電力監控平臺I6000接口的數據處理模型
2019-01-30 07:49:20李斌趙中英王敏
電子技術與軟件工程 2019年1期
文/李斌 趙中英 王敏
1 相關工作
1.1 研究背景及意義
隨著信息化的迅速發展,大數據、云平臺在電力領域的廣泛應用,電力數據規模越來越龐大,部分數據的價值不高,I6000作為電力領域信息化的業務平臺,每天產生大量的數據,如何有效的處理數據,探測其中有效的數據,及時的探測其中有效的數據顯得頗為重要,通過一定的數據挖掘和算法對數據進行采集和分析,可以快速檢測到其中的隱藏數據和故障數據,有助于保證系統安全穩定的運行,提升運維工作效率。
1.2 算法概述
Mitchell定義機器學習為:對于一個給定任務,通過一個性能參數P來衡量任務的性能高低,一個目標程序可以從實例中或者經驗中進行學習,通過學習,這個目標程序對于給定任務的處理效率和性能就會提高。本文以T作為給定的任務,E作為訓練樣本,性能的度量參數設置為P,經過訓練集E的訓練以后,采用新的測試集進行測試,觀測參數P的變化。結合I6000接口數據的特點,本文采用的是無監督學習法,無監督K-means算法流程為:
給定const值K,從測試集中選擇一個random M 值作為聚類中心。對于測試集中的每一個點w(x,y),計算點w到M的距離D(x),公式如下:

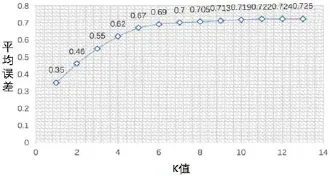
圖1:K值的選取
從測試集中選取D(x)較大的點作為新的聚類中心:a.同理,對于測試集中的每個點,計算其和最新聚類中心的距離D(x),并將結果保存,Sum(D(x)=所有保存結果之和。b.重新選擇隨機值,通過同樣的方法計算新的聚類中心。Sum(D(x)*Randomr=r,currSum += D(x),循環遍歷直到其currSum>r。得到種子點。
重復重復上述步驟,至數量M=k即可。對測試集中所有測試點與k個中心的距離進行計算。將最小的距離記為Ki。計算所有的檢測框后,重新計算每一類的質心。再重復計算,直到聚類中心的變化小于5%,最終輸出k個坐標的x和y。
2 數據集選擇
本文采用的數據都是I6000接口的測試數據,經過清理、集成、選擇、歸一化等過程。使用的數據都是測試環境中的真實數據。在數據選擇前,對數據進行預處理,刪除不符合字段類型等錯誤數據。量化數據進行歸一化處理。公式如下:x*=(x-min)/(max-min)把數據變為(0-1)區間進行分析。
3 實驗過程
3.1 K-means算法K值的選取
本文通過測試K值和聚類后平方誤差的關系,繪制圖表,如圖1所示,隨著K值的增大,平均誤差逐漸趨于平穩,當K值增大到6以后,平均誤差基本不再發生變化。
3.2 對數據進行聚類
在選定k值后,對于給定的I6000接口數據進行聚類,聚類完成后,得到對應的數據分析的結果分布,本文實驗結果顯示,數據呈現具有規律性,不同類型的數據會分布在一定的區域內。不同區域的數據代表不同的數據結果和導向。
4 結語
本文通過I6000測試環境中的實際數據,對數據進行了聚類分析和深度學習,通過測試發現,I6000的接口數據可以通過聚類分析的方法使得結果呈現不同的類型,便于對系統的故障和敏感信息的定位,同時解決了I6000數據延遲問題,本文只需要在I6000接口采集相應的數據進行處理,無需通過延遲或者定期傳輸。
