方塊白文文獻數據庫
2019-02-15 08:08:10韋韌
科技與創新 2019年1期
韋韌
?
方塊白文文獻數據庫
韋韌
(中國社會科學院民族學與人類學研究所,北京 100081)
白族是一個有著悠久歷史和豐富文化的少數民族。方塊白文是古代白族在長期使用漢語文的過程中,用來記錄廣泛使用的白語,仿照漢字創制的一種民族文字,是一種既借用漢字又自造拼合字的意音文字。針對方塊白文情況復雜、信息量大等問題,在充分吸收已有研究成果的基礎上,在普通語言學、普通文字學、比較文字學、漢字構形學理論指導下,借鑒漢字整理的方法,設計和建立了方塊白文數據庫,并以方塊白文材料《云龍白曲殘本》為例,詳細介紹利用數據庫技術研究方塊白文的初步成果,以及方塊白文數據庫在中國少數民族語言文字研究創新中所起到的巨大作用。
方塊白文;數據庫;《云龍白曲殘本》;白族
白族是一個有著悠久歷史和豐富文化的少數民族。白族自稱“僰”“僰子”“僰尼”,均是“白人”之意。別稱比較多,不僅不同民族對白族稱呼不同,連同一個民族對分布在不同地區的白族也有不同的稱呼。納西族稱瀾滄江邊上的白族為“那馬”,稱大理和麗江的白族為“勒布”。傈僳族則稱怒江邊丘的白族為“勒墨”,稱大理白族為“臘本”。洱海地區及其附近漢族稱白族為“民家”。新中國成立后,1956-11,大理白族自治州建立時,根據廣大白族民族意愿,確定族名為“白族”。白族是我國西南山區人口較多的少數民族,根據2010年民族統計年鑒,全國白族總人口有190多萬人,主要聚居在云南省的大理白族自治州和昆明、楚雄、麗江等地州市,少數散居在貴州省畢節、六盤水、江陵等地市、湖南省張家界市及湖北省鶴峰縣。
方塊白文是古代白族在長期使用漢語文的過程中,用來記錄廣泛使用的白語,仿照漢字創制的一種民族文字,是一種既借用漢字又自造拼合字的意音文字。方塊白文的歷史文獻以碑刻、有字瓦片和經卷的批注浮簽為主,近現代方塊白文文獻以祭文、白曲曲本、大本曲曲本為主。有部分碑刻內容已被釋讀出來,但還有一些,由于年代太久遠,與現代白語差異巨大,還有待破譯。建立方塊白文數據庫,可以利用數據庫的優勢,整理、分析方塊白文,破解存疑文獻。
1 方塊白文數據庫建設的總體思路
1.1 必要性和可行性
我們已經進入數字化時代,數字化技術的運用也早已成為科學研究的一個必要有效手段。早在20世紀90年代,漢語言研究就已開始使用數據庫技術,有一部分少數民族語言研究也引入數據庫技術,建立了一系列少數民族語言數據系統。方塊白文由于之前收集的材料較少,目前還沒有建立方塊白文材料數據庫,相比較其他少數民族的語言研究,稍顯滯后。因此,迅速建立一個方塊白文數據庫是非常有必要的,數據庫的建立既可以加大方塊白文材料的整理速度和準確度,又可以使方塊白文的資源共享,減少工作中的重復浪費,提高工作效率。開展方塊白文數據管理關鍵技術的研究,也為方塊白文語言數據和元數據存儲提供了堅實的技術基礎,同時也是滿足少數民族語言信息快速檢索與少數民族語言研究的需要。研究開發方塊白文數據庫系統對搶救和挖掘白族非物質文化遺產也具有非凡的意義。
語言學的材料一般都很龐大,信息多面,必須考慮采用有效的手段進行組織、存儲和管理,并在此基礎上能夠充分、有效地實現語言數據共享和數據發布。其中語言數據存儲是數據查詢檢索、管理、共享發布的基礎,開展存儲構建技術的研究,解決語言數據高效、安全存儲問題,為數據的有效集中、高效查詢、管理、快速傳輸提供基礎,是迫切需要的。
在語言學的研究中常需要對數據進行索引、搜索、排序、抽取和分組等操作,數據庫在這些問題上都很容易實現,并且能形成一個數據庫管理系統。因此,用數據庫進行方塊白文的處理是合適的。
數據庫的建設和方塊白文文字整理研究思路是相輔相成、互相促進的關系。在最初建立數據庫時,方塊白文文字整理研究思路還不明晰,數據庫的結構也很簡單,只是根據材料來源的特點,設計了描述方塊白文形音義的幾個字段。在大量輸入和接觸方塊白文材料后,逐漸總結出方塊白文的特點,摸索出研究的一些規律,由于方塊白文字符的類型不同,各類型有自己的特點,需要分別建立數據表,設計能夠反映其特性的數據庫字段,以求盡量全面地描述出材料的不同信息。建立合成字數據庫又單獨增加了示音構件、表義構件、標示構件3個字段。因此,數據庫是進行方塊白文文字整理研究的重要手段,研究方法的進展也必定會反映在數據庫上。
1.2 數據庫的選用
Oracle Database是關系數據庫的一種,支持關系對象模型的分布式,面向Internet計算,它提供安全的、開放的和科學的信息數據管理方法。由一個Oracle DB和一個Oracle Server實例組成保障了Oracle數據庫具有數據自治性并且能提供很好的數據存儲機制,方便了用戶的使用和操作,提高了信息管理的效率。Oracle數據庫是目前世界上使用最為廣泛的數據庫管理系統,作為一個通用的數據庫系統,它具有完整的數據管理功能;作為一個關系數據庫,它是一個完備關系的產品;作為分布式數據庫它實現了分布式處理功能。 Oracle還提供了豐富的數據類型,可以用準確的數據類型和合理的數據長度來定義數據類型,這樣不但可以降低數據冗余而節省系統存儲空間,還可以提高信息系統的檢索效率。
1.3 數據庫建設與方塊白文研究的關系
方塊白文情況較復雜,提供的信息涉及較多方面,設計和建立方塊白文數據庫是一項消耗巨大精力的工作。在具體操作過程中需要不斷地研究和解決問題,如果考慮不周到或有疏忽遺漏,會給后面的研究工作帶來不可預計的后果,因此,數據庫的建設既是基礎又是關鍵,是方塊白文文字整理研究的重要基礎。
數據庫的建設和方塊白文文字整理研究思路是相輔相成、互相促進的關系。
1.4 數據庫建設的總體方法和階段
總體方法是根據方塊白文的不同類型和特點,分別建立結構不同的數據表,盡量全面地反映各種方塊白文的不同信息,以達到分析每一個字形都可以調動多方面信息的效果。一個信息量充足完善的數據庫需要一個長期建立的過程,必須不斷地完善和補充數據庫。
數據庫建設主要分為4個階段,依次是數據庫結構設計和建立、數據錄入、數據校對和數據整理。對方塊白文進行語言學的大量分析處理沒有先例,在進行方塊白文數據庫的建設時,是摸索前行的,4個階段交叉推進。比如錄入、校對數據時,需要不斷地驗證數據庫的結構設計是否可以充分地展示材料各方面信息,并適當加以改進;同樣,在錄入和校對時也要根據碰到的新情況、新問題對數據的整理步驟和方法進行調整。需要說明的是,在數據錄入時,作者對方塊白文材料已有一些粗略的思考并進行一定的分析,但全面、細致的分析是在數據庫完全建立后才進行的。因此,建立方塊白文數據庫不是遵循一般數據庫建設的4個階段逐步計劃進行,而是基本按照4個階段建立數據庫的順序,但在4階段中不斷交叉互進。
1.5 建設步驟流程
數據庫建設步驟流程如圖1所示。
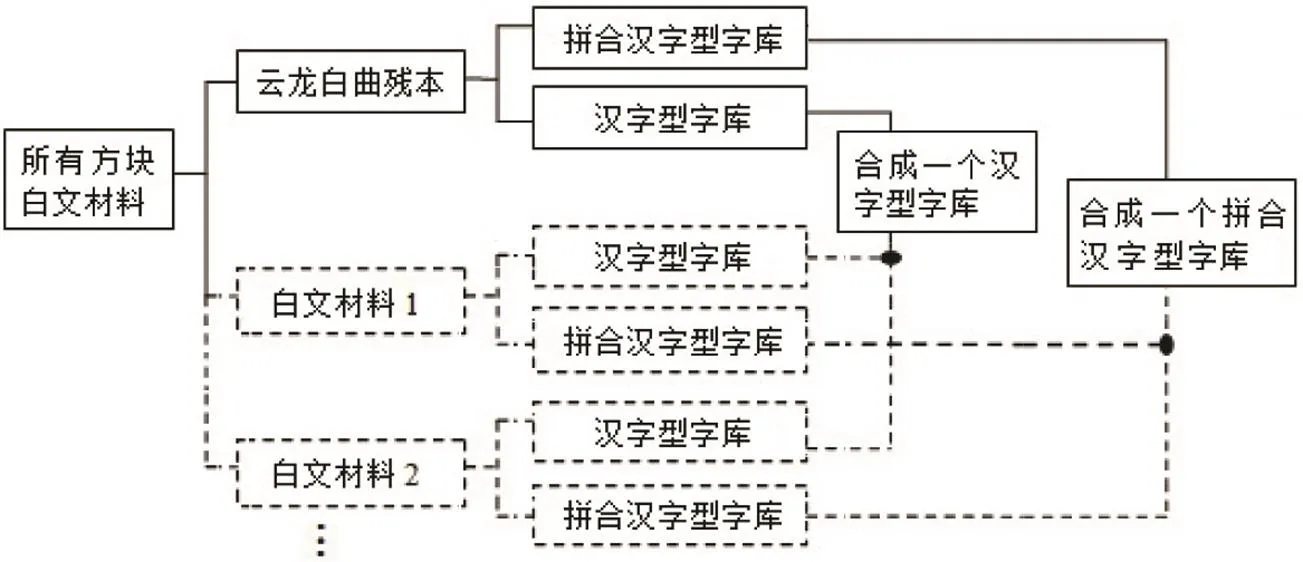
圖1 數據庫建設步驟流程圖
2 《云龍白曲殘本》材料的數據庫建設
方塊白文到底有多少,目前尚不得而知。已發現的文獻多以文學作品形式存在,分布范圍廣,搜集和整理的工作較為艱巨。因此,為了盡快建立一個方塊白文樣本庫,選取的第一份材料一定是可以直接用于研究且學界認可的資料。
目前,已發現并整理的方塊白文文獻形式包括碑刻、大本曲、“吹吹腔”劇本、宗教經文、祭文。選取的第一份建庫材料,《云龍白曲殘本》是中國科學院少數民族語言調查第三工作隊白語小組于1958年在云南省云龍縣寶豐鄉搜集而來,后由中國社會科學院民族學與人類學研究所研究員徐琳先生保存下來。現由美國馬里蘭州圣瑪利大學傅京起老師收藏。目前曲本已釋讀出版(見《中國白族白文文獻釋讀》),可以直接用于研究。曲本中的文字除使用白族一般運用的漢字音讀、訓讀、借詞外,大量使用漢字或漢字部首構造表音兼表意的合成字,合成字在整本曲本中出現較多,遠多于其他已釋讀方塊白文文獻。這些合成字是我們分析白文的重要基本材料,這也是選取《云龍白曲殘本》作為第一個建庫材料的重要原因。
2.1 數字化
在數字化《云龍白曲殘本》文獻原文時,基本采用紫光華宇拼音輸入法v6.7,遇到超出輸入法所支持的字符,使用逍遙筆手寫識別軟件和方正超大字符集。如果字符不在上述兩種輸入法所支持的字符集內,則使用Windows自帶的TrueType造字程序進行造字。
考慮到使用的廣泛性和通用性,論文作者在數字化材料時,將《中國白族白文文獻釋讀》中白曲的注音音標轉寫為潘悟云、李龍開發的云龍國際音標輸入法4.0版。
2.2 建立數據表
數據庫的一個顯著優點在于能夠容納海量數據,并方便管理。這一優點體現在建庫者能夠建立關系清楚明晰的數據庫表。
2.2.1 建立語言材料元數據表
元數據是描述數據及其基本屬性的數據,相當于所有數據的管理中心,為將來數據的使用和管理提供方便。
元數據表字段共6個,分別是材料名稱、對應的漢字形字表表名、對應的拼合漢字形字表表名、建庫時間、材料收集人和材料來源。
2.2.2 建立全字表
全字表字段共7個,分別是曲序號、句序、白字、音、義和句直譯。
2.2.3 建立圖文對照表
圖文對照表字段共2個,分別是字形和對應的圖片。
2.2.4 建立漢字型方塊白文字表
漢字形方塊白文字表字段共13個,分別是曲序號、句序、字形、字形分析、構形模式、聲、韻、調、對應漢字、雙音詞義、句直譯和句意譯。
2.2.5 建立拼合漢字形方塊白文字表
拼合漢字形方塊白文字表字段共15個,分別是曲序號、句序、字形、聲、韻、調、對應漢字、雙音詞義、字形分析、示音構件、表義構件、標示構件、構形模式和備注。
依據數據庫,統計得出作品總字數7 241字,使用的單字1 307個(包括異體字),其中,漢字字形的單字828個,拼合漢字的單字479個。數據庫條數共計2 815條,條數指的是每一個在《云龍白曲殘本》中以不同的形音義出現的字,我們都作為一條。比如“阿”在數據庫中以不同的音義出現了9次,在統計使用的單字時,算作1個方塊白文,數據庫中算作9個方塊白文。我們這樣處理就是要全面地反映方塊白文的面貌。只有這樣,才能全面考察方塊白文文字系統,使研究結論更加準確。
依據方塊白文數據庫,借鑒現有漢字研究的理論方法,采用結構功能分析法對方塊白文的字體類型進行分析,方塊白文分成借用字和自造拼合字兩種類型。借用字是白文借用漢字。以字符構件具有的功能屬性,即白文字符與漢字字符的形音義對應關系為標準,可分為全借字、音讀字、訓讀字、記號字四類。自造拼合字是借用字進入白語言語音系統后,白族仿造漢字構字原理創制。從字符功能角度看,分為7類:音義拼合字、會義拼合字、雙音拼合字、標音拼合字、標義拼合字、標示音義拼合字、記號拼合字。
3 總結
本文介紹的是方塊白文原始語料數據庫的建設,以這些原始語料數據庫作為方塊白文研究的基礎,在對方塊白文進一步的分析研究中,會不斷生成新的數據庫表,可以用于各方面的研究。數據庫將形成方塊白文語料庫,并最終建立方塊白文研究系統。該系統將為白族語言研究提供堅實的服務基礎,并為其他漢字系少數民族文字的數據庫建設提供相關的技術探索。作者對方塊白文的信息處理已經解決了基本的編碼、造字、錄入、排版、部分史料數據庫建設方面的技術問題,但是與實際需求還有一定的距離。根據現有基礎和應用需求,下一步應該開展的工作包括:①盡快制訂方塊白文字符標準,把它納入國家和國際標準體系。②出版方塊白文字典和開發方塊白文和漢文翻譯系統。由于方塊白文字形復雜,各方言區和各個使用者書寫的方塊白文不統一,導致目前能夠閱讀方塊白文的人越來越少,方塊白文文獻的收集、整理任務越來越艱巨,因此,編輯方塊白文字典和研究開發方塊白文和漢文翻譯系統的工作迫在眉睫。
感謝傅京起教授提供原件資料,王鋒研究員提供白語方言調查詞表用于作者論文創作!
[1]徐琳,趙衍蓀.白語簡志[M].北京:民族出版社,1984.
[2]《中國少數民族語言簡志》編委會,《中國少數民族語言簡志叢書》修訂本編委會.中國少數民族語言簡志叢書修訂本·卷貳[M].北京:民族出版社,2009.
[3]張錫祿,甲斐勝二.中國白族白文文獻釋讀[M].桂林:廣西師范大學出版社,2011.
[4]王寧.漢字構形學講座[M].臺北:三民書局,2013.
[5]宋繼華,王寧,胡佳佳.基于語料庫方法的數字化《說文》學研究環境的構建[J].語言文字應用,2007(01):132-138.
[6]李奕琳.借音壯字研究思路與數據庫建設[D].南寧:廣西大學,2006.
[7]劉連芳,顧林,黃家裕,等.壯文與壯文信息處理[J].中文信息學報,2011,25(06):175-182.
[8]柳長青,杜建錄.網絡下的西夏文及西夏文獻處理研究[J].寧夏社會科學,2008(05):113-115.
[9]王成平.彝語言語料資源數據庫的設計與共享的實現[J].中文信息學報,2016,30(01):129-132.
[10]劉連芳,海銀花,那順烏日圖,等.壯、蒙古、維、哈、柯、朝語信息處理研究進展[J].廣西科學院學報,2018年,34(01):18-26.
2095-6835(2019)01-0022-03
G250
A
10.15913/j.cnki.kjycx.2019.01.022
韋韌(1982—),女,博士,助理研究員,主要研究領域為民族語文信息化。
〔編輯:張思楠〕
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
