基于SVM的學習興趣度分析方法的研究
2019-01-09 02:01:44常佳薇
儀器儀表用戶 2019年2期
張 童,常佳薇
(北方工業大學 電子信息工程學院,北京 100144)
0 引言
在計算機視覺和機器學習領域中,自動識別人類自然交流時的表情已經是可以實現的一件事。在之前的許多探究性研究中都在試圖去分類視頻和圖像中所謂的“基礎表情”(anger, disgust, fear, happiness, sadness and surprise),因為基礎情緒表情被認為是普遍表達的,它們的動態在日常生活中也是常見的,這就使得基礎情緒成為開始訓練表情識別系統的自然選擇。
但是不同的誘發刺激源,人臉常能表現出相同或相似的表情。在現實世界里,人們交談時觀察到對方臉部的表情變化,或許可以理解這種表情變化意味著什么,但在利用機器領域工具去分辨這方面還面臨著不少的挑戰。
在課堂的老師與學生的互動中,可以觀察到很多同學產生了微笑的表情,但是這個微笑表情是否與課堂內容相關,有時候老師用肉眼根據經驗就可以直接判斷。在本實驗研究中,本課題希望建立一套實驗,讓機器也能更好地理解學生在上課過程中發出的微笑背后,到底是一個怎樣的心理狀態。
論文的剩余部分如下:第1部分描述了前人相關的工作;第2部分描述了所做的數據實驗和實驗對象介紹;第3節描述了數據的處理、特征的選取以及對性能分析進行了一般性的討論,并對問題進行了更深入的分析。第4節、第5節研究了“認真學習的笑”和“不認真學習的笑”的特征向量,并提出了一種算法來區分。
1 相關研究
基礎情緒的研究以及分類已經很成熟了,在研究基礎情緒的過程中,也極大地促進了情緒識別分類等技術和工具的產生。這些用于將FACS與基礎情緒關聯的技術和工具可以與表演的數據或者其他有限制的數據有很好的效果。但是對于自然數據,這些技術可能無法產生令人滿意的效果。在前期的數據采集上,可以采用基礎情緒研究所衍生的技術工具。谷歌、百度、曠世face++、騰訊等知名的公司就已經有了開源的成熟的API可供調用,這對前期的數據采集提供了便利。

圖1 現場課堂錄制狀態Fig.1 Classroom recording status
Mohammad(Ehsan)Hoque的研究在分類Frustrated和Delighted的笑容時,也是基于自然引發的實驗數據進行的[1]。Mohammad和他的團隊的工作是創造了兩個實驗情景引出兩種情感狀態,在區分這同一表情下的表現出的兩種情感狀態過程中,論文中提出的算法實現了總體準確率為92%,比人類略高。此研究方法給了人們很大的參考借鑒意義,但是對于Mohammad在處理笑容強度的維度上,該項目做出了改變,提出了自己的創新性方法。
2 實驗
最主要的挑戰之一就是數據集的收集,這也是本實驗最耗時,最昂貴的部分。以往數據集的收集過程都是參與者表演、重現和互動的,只有很少的數據集是自發的,而且也沒有一個數據集是專門針對上課場景的。
因為本研究是區分課堂上笑容表情的內在狀態,所使用的數據集也必須是來自課堂教學環境下學生的人臉表情數據資料,所以實驗的目的也就是要錄取到學生上課和老師交流互動時的臉部表情變化。
在實驗視頻錄制方面,該項目采用的是海康威視的DS-2CC597P超寬動態針孔攝像機,輸出設置為1080p、28fps的實時圖像。
共有20名小學生(3名女生和17名男生)參與了這項研究。他們都不了解研究的假設。這20名參與者都是橫跨三年級到五年級的學生,年齡在9歲~13歲之間。在這20名參與者中,研究成員收集了71段“認真學習”時的笑容表情和“不認真學習”時的笑容表情(收集的每個參與者的片段數都是不固定的)。在數據集中,兩種狀態的笑容過程剪輯的平均時間長度略多于7s左右。
3 分析
在以上收集的這些數據中,面部表情是都存在的。下面是用于分類的面部特征的描述。
3.1 人臉識別數據的預處理
在收集到課題所需要的面部表情數據片段后,由于教室環境的復雜性,老師和同學的交流互動過程中都會造成一個單獨攝像頭的視頻幀畫面不止是一個人臉的情況出現,這就需要對視頻幀圖像進行預處理。

圖2 學生課堂發生的一個微笑片段幀Fig.2 The frame of a smile clip in classroom
在人臉檢測及提取技術上,本課題采用的是于仕琪老師的人臉識別技術;該API既可以檢測人臉,也可以提取人臉的關鍵點坐標。
在收集到面部表情數據片段后,要將視頻內容進行一次預處理。將微笑視頻片段分幀并將圖片像素歸一化為400×400的規格。這里,每個視頻片段的時間長短都是不一樣的,這就造成了訓練數據維度不一致的問題,這個問題在本文后面的章節回答。
3.2 人臉特征提取分析
本研究使用于仕琪團隊的面部特征跟蹤器來跟蹤人臉部的68個特征點:20個點圍繞在嘴部,12個點代表眼部(每個眼睛分布6個點,左右對稱),10個點代表眉毛,9個點顯示出鼻子的輪廓,17個點代表臉部輪廓。
本課題計算了原始距離(以像素為單位)、一些部位的角度值以及臉部某些部位的灰度值。這些特征點之間的距離等特征在每一幀中都得測量,當作每一幀微笑圖片的備選特征,所有的特征都在每一幀被追蹤。
3.3 數據集
實驗一共有71個片段。對于每個片段,研究者提取了每一個片段每一幀的特征值,連接他們作為一個向量,這樣每一幀特征值如下:
V={V1,V2,V3,V4.........VN},在這項研究中,由于微笑過程的隨機性,所以每一個微笑片段的幀數是不確定值。
3.4 數據的矯正與優化
本研究在提取微笑視頻片段時,發現很多微笑視頻片段中,有學生微笑時頭部擺動幅度太大,直接檢測不到人臉表情的情形。當頭部擺動幅度小時,在計算每一幀圖片的微笑強度值的過程中,也發現誤差過大的情況,本項目也不希望廢棄這些偏轉角度在一定范圍內的微笑視頻片段,畢竟這也是以后項目中要解決的實際問題。
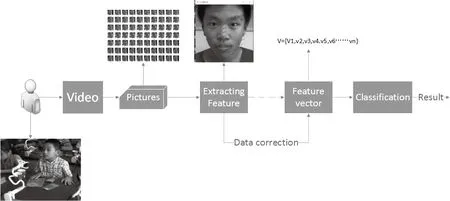
圖3 數據處理系統流程圖Fig.3 Data processing system program flow chart
本實驗中采用龔衛國的基于正弦變換的人臉狀態矯正的方法,通過這種方法,使得側面人臉姿態得到一定角度的姿態矯正,從而變換成接近正面人臉的數據[1]。矯正公式如下:
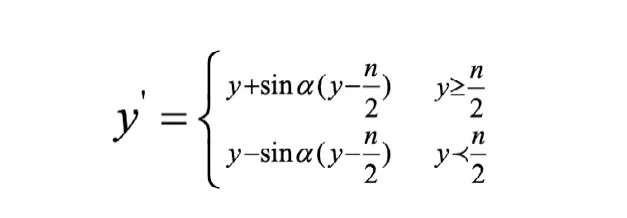
其中,ɑ是偏轉角度,n是人臉圖像的眉心點的坐標y值。
在觀察兩種微笑模式數據集的特征向量后,發現不管是“認真學習時的微笑”還是“不認真學習時的微笑”,特征向量的維度的量級上沒有大的區別,都有不同長短維度的特征向量。
4 最終數據集
在本部分,依舊采用了分析部分中的微笑模式的數據集,開發一種利用時間模式將數據分類為適當類的算法。
該研究運用計算了每一幀微笑圖片的笑容強度值,并作為該幀的特征值[2]。
由于微笑的時間過程的不可控性,所以每一個微笑片段的特征向量是不一樣的。本研究并沒有采用Mohammad(Ehsan)Hoque的微笑序列的維度長度不同的處理方式,即在特征向量后面添加零向量到相同的長度[3]。本項目研究方法是以統計了微笑強度的柱狀圖作為笑容片段的特征向量。將微笑強度值域劃分成10個分值段,統計每一個分值段中的幀數占整個微笑片段幀數的百分比。這樣做的好處一個是降低了數據的維度,另一個是保證了數據的維度的一致性,可用于訓練。這樣,每個微笑片段的特征數據就都變成了一個維度為10的特征向量。
5 分類
該研究方法使用特征向量和標簽進行訓練、驗證和測試。Svm是使用的libSVM實現的[4],以7折交叉驗證。
-s/svm類型選擇為2;-t核函數類型為2,對應的是RBF核函數;-c/cost參數選擇默認為1;-g/gamma參數設置為0.7。
在系統迭代560次后,準確達到81%,并且穩定不變了。
6 結果
這項實驗的結果證明本文方法的工作是有效的。根據訓練分類的結果,對分類成功的每一段微笑視頻數據進行對比后發現,認真學習的笑容強度數值主要集中在0.6~0.85之間,且0.85以后幾乎無分布;不認真學習時的微笑強度數值分布主要集中在0.75~1以上。
同時也比對了錯誤分類的數據,經過圖片對比發現,引起錯誤分類的影響因素主要有兩個原因:一個是有的微笑的過程中伴隨著低頭向下看的動作,該方向上的數據校正沒有解決;另一個是微笑過程中學生的嘴部仍處于說話的狀態。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
發明與創新(2016年38期)2016-08-22 03:02:52
