量,從而恢復二進制程序中的C++對象.Lin等人[299]提出了一種基于動態分析的數據結構識別方法,對執行過程中的變量賦予時間戳標簽,進而進行前向和后向傳播分析,根據標簽傳播到已知類型的使用位置,反推原始變量的類型和成員布局.Lin將同樣的思想應用到內核二進制代碼中,可以識別內核中的對象[300].
二進制程序分析通常需要對二進制程序進行代碼插裝或改寫.主流有 3類二進制插裝方案:在原始二進制程序中直接靜態修改、將二進制程序提升到中間表示中進行修改或者在代碼執行過程中動態修改.第1類方案,靜態二進制插裝,面臨的最大挑戰是反匯編的準確率,基于不準確的反匯編結果進行代碼插裝可能導致程序執行異常.Smithson等人[301]提出了一種兼容的方案 SecondWrite,通過保留未知的代碼段以及對間接跳轉指令進行保守的指針轉換,確保二進制程序改寫的正確性.UROBOROS[302,303]和 Ramblr[304]方案則通過將二進制程序反匯編,進而在匯編碼上進行插裝,最后再組裝生成新的二進制程序的方式進行二進制改寫.第 2類方案是通過將二進制程序提升到中間表示IR上進行修改,這類方案的優點是插裝在 IR上完成,從而與二進制的指令集無關.Song等人提出的BitBlaze平臺[305]的VINE模塊通過將二進制程序轉換為VEX中間表示完成分析和插裝.Brumley等人提出的BAP平臺[306]基于VINE提出了一個新的中間語言.第3類方案是在程序運行時插裝,通過受控的執行環境,在目標基本塊、函數等執行之前進行插裝,經典的方案包括 DynamoRIO[307]、Dyinst[308]、Valgrind[309]以及Intel PIN[310].
二進制分析是許多安全分析的基礎,具體的安全應用場景包括漏洞挖掘、惡意代碼識別、安全防護等.在漏洞挖掘方面,二進制分析方案通常通過匹配漏洞模式的方式來挖掘漏洞.Machiry等人[311]通過靜態分析掃描驅動代碼,根據漏洞模式識別未知驅動漏洞.Wang等人[312]提出了雙取漏洞的更精確的模型,進而采用靜態分析在內核中發現了多個雙取漏洞.Dewey等人[313]基于靜態分析識別虛函數調用點,進而基于可達性分析識別虛函數表溢出漏洞.在惡意代碼識別方面,大部分方案也是通過匹配惡意行為特征實現檢測.Feng等人[189]通過靜態分析組件間的調用關系,與惡意代碼的特征進行匹配,從而識別 Android惡意代碼.Kruegel等人[314]通過靜態分析內核接口,識別正常調用所訪問的內核內存,與目標模塊所訪問的內核內存進行對比,從而發現內核 rootkit.Bergeron等人[315,316]通過采用摘要技術和符號替換技術,比對目標代碼的特征與已知惡意代碼的抽象表示,從而識別混淆的惡意代碼.在安全防護方面,主流的二進制方案是通過二進制改寫部署新的安全策略.Padraig等人[317]通過二進制改寫工具 SecondWrite對二進制程序植入眾多經典源碼層的防御方案,可以有效地保護歷史遺留的二進制代碼.Wartell等人[318]通過靜態改寫二進制程序,在程序加載時對代碼位置進行隨機化,能夠有效緩解部分攻擊.他們提出了另外一個方案[319],通過對所有 API調用點植入安全檢查,自動引入安全監控器來增強二進制程序安全性.Zhang等人[320]通過反匯編二進制程序,并植入控制流完整性安全策略,可以有效地緩解控制流劫持攻擊.Batyuk等人[321]利用靜態分析評估了Android應用中的惡意行為比例,并通過二進制改寫緩解應用中的惡意行為.Zhang等人[322]通過靜態分析識別虛函數調用點,進而通過二進制改寫部署安全策略,極大地緩解了虛函數劫持攻擊.
4 討論與展望
程序分析是一項重要的基礎性技術,它不僅能夠直接用于發現各類軟件中的缺陷、改進軟件質量,還可以在軟件測試、調試、維護以及缺陷預測等方面發揮作用,包括測試數據生成、軟件維護與程序理解、程序修復等.例如,軟件測試的一個重要問題是:如何自動構造比較合適的測試數據,從而達到一定的測試覆蓋率.Xu和Zhang[323]針對C程序的單元測試,采用符號執行、約束求解與線性規劃等技術,自動構造較小的測試數據集.在軟件調試方面,Wu等人提出了 ChangeLocator[324],在控制流分析和程序切片的基礎上,根據軟件崩潰報告自動識別出引發崩潰的代碼變更(crash-inducing changes),從而幫助開發者較快地理解軟件崩潰的原因并找到解決方案.在自動化程序修復方面,Gao等人[325]基于前述數據流分析技術,通過建立合適的抽象域,自動修復程序中的內存泄漏并保證安全性;Xuan等人[326]基于動態分析提取實時運行值,將程序合成轉換為約束求解問題,并應用 SMT獲得可修復程序的代碼補丁.在缺陷預測方面,Briand等人[327,328]利用程序分析技術提取面向對象程序中的內聚性和耦合性等特征,構建定量模型,預測可能包含缺陷的類.
隨著新型軟件形式的出現,程序分析技術也面臨一些新的問題.下面針對新興的智能合約及機器學習軟件上的程序分析進行討論.
4.1 面向智能合約的程序分析
最近數年,源自比特幣(bitcoin)的區塊鏈(blockchain)技術已成為各行各業關注的焦點.區塊鏈可被認為是一種分布式、去中心化的計算與存儲架構,除了支持數字資產外,還能被用于商品溯源、信用管理乃至游戲等各種各樣的去中心化應用(decentralized application,簡稱DApp).為了方便DApp的開發,一些基于區塊鏈技術的區塊鏈平臺應運而生,其中最為引人注目的是以太坊(Ethereum)[329].以太坊被認為是一種可編程的區塊鏈,用戶可以在其上編寫和部署由智能合約(SmartContract)組成的DApp.目前,以太坊智能合約是最流行的DApp模式.
智能合約由Solidity語言開發,被編譯為字節碼后在以太坊虛擬機EVM上運行.由于智能合約可能承載著數額巨大的數字資產,自然也成為了黑客的攻擊目標.針對智能合約的攻擊已經造成了驚人的財產損失[330,331],研究人員開始探索通過軟件分析技術來檢測、驗證智能合約的安全性.如在文獻[332,333]中,符號執行技術被用于在字節碼層面檢測智能合約中的已知類型的潛在漏洞.此外,相對于傳統軟件,智能合約的體量較小(代碼一般為數十至數百行),使得對其使用形式化技術成為可能,涌現出多個智能合約驗證系統[334-339].這些系統根據用戶給出的待驗證屬性或斷言,采用模型檢驗等技術來驗證目標合約的實現是否具有相關特性.與傳統軟件的分析相比,智能合約的分析在技術角度上并無太大不同,有的工作[334,338]甚至直接將智能合約代碼轉換為已有驗證系統所能支持的形式,借助已有驗證系統快速形成了對智能合約的分析能力.如在文獻[338]中,智能合約的Solidity代碼被轉換為 LLVM Bitcode,從而可以利用已有的分析和驗證工具來驗證智能合約.但是智能合約的分析工作也具有一些特殊性,突出表現為部署后的智能合約升級維護較為困難,難以像傳統軟件那樣隨意打補丁,使得人們特別期望能夠在部署前就發現所有的潛在問題,這對智能合約分析系統的分析效能提出了很高的要求.目前,智能合約分析工作面臨的主要挑戰是如何有效地提供分析所需的安全模式或屬性,這往往會同時涉及特定領域知識和程序驗證知識,僅僅依賴用戶提供并不現實.此外,智能合約相關技術還處在進化中,可能會涌現出新的應用模式和新的安全問題,需要持續不斷地跟蹤歸納.如何高效地提取分析所需的先驗知識,是一個非常有意義的研究問題.
4.2 面向機器學習軟件的程序分析
近年來,機器學習及其他智能技術在行業軟件中得到了廣泛的應用,尤其是深度學習技術與工具在語音識別、圖像檢索、自動駕駛等領域取得了較大突破.然而,由于廣泛存在的概率模型、多層傳播的復雜網絡結構、黑盒形式的用戶接口等特性,深度學習工具的質量難以度量.現有的軟件分析技術難以直接應用.研究者提出了一系列程序分析方案用以發現機器學習系統的潛在風險和程序錯誤,提升機器學習系統的質量[340].Qin等人[341]提出了基于程序合成的機器學習系統的功能評估方法 SynEva,該方法通過學習場景的程序合成,用于評估機器學習系統.Sun等人[342]提出了面向深度學習的動態符號執行方法,該符號執行方法將測試需求表示為量化線性運算(quantified linear arithmetic),以神經元覆蓋為目標測試深度神經網絡的魯棒性.
在形式化驗證方面,Gehr等人[55]提出將卷積神經網絡轉化為CAT函數,再使用抽象解釋技術對CAT函數的行為進行上近似,從而驗證對應神經網絡的局部魯棒性.Wang等人[56]設計了基于符號化區間的形式化驗證方案,用來驗證不適宜使用 SMT的屬性.Ruan等人[343]針對深度神經網絡,提出了基于可證明保障(provable guarantee)的可達性分析方法.Huang等人[344]提供了基于 SMT的深度神經網絡的安全性驗證方法.機器學習軟件往往依賴于復雜的數據處理.針對數據量過大難以調試的問題,學術界也提出了若干方法.Ma等人[345]提出了LAMP,該方法用較低的開銷在基于圖的機器學習算法中記錄追蹤關系,以方便程序員定位缺陷.Gulzar等人[346]設計了一系列的調試算子,用于在基于 Spark的大數據分析程序中進行低成本的交互式調試,而不必反復重啟整個計算過程.然而,由于機器學習技術的復雜特性,相對于傳統軟件的分析,機器學習軟件的靜態分析、動態分析等方面都鮮見成果.針對深度學習工具的程序分析仍在起步階段.
5 結束語
程序分析是剖析復雜軟件系統、提高軟件質量的重要手段,是軟件工程、程序設計語言、操作系統、信息安全等領域日益受到關注的研究方向.經過多年的發展,程序分析已在多個方面取得了長足的進步.研究人員將程序語言理論與編譯、人工智能、數據處理等技術相結合,針對不同的軟件形態發展出眾多程序分析技術,同時開發了高效率的自動化分析工具,其中有些工具幫助人們在開源軟件中找到了很多缺陷、漏洞,有些工具在大公司里得到應用,并發揮了重要作用.由于篇幅所限,本文只是簡述了該方向近期的一部分重要成果.
當前,程序分析技術還面臨一系列挑戰,比如準確性、可擴展性等.另外,新型的軟件形態,如智能合約、深度學習等,也需要全新的程序分析技術.隨著軟件應用范圍的發展以及對軟件可靠性要求的提高,程序分析在軟件開發、維護過程中起的作用將越來越大.
致謝在本文寫作過程中,日本九州大學的趙建軍和國防科技大學的王戟提供了很多建設性意見,中國科學院軟件研究所的蘇靜和劉晴幫助整理了部分資料,在此一并感謝.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
人大建設(2019年12期)2019-05-21 02:55:44
電子制作(2018年18期)2018-11-14 01:48:24
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
山東工業技術(2016年15期)2016-12-01 05:31:22
海峽科技與產業(2016年3期)2016-05-17 04:32:12
