基于YOLO的駕駛視頻目標檢測方法
2019-02-25 07:26:58文浩彬張國輝
汽車科技 2019年1期
文浩彬 張國輝
摘 要:運用YOLO(You Only Look Once)實時目標檢測算法解決了駕駛視頻目標檢測問題。針對目標檢測算法受環境條件影響魯棒性差、小目標識別能力不高的問題,建立了涵蓋多種天氣環境、包含疑難目標的駕駛視頻樣本數據庫,提出了疑難樣本訓練方法,訓練出可在多種天氣環境中良好識別小型汽車、行人、公交車及貨車的YOLO檢測模型。實驗結果表明,該訓練方法可有效提升目標檢測性能;所得檢測模型具有較高的召回率和精確度,可初步應用于實時駕駛視頻的目標檢測。
關鍵詞:駕駛視頻;目標檢測;YOLO;碰撞預警
中圖分類號:TP391 文獻標識碼:A 文章編號:1005-2550(2019)01-0073-04
Abstract: Applying YOLO (You Only Look Once) real-time object detection network to detection tasks in vehicle camera videos. Aiming at the low robustness due to environmental impact, and low performance of small object detection of present algorithms, a dataset containing multiple weather condition samples and Difficult Samples is established. The method of training Difficult Label is proposed. A YOLO model capable of well recognizing small cars, pedestrians, buses, and trucks in complex driving environment is trained, with high Recall rate and Precision, which can effectively improve detection performance and be primarily applied to real-time detection in vehicle camera videos.
Key Words: Vehicle camera video; Object detection; YOLO; Collision Warning System
前言
在各類引起交通事故的因素中,人類因素占90%,駕駛員違法占74% [1]。交通環境復雜性是造成駕駛員疲勞、疏忽的主要原因。通過實時檢測交通環境中的行人和車輛,必要時向駕駛員提供預警,可有效避免交通事故發生。
在目標檢測領域中深度神經網絡應用廣泛。從2014年RCNN[2]提出至今,領域內涌現出SPP-NET、SSD、Fast RCNN、RFCN、Faster RCNN、YOLO(You Only Look Once)系列算法等,檢測精度、速度不斷提高。其中,Joseph Redmon等在2018年3月提出YOLO v3[3],因快速、準確的檢測性能成為關注焦點。
本文借鑒YOLO系列算法的最新研究成果,將YOLO v3用于駕駛視頻的目標檢測。建立了涵蓋多種天氣環境的駕駛視頻樣本數據庫;提出了疑難樣本訓練方法。實驗獲得的檢測系統在文中測試數據集上的平均精確度達78.06%,目標召回率高,可初步應用于汽車前向防碰撞系統中的實時駕駛視頻目標檢測。
1 前向防撞預警系統技術路線
使用單目視覺方法實現汽車前向碰撞預警的研究較為成熟,常見方案由五部分組成:攝像機采集圖像;目標檢測;目標距離估算;形成防碰撞策略;執行預警。目標檢測作為該技術的重要環節,其檢測精度、檢測速度對汽車行駛安全性影響大。運用YOLO檢測算法對行駛環境中的目標進行識別,有助于實現實時的目標檢測。圖1為前向防碰撞預警系統技術路線。
2 YOLO網絡模型的訓練
2.1 YOLO v3檢測系統
YOLO v3檢測系統的預測任務主要為兩部分:分類預測和位置預測。
輸入圖片首先經尺寸調整并被劃為N×N的正方形柵格,包含目標中心的柵格單元負責檢測該目標[4]。輸入圖片通過YOLO神經網絡計算后輸出含有分類信息的特征柵格圖。YOLO v3的核心網絡框架為具有53層卷積層的特征提取網絡Darknet-53[3]。
目標位置預測運用K-means聚類方法獲得錨點框(Anchor Box)尺寸,通過對錨點框尺寸進行數學變換獲得預測框(Bounding Box)尺寸。YOLO v3使用跨尺度預測機制(Predictions Across Scales)——在三種尺度的特征圖上執行預測,融合多尺度采樣特征。
2.2 建立駕駛視頻樣本數據庫
車輛行駛環境的開放性增加了目標檢測的難度,亮度變化、天氣狀況(雷雨天氣等)、交通路況(并道合流、轉彎、上下坡等)等對檢測性能影響大。通過行車記錄儀獲取駕駛視頻樣本圖片,涵蓋上述復雜環境及路況。
檢測目標類別為4類:行人(Pedestrian)、小型汽車(Car)、公交車(Bus)和貨車(Truck)。使用LabelImg工具添加樣本標簽,建立基礎數據庫。詳細參數如表1所示。訓練樣本選取具有良好特征的目標進行標記,測試數據則需對樣本圖片中的所有目標進行標記。將XML標簽轉化為可供YOLO識別的TXT文本標簽,完成基礎樣本數據庫的建立。
2.3 網絡模型訓練
以Darknet53為網絡框架,YOLO v3為檢測模型,訓練駕駛視頻目標檢測系統。
為提高訓練效率,選擇開源的預訓練權重darknet53.conv.74.weights初始化卷積層。此預訓練權重通過Darknet53網絡模型在ImageNet數據集上訓練多個循環后獲得。設置沖量系數為0.9,權值衰減系數為0.0005,最大訓練批次為50000步。學習率使用分步調整策略(由10-4至10-6),避免訓練出現過擬合。
2.4 訓練技巧
批樣本數量(Batch)與樣本分支數量(Subdivisions)之比為單個分支中含有的數據量(Subdivision Size),該數據量大小受到硬件計算能力的限制。適當減小批樣本數量和樣本分支數量可減少硬件計算負擔,同時仍可獲得良好的模型檢測性能。
為提升模型檢測精度,更改輸入圖像分辨率適應大尺寸圖像的目標識別。駕駛視頻中圖像的尺寸普遍較大,將輸入圖像尺寸由默認的416×416像素調整為544×544像素。文獻[5]指出,檢測系統對大輸入圖片尺寸的檢測速度低但精度高。執行跨尺度預測時,本文模型得到密度更高的特征柵格圖。
采用疑難樣本訓練方法提高系統檢測精確度(mAP)。本文定義下的疑難樣本為小尺寸、輪廓不完整以及特征模糊的目標。樣本圖片添加標記時設置疑難標簽(Difficult Label),獲得包含疑難樣本的訓練數據集。根據表2試驗數據,該技巧使mAP提升9%。
3 試驗及結果分析
3.1 試驗環境
本文試驗環境如表3所示,該運行環境下的YOLO駕駛視頻目標檢測系統檢測速度可達20FPS。
3.2 檢測結果分析
網絡模型訓練收斂后,對模型檢測性能進行測試。檢測器在測試數據集上進行測試并統計給定閾值下的預測結果,計算精確度、召回率等指標。表4給出分類概率閾值(Thresh)為0.25時的各類評價指標。
其中,檢測系統平均精確度(mean Average Precision, mAP)是單類目標平均精確度(Average Precision for each class, Ap)的算術平均值。目標預
.測正確與否的判斷依據為IOU值——預測框與真實矩形框(Ground Truth Box)的交集與并集之比,IOU值大于50%屬正確目標。
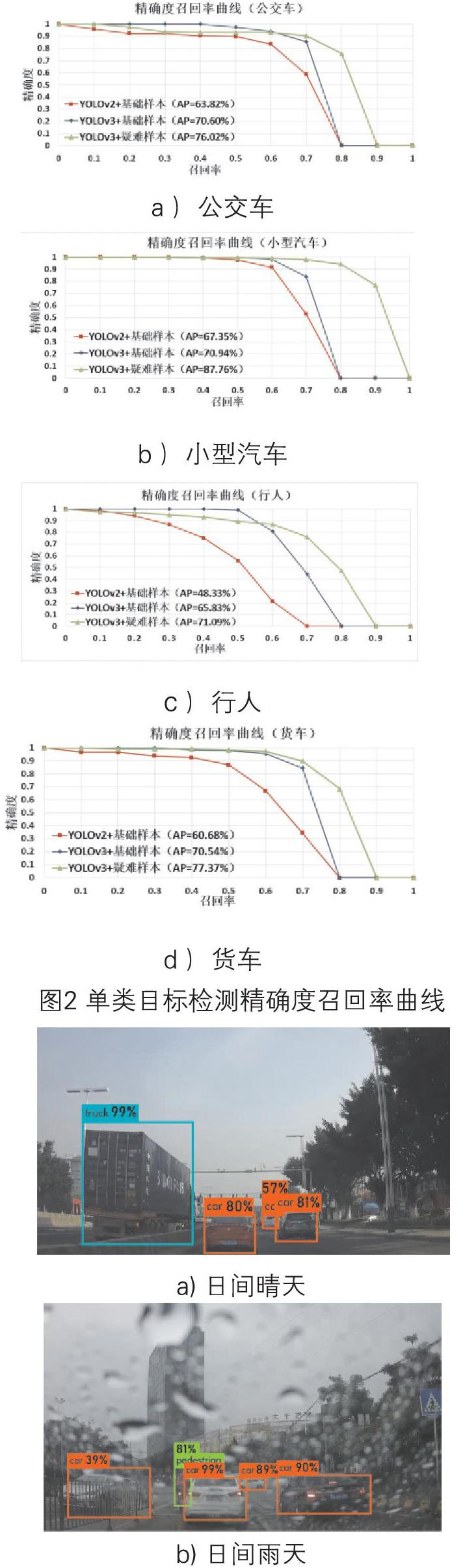
統計結果繪制成精確度召回率曲線,分析檢測系統對各類目標的檢測性能。X軸為召回率(Recall)、Y軸為精確度(Precision),若兩者同時趨于1則表明檢測系統性能越好。
根據圖2分析可知,小型汽車的檢測效果最優,行人最差。使用疑難樣本數據庫訓練的YOLO v3網絡模型中,小型汽車的單類目標平均精確度達87.76%,行人僅71.09%。
對比同在基礎數據庫上訓練得到的YOLO v2與v3網絡模型。(圖2c)說明,YOLO v3網絡的應用給行人類的平均精確度帶來了17.5%的提升,其余類別精度均有提升,充分說明新網絡框架優化了小尺寸目標的識別能力。
此外,疑難樣本訓練方法進一步提升了YOLO v3網絡對各個類別的檢測精度。據圖2b,相比基礎樣本數據庫的訓練結果,小型汽車類AP提升約17%,召回率達90%。
3.3 駕駛視頻檢測結果
選取具有代表性的行駛場景圖片進行測試,直觀對比YOLO駕駛視頻目標檢測系統的性能。檢測結果包含預測矩形框、目標類別和目標分類概率,如圖3所示。預測矩形框上方的分類概率為后期添加。
根據圖3測試結果,各種天氣環境下的目標均得到了合理的分類和定位。從分類預測角度分析,大部分目標的分類概率大于80%,未出現類別誤判;從定位預測角度分析,圖3c右側摩托車騎行人位置預測誤差大,其余目標定位準確。
疑難目標也獲得了較好的預測效果。圖3a中較遠處的小汽車、圖b中受白色車輛遮擋的摩托車騎行人以及圖d分類概率為29%的前排車輛,均屬本文定義下的疑難目標,其分類概率較低,但能成功預測。
總體上,該駕駛視頻檢測系統在測試數據集上的平均精確度達到78.06%,各類目標召回率較高,在日間、夜間和晴天、雨天環境下保持較好的檢測性能。
4 結論
將YOLO v3網絡框架用于實時的駕駛視頻目標檢測,可作為汽車前向防碰撞預警系統技術中目標檢測環節的新解決方案。提出了疑難樣本訓練方法,解決了YOLO系列檢測算法在小尺寸目標及相鄰目標檢測上的不足,在檢測精度上表現出優異的性能。
由于行人目標的特征分布表現為水平方向密集、豎直方向相對稀疏,與YOLO檢測模型對輸入圖片統一劃為正方形柵格的機制不符,導致對行人的檢測效果不夠理想,這是后續工作需要改進的重點。
參考文獻:
[1]畢建彬.道路交通事故的人因分析與駕駛員可靠性研究[D].北京:北京交通大學,2012.
[2]R. Girshick, J. Donahue, and T. Darrel. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Conference on Computer Vision and Pattern Recognition (CVPR), 2014:119-135.
[3]J.Redmon, and A. Farhadi. YOLOv3: An Incremental Improvement[J]. arXiv preprint arXiv:1804.02767,2018.
[4] J.Redmon, S Divvala, and R Girshick. You only look once: unified, real-time object detection [C]. Proc of IEEE Conference on Computer Vision and Pattern Recognition. 2016:779-788.
[5]J.Redmon, and A.Farhadi. YOLO9000: better, faster, stronger[J]. arXiv preprint, arXiv:1612.08242, 2016.
