基于多目標(biāo)演化聚類的大規(guī)模動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)
2019-02-20 08:46:26趙宇海王國(guó)仁
計(jì)算機(jī)研究與發(fā)展 2019年2期
關(guān)鍵詞:檢測(cè)
李 赫 印 瑩 李 源 趙宇海 王國(guó)仁
(東北大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院 沈陽 110819)
真實(shí)世界中,網(wǎng)絡(luò)的節(jié)點(diǎn)和邊通常會(huì)隨時(shí)間動(dòng)態(tài)地變化,這導(dǎo)致了網(wǎng)絡(luò)中的社團(tuán)結(jié)構(gòu)也會(huì)隨著時(shí)間發(fā)生改變.從2005年開始,對(duì)靜態(tài)網(wǎng)絡(luò)缺失的動(dòng)態(tài)特征的研究逐漸成為了研究者們關(guān)注的熱點(diǎn)[1].動(dòng)態(tài)網(wǎng)絡(luò)可以表示成由各個(gè)時(shí)刻靜態(tài)網(wǎng)絡(luò)組成的快照序列,動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)的目的就是準(zhǔn)確地挖掘出每一時(shí)刻快照的社區(qū)結(jié)構(gòu),從而可以分析社區(qū)結(jié)構(gòu)隨著時(shí)間的演變過程,這是無法通過靜態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)洞察的.
動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)有廣泛的應(yīng)用.在基因網(wǎng)絡(luò)分析方面,動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)能揭示特征基因集隨時(shí)間的變化過程;在電商數(shù)據(jù)分析方面,動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)能發(fā)現(xiàn)用戶的偏好變化情況;在社交網(wǎng)絡(luò)數(shù)據(jù)分析方面,動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)能找出興趣團(tuán)體,預(yù)測(cè)團(tuán)體可能參加的活動(dòng).此外,在新聞標(biāo)題內(nèi)容分析、論文作者合作關(guān)系分析、金融股市分析等方面,動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)也有著廣泛的應(yīng)用.隨著社區(qū)檢測(cè)技術(shù)的發(fā)展,動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)將會(huì)在越來越多的實(shí)際網(wǎng)絡(luò)中得到應(yīng)用,并發(fā)揮巨大的作用.
演化聚類框架是動(dòng)態(tài)社區(qū)檢測(cè)的主流方法之一,其基本思想是在第一時(shí)刻網(wǎng)絡(luò)快照社區(qū)檢測(cè)的基礎(chǔ)上,根據(jù)社區(qū)結(jié)構(gòu)的時(shí)間平滑性,用前一時(shí)刻的社區(qū)檢測(cè)結(jié)果指導(dǎo)當(dāng)前時(shí)刻的社區(qū)劃分,以提高動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)的效率.為了避免噪音等因素的影響,保證動(dòng)態(tài)社區(qū)檢測(cè)的準(zhǔn)確性,許多文獻(xiàn)把演化聚類框架引入到動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)中來.但是,演化聚類存在以下2個(gè)問題: 1)在有效性方面,若初始社區(qū)結(jié)構(gòu)檢測(cè)不準(zhǔn)確,會(huì)導(dǎo)致后續(xù)社區(qū)結(jié)構(gòu)檢測(cè)的“結(jié)果漂移”和“誤差累積”問題,即上一個(gè)結(jié)果不準(zhǔn)確將導(dǎo)致下一個(gè)聚類不準(zhǔn)確,并導(dǎo)致這種不準(zhǔn)確性愈演愈烈;2)在效率方面,基于模塊度優(yōu)化的社區(qū)檢測(cè)方法是NP難的[2],許多精確算法無法在合理的時(shí)間內(nèi)解決該問題.
針對(duì)以上問題,本文提出一種基于改進(jìn)演化聚類框架和離散粒子群算法的多目標(biāo)動(dòng)態(tài)社區(qū)檢測(cè)方法,本文的主要貢獻(xiàn)有4個(gè)方面:
1) 提出基于最近未來參考的演化聚類框架,提高初始聚類準(zhǔn)確性,保證動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)的可靠性.
2) 離散粒子群優(yōu)化算法與基于精英策略的非支配排序遺傳算法(NSGA-Ⅱ)結(jié)合,并基于演化聚類框架,利用前一時(shí)刻社區(qū)劃分結(jié)果來快速指導(dǎo)粒子群算法搜索當(dāng)前快照中的社團(tuán)結(jié)構(gòu).
3) 提出基于去冗余策略的隨機(jī)游走初始個(gè)體生成算法DIGRW,對(duì)粒子群的位置進(jìn)行初始化,提高了初始粒子群的個(gè)體多樣性和個(gè)體精度.
4) 提出多個(gè)體交叉算子,增強(qiáng)算法的局部搜索能力,提高算法的收斂速度.
1 相關(guān)工作
由于動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)能揭示靜態(tài)網(wǎng)絡(luò)檢測(cè)無法洞察的社區(qū)結(jié)構(gòu)隨時(shí)間變化的規(guī)律,所以,自動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)這一概念出現(xiàn)以來,一系列針對(duì)該問題的相關(guān)算法被先后提出.如Sarkar等人[3]提出利用數(shù)據(jù)挖掘技術(shù)分析動(dòng)態(tài)網(wǎng)絡(luò)的方法——基于潛在空間模型的動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)方法.Cordeiro等人[4]提出一種基于本地模塊度優(yōu)化的動(dòng)態(tài)社區(qū)自適應(yīng)發(fā)現(xiàn)算法. Li等人[5]提出了一種基于增量識(shí)別的聚類方法來解決動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)問題. Lander等人[6]提出多目標(biāo)圖挖掘算法,用來在復(fù)雜動(dòng)態(tài)網(wǎng)絡(luò)中挖掘和檢測(cè)社區(qū)結(jié)構(gòu).Ma等人[7]提出進(jìn)化非負(fù)矩陣因子分解算法來發(fā)現(xiàn)動(dòng)態(tài)網(wǎng)絡(luò)中社區(qū)的演變規(guī)律.
由于基于模塊度優(yōu)化的社區(qū)檢測(cè)方法是經(jīng)典NP難問題,上述精確算法在處理大規(guī)模動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)時(shí)面臨很大挑戰(zhàn).與精確算法相比,演化算法在處理大數(shù)據(jù)過程中具有較明顯的優(yōu)勢(shì)[8].特別地,由于演化算法具有高度伸縮性、靈活性、全局優(yōu)化等能力,并在特征選擇時(shí)可同時(shí)實(shí)現(xiàn)針對(duì)多目標(biāo)的優(yōu)化,因此演化聚類算法在動(dòng)態(tài)網(wǎng)絡(luò)分析領(lǐng)域中逐漸嶄露頭角.
Chakrabarti等人[9]首次提出演化聚類框架,該框架指出動(dòng)態(tài)網(wǎng)絡(luò)具有時(shí)間平滑性,即相鄰時(shí)刻動(dòng)態(tài)網(wǎng)絡(luò)前后變化差距不大.Kim等人[10]為了提高效率,進(jìn)一步提出基于演化聚類框架的動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)方法,即粒子和密度的演化聚類方法來分析動(dòng)態(tài)網(wǎng)絡(luò)的社區(qū)結(jié)構(gòu).Pizzuti等人[11]提出經(jīng)典的DYN-MOGA算法.首次將多目標(biāo)優(yōu)化方法和演化聚類框架結(jié)合用于動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè),使算法具有隱并行性,既保證了當(dāng)前時(shí)刻社區(qū)劃分質(zhì)量,又保證了當(dāng)前時(shí)刻社區(qū)劃分與前一時(shí)刻社區(qū)劃分的相似度較大.這些算法將演化聚類和演化算法結(jié)合,用于動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè),在處理大規(guī)模網(wǎng)絡(luò)效率上有所提高,但有效性仍存在問題.
針對(duì)現(xiàn)有同類算法存在的以上問題,本文提出一種基于多目標(biāo)演化聚類的動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)算法DYN-MODPSO,既提高了效率,又保證了結(jié)果的有效性.
2 基本概念及問題定義
本節(jié)主要描述算法執(zhí)行過程中涉及的基本概念,并對(duì)要解決的主要問題給出具體定義.
2.1 基本概念
動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)主要涉及2個(gè)基本概念,一個(gè)是對(duì)某個(gè)社區(qū)劃分好壞的評(píng)估,另一個(gè)是對(duì)不同社區(qū)劃分相似性的評(píng)估.以下分別描述這2個(gè)概念.


(1)


(2)

(3)


(4)
2.2 問題定義
動(dòng)態(tài)網(wǎng)絡(luò)可以建模為圖N={N1,N2,…,NT}的形式,其中T表示時(shí)刻,Ni表示時(shí)刻i的網(wǎng)絡(luò)快照.社區(qū)是一系列的節(jié)點(diǎn)集合,這些集合內(nèi)部節(jié)點(diǎn)具有強(qiáng)關(guān)聯(lián)關(guān)系,集合間的節(jié)點(diǎn)具有弱關(guān)聯(lián)關(guān)系.動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)就是要找出不同時(shí)刻網(wǎng)絡(luò)快照中存在的真實(shí)社區(qū)結(jié)構(gòu).為了定量地衡量社區(qū)結(jié)構(gòu)劃分好壞,本文采用社區(qū)分?jǐn)?shù)CS來評(píng)估社區(qū)劃分質(zhì)量,用歸一化互信息函數(shù)NMI來評(píng)估2種社區(qū)劃分的相似性.
3 基于改進(jìn)粒子群的社區(qū)檢測(cè)算法MRDPSO
基于模塊度的動(dòng)態(tài)社區(qū)檢測(cè)是NP難問題,因此本文提出將粒子群優(yōu)化算法和演化聚類框架相結(jié)合的有效解決方法.傳統(tǒng)粒子群算法主要用于處理靜態(tài)網(wǎng)絡(luò)數(shù)據(jù),不能和演化聚類框架相結(jié)合.本文對(duì)文獻(xiàn)[11]提出的離散粒子群算法進(jìn)行了改進(jìn),提出了算法MRDPSO(multi-results discrete particle swarm optimization).MRDPSO與現(xiàn)有的粒子群算法不同,主要從3個(gè)方面進(jìn)行了改進(jìn):1)改進(jìn)了粒子群算法的輸出,可以輸出多個(gè)最優(yōu)解,避免了最優(yōu)解的遺漏問題;2)用基于去冗余的隨機(jī)游走初始群體生成方法初始化粒子群,提高粒子群中個(gè)體多樣性并保證個(gè)體初始精度;3)提出多個(gè)體交叉算子(multi-individuals crossover operator, MICO)及改進(jìn)的干擾算子NBM+(neighbor based mutation),增強(qiáng)算法的局部搜索能力.
3.1 MRDPSO總體描述
MRDPSO偽代碼如算法1所示.MRDPSO框架由3個(gè)主要部分構(gòu)成: 1)初始化階段,利用基于去冗余策略的隨機(jī)游走初始群體生成算法DIGRW初始化粒子群的位置信息,保證了初始種群個(gè)體具有一定精度和多樣性,避免算法陷入早熟(行①~④);2)搜索階段,對(duì)多目標(biāo)粒子群社區(qū)檢測(cè)方法進(jìn)行改進(jìn),使得粒子群的全局最優(yōu)位置都保留下來,使算法能夠適應(yīng)動(dòng)態(tài)社區(qū)檢測(cè)的需求(行⑤~);3)突變階段,提出多個(gè)體交叉算子MICO(行)及改進(jìn)的干擾算子NBM+(行⑨),使得粒子群在向全局最優(yōu)解靠近的同時(shí),能夠在小范圍的精英粒子群體中進(jìn)行局部搜索,提高算法發(fā)現(xiàn)全局最優(yōu)解的效率.3.2~3.4節(jié)將對(duì)這3個(gè)主要步驟分別進(jìn)行描述.
算法1. MRDPSO.
輸入:靜態(tài)網(wǎng)絡(luò)G={V,E};
① 粒子群位置初始化:利用DIGRW得到所有粒子的位置P={x1,x2,…,xpop};
② 粒子群速度初始化:初始化所有粒子速度V={v1,v2,…,vpop},令vi=0,其中i=1,2,…,pop;

⑤ 迭代,t=0;
⑥ fori=1,2,…,popdo



3.2 粒子群初始化
3.2.1 編碼方式
在用演化計(jì)算進(jìn)行社區(qū)檢測(cè)的過程中,每個(gè)個(gè)體作為一種社區(qū)劃分方案,都以編碼的方式存在.目前的編碼方式主要有字符串編碼方式和位鄰接編碼方式[13].
圖1(a)為一個(gè)原始網(wǎng)絡(luò);圖1(b)為原始網(wǎng)絡(luò)的3個(gè)子圖,每個(gè)子圖表示一個(gè)社區(qū).圖2的位鄰接編碼對(duì)應(yīng)圖1(b)所示的劃分,圖2中字符串編碼為位鄰接編碼的解碼.在位鄰接編碼方式中,如果節(jié)點(diǎn)i的基因值是j,則節(jié)點(diǎn)i與節(jié)點(diǎn)j位于相同社區(qū);在字符串編碼方式中,如果節(jié)點(diǎn)i的基因值為k,則節(jié)點(diǎn)i在標(biāo)號(hào)為k的社區(qū)中.
如圖2所示,基于位鄰接的編碼方式先轉(zhuǎn)換成字符串編碼,然后再解碼成社區(qū)劃分C={C1,C2,C3}的集合形式.所以位鄰接編碼方式解碼困難、效率低,故本文采用直觀、高效的字符串編碼方式.
3.2.2 初始化粒子群位置
如果初始粒子群有過多的冗余個(gè)體,就不能保證初始種群個(gè)體有較強(qiáng)的多樣性.如圖3所示.
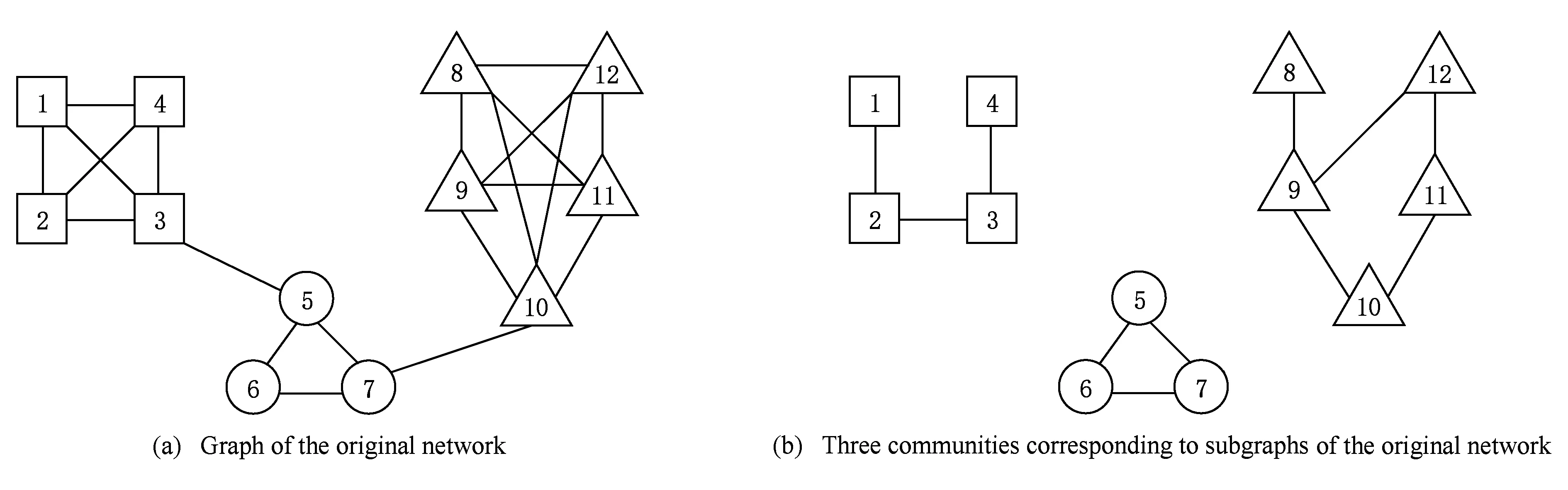
Fig. 1 Community division of the network圖1 網(wǎng)絡(luò)的社區(qū)劃分

Fig. 2 The encoding scheme圖2 編碼方式

Fig. 3 The encoding scheme and the corresponding community division圖3 編碼方式與對(duì)應(yīng)的社區(qū)劃分
圖3(a)中2種不同的字符串編碼均對(duì)應(yīng)如圖3(b)所示的劃分,因此圖3中的2種字符串編碼稱為冗余編碼.過多的冗余個(gè)體很容易導(dǎo)致算法陷入局部最優(yōu),或者算法的收斂速度降低.
針對(duì)這一問題,本文提出基于去冗余策略的隨機(jī)游走初始群體生成算法DIGRW(different individual generation based on random walk).算法DIGRW大致過程有4個(gè)步驟:1)用基于隨機(jī)行走的初始群體生成算法生成一個(gè)粒子位置p;2)用字符串去冗余方法(redundancy removal method, RRM)將個(gè)體p唯一化;3)若個(gè)體不重復(fù),保留到種群中,否則刪除;4)當(dāng)種群個(gè)數(shù)達(dá)到上限時(shí),停止生成個(gè)體.后2個(gè)步驟比較直觀,以下主要對(duì)DIGRW算法的前2步加以描述.
隨機(jī)游走初始化社區(qū)劃分的理論基礎(chǔ)是:根據(jù)社區(qū)的連接屬性,即社區(qū)內(nèi)的連接密度遠(yuǎn)大于社區(qū)外的連接密度,那么如果起始節(jié)點(diǎn)和目的節(jié)點(diǎn)位于同一社區(qū),則會(huì)有更多經(jīng)過k步到達(dá)目的節(jié)點(diǎn)的路徑存在;反之,經(jīng)過k步到達(dá)目的節(jié)點(diǎn)概率很小.基于隨機(jī)游走的初始化社區(qū)劃分基本過程為:1)隨機(jī)選定一個(gè)目的節(jié)點(diǎn)n,計(jì)算每個(gè)節(jié)點(diǎn)經(jīng)過k步到n的概率;2)將所有節(jié)點(diǎn)依照概率值降序排列,在排序后的節(jié)點(diǎn)中找出二分分列點(diǎn),使得模塊度函數(shù)Q增加最大;3)如果不存在使函數(shù)Q增大的分裂點(diǎn),遞歸終止,否則分裂點(diǎn)將當(dāng)前網(wǎng)絡(luò)分裂成2個(gè)子網(wǎng)絡(luò),并分別對(duì)其遞歸執(zhí)行上述操作.
算法2.RRM(p).
輸入:編碼p;
輸出:p所對(duì)應(yīng)的唯一編碼u.
①u[1]=1;
② max=u[1];
③ for inti=0,1,…,|p|-1 do
④ for intj=0,1,…,ido
⑤ if(p[i]≠p[j])
⑥ continue;
⑦ else
⑧u[i]=u[j];
⑨ break;
⑩ end if
字符串去冗余策略RRM是將給定的編碼標(biāo)準(zhǔn)化,使其成為能唯一表示該編碼所對(duì)應(yīng)社區(qū)劃分的形式.算法RRM步驟如算法1所示.RRM的本質(zhì)是對(duì)節(jié)點(diǎn)所屬的社區(qū)標(biāo)號(hào)進(jìn)行調(diào)整.在每個(gè)編碼p中,規(guī)定節(jié)點(diǎn)1所屬社區(qū)的標(biāo)號(hào)為1,即u[1]=1(行①~②).從節(jié)點(diǎn)2開始,依次對(duì)節(jié)點(diǎn)的社區(qū)標(biāo)號(hào)進(jìn)行調(diào)整:如果節(jié)點(diǎn)i與前面的節(jié)點(diǎn)j處于相同社區(qū),那么u[i]=u[j],否則如果節(jié)點(diǎn)i與前面的每個(gè)節(jié)點(diǎn)都不在一個(gè)社區(qū),那么將當(dāng)前最大的社區(qū)標(biāo)號(hào)值加1,作為u[i]的社區(qū)標(biāo)號(hào)(行③~).
3.3 粒子群搜索


(5)

(6)

3.4 干擾算子和交叉算子
粒子群優(yōu)化算法可以通過結(jié)合遺傳操作中的交叉和變異操作來保留最優(yōu)粒子,增強(qiáng)種群多樣性和增加跳出局部最優(yōu)區(qū)域的能力.本研究中分別提出一種新的交叉算子MICO和一種新的干擾算子NBM+來實(shí)現(xiàn)粒子群優(yōu)化過程中的個(gè)體交叉和變異操作.以下分別對(duì)這2個(gè)算子進(jìn)行介紹.
3.4.1 多個(gè)體交叉算子MICO
傳統(tǒng)交叉算子僅是針對(duì)2個(gè)父代個(gè)體,與此不同,本文提出一種新的多個(gè)體交叉算子.受聚類融合算法平衡多個(gè)聚類結(jié)果獲得更準(zhǔn)確結(jié)果的思想啟發(fā)[14-17],本文將遺傳算法中傳統(tǒng)2個(gè)父代個(gè)體交叉算子擴(kuò)展成多個(gè)體交叉算子,提出多個(gè)體交叉算子MICO.
MICO交叉操作過程有3個(gè):1)從所有粒子的歷史最優(yōu)位置pbest中隨機(jī)挑選出M個(gè)位置;2)設(shè)交叉產(chǎn)生的新位置為x,將x[i]賦值為M個(gè)位置中第i個(gè)元素上出現(xiàn)次數(shù)最多的社區(qū)標(biāo)號(hào),如果有多個(gè)出現(xiàn)最多的社區(qū)標(biāo)號(hào),則隨機(jī)選一個(gè)賦值;3)交叉完成,產(chǎn)生新位置x,對(duì)x采用去冗余策略RRM去冗余.
如圖4所示,若M=5,則隨機(jī)選出5個(gè)位置向量x1,x2,x3,x4,x5,對(duì)它們進(jìn)行多個(gè)體交叉操作,產(chǎn)生的新位置向量記為x.現(xiàn)在對(duì)基因位x[3]進(jìn)行賦值,可以看出x1~x5的第3個(gè)基因值中的社區(qū)標(biāo)號(hào)2出現(xiàn)次數(shù)最多,則令x[3]的基因值為2.以此類推,x的所有基因位都按照這個(gè)規(guī)律賦值,最終x=(1,1,2,1,2,3,3,3).

Fig.4 Search operation based on elitist-crossover圖4 精英交叉搜索算子
3.4.2 干擾算子NBM+
為了提高粒子群算法的局部搜索能力,文獻(xiàn)[14]提出干擾算子NBM.然而,NBM會(huì)產(chǎn)生冗余個(gè)體,故本文在此基礎(chǔ)上加入了字符串去冗余策略,提出改進(jìn)的干擾算子NBM+來增強(qiáng)解的多樣性,避免算法陷入局部最優(yōu).
NBM+的過程有3步:1)生成一個(gè)[0,1]之間的隨機(jī)數(shù)m;2)判斷m與突變概率pm之間的關(guān)系,若m 算法MODPSO處理的是單時(shí)間片上靜態(tài)網(wǎng)絡(luò)聚類問題,本節(jié)基于前面提出的單快照社區(qū)檢測(cè)算法MRDPSO,進(jìn)一步提出基于演化聚類框架的動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)算法DYN-MODPSO(multi-objective discrete particle swarm optimization for dynamic network)來處理動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè)問題. DYN-MODPSO偽代碼如算法3所示. 算法3. DYN-MODPSO. 輸入:動(dòng)態(tài)圖N={N1,N2,…,NT},時(shí)刻T,最大迭代次數(shù)genmax; 輸出:Nt的聚類結(jié)果Ct. ① while(t==1‖t==2) ④ end if ⑤ fort=3 toTdo ⑦ while (gen≤genmax) ⑧ fori=1,2,…,popdo 算法3由2個(gè)主要部分構(gòu)成:1)基準(zhǔn)聚類校正,此階段分別用MRDPSO處理動(dòng)態(tài)網(wǎng)絡(luò)中的前2張快照,通過計(jì)算不同快照中社區(qū)劃分的相似性,基于時(shí)間平滑性原理對(duì)初始社區(qū)的檢測(cè)結(jié)果進(jìn)行校正,避免因快照1聚類結(jié)果不準(zhǔn)導(dǎo)致快照2聚類結(jié)果不準(zhǔn)的問題(行①~④);2)多目標(biāo)演化聚類.此階段在基準(zhǔn)聚類校正的基礎(chǔ)上,將多目標(biāo)優(yōu)化算法NSGA-Ⅱ與MRDPSO融合,處理后續(xù)快照的社區(qū)檢測(cè)問題(行⑤~).以下各節(jié)將對(duì)這2個(gè)主要步驟分別進(jìn)行描述. 前面改進(jìn)的粒子群算法MRDPSO在與演化聚類結(jié)合處理動(dòng)態(tài)社區(qū)檢測(cè)的過程中,仍然會(huì)產(chǎn)生“結(jié)果漂移”和“誤差累積”的問題.為解決該問題,本文提出基于最近未來參考策略的基準(zhǔn)聚類校正方法,保證初始聚類結(jié)果的準(zhǔn)確性,從而提高動(dòng)態(tài)社區(qū)檢測(cè)結(jié)果的有效性. 對(duì)poplist采用多目標(biāo)優(yōu)化算法NSGA-Ⅱ中的非支配排序和擁擠距離排序[18-20],根據(jù)動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)的時(shí)間平滑性,選出社區(qū)劃分質(zhì)量好,同時(shí)又與前一張快照劃分最相似的解作為當(dāng)前快照的劃分結(jié)果(行~).依照這樣的規(guī)律,DYN-MODPSO對(duì)每一張動(dòng)態(tài)圖快照都進(jìn)行關(guān)聯(lián)性地處理,直到處理完最后一個(gè)動(dòng)態(tài)圖快照NT,輸出最優(yōu)社區(qū)劃分方案CT,算法結(jié)束(行~).粒子群的非支配排序過程,就是粒子通過兩兩比較CS與NMI后,按照適應(yīng)度值從大到小進(jìn)行的排序過程.粒子群的擁擠距離排序過程,就是在同一個(gè)支配等級(jí)中,即適應(yīng)度值相同的條件下,選擇互不相似的粒子排在前面,將比較與前面粒子比較相似的粒子排在后面,這樣能夠避免得到的解扎堆聚集,從而保證解的多樣性. 本文分別用人工網(wǎng)絡(luò)和真實(shí)世界網(wǎng)絡(luò)對(duì)算法進(jìn)行了測(cè)試,對(duì)比算法是DYN-MOGA,Kim-Han,IBEA.本實(shí)驗(yàn)所用的軟硬件環(huán)境如下:Red Hat 64位操作系統(tǒng),16核CPU,主頻1.9 GHz,16 GB內(nèi)存,2 TB硬盤;Eclipse版本為4.5.0,Java版本為1.8.0. 本文使用Youtube,LiveJournal,DBLP,F(xiàn)lickr這4個(gè)真實(shí)數(shù)據(jù)集和人工數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)[21-22].其中,Youtube是用戶到用戶的鏈接關(guān)系網(wǎng);DBLP是作者合作關(guān)系網(wǎng);LiveJournal是在線社交關(guān)系網(wǎng);Flickr是一個(gè)分享網(wǎng)站的組員關(guān)系網(wǎng). 人工數(shù)據(jù)集使用文獻(xiàn)[21]中的算法生成.數(shù)據(jù)集Dz(z=3,4,5,6),其中z表示不同社區(qū)之間的邊平均數(shù).z越大,社團(tuán)間的連邊越多,社團(tuán)內(nèi)的邊越少,社團(tuán)結(jié)構(gòu)越不明顯.數(shù)據(jù)集統(tǒng)計(jì)信息如表1、表2所示. Table 1 Real Datasets表1 真實(shí)數(shù)據(jù)集 Table 2 Synthetic Datasets表2 合成數(shù)據(jù)集 實(shí)驗(yàn)結(jié)果主要從NMI值、模塊度、運(yùn)行時(shí)間和收斂性4個(gè)方面驗(yàn)證算法的有效性.以下分別給出算法DYN-MODPSO在這4個(gè)指標(biāo)下的度量結(jié)果. 5.3.1 NMI值比較 由于人工網(wǎng)絡(luò)的社區(qū)劃分已經(jīng)確定,所以本文選擇第2節(jié)介紹的歸一化互信息函數(shù)NMI作為指標(biāo),來評(píng)估這3個(gè)算法的社區(qū)劃分結(jié)果和標(biāo)準(zhǔn)社區(qū)劃分的相似性,從而檢測(cè)算法的準(zhǔn)確性.圖5所示的是算法對(duì)人工網(wǎng)絡(luò)10張快照檢測(cè)結(jié)果的NMI值. NMI的值越接近1,算法的檢測(cè)結(jié)果越接近真實(shí)的社區(qū)劃分.如圖5所示,當(dāng)z=3時(shí),DYN-MODPSO的NMI值接近1,而DYN-MOGA和Kim-Han的NMI值分別在0.95和0.9上下浮動(dòng),IBEA的值初始接近0.95,隨著時(shí)間的推移,它的NMI值逐漸下降,在時(shí)間片T=10時(shí)低于0.9.當(dāng)z=4,5時(shí),4個(gè)算法的NMI值都下降,但是DYN-MODPSO的NMI值都穩(wěn)定在0.9,明顯高于DYN-MOGA,Kim-Han和IBEA.當(dāng)z=6時(shí),DYN-MOGA, Fig. 5 NMI value of the synthetic dataset圖5 人工數(shù)據(jù)集的NMI值 Kim-Han,IBEA的NMI值已經(jīng)接近0.6,而DYN-MODPSO仍穩(wěn)定在0.85. 由此可以看出,當(dāng)網(wǎng)絡(luò)社區(qū)結(jié)構(gòu)明顯時(shí),4個(gè)算法都能檢測(cè)到動(dòng)態(tài)網(wǎng)絡(luò)中準(zhǔn)確的社區(qū)結(jié)構(gòu).當(dāng)動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)結(jié)構(gòu)變得模糊,4個(gè)算法的社區(qū)檢測(cè)能力均下降,但是DYN-MODPSO依然可以檢測(cè)到相對(duì)準(zhǔn)確的社區(qū)結(jié)構(gòu).故算法DYN-MODPSO的檢測(cè)能力都優(yōu)于DYN-MOGA,Kim-Han,IBEA,并且穩(wěn)定性較強(qiáng). 5.3.2 模塊度比較 由于真實(shí)數(shù)據(jù)集的社區(qū)劃分未知,所以用衡量社區(qū)劃分質(zhì)量的模塊度函數(shù)來對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行評(píng)估.模塊度值越大,結(jié)果越接近真實(shí)的社區(qū)結(jié)構(gòu).模塊度函數(shù)記作Q,定義為社區(qū)內(nèi)實(shí)際的邊數(shù)與隨機(jī)連接情況下社區(qū)內(nèi)期望的邊數(shù)之差.函數(shù)Q的計(jì)算公式如下: (7) 其中,A是網(wǎng)絡(luò)的鄰接矩陣,m是網(wǎng)絡(luò)的總邊數(shù),ki表示節(jié)點(diǎn)i的度,ci表示節(jié)點(diǎn)i所在的社區(qū)標(biāo)號(hào).如果i=j,則δ(i,j)=1,否則δ(i,j)=0. 本文選擇數(shù)據(jù)集的前5張快照,記錄它們的模塊度,如圖6所示.從圖6中可以看出DYN-MODPSO的模塊度大于DYN-MOGA,Kim-Han,IBEA.如圖6(a)(b),4個(gè)算法的模塊度都很高,DYN-MODPSO穩(wěn)定在0.65上下,隨著數(shù)據(jù)集規(guī)模變大,如圖6(c)(d),4個(gè)算法的模塊度均減少,但是DYN-MODPSO的模塊度值仍然在0.53上下.所以,DYN-MODPSO準(zhǔn)確性很高,并且適合處理大數(shù)據(jù)網(wǎng)絡(luò)圖. 5.3.3 運(yùn)行時(shí)間比較 Fig. 6 The modular comparison of four real datasets圖6 4個(gè)真實(shí)數(shù)據(jù)集的模塊度比較 Fig. 7 Runtime comparison of the two algorithms圖7 算法運(yùn)行時(shí)間對(duì)比 圖7所示的是算法的運(yùn)行時(shí)間對(duì)比圖.算法在人工數(shù)據(jù)集上的平均運(yùn)行時(shí)間如圖7(a)所示,可以看出DYN-MODPSO的運(yùn)行時(shí)間小于DYN-MOGA.當(dāng)z=3,4時(shí),算法DYN-MODPSO和DYN-MOGA的運(yùn)行時(shí)間相差不大.當(dāng)z=5,6時(shí),網(wǎng)絡(luò)中的社團(tuán)結(jié)構(gòu)變得模糊,此時(shí)DYN-MOGA的運(yùn)行時(shí)間比DYN-MOGA將近縮短了一半. 算法在4個(gè)真實(shí)數(shù)據(jù)的平均運(yùn)行時(shí)間如圖7(b)所示,DYN-MOGA的運(yùn)行時(shí)間比DYN-MRDPSO長(zhǎng),而且數(shù)據(jù)集越大,運(yùn)行時(shí)間差越大,如圖7所示DYN-MOGA在LiveJournal數(shù)據(jù)集的運(yùn)行時(shí)間是DYN-MRDPSO的2倍多.所以DYN-MRDPSO是更高效的動(dòng)態(tài)社區(qū)檢測(cè)演化算法,更適合處理大規(guī)模數(shù)據(jù). 5.3.4 收斂性比較 在社區(qū)檢測(cè)方法中,DYN-MRDPSO和DYN-MOGA都是演化算法.收斂性是評(píng)估演化算法的一個(gè)指標(biāo).在不斷地迭代過程中,種群中不斷優(yōu)化最優(yōu)解,當(dāng)達(dá)到一定迭代次數(shù)時(shí),最優(yōu)解趨于穩(wěn)定,不會(huì)隨著迭代次數(shù)的增加而變化,這時(shí)算法收斂. 本文記錄了DYN-MRDPSO和DYN-MOGA收斂時(shí)的最小迭代次數(shù),如圖8所示.DYN-MRDPSO的迭代次數(shù)遠(yuǎn)小于DYN-MOGA,說明DYN-MRDPSO具有更高的執(zhí)行效率.因?yàn)镈YN-MRDPSO利用DIGRW來初始化種群,使種群在一定程度上接近最優(yōu)解,而DYN-MOGA的初始種群是隨機(jī)生成的,所以算法的迭代次數(shù)比DYN-MRDPSO多許多. Fig. 8 Convergence comparison of algorithms圖8 算法收斂性對(duì)比 本文提出一個(gè)參考最近未來的演化聚類框架,并將其引入粒子群社區(qū)檢測(cè)方法中,提出了DYN-MODPSO算法.為了加快粒子群算法的收斂速度,本文對(duì)隨機(jī)行走社區(qū)劃分方法做了改進(jìn),提出了基于去冗余策略的隨機(jī)行走初始個(gè)體生成算法,來初始化粒子群,使得粒子具有一定的精度和多樣性.在粒子群的搜索過程中,本文引入多目標(biāo)優(yōu)化算法NSGA-Ⅱ來同時(shí)優(yōu)化NMI和CS這2個(gè)社區(qū)劃分適應(yīng)度函數(shù),并加入干擾算子和多個(gè)體交叉算子來加強(qiáng)算法的局部搜索能力. 通過實(shí)驗(yàn)可以看出,在社區(qū)檢測(cè)的性能方面,算法DYN-MRDPSO比DYN-MOGA和Kim-Han能檢測(cè)到更準(zhǔn)確的社區(qū)結(jié)構(gòu),是有效的.在社區(qū)檢測(cè)的準(zhǔn)確性方面,算法DYN-MODPSO的社區(qū)劃分準(zhǔn)確性高于DYN-MOGA和Kim-Han,且具有較優(yōu)的穩(wěn)定性.故算法DYN-MODPSO是有應(yīng)用意義的,可以用于動(dòng)態(tài)網(wǎng)絡(luò)社區(qū)檢測(cè).4 算法DYN-MODPSO
4.1 算法總體描述






4.2 基準(zhǔn)聚類校正

4.3 多目標(biāo)演化聚類

5 實(shí)驗(yàn)結(jié)果與分析
5.1 實(shí)驗(yàn)環(huán)境配置
5.2 實(shí)驗(yàn)所用數(shù)據(jù)集


5.3 實(shí)驗(yàn)結(jié)果及分析





6 總結(jié)與展望
猜你喜歡
中國(guó)設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
