智能芯片的評(píng)述和展望
2019-02-20 03:34:24周聖元陳云霽陳天石
計(jì)算機(jī)研究與發(fā)展 2019年1期
韓 棟 周聖元 支 天 陳云霽 陳天石,3
1(中國科學(xué)院計(jì)算技術(shù)研究所智能處理器中心 北京 100190)2(中國科學(xué)院大學(xué) 北京 100049)3(上海寒武紀(jì)信息科技有限公司 上海 201203)
人工智能是研究如何讓計(jì)算機(jī)從原始數(shù)據(jù)獲取知識(shí),實(shí)現(xiàn)類似人類的行為或智能的學(xué)科.人類作為地球上擁有最高智慧的生物,有著區(qū)別于傳統(tǒng)計(jì)算機(jī)的感知、學(xué)習(xí)和決策等能力.近些年,人工智能技術(shù)在許多商業(yè)領(lǐng)域的應(yīng)用取得了巨大的成功.人工智能技術(shù)使得電腦能夠像人類一樣,在復(fù)雜多變的真實(shí)環(huán)境中做出判斷和決策.其中發(fā)展最為迅速的技術(shù)是模仿人類大腦神經(jīng)系統(tǒng)結(jié)構(gòu)的人工神經(jīng)網(wǎng)絡(luò)(ANN).人工神經(jīng)網(wǎng)絡(luò)的基本單元是感知器,它可以接受一系列輸入然后產(chǎn)生輸出.多層的感知器組成一個(gè)層級(jí)性的網(wǎng)絡(luò)結(jié)構(gòu),每層網(wǎng)絡(luò)中的感知器接受上層的輸入,然后生成輸出傳遞給下一層,最終產(chǎn)生輸出.
人工神經(jīng)網(wǎng)絡(luò)的概念最早由McCulloch和Pitts[1]在1943年提出,并且他們提出了第1個(gè)神經(jīng)網(wǎng)絡(luò)模型,即神經(jīng)元模型(M-P)模型.之后,基于神經(jīng)突觸模型,Knott[2]在1951年提出了第1個(gè)神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)策略.1958年,Rosenblatt[3]發(fā)明了用來進(jìn)行模式識(shí)別的感知器模型,并且證明了在監(jiān)督學(xué)習(xí)的策略下感知器模型可以收斂.1974年,Werbos[4]發(fā)明了著名的監(jiān)督學(xué)習(xí)算法——反向傳播算法(BP),這大大推動(dòng)了神經(jīng)網(wǎng)絡(luò)的發(fā)展.
近年來,隨著世界各地科研人員和科技公司的重視和投入,人工智能的研究取得重大進(jìn)展,在語音識(shí)別、圖像分類、自然語言處理、系統(tǒng)辨識(shí)與控制、醫(yī)療診斷等應(yīng)用領(lǐng)域取得了巨大突破[5-17].
傳統(tǒng)的人工智能算法運(yùn)行于CPU或GPU之上,但隨著人工智能算法中人工神經(jīng)網(wǎng)絡(luò)的網(wǎng)絡(luò)結(jié)構(gòu)迅速膨脹,單一的CPU或GPU在人工智能的處理上十分低效,于是很多硬件研究人員也開始轉(zhuǎn)向能夠有效支持人工智能算法的性能更強(qiáng)大的領(lǐng)域?qū)S锰幚砥鞯难芯考岸嗪颂幚砥飨到y(tǒng)的研究.
但是,隨著半導(dǎo)體工藝達(dá)到納米級(jí)的尺度,柵氧化層泄漏損耗在整個(gè)芯片能量消耗中占據(jù)更大的比重,而且溝道摻雜濃度提高會(huì)導(dǎo)致結(jié)泄漏損耗增加[18].所以,能量密度的增加使得保證所有晶體管在全頻率和額定電壓下同時(shí)開關(guān)動(dòng)作,并且保持芯片工作在安全溫度范圍內(nèi)變得十分困難.
此外,Esmaeilzadeh等人[19]的研究表明,在給定溫度和能量的要求下,8 nm的集成電路中需保持?jǐn)嚯姷脑?dark silicon)的比例會(huì)達(dá)到50%~80%,系統(tǒng)僅僅能在最好的情況下獲得7.9倍的加速.在這種情況下,研究人員開始研究專用的協(xié)處理器和通用處理器組成的混合系統(tǒng)來提高系統(tǒng)的性能.
1 人工智能簡(jiǎn)介
1.1 經(jīng)典算法
本節(jié)主要講述SVM算法[20]、k-Means算法[21]以及感知器算法[3]等經(jīng)典人工智能算法.
SVM算法[20]是一種通過線性和非線性變換,對(duì)二分類問題進(jìn)行有監(jiān)督學(xué)習(xí)的算法.其首先通過核函數(shù),將支持向量映射到高維度空間,然后在高維度空間依據(jù)范式進(jìn)行線性分類,最終得到分類超平面.然后其通過已有的核函數(shù)以及該超平面對(duì)后續(xù)測(cè)試集進(jìn)行分類.
k-Means算法[21]是一種通過迭代將數(shù)據(jù)進(jìn)行無監(jiān)督學(xué)習(xí)的聚類算法.其首先任選k個(gè)數(shù)據(jù)作為聚類中心,然后對(duì)每個(gè)數(shù)據(jù)點(diǎn)計(jì)算其與聚類中心的距離,再后重新計(jì)算聚類中心,最后判定用以評(píng)測(cè)數(shù)據(jù)的測(cè)度函數(shù)是否收斂,如果收斂則結(jié)束,否則繼續(xù)調(diào)整聚類中心.
感知器算法是一種針對(duì)二分類問題的監(jiān)督學(xué)習(xí)算法.其通過權(quán)重和輸入進(jìn)行內(nèi)積,得到激活值,然后依據(jù)激活值與數(shù)據(jù)標(biāo)定結(jié)果,對(duì)權(quán)重進(jìn)行更新,從而逐漸收斂得到二分類權(quán)重.
1.2 人工神經(jīng)網(wǎng)絡(luò)基本算法
近幾年,人工智能算法中的人工神經(jīng)網(wǎng)絡(luò)算法所占比重日益加大.傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)使用Sigmoid函數(shù)作為神經(jīng)元的激活函數(shù),使用BP算法作為訓(xùn)練方法.但BP算法由于其殘差會(huì)從靠后一個(gè)層向前一層反饋的時(shí)候,乘以因子得到前一層的殘差,因此,如果因子總是小于1,會(huì)產(chǎn)生“梯度消失”現(xiàn)象.隨著網(wǎng)絡(luò)層數(shù)的加深,“梯度消失”的現(xiàn)象更加嚴(yán)重,優(yōu)化函數(shù)容易陷入局部最優(yōu)解,并且局部最優(yōu)更可能偏離全局最優(yōu),深層網(wǎng)絡(luò)的效果可能還不如淺層網(wǎng)絡(luò).深度神經(jīng)網(wǎng)絡(luò)(DNN)[22]使用ReLU函數(shù)代替了Sigmoid函數(shù),從而有效克服梯度消失的問題.最初,DNN中采用全連接層進(jìn)行連接,但是因?yàn)榫W(wǎng)絡(luò)輸入層的節(jié)點(diǎn)很多,同時(shí)全連接層要求下層神經(jīng)元和上層所有神經(jīng)元形成連接,這樣一來網(wǎng)絡(luò)的參數(shù)數(shù)量會(huì)迅速膨脹.但是,實(shí)際上,在很多應(yīng)用中,譬如圖像領(lǐng)域,只有圖像中局部的像素之間才存在關(guān)聯(lián),所以下層網(wǎng)絡(luò)只需要和上層網(wǎng)絡(luò)中的局部生成連接即可.卷積神經(jīng)網(wǎng)絡(luò)(CNN)就是基于這種思想,通過卷積核將下層和上層進(jìn)行連接,卷積核參數(shù)在上層節(jié)點(diǎn)中共享,從而減少了網(wǎng)絡(luò)的參數(shù).卷積神經(jīng)網(wǎng)絡(luò)主要包括卷積層、匯聚層、歸一化層和全連接層(分類層)這4種網(wǎng)絡(luò)層.
1) 卷積層.卷積層通過幾個(gè)濾波器(核)提取輸入數(shù)據(jù)的特征.假設(shè)卷積層的輸入尺寸為xi×yi×di,每一個(gè)卷積核的尺寸為Kx×Ky,步長為Sx,Sy.則輸出特征圖(a,b)處的值為
其中,f(*)一般為激活函數(shù),如ReLU函數(shù);wi,j,k和β代表相應(yīng)的權(quán)重和偏置.
2) 匯聚層(池化層).匯聚層的主要作用是降低特征圖的尺寸,進(jìn)一步減少網(wǎng)絡(luò)中的參數(shù)數(shù)量,同時(shí)減少過擬合的出現(xiàn).匯聚層常用最大值函數(shù)或平均值函數(shù)作為濾波器的形式,保留局部的最大值或平均值.設(shè)窗的大小為Kx×Ky,最大值的情況表示為
3) 歸一化層.歸一化層通過不同特征圖的相同位置值的對(duì)比來模擬生物神經(jīng)元的橫向抑制機(jī)制.歸一化層有2種類型,局部對(duì)比歸一化(LCN)(即將每個(gè)數(shù)據(jù)與同一特征層相鄰位置的數(shù)據(jù)進(jìn)行歸一化)和局部響應(yīng)歸一化 (LRN)(即每個(gè)數(shù)據(jù)與不同特征層的同一位置的數(shù)據(jù)進(jìn)行歸一化).實(shí)際使用中,LRN由于其跨越特征層做歸一化的特性,因而使用較多.LRN形式為
其中,α,β,k是該層的參數(shù),M參數(shù)是特征圖fi的鄰居個(gè)數(shù).
4) 分類層(全連接層).分類層通常作為神經(jīng)網(wǎng)絡(luò)的末層,輸出節(jié)點(diǎn)與輸入層全連接,可計(jì)算為
其中,f(*)是最大值函數(shù)或其他激活函數(shù);w和β代表相應(yīng)的偏置.
1.3 常見人工智能應(yīng)用算法
1.3.1 AlexNet
AlexNet[23]是一個(gè)8層的卷積神經(jīng)網(wǎng)絡(luò),在ImageNet LSVRC-2010比賽對(duì)120萬圖像的1 000分類問題中,它達(dá)到了top-1 37.5%,top-5 17.0%的錯(cuò)誤率,并且該模型的變種在ILSVRC-2012比賽中獲得了冠軍.
AlexNet的前5層是卷積層(某些卷積層中含有池化層),后3層是全連接層,最后一層是一個(gè)1 000維的softmax層.它有4個(gè)新的特征:
1) 使用ReLU非線性激活函數(shù).采用了非線性的激活函數(shù)ReLU,比傳統(tǒng)使用Sigmoid的等價(jià)網(wǎng)絡(luò)快6倍.
2) 多GPU訓(xùn)練.120萬張圖片訓(xùn)練時(shí)的計(jì)算量太大,因此將它們的網(wǎng)絡(luò)分布在了2個(gè)GPU上.它們?cè)诿總€(gè)GPU上放置一半的神經(jīng)元,同時(shí)只在某些特定的層上進(jìn)行GPU之間的通信.
3) 局部響應(yīng)歸一化.即引入了LRN,從而增加了模型的泛化能力.
4) 重疊池化.傳統(tǒng)的CNN中采用局部池化層,即池化單元互不重疊,亦即步長s等于窗的邊長z.在該網(wǎng)絡(luò)中采用了s=2,z=3的池化層,即重疊池化.
AlexNet針對(duì)過擬合采取了2種方法:1)數(shù)據(jù)增強(qiáng).該網(wǎng)絡(luò)中采用2種數(shù)據(jù)增強(qiáng)的舉措.一是進(jìn)行圖像變換和水平翻轉(zhuǎn),從256×256的圖像中提取5個(gè)(四角及中心)224×224的圖像塊并進(jìn)行水平翻轉(zhuǎn),最終得到10個(gè)圖像,對(duì)這10個(gè)圖像在softmax層的結(jié)果進(jìn)行平均.2)失活(dropout).失活是指以0.5的概率把隱層神經(jīng)元的輸出設(shè)為0,這樣來強(qiáng)迫神經(jīng)元學(xué)習(xí)更魯棒的特征.在測(cè)試時(shí)使用所有神經(jīng)元,但將它們的輸出乘以0.5.該網(wǎng)絡(luò)的前2個(gè)全連接層使用了失活方法.
1.3.2 GoogLeNet
GoogLeNet[24]是一個(gè)22層的深度卷積神經(jīng)網(wǎng)絡(luò),基于Inception架構(gòu)[25],該架構(gòu)能夠在保持計(jì)算量不變的基礎(chǔ)上增加網(wǎng)絡(luò)深度和廣度.GoogLeNet在ILSVRC2014比賽中取得了當(dāng)時(shí)的最好結(jié)果.
提高深度 CNN性能最直接的方式是增加其深度和廣度.然而這種方式使得系統(tǒng)更容易過擬合,同時(shí)也增加了計(jì)算資源的消耗.解決該問題的基本方法是將全連接層替換為稀疏的全連接層或卷積層.然而在非均勻的稀疏結(jié)構(gòu)上進(jìn)行數(shù)值運(yùn)算時(shí),現(xiàn)行的計(jì)算架構(gòu)效率低下.
Inception架構(gòu)基于的主要思想是:使用容易獲得的稠密子結(jié)構(gòu)近似覆蓋卷積神經(jīng)網(wǎng)絡(luò)的最優(yōu)稀疏結(jié)構(gòu).據(jù)此產(chǎn)生了圖1所示的結(jié)構(gòu):使用不同尺度的卷積核進(jìn)行卷積,提取更加豐富的特征,然后進(jìn)行聚合.
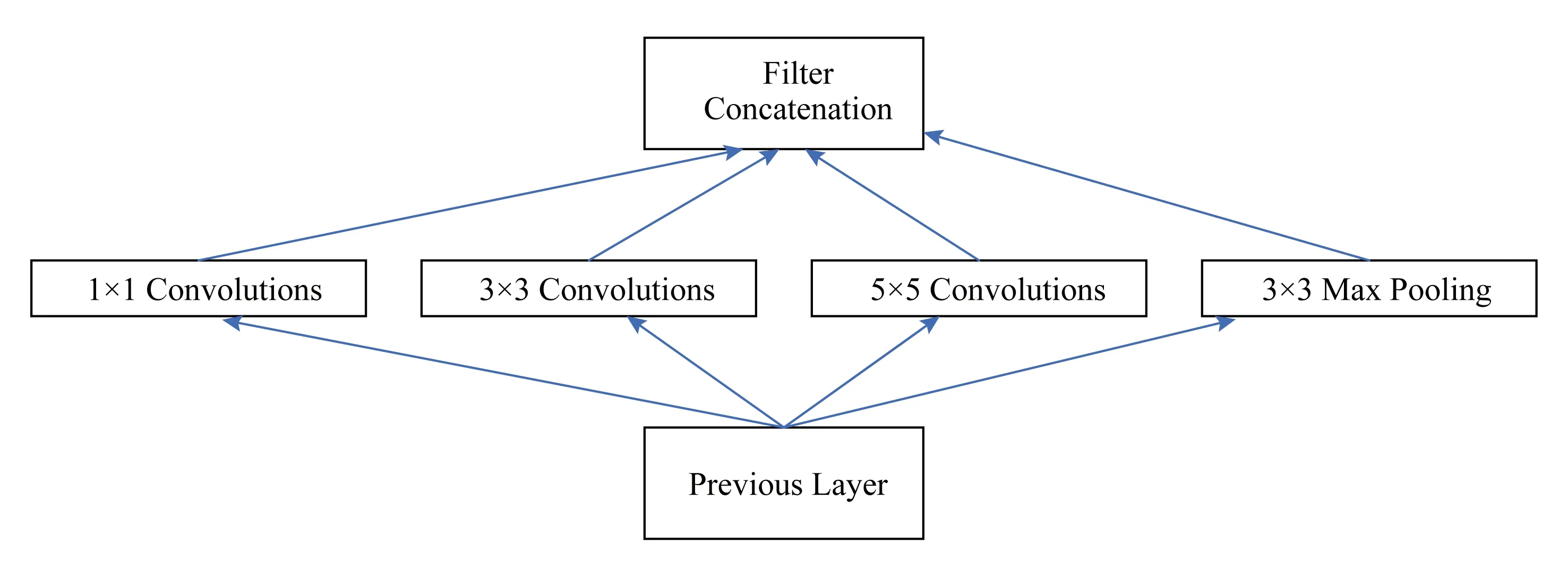
Fig. 1 Initial architecture of Inception network圖1 初始Inception結(jié)構(gòu)
Inception架構(gòu)基于的另外一個(gè)思想是:在計(jì)算要求高的地方減少維度.圖1中所示的的卷積核仍然會(huì)帶來很大計(jì)算量,于是使用了的卷積核降維之后再進(jìn)行卷積.如圖2所示:
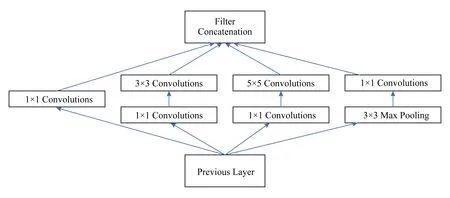
Fig. 2 Final architecture of Inception network圖2 最終Inception結(jié)構(gòu)
1.3.3 ResNet
ResNet[26]基于殘差學(xué)習(xí)框架,擁有更深的網(wǎng)絡(luò)結(jié)構(gòu),但復(fù)雜度仍然較低.該網(wǎng)絡(luò)在ImageNet測(cè)試集上取得了3.57%的錯(cuò)誤率,并且在ILSVRC2015分類任務(wù)中贏得了第1名.
在解決梯度消失的基礎(chǔ)上,一方面較深的模型效果更好,另一方面隨著深度的增加準(zhǔn)確率會(huì)發(fā)生飽和,然后迅速下降.這種退化不是由于過擬合引起的,增加層數(shù)會(huì)帶來更大的誤差.ResNet通過引入深度殘差學(xué)習(xí)框架,解決了退化問題.
ResNet中的思路是:
1) 殘差學(xué)習(xí).如圖3所示,假設(shè)多層網(wǎng)絡(luò)可以近似復(fù)雜函數(shù)H(x),這等價(jià)于讓網(wǎng)絡(luò)近似殘差函數(shù)F(x)=H(x)-x,然后加入前饋得到H(x)=F(x)+x.
2) 快捷恒等映射.多層網(wǎng)絡(luò)可以表示為y=F(x,Wi)+x,如果F,x維度不匹配,可以使用Ws來匹配維度y=F(x,Wi)+Wsx.
3) 網(wǎng)絡(luò)結(jié)構(gòu).先設(shè)計(jì)簡(jiǎn)單網(wǎng)絡(luò),設(shè)計(jì)原則為:相同輸出特征圖尺寸的層具有相同數(shù)量的濾波器;特征圖尺寸減半時(shí)將濾波器數(shù)量加倍.然后在簡(jiǎn)單網(wǎng)絡(luò)基礎(chǔ)上加入快捷連接.
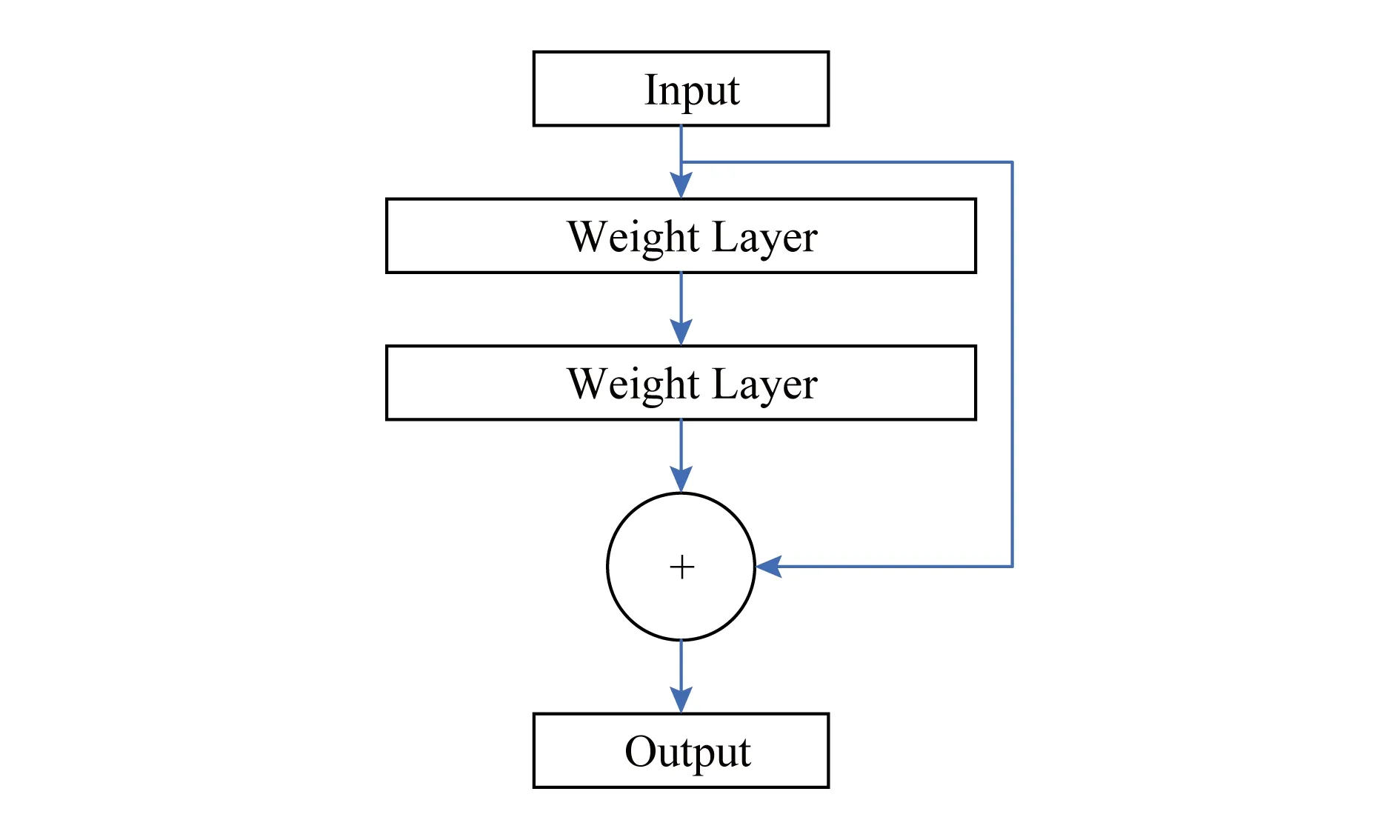
Fig. 3 Residual network圖3 殘差學(xué)習(xí)網(wǎng)路
1.3.4 Faster R-CNN
先進(jìn)的目標(biāo)檢測(cè)算法依靠區(qū)域提議算法(region proposal algorithm)和基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)(R-CNN).其中Fast R-CNN利用很深的網(wǎng)絡(luò)實(shí)現(xiàn)了接近實(shí)時(shí)的速率,而提議算法(proposals)是計(jì)算的主要瓶頸.R-CNN使用GPU進(jìn)行運(yùn)算,將區(qū)域提議算法在GPU上實(shí)現(xiàn)是一個(gè)加速的方法,但這樣就不能進(jìn)行共享計(jì)算.為此,F(xiàn)aster R-CNN[27]引入了區(qū)域提議網(wǎng)絡(luò)(RPN),代替了以前使用的選擇性搜索(selective search)或滑動(dòng)窗口算法進(jìn)行區(qū)域提議.RPN與檢測(cè)網(wǎng)絡(luò)共用全圖像的卷積特征,實(shí)現(xiàn)了幾乎零成本的區(qū)域提議過程.
RPN的思路是:基于共享卷積層所得的特征圖對(duì)可能的候選框進(jìn)行判別.RPN引入錨點(diǎn)(anchor)機(jī)制,對(duì)特征圖進(jìn)行卷積相當(dāng)于使用滑窗在特征圖上進(jìn)行平移,在特征圖的每個(gè)位置可以預(yù)測(cè)多個(gè)提議區(qū)域(假設(shè)有k個(gè)),每個(gè)位置可以在滑窗的基礎(chǔ)上加入尺度和長寬比,例如在文獻(xiàn)[27]中定義3種尺度和3種長寬比,則k=9,這樣的每個(gè)候選窗口稱為一個(gè)錨點(diǎn),對(duì)于W×H的特征圖有W×H×k個(gè)錨點(diǎn).之后的網(wǎng)絡(luò)產(chǎn)生2個(gè)分支,一個(gè)分支用于計(jì)算目標(biāo)邊框的坐標(biāo)和寬高(邊框回歸層reg),一個(gè)分支用于判斷邊框確定的區(qū)域是不是目標(biāo)(分類層cls).
為了訓(xùn)練RPN,給每個(gè)錨點(diǎn)按照4個(gè)規(guī)則標(biāo)定類別標(biāo)簽(是或不是目標(biāo)):1)如果候選框與真實(shí)框交并比(IoU)最大,標(biāo)記為正樣本;2)如果候選框與真實(shí)框交并比IoU>0.7,標(biāo)記為正樣本;3)IoU<0.3標(biāo)記為負(fù)樣本;4)其余情況對(duì)訓(xùn)練目標(biāo)沒有幫助.然后根據(jù)Fast R-CNN的多任務(wù)損失方法最小化目標(biāo)函數(shù),損失函數(shù)為
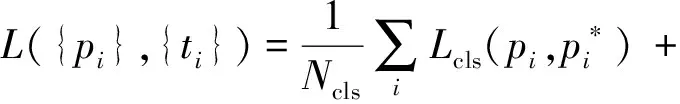
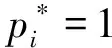
為了能夠讓RPN和Fast R-CNN共享卷積層,有3種方法:1)交替訓(xùn)練.先訓(xùn)練RPN,然后用提議訓(xùn)練Fast R-CNN,F(xiàn)ast R-CNN微調(diào)的網(wǎng)絡(luò)用于初始化RPN.2)近似聯(lián)合訓(xùn)練.每次BP迭代時(shí),前向過程生成區(qū)域提議,反向傳播過程中,對(duì)共享層組合RPN損失信號(hào)和Fast R-CNN損失信號(hào),其中忽略了提議邊界框的導(dǎo)數(shù),故為近似聯(lián)合訓(xùn)練.3)非近似聯(lián)合訓(xùn)練.加入了使邊界框坐標(biāo)可微分的ROI(region of interesting)池化層.
1.3.5 GAN
生成對(duì)抗網(wǎng)絡(luò)(GAN)[28]同時(shí)訓(xùn)練一個(gè)獲取數(shù)據(jù)分布的生成網(wǎng)絡(luò)G和一個(gè)用來判斷樣本是否屬于訓(xùn)練集的識(shí)別網(wǎng)絡(luò)D,這是一個(gè)對(duì)抗的過程.訓(xùn)練的目標(biāo)是,使G最大化讓D出錯(cuò)的可能.這是一個(gè)極小化極大值(minimax)問題,訓(xùn)練的結(jié)果是G生成近似訓(xùn)練集的數(shù)據(jù)分布,而D判斷樣本屬于任何一方的概率都是1/2.在G和D都是多層感知器(MLP)的情況下可以使用BP算法進(jìn)行訓(xùn)練.
2 人工智能處理器
2.1 FPGA
FPGA的可編程性和可重構(gòu)性等特點(diǎn)允許在短時(shí)間內(nèi)對(duì)定制的設(shè)計(jì)進(jìn)行評(píng)估,以此縮短開發(fā)周期,節(jié)省設(shè)計(jì)的開發(fā)費(fèi)用.因此,有很多研究人員基于FPGA平臺(tái)進(jìn)行人工智能處理器的研究和實(shí)現(xiàn).
Farabet等人[29]實(shí)現(xiàn)了一個(gè)類RISC(精簡(jiǎn)指令集計(jì)算機(jī))的可編程卷積網(wǎng)絡(luò)處理器.該處理器通過多個(gè)DSP并行地計(jì)算使用相同的輸入的不同輸出的局部和,然后平移輸入(窗口)來完成相應(yīng)輸出的卷積.Farabet等人[30]后來在Xilinx Virtex 6 FPGA平臺(tái)上實(shí)現(xiàn)了一個(gè)可擴(kuò)展數(shù)據(jù)流硬件結(jié)構(gòu).該系統(tǒng)包括多個(gè)計(jì)算單元(tiles),每個(gè)計(jì)算單元集成了多個(gè)一維卷積器(MAC)來構(gòu)成二維卷積器.
由于二維卷積廣泛應(yīng)用于圖像處理等場(chǎng)景中,Cardells-Tormo等人[31]提出了用于二維卷積的基于FPGA的結(jié)構(gòu).這種結(jié)構(gòu)需要相對(duì)更少的片上內(nèi)存開銷,因此可以用低成本的FPGA實(shí)現(xiàn).此外,他們還提出了單位面積最大吞吐量準(zhǔn)則,用來說明這種結(jié)構(gòu)的高效性.
之后,隨著任務(wù)復(fù)雜度日益增加,因此,為了能處理越來越復(fù)雜的多層感知器,Ordoez-Cardenas等人[32]使用低成本的Xilinx Spartan-3E FPGA實(shí)現(xiàn)了多層感知器神經(jīng)網(wǎng)絡(luò)(MLP)和相應(yīng)的學(xué)習(xí)算法.他們?cè)O(shè)計(jì)了一個(gè)模塊化的方案,使系統(tǒng)能夠靈活地調(diào)整到特定的應(yīng)用中.同時(shí),流水線結(jié)構(gòu)也提高了這個(gè)系統(tǒng)的性能.
在處理神經(jīng)網(wǎng)絡(luò)系統(tǒng)的過程中,由于計(jì)算量增大,因此,功耗問題日益嚴(yán)峻,Maashri等人[33]發(fā)明了一個(gè)用于通用識(shí)別的神經(jīng)網(wǎng)絡(luò)系統(tǒng).該系統(tǒng)基于一個(gè)用于視覺處理的仿生神經(jīng)網(wǎng)絡(luò)模型HMAX,相比于CPU和GPU,它能夠分別達(dá)到7.6倍和4.3倍的加速,節(jié)省12.8倍和7.7倍的能量消耗.
Gokhale等人[34]設(shè)計(jì)的nn-X則是一個(gè)可擴(kuò)展、低功耗、用于加速深度神經(jīng)網(wǎng)絡(luò)的協(xié)處理器,它能夠達(dá)到理論227Gops/s和實(shí)際200Gops/s的性能,同時(shí)整個(gè)系統(tǒng)的功耗只有8W.在Xilinx ZC706平臺(tái)上實(shí)現(xiàn)的內(nèi)核使用2個(gè)ARM Cortex-A9 CPU作為主處理器,主處理器用來解析神經(jīng)網(wǎng)絡(luò)并將其翻譯為相應(yīng)的指令,然后將數(shù)據(jù)傳遞給協(xié)處理器nn-X.
隨著研究的推進(jìn),脈動(dòng)型結(jié)構(gòu)突顯出其在執(zhí)行卷積運(yùn)算中的優(yōu)勢(shì).SCoNN[35]是一個(gè)用于CNN推理階段的脈動(dòng)型(systolic)硬件實(shí)現(xiàn).它通過多個(gè)2D數(shù)組處理單元和一個(gè)滑窗實(shí)現(xiàn)并行的卷積處理.為了節(jié)省更多的能量和帶寬,SCoNN[36-37]直接把中間結(jié)果儲(chǔ)存到RAM中來作為下層的輸入數(shù)據(jù).Sankaradas等人提出了由systolic并行卷積基元和一個(gè)數(shù)據(jù)傳輸專用控制器組成的協(xié)處理器,它擁有用于協(xié)處理器的片下高帶寬內(nèi)存,同時(shí)使用較低的數(shù)據(jù)精度,在每次內(nèi)存操作時(shí)使用打包過的數(shù)據(jù)字.該協(xié)處理器在FPGA中實(shí)現(xiàn),需要和主機(jī)一起工作.但是,脈動(dòng)陣列機(jī)具有很多優(yōu)缺點(diǎn).其優(yōu)點(diǎn)有:可以大量復(fù)用輸出數(shù)據(jù);更簡(jiǎn)單的處理單元設(shè)計(jì);為并發(fā)性調(diào)整的流水線;對(duì)計(jì)算密集型問題有相對(duì)較高的性能;簡(jiǎn)單數(shù)據(jù)流和常規(guī)控制;具有可擴(kuò)展性和模塊化特性.缺點(diǎn)有:對(duì)不同規(guī)模人工智能算法的靈活性不足;存在內(nèi)存帶寬約束等[38-39].
隨著人工智能算法的數(shù)據(jù)量越來越大,通常需要使用額外的儲(chǔ)存空間來儲(chǔ)存它們.同時(shí),隨著人工智能算法越來越復(fù)雜,帶寬需求越來越大.因此,研究者們開始尋找新的結(jié)構(gòu)來充分地重利用(reuse)人工智能算法中的數(shù)據(jù).
Qiu等人[40]提出了一個(gè)基于FPGA的人工智能加速器,它使用了全連接層的權(quán)重矩陣的奇異值分解來減少內(nèi)存訪問,同時(shí)采用動(dòng)態(tài)精度數(shù)據(jù)量化方法來減少能量和邏輯消耗.他們發(fā)現(xiàn)卷積層的核心是計(jì)算而全連接層的核心是內(nèi)存,基于此,他們使用不同的方案對(duì)待2種數(shù)據(jù).他們利用Xilinx Zynq ZC706實(shí)現(xiàn)的設(shè)計(jì)在150 MHz下的CNN的運(yùn)算中達(dá)到了137.0 GOP/s的性能.
Zhang等人[41]實(shí)現(xiàn)了基于VC707 FPGA的61.62 GFLOPS人工智能加速器.他們使用了循環(huán)分塊和轉(zhuǎn)化技術(shù)來定量分析卷積層的計(jì)算和帶寬需求,然后借助roofline模型開發(fā)了一個(gè)統(tǒng)一的結(jié)構(gòu).
Suda等人[42]則更深入地進(jìn)行了Zhang等人的研究.他們不僅關(guān)注卷積層的加速,還提出了一種系統(tǒng)的設(shè)計(jì)開發(fā)方法,來最大化基于OpenCL的FPGA加速器的性能.
為了減少額外的內(nèi)存和帶寬開銷,Peemen等人[43]提出新型的人工智能加速器.他們?cè)O(shè)計(jì)了一種靈活的內(nèi)存管理方式,用來支持?jǐn)?shù)據(jù)訪問和優(yōu)化人工智能算法中的數(shù)據(jù)位置.這種加速器能夠最小化片上內(nèi)存需求,同時(shí)能夠最大化數(shù)據(jù)的利用率,因此這種方法避免了不必要的封裝(footprint)和能量消耗.
此外,除去將人工神經(jīng)網(wǎng)絡(luò)部署于FPGA,Rice等人[44]基于George和Hawkins[45]研究的理論結(jié)構(gòu),實(shí)現(xiàn)了基于FPGA的分層貝葉斯網(wǎng)絡(luò)模型.結(jié)果表明相比于全部在Cray XD1運(yùn)行的軟件,他們的硬件提升了75倍的平均吞吐量.Kim等人[46]提出了一種生成高效置信網(wǎng)絡(luò)(deep belief nets)原型,該模型比在高檔CPU上最優(yōu)的軟件實(shí)現(xiàn)快了25~30倍.
2.2 ASIC
專用集成電路(ASIC)是一類專用的電路,能夠給設(shè)計(jì)者實(shí)現(xiàn)應(yīng)用最大程度的自由.為了滿足不同消費(fèi)者的需求,ASIC常常有更小的體積、更低的功耗、更高的性能、更強(qiáng)的安全性和量產(chǎn)之后更低的成本.
卷積運(yùn)算在人工智能算法中占據(jù)很大的運(yùn)算量,它本質(zhì)上適合做并行運(yùn)算.早期關(guān)于專用人工智能芯片的研究主要關(guān)注如何盡可能快速地實(shí)現(xiàn)卷積運(yùn)算,以滿足實(shí)時(shí)處理的需求.
Lee和 Aggarwal[47]提出了一種并行的二維卷積結(jié)構(gòu),這種處理器擁有和圖片像素?cái)?shù)目相同的處理單元,這些處理單元之間網(wǎng)狀相連,它可以使用任意大小的2維或3維的卷積核.Kamp等人[48]提出了一種全集成的2維濾波器(卷積核)宏單元(macrocell),它提供了7×7的可編程的卷積核,但只適用于垂直對(duì)稱的參數(shù)掩模.
Kim等人[49]提出了一種201.4 GOPS的實(shí)時(shí)多目標(biāo)識(shí)別處理器.芯片模仿人類視覺系統(tǒng),在含有3級(jí)流水線的神經(jīng)感知器中使用了仿生神經(jīng)網(wǎng)絡(luò)和模糊電路.
由于人工智能算法中的Deep CNN在許多計(jì)算機(jī)視覺任務(wù)中能夠達(dá)到最高的準(zhǔn)確率,在經(jīng)濟(jì)的推動(dòng)下出現(xiàn)了很多Deep CNN加速器.Sim等人[50]提出了一種Deep CNN加速器,它擁有1.42 TOPS/W的能量效率.為了減少能量消耗,他們應(yīng)用了一個(gè)雙范圍的乘法累加器(DRMAC)來進(jìn)行低能耗的卷積運(yùn)算.他們利用了分塊排列的方式(tiled manner),使用和片上存儲(chǔ)相同大小的數(shù)據(jù)塊和壓縮的卷積核進(jìn)行卷積運(yùn)算,來減少片下內(nèi)存的開銷和帶寬需求.
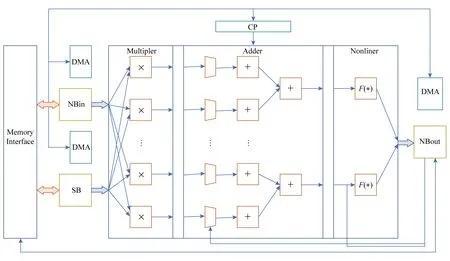
Fig. 4 Architecture of DianNao圖4 DianNao結(jié)構(gòu)方框圖
此外,還有利用人工智能算法內(nèi)在錯(cuò)誤彈性(intrinsic error resilience)的硬件加速器研究.Hashmi等人[51]提出了一種仿生的計(jì)算模型,并且揭示了相對(duì)皮質(zhì)網(wǎng)絡(luò)(relative cortical networks)的內(nèi)在容錯(cuò)性.這個(gè)模型的關(guān)鍵是使用固定型方案(stuck-at)來保護(hù)函數(shù)計(jì)算結(jié)果,當(dāng)硬件出現(xiàn)錯(cuò)誤時(shí)不做任何處理.人工智能算法本質(zhì)上能夠抵抗短暫或者永久的錯(cuò)誤,基于此,Temam[52]提出并且實(shí)現(xiàn)了一個(gè)能夠忍受多重錯(cuò)誤的人工智能芯片.它可以使用多種的基于ANN的算法,實(shí)現(xiàn)一些高性能任務(wù)的運(yùn)算.它和其他定制芯片一樣,相比通用芯片能夠提高2個(gè)數(shù)量級(jí)的能量效率.
3 DianNao系列加速器
3.1 DianNao
DianNao[53]作為DianNao系列中最早的加速器,其計(jì)算峰值達(dá)到452 GOP/s,在臺(tái)積電65 nm的工藝下,面積為3.02 mm,功耗為485 mW.DianNao主要關(guān)注內(nèi)存使用的加速,其利用陳天石等研究者提出的啟發(fā)式模型方法,達(dá)到了計(jì)算量和內(nèi)存體系之間完美的平衡,從而獲得了相比CPU具有3個(gè)量級(jí)的能量效率提升.同時(shí),盡管GPU在運(yùn)算速度上超過了DianNao,但它需要的能量和面積是DianNao的100倍.
DianNao基本結(jié)構(gòu)為一個(gè)控制邏輯(CP)和其控制一個(gè)輸入緩沖區(qū)(NBin),以及另一個(gè)緩沖區(qū)(SB)和其將輸入神經(jīng)元和權(quán)重傳遞給的神經(jīng)功能單元(NFU),然后還包括輸出緩沖區(qū)(NBout),其從NFU接收輸出神經(jīng)元,如圖4所示.其中使用了一個(gè)內(nèi)存接口來為3個(gè)緩沖區(qū)中的數(shù)據(jù)流進(jìn)行路由.其NFU利用交錯(cuò)的3級(jí)流水線結(jié)構(gòu),將不同類型的層在DianNao中被分解為2個(gè)階段或者3個(gè)階段,并且在CP的控制下進(jìn)行流水線運(yùn)算,同時(shí)對(duì)多個(gè)輸出神經(jīng)元進(jìn)行計(jì)算.
為了在降低計(jì)算的能量消耗的同時(shí),優(yōu)化數(shù)據(jù)傳輸策略,減少數(shù)據(jù)傳輸?shù)哪芰浚珼ianNao將片上存儲(chǔ)被分為3部分:輸入緩沖區(qū)(NBin)、輸出緩沖區(qū)(NBout)和突觸(權(quán)值)緩沖區(qū)(SB).其收益如下:1)可以調(diào)整SRAM為合適的讀寫帶寬,而不必是同等的帶寬.由于權(quán)重的數(shù)目大約比輸入神經(jīng)元和輸出神經(jīng)元的數(shù)目高一個(gè)量級(jí),這種專用的結(jié)構(gòu)可以為讀請(qǐng)求提供更好的能量和時(shí)間性能.2)分離儲(chǔ)存和神經(jīng)網(wǎng)絡(luò)位置先驗(yàn)信息,使得DianNao能夠避免數(shù)據(jù)沖突,這種發(fā)生在緩沖區(qū)的沖突往往需要消耗時(shí)間和能量來彌補(bǔ).3)DianNao能夠讓NBin緩沖區(qū)工作在循環(huán)緩存狀態(tài),來重用輸入神經(jīng)元數(shù)據(jù).因此,DianNao相比CPU或GPU將數(shù)據(jù)傳輸帶寬減少到1/30~1/10.
3.2 DaDianNao
DaDianNao[54]是在DianNao的基礎(chǔ)之上構(gòu)建的多核處理器,其處理器核心的規(guī)模擴(kuò)大到16個(gè),同時(shí)增大了片上內(nèi)存.DaDianNao基于28 nm工藝,運(yùn)行頻率為606 MHz,同時(shí)其面積只有67.7 mm2,功率只有大約16 W.DaDianNao不僅支持推理算法,同時(shí)支持訓(xùn)練算法,以及權(quán)值預(yù)訓(xùn)練環(huán)節(jié)(RBM).
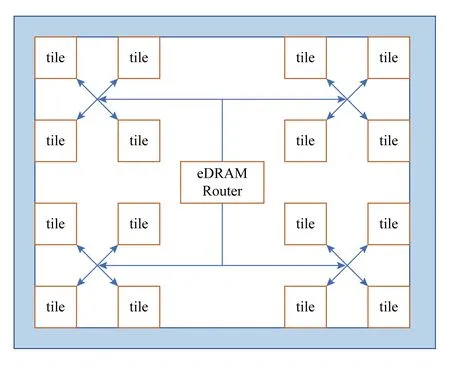
Fig. 5 Architecture of DaDianNao圖5 DaDianNao結(jié)構(gòu)方框圖
為了有效避免邏輯和數(shù)據(jù)的擁塞,DaDianNao采用如圖5所示的分塊(tile-based)結(jié)構(gòu),即將所有輸出神經(jīng)元的運(yùn)算被分為16個(gè)片段,分給相應(yīng)的運(yùn)算塊(tile).其每個(gè)運(yùn)算塊(tile)同時(shí)處理16個(gè)輸出節(jié)點(diǎn)對(duì)應(yīng)的輸入節(jié)點(diǎn),即單個(gè)芯片同時(shí)進(jìn)行256個(gè)并行運(yùn)算.
DaDianNao一方面使用了大量分布式的eDRAM來使所有的突觸(權(quán)重)靠近運(yùn)算器,另一方面通過采用了一個(gè)高帶寬的胖樹(fat tree)結(jié)構(gòu)來向每個(gè)塊(tile)廣播相同的輸入數(shù)據(jù)以及收集每個(gè)塊中不同的輸出節(jié)點(diǎn)值.其在胖樹結(jié)構(gòu)的末端,有2個(gè)eDRAM起到和DianNao中的NBin和NBout相同的作用.同時(shí),中心eDRAM中的輸入神經(jīng)元值被廣播到所有的塊(tile)來計(jì)算不同的輸出,這些輸出被集中到另一個(gè)中心eDRAM.這樣,一方面,在MLP和卷積層中,比起神經(jīng)元,權(quán)重的數(shù)量更多,所以移動(dòng)神經(jīng)元值比移動(dòng)權(quán)重更合理;另一方面,靠近計(jì)算單元儲(chǔ)存權(quán)重提供低能耗/低延時(shí)的數(shù)據(jù)供應(yīng).同時(shí)中心eDRAM連接到了hyper transport(HT)2.0接口,用以和相同的芯片通信系列.
3.3 PuDianNao
PuDianNao[55]是DianNao系列中,用以支持多種人工智能算法的人工智能芯片.其支持的算法有k-近鄰、樸素貝葉斯、k-均值、線性回歸、支持向量機(jī)、深度神經(jīng)網(wǎng)絡(luò)、分類樹等.PuDianNao在1 GHz的頻率下,具有每秒1.056萬億次運(yùn)算的峰值性能,但是只有0.596 W的功耗和3.51 mm2的芯片面積.多種人工智能算法在PuDianNao上運(yùn)行的平均性能相當(dāng)于使用通用GPU的性能,但是其能量消耗只有GPU大約百分之一.
Fig. 6 Architecture of PuDianNao圖6 PuDianNao結(jié)構(gòu)方框圖
如圖6所示,PuDianNao由功能單元、數(shù)據(jù)緩存、1個(gè)控制模塊、1個(gè)指令緩存和1個(gè)DMA組成.其中,為了支持多種人工智能算法,功能單元被分為1個(gè)用來支持多種基礎(chǔ)運(yùn)算的機(jī)器學(xué)習(xí)功能單元(MLU)和1個(gè)輔助MLU的算法邏輯單元(ALU).
MLU包含6級(jí)流水,用以支持多種人工智能算法.1)第1級(jí)計(jì)數(shù)級(jí)(Counter)通過按位與運(yùn)算或比較輸入數(shù)據(jù)然后累加結(jié)果來加速計(jì)數(shù)運(yùn)算,計(jì)數(shù)運(yùn)算在分類樹和樸素貝葉斯中經(jīng)常使用.2)第2級(jí)加法級(jí)(Adder)用來計(jì)算機(jī)器學(xué)習(xí)中普通的向量加法.3)第3級(jí)乘法級(jí)(Mult)計(jì)算向量乘法,并且可以從前一級(jí)或數(shù)據(jù)緩存中輸入數(shù)據(jù).4)第4級(jí)加法樹級(jí)(Adder tree)對(duì)乘法的結(jié)果進(jìn)行求和.5)第5級(jí)累加級(jí)(Acc)對(duì)求和結(jié)果進(jìn)行累加.6)最后的第6級(jí)Misc級(jí)負(fù)責(zé)排序和線性插值運(yùn)算,排序器可以用來尋找累加級(jí)中的最小值,線性插值器用來計(jì)算非線性函數(shù)的近似結(jié)果.其中,乘法級(jí)、加法樹級(jí)和累加級(jí)配合共同實(shí)現(xiàn)點(diǎn)乘運(yùn)算.此外,ALU用以提供MLU支持的基礎(chǔ)運(yùn)算外的各種各樣的運(yùn)算.
片上數(shù)據(jù)緩存被分為3個(gè)分離的部分:8 KB的HotBuf,16 KB的ColdBuf 和8 KB的 OutputBuf.HotBuf用來存儲(chǔ)短重用距離(short reuse distance)的輸入數(shù)據(jù),相反,ColdBuf用來存儲(chǔ)長重用距離(long-reuse distance)的輸入數(shù)據(jù),而OutputBuf用來存儲(chǔ)臨時(shí)或輸出數(shù)據(jù).其一方面適應(yīng)了機(jī)器學(xué)習(xí)中多種集群平均重用距離的變量,另一方面可以消除由不同讀入數(shù)據(jù)位寬引起的額外帶寬開銷.因此,PuDianNao可以避免內(nèi)存帶寬成為系統(tǒng)瓶頸.
3.4 ShiDianNao
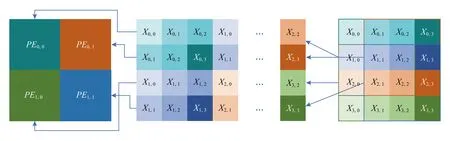
Fig. 7 Computation mode of ShiDianNao圖7 ShiDianNao運(yùn)算模式
ShiDianNao[39]是用來處理圖像實(shí)時(shí)人工智能算法的人工智能芯片.它能夠被嵌入到傳感器中,以實(shí)現(xiàn)實(shí)時(shí)的圖像處理.ShiDianNao可以直接從CMOS或CCD傳感器直接獲取輸入圖像,同時(shí)僅用SRAM進(jìn)行了完整的CNN映射,減少DRAM對(duì)權(quán)值的訪問.其相比DianNao,它大體上提升了60倍的能量效率.
ShiDianNao加速器包括1個(gè)突觸權(quán)值緩存(synapse buffer, SB)、2個(gè)儲(chǔ)存輸入輸出節(jié)點(diǎn)數(shù)據(jù)的緩存(NBin, NBout)、1個(gè)神經(jīng)功能單元(neural function unit, NFU)和1個(gè)算法邏輯單元(arith-metic logic unit, ALU),1個(gè)用來儲(chǔ)存指令和譯碼的緩存和譯碼器.其中,NFU用來進(jìn)行加、乘、比較等基礎(chǔ)的運(yùn)算,ALU專門用于激活函數(shù)的運(yùn)算.
NFU包含了一組處理基元(processing element, PE)陣列.基于2維滑窗的特點(diǎn),同時(shí)卷積核的大小有限,處理基元的性質(zhì)為:每個(gè)基元代表一個(gè)神經(jīng)元(節(jié)點(diǎn)),排列在一個(gè)2維的網(wǎng)格拓?fù)浣Y(jié)構(gòu)中.它可以傳輸FIFO中的數(shù)據(jù)到其相鄰的基元中.
以圖7所示的卷積層為例,假設(shè)PE陣列的大小為2×2,卷積層卷積核的大小為3×3,步長為1×1.在計(jì)算特征圖時(shí),每個(gè)PE計(jì)算一個(gè)輸出神經(jīng)元(節(jié)點(diǎn)),計(jì)算結(jié)束后移動(dòng)到一個(gè)新的基元中.在計(jì)算的第1個(gè)周期Cycle0,所有4個(gè)PE(PE0,0,PE0,1,PE1,0,PE1,1)從SB中獲取卷積核k0,0的值,從NBin中獲取第1個(gè)輸入節(jié)點(diǎn)的值(x0,0,x0,1,x1,0,x1,1),然后PE計(jì)算輸入節(jié)點(diǎn)和權(quán)值的乘積,把臨時(shí)結(jié)果儲(chǔ)存到寄存器中,同時(shí)從FIFO中獲取輸入節(jié)點(diǎn)值.PE1,0,PE1,1在Cycle1中從NBin讀取輸入節(jié)點(diǎn)x2,0,x2,1,在Cycle2中讀取x3,0,x3,1.PE0,0,PE0,1在Cycle1中從PE1,0,PE1,1的FIFO中讀取輸入節(jié)點(diǎn)x1,0,x1,1,在Cycle2中讀取x2,0,x2,1.同時(shí),在Cycle1和Cycle2中廣播卷積核值k1,0,k2,0,儲(chǔ)存輸入節(jié)點(diǎn)值到FIFO中.乘法運(yùn)算的結(jié)果和前一次計(jì)算的結(jié)果進(jìn)行累加.Cycle3~Cycle5和Cycle6~Cycle8的操作類似.PEi,0(i=0,1)從PEi,1中獲取輸入節(jié)點(diǎn)值xi,1-xi+2,1,xi,2-xi+2,2.PEi,1(i=0,1)從NBin中獲取輸入節(jié)點(diǎn)值xi,2-xi+2,2,xi,3-xi+2,3.同時(shí)系統(tǒng)順序地從SB中讀取卷積核值k0,1-k2,1和k0,2-k2,2,并將它們廣播給所有的PE,乘法和累加運(yùn)算仍然同之前一樣.這樣每個(gè)PE就完成了運(yùn)算,然后將累加的和傳給ALU就得到了輸出的y0,0,y0,1,y1,0,y1,1.
3.5 Cambricon-X
Cambricon-X[56]是一款專門針對(duì)稀疏剪枝設(shè)計(jì)的人工智能處理器.其利用人工神經(jīng)網(wǎng)絡(luò)的稀疏性,減少運(yùn)算量,同時(shí)減少功耗和面積.
其總體結(jié)構(gòu)如圖8所示,由Buffer Controller負(fù)責(zé)從NBin中讀取數(shù)據(jù)送給PE,同時(shí)將PE的執(zhí)行結(jié)果存放到NBout中,PE進(jìn)行具體的運(yùn)算.
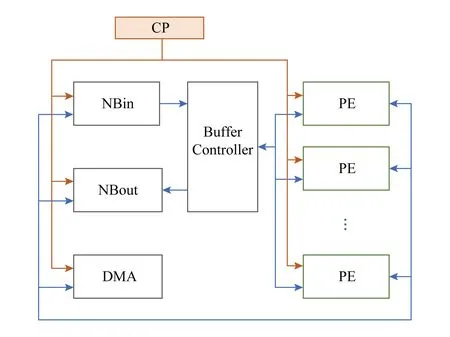
Fig. 8 Architecture of Cambricon-X圖8 Cambricon-X總體結(jié)構(gòu)框圖
其中,Buffer Controller的結(jié)構(gòu)如圖9所示,同時(shí)從NBin中讀取神經(jīng)元,然后依據(jù)各PE中的稀疏權(quán)值對(duì)應(yīng)的索引,篩選出該P(yáng)E需要運(yùn)算的神經(jīng)元,而后將篩選后的神經(jīng)元發(fā)送給相應(yīng)的PE,與PE中SB存儲(chǔ)的稀疏權(quán)值進(jìn)行運(yùn)算.從而,有效利用了稀疏神經(jīng)網(wǎng)絡(luò)的權(quán)值稀疏性,將不需要計(jì)算的數(shù)據(jù)在送給運(yùn)算部件之前先行剔除掉.同時(shí),其BCFU則將旁路過來的input數(shù)據(jù)和PE的運(yùn)算結(jié)果進(jìn)行整合,得到最終的數(shù)據(jù),將其寫入到NBout中.
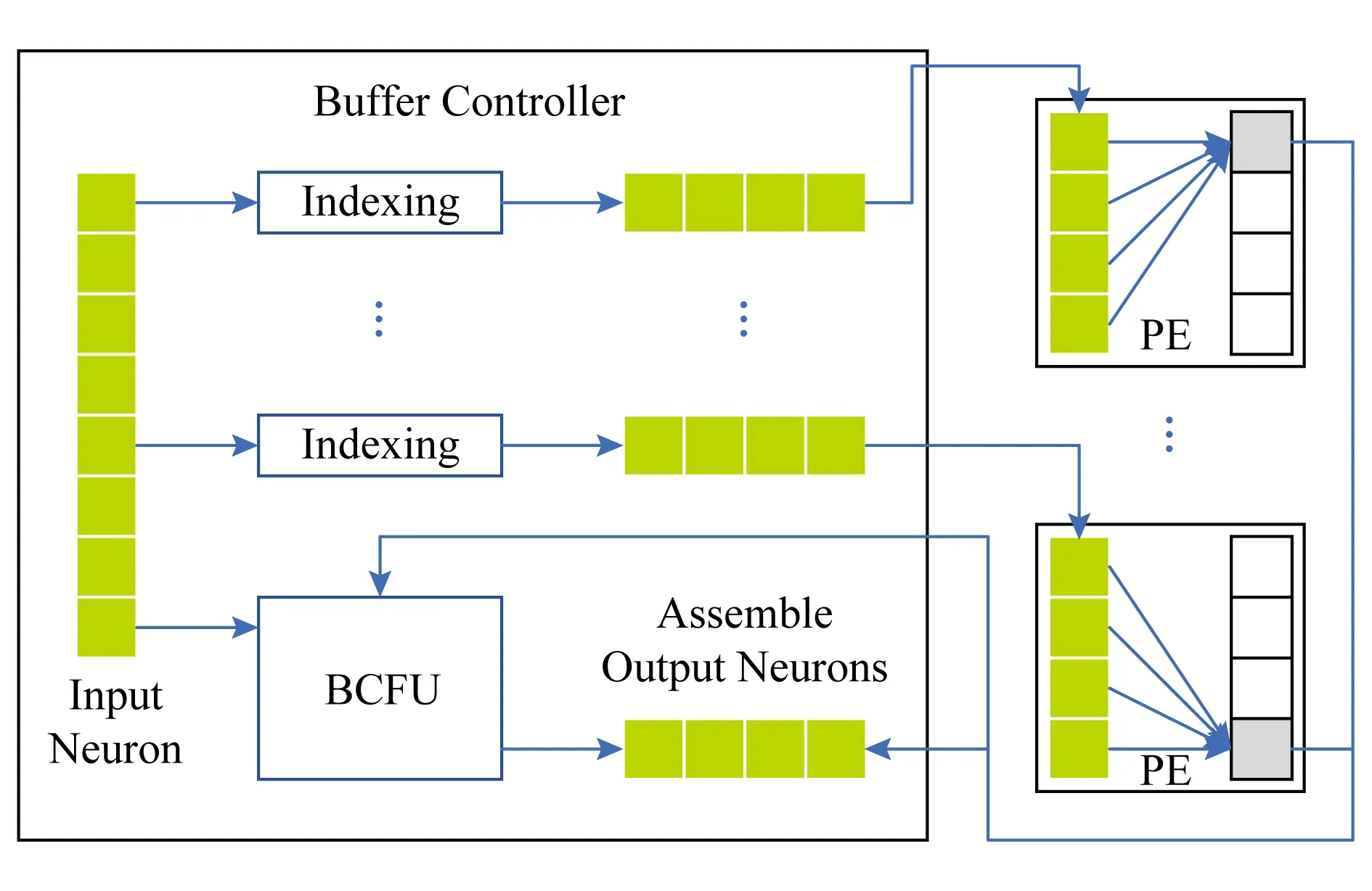
Fig. 9 Architecture of Buffer Controller圖9 Buffer Controller結(jié)構(gòu)框圖
PE結(jié)構(gòu)如圖10所示,其分為PEFU以及SB.PEFU即包含乘法以及加法樹,將稀疏選擇之后的神經(jīng)元以及權(quán)重進(jìn)行乘法,然后將得到的結(jié)果通過加法樹得到最終結(jié)果.SB則存放稀疏之后的權(quán)重,與稀疏選擇之后的輸入一一對(duì)應(yīng).

Fig. 10 Architecture of PE and PEFU圖10 PE和PEFU結(jié)構(gòu)框圖
Cambricon-X利用稀疏選數(shù),在16個(gè)PE的基礎(chǔ)之上,做到了544 GOP/s的峰值,但是65 nm的工藝之下面積僅有6.38 mm2,并且其功耗僅有954 mW.
3.6 指令集
Cambricon[57]是一種新型的用于人工智能芯片的指令集結(jié)構(gòu)(ISA).這種裝載結(jié)構(gòu)基于對(duì)現(xiàn)有的人工智能算法復(fù)雜的分析,集成了標(biāo)量、向量、矩陣、邏輯、數(shù)據(jù)傳輸和控制指令等.基于10種有代表性的NN技術(shù)對(duì)指令集進(jìn)行的評(píng)估表明,Cambricon對(duì)大范圍的人工智能算法有很強(qiáng)的表示能力,并且有比x86,MIPS和GPGPU等通用指令集更高的代碼密度.比起最新最先進(jìn)的人工智能芯片DaDianNao(能夠適應(yīng)3種神經(jīng)網(wǎng)絡(luò)),基于Cambricon的加速器原型只帶來了可以忽略不計(jì)的延時(shí)/能量/面積開銷,卻能夠覆蓋10種不同的神經(jīng)網(wǎng)絡(luò)基準(zhǔn).
Cambricon的設(shè)計(jì)受到RISC ISA的啟發(fā):首先,將復(fù)雜、高信息量的、描述高層次的神經(jīng)網(wǎng)絡(luò)功能塊(如網(wǎng)絡(luò)層)分解為對(duì)應(yīng)低層次運(yùn)算的更短的指令(如點(diǎn)乘),這樣就可以使用低層次的運(yùn)算來集成新的高層次的功能塊,這就保證了加速器有很廣泛的適用范圍.其次,簡(jiǎn)短的指令大大地降低了指令譯碼器設(shè)計(jì)和驗(yàn)證的復(fù)雜性.
Cambricon的裝載結(jié)構(gòu)只允許使用加載或儲(chǔ)存(load/store)指令對(duì)主內(nèi)存進(jìn)行訪問.Cambricon不使用向量寄存器,而是將數(shù)據(jù)儲(chǔ)存在片上暫存器中.Cambricon包含了4種指令類型:計(jì)算類型、邏輯類型、控制類型、數(shù)據(jù)傳輸類型.盡管4種指令有效長度不同,但為了設(shè)計(jì)的簡(jiǎn)單性和內(nèi)存對(duì)齊的作用,所有的指令均為64 b.
Cambricon的控制指令和數(shù)據(jù)傳輸指令與MIPS指令類似.Cambricon包含2條控制指令:jump和conditionalbranch.為了支持向量和矩陣運(yùn)算指令,Cambricon的數(shù)據(jù)傳輸指令支持可變數(shù)據(jù)尺寸.
基于對(duì)GoogLeNet的定量分析,神經(jīng)網(wǎng)絡(luò)中99.992%的基礎(chǔ)運(yùn)算可以被合并為向量運(yùn)算,99.791%的向量運(yùn)算可以被更進(jìn)一步合并為矩陣運(yùn)算.因此,人工智能算法可以分解為標(biāo)量、向量和矩陣運(yùn)算,而Cambricon充分地利用了這一點(diǎn).
1) 矩陣指令.Cambricon中含有6條矩陣指令.以MLP為例,每個(gè)全連接層進(jìn)行的運(yùn)算為y=f(Wx+b).其中的關(guān)鍵運(yùn)算是Wx,這可以通過矩陣乘向量指令(matrix-mult-vector, MMV)實(shí)現(xiàn).為了避免轉(zhuǎn)置運(yùn)算,還有VMM指令,在神經(jīng)網(wǎng)絡(luò)的權(quán)值更新中,會(huì)用到W=W+μΔW運(yùn)算.因此有叉乘指令(outer-product, OP)、矩陣乘標(biāo)量指令(matrix-mult-scalar, MMS)和矩陣加法(matrix-add-matrix, MAM)指令.此外Cambricon還提供了矩陣減法指令(matrix-subtract-matrix, MSM)指令用于玻爾茲曼機(jī)(RBM).
2) 向量指令.不失一般性,以Sigmoid函數(shù)為例:對(duì)于向量A,執(zhí)行Sigmoid運(yùn)算f(A)=eA(1+eA),即對(duì)向量A中的每個(gè)元素進(jìn)行激活操作.首先,使用向量指數(shù)指令(vector-exponential, VEXP)對(duì)向量A的每個(gè)元素求指數(shù);其次,使用向量標(biāo)量加法指令(vector-add-scalar, VAS)為上述結(jié)果向量eA的每個(gè)元素加1;最后,使用向量除法指令(vector-divide-vector, VDV)計(jì)算eA(1+eA).類似地,對(duì)于其他函數(shù)Cambricon提供相應(yīng)的向量指令,如vector-mult-vector (VMV),vector-logarithm(VLOG)等.此外,Cambricon提供了向量隨機(jī)數(shù)指令(random-vector, RV),用于相關(guān)人工智能算法的實(shí)現(xiàn)中.
3) 邏輯指令.最好的人工智能算法中往往使用比較運(yùn)算或其他邏輯運(yùn)算.Cambricon中使用vector-greater-than-merge (VGTM)指令用于支持最大匯聚(max-pooling)運(yùn)算.此外,Cambricon還提供了vector-greater-than (VGT), vector AND(VAND)等指令.
4) 標(biāo)量指令.Cambricon仍然提供基礎(chǔ)的單元素標(biāo)量運(yùn)算和標(biāo)量超越函數(shù)等指令.
4 人工神經(jīng)網(wǎng)絡(luò)相關(guān)技術(shù)的發(fā)展
4.1 權(quán)值與輸入量化
4.1.1 二值網(wǎng)絡(luò)
由于人工智能芯片中乘法器最消耗能量和空間,Courbariaux等人[58]提出使用只含有-1和1的二值化權(quán)重可以將復(fù)雜的乘法累加運(yùn)算替換為簡(jiǎn)單的累加運(yùn)算,進(jìn)而提升硬件的性能.二值化連接(BinaryConnect)方法基于2個(gè)關(guān)鍵點(diǎn):1)累加平均大量的隨機(jī)梯度需要足夠的精度,但含噪聲的權(quán)重(可以認(rèn)為離散化是一種噪聲)也同樣適用于隨機(jī)梯度下降法(SGD).SGD每步都很小并且含有噪聲,對(duì)每個(gè)權(quán)重而言,隨機(jī)梯度的求和將噪聲平均掉了,因此這些累加器需要足夠的精度(來計(jì)算平均).同時(shí),研究發(fā)現(xiàn)隨機(jī)舍入可以用來進(jìn)行無偏離散化.2)變化權(quán)重噪聲、失活(Dropout)和失連(DropConnect)等方法在激活值或權(quán)重中加入了噪聲.但這些噪聲權(quán)重實(shí)際上提供了一種正則化的方法,可以讓更模型有更好的推廣性(避免了過擬合).這些研究說明只有權(quán)重的期望值才需要很高的精度,噪聲實(shí)際上是有好處的.
BinaryConnect方法中的權(quán)重只含有+1和-1兩種情況,這樣乘法累加運(yùn)算就可以被加減運(yùn)算取代.一種直接的二值化方法如下:
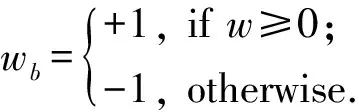
這種固定的二值化方法可以通過平均大量輸入權(quán)重的離散值來補(bǔ)償信息的損失.另一種更精細(xì)準(zhǔn)確的方法是隨機(jī)二值化方法:
其中,σ是Hard Sigmoid 函數(shù):
網(wǎng)絡(luò)的更新策略是:為了保證SGD算法正常工作,只在前向傳播和后向傳播時(shí)使用二值化權(quán)重,權(quán)重更新時(shí)仍使用精確的權(quán)重.
4.1.2 三值網(wǎng)絡(luò)
Hwang等人[59]提出了一種新的人工智能算法,它只需要三值(+1,0,-1)的權(quán)重和2~3位的定點(diǎn)量化信號(hào).訓(xùn)練算法仍使用反向傳播算法重訓(xùn)練定點(diǎn)網(wǎng)絡(luò),但使用了一些方法進(jìn)行提高精度,如通過范圍和靈敏度分析進(jìn)行精細(xì)信號(hào)分組(elaborate signal grouping)、同時(shí)量化權(quán)重和信號(hào)值、最優(yōu)量化參數(shù)搜索和對(duì)深度神經(jīng)網(wǎng)絡(luò)的考慮.
由于對(duì)權(quán)重和信號(hào)使用不同數(shù)據(jù)類型太復(fù)雜,所以需要根據(jù)它們的范圍和量化敏感度對(duì)它們分組.在每層的權(quán)重中,只有偏置值(bias)需要很高的精度(它們的范圍通常比其他權(quán)重大很多).對(duì)偏置值使用較高的(如8 b)定點(diǎn)數(shù)類型不會(huì)帶來很大的開銷.隱層信號(hào)的量化敏感度都很低,但網(wǎng)絡(luò)輸入的量化敏感度十分取決于應(yīng)用.一種傳統(tǒng)的量化方法是:通過最優(yōu)步長Δ直接量化訓(xùn)練的浮點(diǎn)數(shù)權(quán)重,浮點(diǎn)數(shù)權(quán)重可以通過先使用玻爾茲曼機(jī)(RBM)進(jìn)行預(yù)訓(xùn)練,然后使用誤差反向傳播的精細(xì)調(diào)整來獲得.可以通過最小化L2誤差方法(類似Lloyd-Max量化)獲得初始值,然后使用窮舉搜索對(duì)量化步長進(jìn)行微調(diào)來獲得最優(yōu)步長.為了減小搜索維度,可以使用貪心算法進(jìn)行逐層搜索.最終Δ大約是Lloyd-Max方法結(jié)果的1.2~1.6倍.
在權(quán)重精度很低時(shí),直接量化方法有很高的輸出誤差.這可以通過使用定點(diǎn)優(yōu)化方法重訓(xùn)練量化的神經(jīng)網(wǎng)絡(luò)來解決.直接對(duì)量化的神經(jīng)網(wǎng)絡(luò)使用反向傳播算法往往行不通,這是因?yàn)闄?quán)重的更新值往往比量化的步長小很多.為了解決這個(gè)問題,該網(wǎng)絡(luò)同時(shí)保留高精度和低精度的權(quán)重和信號(hào).高精度的權(quán)重用于計(jì)算誤差的累計(jì)和生成量化的權(quán)重,而低精度的權(quán)重用于后向傳播算法的前向和后向步驟.
4.2 計(jì)算以及傳輸剪枝
4.2.1 稀疏CNN
Graham[60]通過研究發(fā)現(xiàn),在高分辨率人工智能算法中使用單像素筆畫所寫的字符是一種稀疏矩陣.同時(shí)圖片填充后也可以認(rèn)為是稀疏的,充分利用矩陣的稀疏性可以更加高效地訓(xùn)練更大更深的網(wǎng)絡(luò).
假設(shè)手寫字符是一個(gè)N×N的二值圖片,非零像素?cái)?shù)目只有O(N),第1個(gè)隱層可以借助稀疏性計(jì)算得更快.傳統(tǒng)卷積層使用valid模式,但不是最優(yōu)的,解決方法有:1)對(duì)輸入圖片用零像素填充;2)在每個(gè)卷積層使用較少數(shù)目的填充,保證卷積使用full模式;3)對(duì)一組重疊的子圖使用卷積網(wǎng)絡(luò).而稀疏性能夠組合這些好的特點(diǎn).
對(duì)于手寫字體而言,更慢的池化操作(窗較小的池化層,網(wǎng)絡(luò)更深)可以保留更多的空間信息,使網(wǎng)絡(luò)具有更好的可推廣性.對(duì)通常的輸入而言,慢的池化層相對(duì)需要更高的計(jì)算代價(jià),但稀疏的輸入由于在網(wǎng)絡(luò)的前幾層保留了稀疏性,就只需要相對(duì)較低的能量代價(jià).
DeepCNet(l,k)的網(wǎng)絡(luò)結(jié)構(gòu)為:l+1層卷積層,中間是l層2×2的池化層.第l卷積層的濾波器的數(shù)量是nk,第1層濾波器尺寸為3×3,后面的層的濾波器的尺寸為2×2.在DeepCNet的基礎(chǔ)上加入network-in-network層,NiN層卷積核尺寸為1×1,在每個(gè)池化層和最后一個(gè)卷積層的后面加入NiN層,生成DeepCNiN(l,k)網(wǎng)絡(luò).在該網(wǎng)絡(luò)中,采用了2種措施來使反向傳播函數(shù)更加高效:首先,只對(duì)卷積層進(jìn)行失活操作,對(duì)NiN層不進(jìn)行操作.其次,使用了leaky修正線性單元:
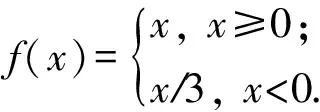
假設(shè)輸入全零時(shí),隱層變量的狀態(tài)為基態(tài)(ground state)(由于偏置的存在,基態(tài)的值非零).當(dāng)輸入稀疏數(shù)組時(shí),只需要計(jì)算和基態(tài)不同的隱層變量的值.為了前向傳播網(wǎng)絡(luò),對(duì)每層計(jì)算2種矩陣:1)特征矩陣(feature matrix)是一個(gè)行向量列表,一個(gè)代表ground state,一個(gè)代表該層中每個(gè)激活位置.矩陣的寬度時(shí)每個(gè)空間位置特征的數(shù)量.2)指針矩陣(pointer matrix)是一個(gè)和卷積層大小相同的矩陣.在其中儲(chǔ)存每個(gè)空間位置在特征矩陣中對(duì)應(yīng)的行.
4.2.2 ReLU運(yùn)行時(shí)剪枝
Akhlaghi等人[61]統(tǒng)計(jì)發(fā)現(xiàn),CNN中的ReLU層的大量輸出都是零值,說明了卷積層中大量的輸出為負(fù)值.同時(shí),不同中間層的零值空間分布不同.基于這個(gè)特點(diǎn),SnaPEA算法能夠提前判斷中間計(jì)算結(jié)果是否會(huì)產(chǎn)生零值來決定是否提前終止,進(jìn)而減少算法的計(jì)算量.SnaPEA有2種模式:1)準(zhǔn)確模式.不會(huì)降低分類的準(zhǔn)確率.2)預(yù)測(cè)模式.通過預(yù)測(cè)提前中止計(jì)算,以節(jié)省更多的計(jì)算量,代價(jià)是分類準(zhǔn)確度有一定降低.
在準(zhǔn)確模式下,將卷積核中的權(quán)重按照符號(hào)排序,正的權(quán)值在前,負(fù)的權(quán)值在后.在計(jì)算過程中定期檢查求和的符號(hào)位,一旦符號(hào)位為負(fù)就終止運(yùn)算,在這種情況下不會(huì)降低分類準(zhǔn)確率.
在預(yù)測(cè)模式下,如果卷積運(yùn)算在特定次數(shù)的MAC運(yùn)算后低于相應(yīng)的閾值,最終的結(jié)果就很可能是負(fù)的,于是提前終止運(yùn)算.但是這種操作會(huì)降低最終分類的準(zhǔn)確度,為了減小這種損失,需要確定2個(gè)參數(shù):閾值和相應(yīng)的運(yùn)算次數(shù).參數(shù)可以通過一個(gè)多變量約束的優(yōu)化問題來確定,進(jìn)一步通過貪心算法來解決這個(gè)問題.該算法包括3個(gè)步驟:1)獨(dú)立測(cè)量準(zhǔn)確率對(duì)每個(gè)卷積核引入不精確值(提前停止)的靈敏度,根據(jù)這個(gè)靈敏度確定每個(gè)卷積核的參數(shù);2)聯(lián)合每層各個(gè)核的參數(shù),為每層確定一組參數(shù);3)迭代調(diào)整各層參數(shù),使得在減少最大計(jì)算量的同時(shí)達(dá)到可以接受的準(zhǔn)確率.由于確定參數(shù)的算法執(zhí)行一次,所以并不會(huì)在CNN執(zhí)行期間增加額外的運(yùn)行開銷.
預(yù)測(cè)模式執(zhí)行特定次數(shù)計(jì)算后根據(jù)閾值判斷是否終止計(jì)算,因此需要確定計(jì)算哪一部分權(quán)值.一種方法是將權(quán)重按照絕對(duì)值降序排序,選擇幅值較大的進(jìn)行計(jì)算.但由于忽略了數(shù)據(jù)隨機(jī)性和數(shù)據(jù)之間的依賴,這種方法會(huì)導(dǎo)致正確率急劇下降.SnaPEA將權(quán)重按升序排序,并將其分為幾組,從每組中選取幅值最大的權(quán)重參與計(jì)算.在這種情況下,劃分的組數(shù)就是運(yùn)算的次數(shù).
4.3 特殊器件
3.1節(jié)所述的DianNao系列芯片采用了分布式片上內(nèi)存來減小數(shù)據(jù)傳輸?shù)哪芰块_銷,此外還有其他降低數(shù)據(jù)傳輸能量開銷的方法:例如,讓片下高密度的內(nèi)存更加靠近計(jì)算單元,或者直接將計(jì)算單元集成到內(nèi)存中.在嵌入式系統(tǒng)中,還會(huì)將計(jì)算模塊集成到傳感器中.一些相關(guān)的研究中使用了模擬信號(hào)處理,但其有增加電路敏感性和設(shè)備非理想性的缺點(diǎn),導(dǎo)致的結(jié)果是通常使用降低的精度進(jìn)行計(jì)算.另一個(gè)問題是,DNN通常在數(shù)字域進(jìn)行訓(xùn)練,對(duì)于模擬信號(hào)處理,DAC和ADC就還需要額外的能量消耗.
同時(shí),除了如DaDianNao等,把DRAM集成到芯片中,還可以使用TSV技術(shù)(也稱3D內(nèi)存技術(shù))將DRAM堆疊在芯片上.這種技術(shù)已經(jīng)以混合立方儲(chǔ)存器(HMC)和高帶寬內(nèi)存(HBM)的形式商業(yè)化了.相比二維 DRAM,三維內(nèi)存(3D DRAM)的電容更小,因此能夠?qū)捥嵘粋€(gè)量級(jí),同時(shí)能夠節(jié)省5倍的能量.
將處理單元集成在內(nèi)存中是另一種思路[62].例如,乘法累加運(yùn)算可以集成在一個(gè)SRAM數(shù)組的位元(bit cell)中.在這項(xiàng)研究中,使用了5位DAC將字線(WL)轉(zhuǎn)換成代表特征向量的模擬電壓,使用位元(bit cell)儲(chǔ)存權(quán)重(±1),位元電流(IBC)計(jì)算出特征向量和權(quán)重的積,位元電流之間相加來對(duì)位線(VBL)放電.比起分離進(jìn)行讀取和運(yùn)算,這種方法節(jié)省了12倍的能量.
乘法累加運(yùn)算可以直接集成在先進(jìn)的非易失性儲(chǔ)存器中(憶阻器).特別地,可以使用電阻器的電導(dǎo)作為權(quán)重,電壓作為輸入來進(jìn)行乘法運(yùn)算,電流是乘法的輸出.加法操作可以通過將不同憶阻器的電流相加進(jìn)行.這種方法的優(yōu)點(diǎn)是,由于計(jì)算被集成在內(nèi)存中,所以不用進(jìn)行數(shù)據(jù)的傳輸,進(jìn)一步節(jié)省了能量消耗.可供用作非易失性儲(chǔ)存器的器件有:phase change memory (PCM),resistive RAM(ReRAM),conductive bridge RAM (CBRAM)和spin transfer torque magnetic RAM (STT-MRAM)等.該技術(shù)的缺點(diǎn)有:降低了計(jì)算精度、需要忍受額外的ADC/DAC開銷、數(shù)組大小受連接電阻的導(dǎo)線數(shù)目限制、對(duì)憶阻器的編程需要消耗很大的能量等.ISAAC將DaDianNao中的eDRAM替換為憶阻器,為了解決精度不足問題,其中使用了8個(gè)二位的憶阻器來進(jìn)行16 b的點(diǎn)乘運(yùn)算.
在圖像處理領(lǐng)域,將數(shù)據(jù)從傳感器傳輸?shù)絻?nèi)存中占據(jù)了系統(tǒng)能量消耗的很大的一部分.因此有一些研究試圖讓處理器盡可能地接近傳感器.特別地,大部分研究針對(duì)的是如何將計(jì)算移動(dòng)到模擬域以避免ADC的使用,進(jìn)而節(jié)省能量.然而,電路的非理想性導(dǎo)致了模擬計(jì)算中只能使用更低的精度.有研究將矩陣乘法集成在ADC中,其中乘法的高位使用開關(guān)電容進(jìn)行計(jì)算.此外,還有研究實(shí)現(xiàn)了模擬的累加運(yùn)算,其中假設(shè)3 b權(quán)重和6 b激活值的精度是足夠的,這將傳感器中ADC轉(zhuǎn)換次數(shù)減少到1/21.更有研究將整個(gè)卷積層的運(yùn)算在模擬域?qū)崿F(xiàn).
除了可以將計(jì)算集成在ADC之前,將計(jì)算嵌入在傳感器本身也是可行的.有研究使用了Angle Sensitive Pixels傳感器來計(jì)算輸入的梯度,降低了10倍的數(shù)據(jù)傳輸消耗.此外,由于DNN第1層的輸出通常是類似梯度的特征圖,這使得有可能跳過第1層的計(jì)算,進(jìn)一步減少能量消耗.
5 未來工作展望
人工智能日益成為工業(yè)界和學(xué)術(shù)界極其重要的一個(gè)領(lǐng)域.隨著人工智能算法日益復(fù)雜以及人工智能處理的數(shù)據(jù)日益增大,人工智能芯片相比GPU和CPU等傳統(tǒng)處理器,具有越來越明顯的優(yōu)勢(shì).人工智能芯片可以滿足在日益復(fù)雜的應(yīng)用場(chǎng)景中,對(duì)存儲(chǔ)性能和計(jì)算能力的巨大需求.隨著技術(shù)的發(fā)展和研究的深入,人工智能芯片已經(jīng)發(fā)展出了諸如DianNao系列的芯片系列,解決了很多現(xiàn)有的問題和應(yīng)用場(chǎng)景.但是,目前的人工智能芯片,其訪存瓶頸和計(jì)算能耗依然有很多的提升空間.其未來可能的發(fā)展方向有5個(gè)方面:
1) 隨著應(yīng)用場(chǎng)景的增多,人工智能算法日益復(fù)雜,作為人工智能芯片,保持針對(duì)人工智能算法的通用性將會(huì)是一個(gè)巨大的挑戰(zhàn).
2) 人工智能算法中,其計(jì)算過程具有非精確性特點(diǎn),因此,使用低精度量化是減少人工智能算法的計(jì)算復(fù)雜度和開銷的一種重要的手段.其不僅可以如4.1節(jié)所說,使用二值網(wǎng)絡(luò)處理特定的算法,同時(shí)還可以尋找適用范圍更加廣泛、更加精準(zhǔn)的算法.將這些算法應(yīng)用在人工智能芯片之后,將極大地節(jié)省芯片功耗和面積.
3) 由于現(xiàn)有的人工智能算法,其搜索空間龐大無比.因此,進(jìn)一步利用其稀疏性質(zhì),減少人工智能算法的計(jì)算復(fù)雜度和開銷,將會(huì)使得人工智能芯片具有更低的功耗和面積.
4) 隨著芯片集成度越來越高,如何在一個(gè)芯片中部署多個(gè)運(yùn)算核單元,并且使得這些運(yùn)算核協(xié)同工作,獲得較高的加速比,也逐漸成為一個(gè)重要的發(fā)展方向.
5) 對(duì)于人工智能算法,其計(jì)算單元相對(duì)簡(jiǎn)單,因此,探索新的物理器件例如光衍射、憶阻器等來進(jìn)行存儲(chǔ)和運(yùn)算,可以極大地優(yōu)化人工智能芯片的功耗和算法.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
西安航空學(xué)院學(xué)報(bào)(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
測(cè)控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測(cè)試(2018年18期)2018-11-14 02:30:34
IT經(jīng)理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
電信科學(xué)(2016年10期)2016-11-23 05:11:56
南風(fēng)窗(2016年19期)2016-09-21 16:51:29
南風(fēng)窗(2016年19期)2016-09-21 04:56:22
