基于LSTM的移動對象位置預測算法*
2019-01-17 06:32:20江國華秦小麟王鐘毓
計算機與生活 2019年1期
關鍵詞:模型
高 雅,江國華,秦小麟,王鐘毓
南京航空航天大學 計算機科學與技術學院,南京 210016
1 引言
隨著以全球定位系統(global position system,GPS)為代表的定位技術的日趨成熟和普及,通過移動定位設備獲取到的移動對象軌跡數據越來越多。位置信息是用戶最為重要的上下文信息之一,可為各類服務和應用提供重要支持,如智能交通系統(intelligent transport system,ITS)、智能導航系統、路線規劃、推薦系統[1]、公共設施規劃[2]和公共安全[3]等。大規模可用性極高的數據和基于位置服務(location based service,LBS)的應用的發展,使移動對象的軌跡信息逐漸成為研究熱點。其中,位置預測是基于位置的服務的重要組成部分,提出有效方法以分析和預測移動對象位置具有重要意義。例如,在導航系統中,通過用戶的車載GPS記錄其歷史軌跡信息,挖掘其運動模式并預測用戶的目的地,推薦不擁堵的最優路線或尚有空位的停車場。在交通系統中,對城市車輛軌跡的位置預測有助于了解市民的出行規律,提前預知某一時段某一路線的交通狀況。在基于位置的信息投遞中,通過用戶的手持移動設備獲取用戶的歷史簽到數據,分析并預測用戶下一步的位置,手機應用中的廣告推送功能可用此對其進行相關的廣告投放。
移動對象位置預測的方法的實現步驟一般為:首先,抽象化真實數據,將地理位置信息和時間信息以易于處理的方式表示;然后,對抽象化后的軌跡數據建模,進一步挖掘其運動模式[4];最后,對當前用戶的輸入軌跡,根據習得的運動模式,預測該用戶下一步最可能到達的位置。
基于移動對象軌跡數據的位置預測問題得到了廣泛的研究,其中,應用較為廣泛的方法有:馬爾可夫鏈(Markov chain,MC)模型、軌跡頻繁模式挖掘和循環神經網絡(recurrent neural network,RNN)等。馬爾可夫模型通過計算用戶位置之間的轉換概率建立轉移矩陣,以推測下一步最可能到達的位置[5-6]。軌跡模式挖掘通過挖掘頻繁模式找出典型運動模式[7]。循環神經網絡通過隱藏層神經元的連接性處理序列數據以學習運動模型[8]。
雖然上述方法已經在一些應用場景中得到了很好的效果,但它們針對的都是短時間軌跡序列,沒有考慮到過長的歷史信息會帶來的維數災難,不能解決長序列軌跡的位置預測問題。用戶的軌跡數據會隨時間的增長而變多,GPS的采樣周期短,收集到的數據多且連續,在學習預測模型前,應對位置序列進行預處理,通過網格化和分布式表示的方法,降低位置向量的維數。并且,傳統的方法如軌跡頻繁模式挖掘,普遍都是先將原始軌跡按密度聚類,將軌跡線段劃分到不同的類簇中,以聚類序列表示軌跡。這雖然能在保證劃分意義的前提下縮短序列長度,但基于密度的聚類方法不僅時間復雜度大,而且會忽略聚類區域之外的離散軌跡。
軌跡數據是有時間順序的時空數據,而神經網絡被證明在處理時序數據的數據挖掘和預測方面效果最佳。但歷史信息具有時效性,考慮失效的歷史信息會產生梯度消失或梯度爆炸問題[9],而忽略有效的歷史信息會導致模型精確度下降。長短期記憶網絡(long short-term memory,LSTM)[10]被證明是這一問題很好的解決方法。但LSTM也要求輸入低維度的向量,否則循環神經網絡隱藏層和輸入層的神經元之間的全連接屬性會導致嚴重的維數災難,增大開銷,降低模型的學習效率。
針對上述問題,為了對移動對象的時空數據進行更精確的建模從而進一步預測其未來位置,本文提出了位置分布式表示模型(location distributed representation model,LDRM),將難以處理的高維位置onehot向量轉化為包含移動對象運動模式的低維位置嵌入向量。在LDRM模型基礎上,與基于LSTM的位置預測算法結合為LDRM-LSTM移動位置預測算法。該算法在考慮移動對象行為具有相似性和時效性的基礎上,對歷史軌跡位置向量進行降維,從而有效提高了預測模型的效率和精確度。
本文的主要貢獻如下:
(1)提出了一種位置分布式表示模型LDRM,將難以處理的高維位置one-hot向量轉化為包含移動對象運動模式的低維位置嵌入向量。在不忽略移動對象運動規律的同時,有效降低了位置序列數據的維數,提高了訓練模型的效率。
(2)考慮軌跡數據的時效性和移動對象行為的相似性,采用LSTM模型作為訓練模型,學習一個全局的位置預測模型,提高了長序列軌跡數據的預測精度。
(3)實驗所用的GPS軌跡數據為微軟亞洲研究院提供的真實數據集Geolife,并使用一系列量化指標來評估預測得到的結果。實驗結果證明,與現有的算法相比,提出的LDRM-LSTM算法的預測精度得到了明顯提升。
2 相關工作
隨著基于位置的服務的發展,移動對象位置預測的工作逐漸成為研究的熱點,國內外研究者針對移動對象位置數據挖掘與預測已經展開了相關研究。在移動對象位置預測中,通常的方法是通過移動對象歷史數據,預測移動對象的位置。
Koren等人[11]提出了基于矩陣因子分解的方法,通過分解包含地理位置信息的用戶行為矩陣判斷用戶最可能訪問的位置。Xiong等人[12]改進了這一算法,通過張量分解(tensor factorization,TF)的方式,同時考慮歷史軌跡信息中的地理位置信息和時間信息。上述算法都基于對移動對象歷史訪問記錄的挖掘,沒有考慮當前移動對象位置及軌跡,得到的預測精度不高。
Monreale等人[13]提出了WhereNext方法,從歷史軌跡數據中提取對象的軌跡模式,借此預測用戶頻繁訪問的位置,同時利用T-pattern tree查詢最佳匹配軌跡。Ying等人[14]提出了基于地理和軌跡的語義特征預測移動對象下一時刻位置信息的方法,該方法通過挖掘同類用戶的常見行為特性來預測其未來位置。Morzy[15]采用改進的Apriori算法來生成關聯規則,并在后來的研究中利用改進的PrefixSpan算法[16]通過移動軌跡序列頻繁項集來預測移動對象的位置[7]。然而,頻繁軌跡挖掘算法效率低下,數據每次更新都要重新挖掘頻繁軌跡,使預測效率降低。
馬爾可夫鏈(MC)模型利用移動對象的歷史軌跡預測位置,考慮軌跡的順序特征,使用馬爾可夫鏈描述移動對象在位置之間的轉移概率,Rendle等人[17]提出一種用因式分解轉移概率矩陣的方法擴展了MC模型,在時空數據的位置預測上取得了很好的效果。Mathew等人[18]使用隱馬爾可夫模型(hidden Markov model,HMM)計算移動軌跡序列中的隱狀態來計算移動對象概率最高的下一個位置。但多階MC模型尤其是高階MC模型,當數據增加時狀態會呈爆炸式增長,轉移概率矩陣規模的膨脹增加了預測的復雜度。
近年來,神經網絡在數據挖掘與預測中的應用逐漸廣泛。在神經網絡模型中,RNN最適用于時序數據的預測。Liu等人[8]提出了ST-RNN(spatial temporal-RNN)算法,用移動對象歷史時空數據訓練RNN網絡,預測用戶在某個時間點的位置。Al-Molegi等人[19]改進了該算法,其提出的STF-RNN(spatial temporal featured-RNN)算法獲得了更好的預測準確率。
然而傳統的RNN無法處理大量歷史數據的軌跡序列,過多的歷史數據會導致參數訓練時的梯度消失、梯度爆炸和歷史信息損失等問題,改進的LSTM則可以解決這些問題。LSTM在很多領域已經獲得了一定的成果,如機器翻譯[20]、信息檢索[21]和圖像處理[22]等方面。Sutskever等人[20]提出了基于LSTM的神經網絡語言模型,并運用于自然語言處理方面,實現序列到序列(sequence to sequence)框架用于機器翻譯。Malhotra等人[23]將LSTM模型運用于時序數據異常檢測領域,解決了無監督環境下采集到非傳感器數據從而導致時間序列不可預測的問題,在對不可預測的時間序列和長時間序列的異常檢測中,取得了很好的效果。
Wu等人[24]提出了一種基于LSTM的時空語義算法(spatial-temporal-semantic neural network algorithm,STS-LSTM)對移動對象進行位置預測。該算法提出一種特征提取的方法將路網軌跡轉化為離散位置點并用LSTM模型進行位置預測,較傳統算法精確度有了明顯的提升,但該算法并沒有考慮到長時間序列的數據壓縮問題。
針對以上不足,本文提出一種基于LSTM的移動對象位置預測方法,利用LSTM模型解決長序列的位置預測問題,在學習預測模型前,先對歷史數據進行了預處理,使軌跡的時空數據轉化為具有上下文信息且維數較低的神經網絡輸入向量。擺脫了傳統位置預測算法的弊端,有效提高了預測精度和效率。
3 算法描述
LDRM-LSTM算法整體框架如圖1所示,算法由三部分組成,即用于將軌跡數據轉化為位置序列的預處理部分,對高維位置向量進行降維處理的位置分布式表示模型LDRM部分和基于LSTM的根據歷史位置序列學習運動模式的預測模型部分。下面將用3節對這三部分進行詳細的說明。
本章所用的軌跡數據的符號表示及說明如表1所示。

Table 1 Description of symbol definition表1 符號定義說明
3.1 軌跡數據預處理
移動對象軌跡數據通常由GPS采集。考慮軌跡數據的結構,經過采樣生成的一條軌跡可以表示為一系列的位置點的集合。由于采集的點的序列,在時間空間上相對緊密,難以從中挖掘出其運動的模式。如圖2中的兩條軌跡P(實線軌跡)與P′(虛線軌跡),很難從中發現明顯的普遍特征,那么對于大量的如此表現形式的軌跡,就更難挖掘出其中的模式進行預測。因此在移動對象位置預測之前,必須對原始軌跡數據進行預處理。
網格化是研究移動對象軌跡常用的方式,其核心思想是將移動對象所在平面劃分為網格,將精確但冗余的經緯度信息轉化為抽象的網格信息,以便對移動對象軌跡進行預測。如圖2右圖所示,通過網格將復雜的軌跡P與P′轉化為相同的軌跡L1→L2→L4→L3,更能抽象地表示移動對象的運動過程。
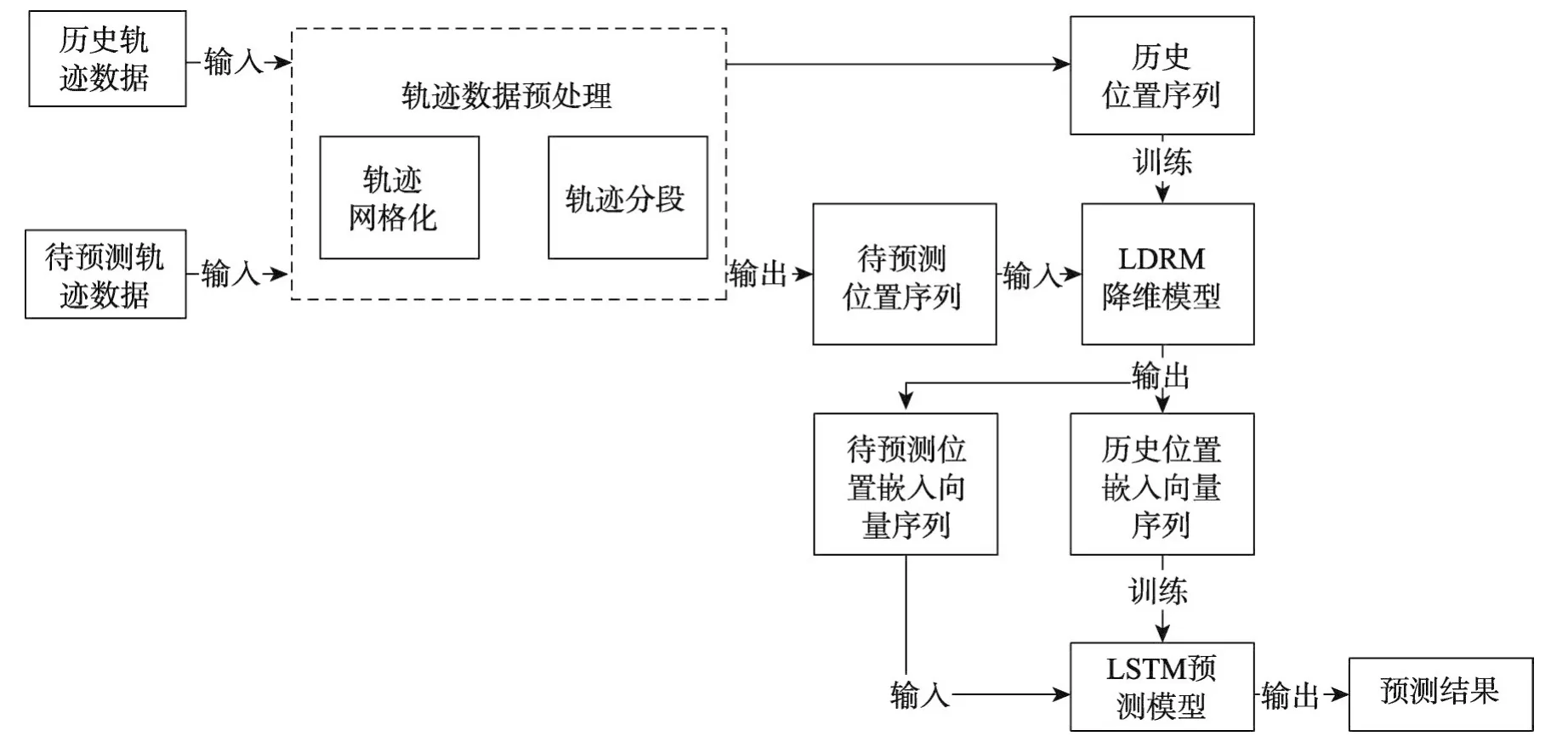
Fig.1 Overall framework of LDRM-LSTM圖1 LDRM-LSTM算法整體框架

Fig.2 Trajectory data gridding圖2 軌跡數據網格化
采用Geohash編碼對軌跡進行網格化。Geohash由Niemeyer提出,最初用于geohash.org服務中,目的是為地球上每一個位置提供一條短URL作為唯一標識[25]。Geohash編碼的基本原理是將地球視為二維平面,把該平面沿經度和維度的方向遞歸二分為更小的子平面,使平面被網格化為子平面的集合,每個子平面在一定經緯度范圍內擁有相同的Geohash編碼。根據Geohash編碼方案,其編碼具有唯一性,即Geohash的每個單元網格在地球表面均有唯一空間區域與之對應,這種特性便于對軌跡數據進行無歧義的網格序列化。
使用Geohash編碼將軌跡所在地區分為n個網格,第i個網格編碼為Li(1≤i≤n),每個網格代表一個位置。由于GPS數據采集的時候可能有誤差,有些網格只有極少數軌跡點存在其中,需要將其作為離群點剔除。因此,設計算軌跡經過編號為Li的網格的軌跡點個數為,若大于網格最小有效軌跡點數δ,則將該網格編碼Li與來到該網格的時刻ti構成的二元組加入帶時間屬性的位置序列T,如式(1)所示。

根據式(1),將原始軌跡數據轉化為帶時間屬性的位置序列T。然而,GPS軌跡采集過程通常是連續很長一段時間,導致T過長,并且其中有些二元組之間的時間間隔過大,對位置預測有較大影響。因此,需要通過時間閾值將位置序列T分段。設第k段帶時間屬性的位置序列Tk={<Lk,tk>,<Lk+1,tk+1>,…,<Lk+l,tk+l>},其中存在時間點ti,有ti+1-ti>γ,則將位置序列Tk分為Ta和Tb兩個子序列,用時間點ti分割原序列,分割后的兩個子序列Ta={<Lk,tk>,<Lk+1,tk+1>,…,<Li,ti>},Tb={<Li+1,ti+1>,<Li+2,ti+2>,…,<Lk+l,tk+l>},其中,k<i<l。
通過上述算法,將移動對象原始軌跡數據轉化為h個位置序列,構成位置序列集合H={T1,T2,…,Th}。同時,構建n個移動對象位置組成的集合S={L1,L2,…,Ln}。移動對象位置預測問題如定義1所示。
定義1(移動對象位置預測問題)設h個歷史位置序列組成的歷史軌跡集合H={T1,T2,…,Th},當前軌跡為T′={<Li,ti>},0≤i≤t,預測移動對象在t+1所在的位置Lt+1。
3.2 位置分布式表示模型LDRM
將移動對象軌跡數據轉化為位置序列后,由于位置信息是離散的Geohash編碼,無法直接進行訓練,需要將編碼轉化為向量。通用的離散值轉為向量的方法是one-hot編碼,即對于n個位置的集合S={L1,L2,…,Ln},對于每一個位置Li,構建一個零向量,將其第i維賦值為“1”,即只有這一位有效,其他位均為“0”。如位置L1的可表示為:(1,0,0,0,…),這個稀疏的向量即為該位置的one-hot編碼。這種編碼將離散的位置編碼轉化為向量,解決了模型無法處理離散數據的問題。但是這種編碼也存在著問題:(1)在數據量大、不同位置多的情況下,容易受維數災難的困擾;(2)不能很好地描述位置之間的關系,也不能體現出移動對象的運動模式。
針對one-hot存在的問題,采取分布式表示(distributed representation)的方法,提出了位置分布式表示模型LDRM,將包含位置信息的one-hot編碼通過神經網絡轉化為低維度的含有位置上下文信息的位置嵌入向量(location embedding vector,LEV),避免了由于位置過多帶來的維數災難問題。
移動對象的運動往往存在某種隱藏的規律,即某些移動對象序列會以較高概率出現。設一個長度為N的位置序列出現概率為P=(L1,L2,…,LN),在理想狀態下,即移動對象出現在每個位置的概率相互獨立時,計算公式如式(2)所示。
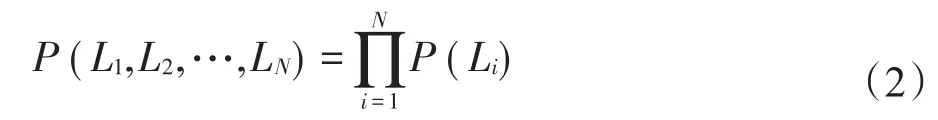
但這樣的假設太過理想化,因為移動對象當前位置與其之前位置是相關的。假設在一段位置序列中,移動對象的位置和前t個位置有關,如式(3)所示。
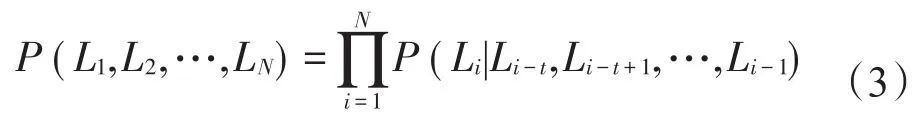
LDRM模型在對位置one-hot向量降維的同時,從軌跡未知序列中挖掘位置之間的關系,使得P(Li|Li-t,Li-t+1,…,Li-1)最大化,從而將序列中的運動模式隱含到位置嵌入向量中。
設移動對象位置序列共有n個位置,則每個位置構成一個n維的one-hot向量l,每個one-hot向量對應一個m維的位置嵌入向量。LDRM模型神經網絡結構如圖3所示。
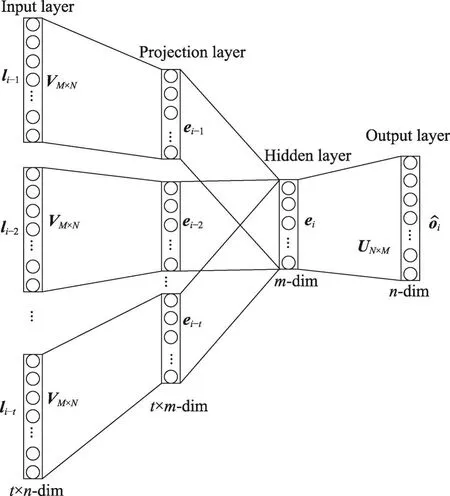
Fig.3 Structure of LDRM neural network圖3 LDRM神經網絡結構
設當前位置編號為i,對應的one-hot向量為li,和當前位置相關的位置為{li-t,li-t+1,…,li-1}。假設當前存在輸入矩陣V∈Rm×n,根據式(4)可計算投影層每個位置嵌入向量{ei-t,ei-t+1,…,ei-1}。

在移動對象位置序列中,不同位置的重要程度不同,比如熱門景點、商場、學校、醫院等對下一個位置的影響要明顯高于一般位置。故給每一個位置根據其在所有軌跡中出現的次數賦予一個權值wi,計算方式如式(5)所示。

將前i個位置的嵌入向量通過式(6)計算出當前位置的嵌入向量ei。

設輸出矩陣U∈Rn×m,當前位置的嵌入向量經過輸出矩陣的變換成為n維輸出向量。輸出層將嵌入向量轉化為輸出向量的計算方式如式(7)所示。

為n維輸出向量,理想狀態下的輸出向量oi應該和當前位置的one-hot向量相等,即oi=li。在這種情況下,該模型的損失函數交叉熵(cross entropy)的計算方式如式(8)所示。
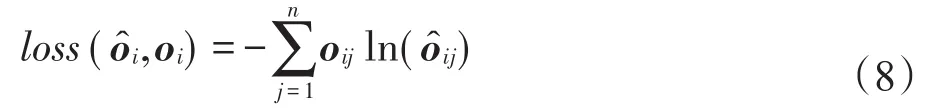
由于模型輸出為離散的one-hot向量,若直接使用交叉熵作為目標函數,會造成模型泛化性嚴重下降。因此,定義該模型的目標函數如式(9)所示。其中,ui為輸出矩陣U的第i行,表示li的輸出向量。
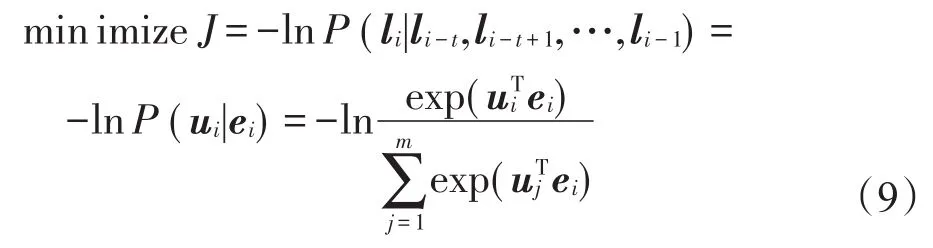
使用梯度下降的方法,計算ui和ei,即可得到矩陣V和U。通過公式e=Vl,即可計算每個one-hot向量對應的位置嵌入向量。位置嵌入向量的總體計算流程如算法1所示。
算法1LDRM算法
輸入:每個位置one-hot向量集合Sonehot,軌跡序列集合Strajectory,相關位置數t。
輸出:每個位置對應的位置嵌入向量構成的集合SLEV。
1.Trainingset=[];//構建訓練數據集及其標簽,初始值為空
2.For eachliinSonehot//遍歷one-hot向量集合
3.For eachTjinStrajectory//遍歷軌跡序列集合
4.IfliinTjand the order ofliisk//如果當前位置在當前軌跡序列中出現,且是當前軌跡序列中第k個位置
5.Thendata={li-t,li-t+1,…,li-1},label=li//當前位置的前t個位置為訓練數據,當前位置為標簽
6.add{data,label}intoTrainingset//存儲訓練數據與標簽
7.Whileepoch<epochround//當訓練未完成時
8.For each{data,lable}inTrainingset//遍歷構建的數據集
9.Input{data,lable}into Nerual Network//將數據與標簽放入神經網絡
10.Calculate functionJ//計算目標函數
11.Backpropagation parameterUandV//反向傳播調整參數U和V
12.For eachliinSonehot
13.ei=U?li//對于每一個one-hot向量,計算對應的位置嵌入向量
14.AddeitoSLEV//存儲計算結果
算法1計算了每個位置one-hot向量構成的位置嵌入向量。計算過程分為三個主要部分:首先通過遍歷位置one-hot向量集合和軌跡序列集合構建訓練集;然后使用該訓練集訓練LDRM神經網絡參數U和V;最后通過該參數計算每個位置的位置嵌入向量。
3.3 基于LSTM的位置預測算法
LSTM模型是一種RNN的變型,由記憶單元(memory cell)和多個調節門(gate)組成。LSTM使用記憶單元的狀態(state)來保存歷史信息,使用輸入門(input gate)、輸出門(output gate)和遺忘門(forget gate)來控制記憶單元。利用調節門來選擇信息,可表示為y(x)=σ(Wx+b),其中W表示權重矩陣,b表示偏移向量。由于傳統的RNN展開后相當于多層的前饋神經網絡,層數對應于歷史數據的數量,過多的歷史數據會導致參數訓練時的梯度消失、梯度爆炸和歷史信息損失等問題,在處理大量歷史數據的預測問題上,LSTM被證明比RNN具有更好的表現。
LSTM的單元結構如圖4所示,設xt、ht為t時刻的輸入和輸出數據,i、f和o分別為輸入層、遺忘層和輸出層,Ct為t時刻記憶單元的狀態值。LSTM單元的更新可分為如下幾個步驟。
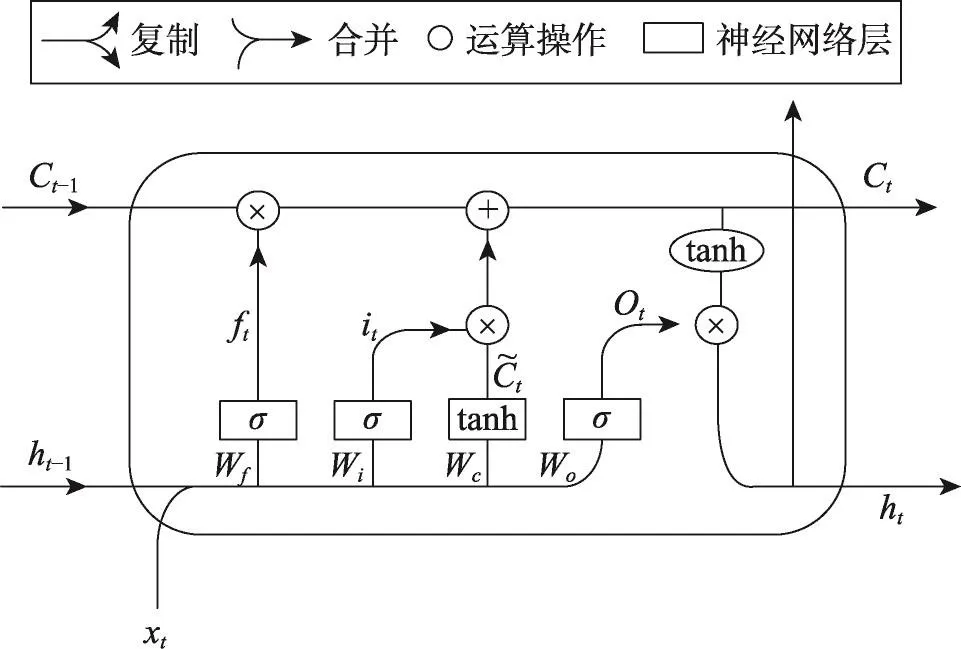
Fig.4 Structure of LSTM network圖4 LSTM單元結構圖
(1)決定從上一狀態中丟棄什么信息。遺忘門是用于控制歷史信息對當前記憶單元狀態值的影響的,因此通過遺忘門來計算ft,如式(10)所示。其中Wf表示遺忘門的權重矩陣,bf表示遺忘門的偏移向量。σ是logistic sigmoid激活函數,取值在(0,1)之間,1表示“全部保留”,0表示“全部丟棄”。

(2)決定什么信息被存入當前狀態中。輸入門是用于控制當前輸入對記憶單元狀態值的影響的,因此通過輸入門來計算it,如式(11)所示。按照傳統的RNN公式計算當前時刻的候選記憶單元值C?t,其中函數tanh的取值范圍在(-1,1)之間。
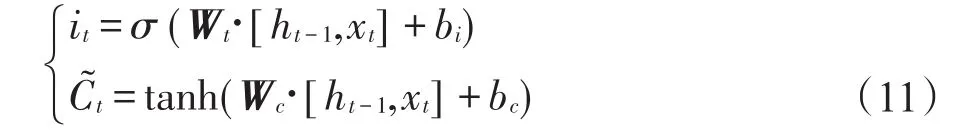
(3)決定好丟棄和更新什么信息后,執行記憶單元的更新,計算當前時刻記憶單元的狀態值Ct,如式(12)所示,⊙是點乘運算。

(4)確定輸出值。輸出門用于控制記憶單元狀態值的輸出,用sigmoid函數計算決定輸出的部分,如式(13)所示。將通過tanh函數處理的記憶單元狀態與結果ot相乘,得到LSTM單元在t時刻的輸出ht。
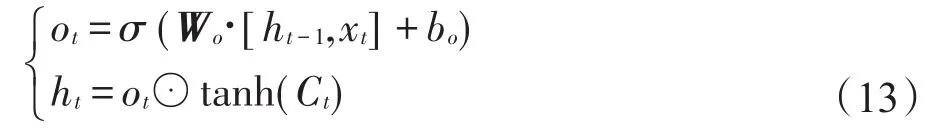
經過LSTM根據訓練數據調整神經元之間的權重的學習過程[26],得到一個全局的位置預測模型。通過上述門控機制,LSTM解決了RNN處理長序列容易發生的梯度消失、梯度爆炸和歷史信息損失等問題,在移動對象位置預測方面有更好的表現。
使用LDRM模型對位置序列進行降維后,難以處理的高維one-hot向量被轉化為低維度的含上下文信息的位置嵌入向量,從而使得基于LSTM的位置預測算法可以更好地處理移動對象位置預測問題。
設降維后的位置嵌入向量集合為SLEV={e1,e2,…,en},則移動對象位置序列可以轉化為由嵌入向量組成的序列。但放入LSTM模型中的每個序列的長度必須相同,因此采取滑動窗口的方式,將所有的軌跡轉化為可訓練的固定長度的輸入與輸出樣本集,如圖5所示。
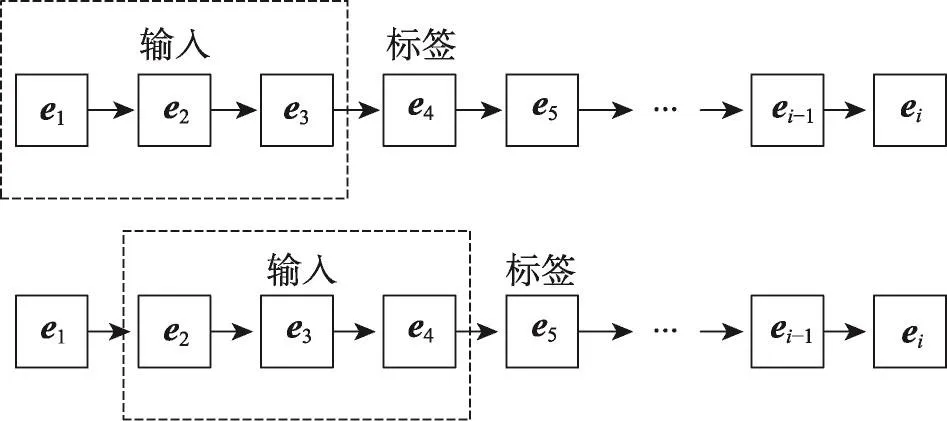
Fig.5 Generate sample set using sliding window method圖5 滑動窗口法生成樣本集
將經過LDRM模型降維的歷史位置嵌入向量作為LSTM模型的輸入,訓練出針對移動對象位置預測問題的LSTM模型。將待預測位置嵌入向量序列輸入模型得到輸出向量eoutput,將eoutput與E中所有位置嵌入向量計算歐式距離,與eoutput距離最小的位置嵌入向量即為預測結果eresult。模型的位置預測結果即為eresult對應的位置one-hot向量lresult。
算法2LSTM位置預測算法
輸入:位置嵌入向量集合SLEV,軌跡序列集合Strajectory,待預測位置序列Ttest。
輸出:預測結果的one-hot向量lresult。
1.Trainingset=[];//構建訓練數據集及其標簽,初始值為空
2.For eachTiinStrajectory
3.For slide windowTs={la,la+1,…,lb}inTi//通過滑動窗口方式構建子序列
4.Extractdata={ea,ea+1,…,eb-1l},abel=ebfromTs//將子序列中one-hot向量轉化為位置嵌入向量,并構建訓練數據與標簽
5.Add{data,label}toTrainingset//保存訓練數據與標簽
6.Whileepoch<epochround//當訓練未完成時
7.For each{data,lable}inTrainingset
8.Input{data,lable}into LSTM neural network//將訓練數據與標簽輸入LSTM網絡
9.Calculate bias function of LSTM//計算誤差函數
10.Backpropagation parameters//反向傳播調整網絡參數
11.InputTtestinto LSTM Network get result embedding vectoreoutput//將測試數據輸入網絡得到輸出的位置嵌入 向量
12.For eacheiinSLEV
13.Finderesult=ei,for which distance ofeiandeoutputis minimum//在位置嵌入向量集中尋找距離最近的向量
14.Output correspondinglresultoferesult//將距離最近的向量轉化為one-hot向量并輸出
LSTM位置預測算法的流程如算法2所示。首先通過滑動窗口將軌跡數據分割并轉化為訓練集。然后通過訓練集訓練LSTM神經網絡,最后將待預測軌跡輸入LSTM神經網絡中,得到輸出的位置嵌入向量,并篩選與該向量距離最近的位置嵌入向量,該向量對應的位置即為預測的位置。
由算法1與算法2可見,LDRM-LSTM算法采用了離線訓練在線預測流程結構,即在預測前將模型參數訓練完成,在預測時僅需要計算預測結果即可。這種方式的優點為將耗時操作在預測前完成,預測時的時間復雜度極低。本文中,LDRM降維模型和LSTM預測模型均由歷史軌跡數據離線訓練得出,在進行軌跡數據預測時只需將待預測軌跡數據進行預處理后輸入模型即可得到預測結果,具有很強的實用性。
4 實驗與分析
4.1 實驗數據與環境
為了驗證移動對象位置預測算法的預測準確性,使用微軟亞洲研究院的Geolife project數據進行測試。該數據集包括182個用戶5年間(從2007年4月到2012年8月)的運動軌跡數據。數據集覆蓋中國、美國和歐洲的不同城市,大部分數據是在北京采集的。軌跡數據數量為18 670條數據,覆蓋長達50 176 h的時間和1 292 951 km的距離。軌跡是通過帶GPS功能的手機采集而來,每隔1到5 s采集一次位置數據。軌跡信息中包含經緯度、時間等信息。
實驗操作系統為ubuntu14.04(64 bit),CPU為Intel Core i5-3470,內存為16 GB,顯卡為NVIDIAGTX970,實驗代碼用python編程語言實現。
4.2 預測評價標準
定義2絕對預測精度(absolute precision,AP)即預測結果和真實結果的差距。設共有K個測試樣本,第i個樣本的預測結果為pli,真實結果為li。絕對預測精度分數ScoreAP如式(14)所示。

由于絕對預測精度的要求較為苛刻,無法對算法在預測不完全精確的情況下的預測結果優劣進行比較。因此實驗同時使用相對預測精度來進行預測精度度量。
定義3相對預測精度(relative precision,RP)即在預測不完全精確的情況下,對預測偏離度進行量化度量的一種精度,計算方式如式(15)所示[27]。

由于每個位置是大小相等的網格,因此可以將每個網格視為坐標軸上1×1的單元格。故式(15)中的距離函數dist采用曼哈頓距離計算兩個網格之間的距離。在預測結果非絕對精確時,設定相對預測精度可以通過其與真實位置的距離偏差來選擇相對精確的預測點,ScoreAP越低,表示預測精度越高。
4.3 軌跡數據預處理與樣本集生成
從原始數據中,提取出在北京的13 101條軌跡,使用6位Geohash編碼對軌跡進行網格化(約600 m×600 m網格),共生成14 777個不同的位置。將經緯度軌跡轉化為位置序列并分段,設分段時間閾值為30 min,位置包含最小有效軌跡點數為10。
通過上述方式,將原始軌跡轉化為21 740條位置序列。對提取出的位置序列,使用滑動窗口的方式生成樣本集。設滑動窗口長度len=8,滑動步長step=3,除去長度小于len的位置序列后,得到69 537個樣本,隨機取其中的5 000個樣本作為測試集,其余數據作為訓練集。軌跡預處理的參數選擇總結如表2所示。
4.4 LDRM模型性能分析

Table 2 Parameters of trajectory preprocess表2 軌跡預處理參數
通過預處理與樣本集生成,將原始Geolife數據轉化為軌跡位置序列訓練集與測試集。在進行預測之前,需要使用軌跡位置序列訓練集對LDRM位置降維模型進行訓練。由于數據集中存在14 777個位置,即輸入的位置one-hot向量的維度n=14 777。設LDRM降維得到的位置嵌入向量的維度為m。位置嵌入向量維度m對預測結果有較大影響,過大的位置嵌入向量維度仍然會導致一定程度的維數災難問題,過小的位置嵌入向量維度會造成大量的信息在降維中損失,都會導致預測維度下降。因此,將m的取值范圍預設為50到500,步長為50。通過對訓練集進行交叉驗證計算絕對精度與相對精度,計算m的取值對LDRM-LSTM位置預測算法的效果的影響,實驗結果如圖6和圖7所示。
由圖6和圖7可見,位置嵌入向量在100~150維之間時,預測結果與真實結果的絕對差距最小,相對偏離度最小,即絕對精度和相對精度均達到最佳,預測效果最好。由于絕對精度與相對精度相比更為重要,因此取絕對精度最高的100維作為降維后位置嵌入向量的維度。為了方便觀察嵌入向量空間分布,將位置嵌入向量經過主成分分析(principal component analysis,PCA)降維到二維后,部分位置嵌入向量在二維向量空間中的分布如圖8所示。每個位置點上的標簽為各自的Geohash編碼,圖中越接近的兩個空間向量,代表其在運動軌跡中越相關。
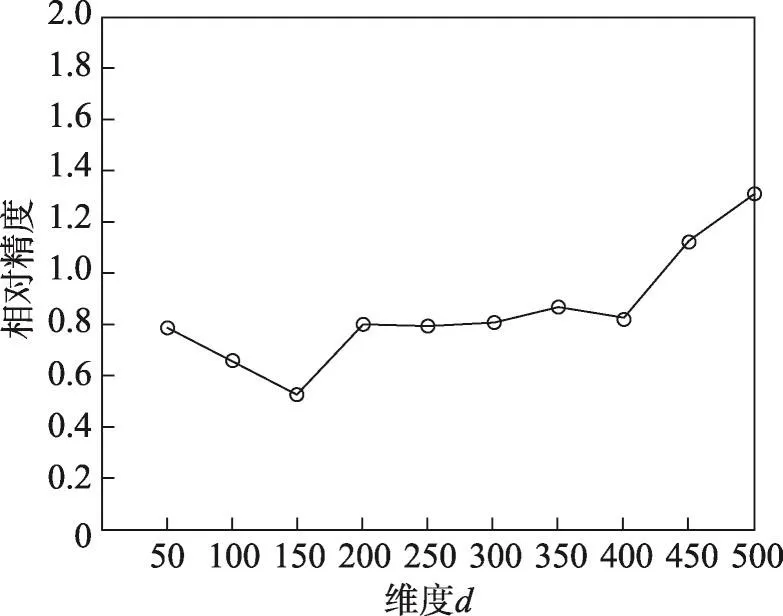
Fig.7 Relative precision of LDRM-LSTM in different dimensions圖7 不同維度下LDRM-LSTM預測的相對精度

Fig.8 Graph of location embedding representation圖8 位置嵌入向量空間分布示意圖
4.5 LSTM位置預測算法結果與分析
在確定了最優的嵌入向量維度并在將訓練集與測試集中位置序列均轉化為位置嵌入向量序列后,使用訓練集中降維后的位置嵌入向量序列對LSTM神經網絡進行訓練,再使用訓練后的模型對測試集中的待預測的位置嵌入向量序列進行位置預測。將預測結果與真實值相對照,計算絕對精度與相對精度,并與HMM、MC、XGBoost(extreme gradient boosting)[28]、LSTM以及STS-LSTM等現有算法在同一樣本集上進行對比。這些算法均為離線訓練在線預測算法,離線訓練時間和參數相關,在線預測時間復雜度幾乎一致。實驗結果如表3所示。

Table 3 Results of location prediction表3 位置預測結果
由表3可見,LDRM-LSTM算法的絕對預測精度和相對預測精度遠遠高于未采用降維算法的LSTM模型,證明LDRM降維模型較好地解決了維度災難問題。同時,LDRM-LSTM預測絕對精度和相對精度均高于所列出的經典位置預測算法,說明在解決長序列位置預測的問題上,LDRM-LSTM算法可以克服現有算法存在的弊端,得到較好的預測結果。
5 結束語
移動對象位置預測與運動模式挖掘一直是研究的熱點,可為各類基于位置的服務和應用提供重要支持,如智能交通系統、智能導航系統、路線規劃等,具有很高的實用性和現實意義。傳統的基于Markov概率模型的位置預測算法和基于神經網絡的位置預測算法無法處理位置過多帶來的維數災難問題。提出了LDRM模型,通過神經網絡挖掘移動對象軌跡數據中的隱含規律,將原始的高維one-hot向量轉化為低維度的位置嵌入向量,再通過基于LSTM的移動對象位置預測算法進行位置預測。實驗證明本文提出的LDRM-LSTM算法預測準確率高于經典的MC、HMM、RNN及XGBoost等算法。同時,算法采用離線訓練在線預測的流程結構,使用歷史數據訓練的模型進行位置預測,在實際應用中有較高的價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
