網(wǎng)絡(luò)謠言敏感詞庫(kù)的構(gòu)建研究
2019-01-06 03:42:46夏松林榮蓉劉勘
知識(shí)管理論壇 2019年5期
夏松 林榮蓉 劉勘

摘要:[目的/意義]網(wǎng)絡(luò)謠言嚴(yán)重影響網(wǎng)絡(luò)正常信息的傳播,對(duì)網(wǎng)絡(luò)謠言進(jìn)行識(shí)別有著重要的現(xiàn)實(shí)意義。筆者構(gòu)建一個(gè)基于微博的網(wǎng)絡(luò)謠言敏感詞庫(kù),以提高網(wǎng)絡(luò)謠言的識(shí)別精度。[方法/過程]針對(duì)微博類社交平臺(tái)短文本的特點(diǎn),首先舍棄傳統(tǒng)的分詞算法,設(shè)計(jì)LBCP抽詞算法,并結(jié)合位置信息和改進(jìn)的TF-IDF權(quán)重來提取敏感詞庫(kù)的種子詞集,然后通過聚類算法將種子詞的近義詞補(bǔ)充到詞庫(kù)中,再將常用的替代詞也加入到詞庫(kù)中,從而得到最終的敏感詞庫(kù)。[結(jié)果/結(jié)論]利用敏感詞特征對(duì)謠言進(jìn)行判斷,在提取微博的內(nèi)容特征、用戶特征、傳播特征以及情感分析特征的基礎(chǔ)上,新增敏感詞特征以后謠言識(shí)別率有明顯提升,得到較好的識(shí)別效果。
關(guān)鍵詞:敏感詞庫(kù);詞向量;特征空間;網(wǎng)絡(luò)謠言
分類號(hào):G202
引用格式:夏松, 林榮蓉, 劉勘. 網(wǎng)絡(luò)謠言敏感詞庫(kù)的構(gòu)建研究: 以新浪微博謠言為例[J/OL]. 知識(shí)管理論壇, 2019, 4(5): 267-275[引用日期]. http://www.kmf.ac.cn/p/185/.
1? 引言
對(duì)網(wǎng)絡(luò)謠言進(jìn)行深入分析有助于及時(shí)判斷真實(shí)或虛假的信息,創(chuàng)造一個(gè)健康的網(wǎng)絡(luò)環(huán)境。目前網(wǎng)絡(luò)謠言的識(shí)別多是從用戶特征、傳播特征的角度進(jìn)行分析,而事實(shí)上,謠言敏感詞是識(shí)別網(wǎng)絡(luò)謠言的一個(gè)重要特征,謠言敏感詞分析有助于提高對(duì)謠言的判別,遏制謠言的蔓延和傳播。
詞庫(kù)是詞匯的集合體,通常包括基本詞庫(kù)以及專業(yè)詞庫(kù),應(yīng)用較廣的專業(yè)詞庫(kù)包括流行詞庫(kù)、專業(yè)本體詞庫(kù)、敏感詞庫(kù),情感詞庫(kù)等。其中,現(xiàn)有的敏感詞庫(kù)主要有反動(dòng)敏感詞庫(kù)、暴恐敏感詞庫(kù)、色情敏感詞庫(kù)、垃圾廣告敏感詞庫(kù)等,被廣泛地應(yīng)用在各類貼吧、論壇以及垃圾郵件檢測(cè)中。
但目前還沒有一個(gè)完備的網(wǎng)絡(luò)謠言敏感詞庫(kù)。本文的謠言敏感詞庫(kù)是應(yīng)用于微博微信這類平臺(tái)的,專門用于謠言的識(shí)別,包括:①失實(shí)的事件,比如某地發(fā)生地震、騷亂等子虛烏有的事件;②夸大事實(shí)真相,比如廠商對(duì)自身產(chǎn)品的過度或虛假宣傳、對(duì)同行產(chǎn)品的詆毀; ③過期信息的使用及詐騙,比如將小女孩走失的消息更改時(shí)間地點(diǎn)或者電話號(hào)碼之后再次發(fā)送,誘導(dǎo)人們撥打有詐騙嫌疑的電話等。這些謠言會(huì)在一定時(shí)期一定程度上引發(fā)了社會(huì)各領(lǐng)域人們的關(guān)注甚至成為焦點(diǎn),如果不及時(shí)處理,其潛在的安全威脅也是不可估量的,而對(duì)于這些謠言涉及的敏感詞,傳統(tǒng)的詞庫(kù)并不能很好地識(shí)別。因此,筆者所構(gòu)建的敏感詞庫(kù)是基于微博謠言而建立的,有較強(qiáng)的實(shí)用價(jià)值,為社交平臺(tái)的謠言識(shí)別提供速度和質(zhì)量的保證。
2? 相關(guān)工作
敏感詞庫(kù)的構(gòu)建主要在于敏感詞匯信息的識(shí)別、敏感詞匯的提取以及擴(kuò)展。其中,敏感信息的提取目前大多通過人工標(biāo)記與挑選或者基于傳統(tǒng)權(quán)重計(jì)算方法[1]去衡量與選擇,再基于參考詞林,去迭代地識(shí)別敏感信息,最后通過相關(guān)算法進(jìn)行敏感詞的擴(kuò)充[2],如劉耕等[3]采用基于廣義的jaccard系數(shù)方法來計(jì)算得到敏感詞的相關(guān)聯(lián)詞匯。
針對(duì)敏感事件和熱點(diǎn)話題的很多研究從敏感詞庫(kù)和熱點(diǎn)詞集入手,取得了較好的效果。詞庫(kù)的構(gòu)建類似于提取文本中的關(guān)鍵字,多以已有的專業(yè)詞匯為基礎(chǔ),采用計(jì)算特征詞權(quán)重的方法。徐琳宏[4]根據(jù)情感分類現(xiàn)狀,確定分類的體系,再綜合各種情感詞匯的資源來構(gòu)造情感詞匯的本體,采用了手工分類以及自動(dòng)獲取結(jié)合的方法獲取詞匯本體;侯麗[5]采用N-Gram及各種過濾規(guī)則結(jié)合的術(shù)語識(shí)別公眾日志數(shù)據(jù),能較好地識(shí)別發(fā)現(xiàn)健康類詞集;C. Quan等[6]從情感類別符號(hào)、情緒強(qiáng)度、情感詞、程度詞、否定詞、連詞、修辭等識(shí)別情感種子詞,從而完成情感詞典的構(gòu)建;F. Peng等[7]利用線性鏈條件隨機(jī)場(chǎng)(CRFs)來進(jìn)行基于字、詞、多詞等形式的領(lǐng)域集成的中文分詞,并通過基于概率的新詞檢測(cè)方法進(jìn)行新詞識(shí)別;周強(qiáng)[8]提出一種多資源融合自動(dòng)構(gòu)建漢語謂詞組合范疇語法(CCG)詞庫(kù)的方法,不同句法語義分布特征,融合形成CCG原型范疇表示,將它們指派給各資源信息完全重合的謂詞形成核心詞庫(kù);K. J. Chen等[9]實(shí)現(xiàn)了通過一個(gè)未知詞提取系統(tǒng)來在線識(shí)別新詞,主要通過統(tǒng)計(jì)信息以及語法語義上下文等信息進(jìn)行新詞識(shí)別;彭云等[10]在商品情感詞的提取過程中,基于商品評(píng)論文本,從詞義理解、句法分析等角度獲得詞語間語義關(guān)系,并將其嵌入到主題模型,提出基于語義關(guān)系約束的主題模型SRC-LDA,從而實(shí)現(xiàn)主題詞的提取。
在構(gòu)造詞庫(kù)時(shí),只是確定了基本詞集往往是不夠的,需要對(duì)其進(jìn)行擴(kuò)充從而得到較為完整的詞庫(kù)。詞匯擴(kuò)展與關(guān)鍵字?jǐn)U展相似,通過詞義近似或語義近似展開。H. Chen等[11]從詞典中提取了近似語義信息的詞作為擴(kuò)展。S. Yu等[12]利用VIPS(VIsion-based Page Segmentation)算法進(jìn)行查詢擴(kuò)展,該算法主要是通過調(diào)用嵌入在Web瀏覽器中的分析器來獲取DOM結(jié)構(gòu)以及視覺相關(guān)信息(所有視覺信息都來自HTML元素和屬性)進(jìn)行查詢擴(kuò)展。J. M. Pnote和W. B. Croft[13]提出了將統(tǒng)計(jì)語言模型和信息檢索相結(jié)合,使用詞頻和文檔頻率按綜合頻率對(duì)詞信息進(jìn)行排序;T. Pedersen和A. Kulkarni[14]通過聚類實(shí)現(xiàn)類似的詞的識(shí)別,然后將它們應(yīng)用到語義擴(kuò)展;P. D. Turney和M. L. Litham[15]通過計(jì)算傾向性基準(zhǔn)詞與目標(biāo)詞匯間相似度的方法識(shí)別詞匯語義傾向性;A. Neviarouskaya等[16]通過同義詞和反義詞的關(guān)系、上下文語義關(guān)系、推導(dǎo)關(guān)系以及與已知的詞匯單位復(fù)合來進(jìn)行情感詞典的擴(kuò)展。
但是上述敏感詞庫(kù)的構(gòu)建方法應(yīng)用于網(wǎng)絡(luò)謠言語料庫(kù)建設(shè)并不完全合適,首先目前謠言并沒有可參考的詞林。而且傳謠變化形式多樣,擴(kuò)展和傳播方式多種多樣。某些詞匯出現(xiàn)在網(wǎng)絡(luò)謠言中的頻率高,同時(shí)存在于正常微博中的頻率也高,不能單獨(dú)用來判定謠言。針對(duì)以上謠言敏感詞的特點(diǎn),筆者設(shè)計(jì)了一個(gè)抽詞算法提取敏感詞并進(jìn)行多級(jí)擴(kuò)充,旨在建立一個(gè)實(shí)用的網(wǎng)絡(luò)謠言敏感詞庫(kù)。
3? 謠言敏感詞庫(kù)設(shè)計(jì)
3.1? 謠言敏感詞庫(kù)構(gòu)建的困難
針對(duì)謠言特征所構(gòu)建的微博謠言敏感詞庫(kù)是一個(gè)專業(yè)性偏向性較強(qiáng)的專業(yè)詞庫(kù),需要有大量的微博謠言語料,同時(shí)在構(gòu)建敏感詞庫(kù)的過程中會(huì)遇到下述困難:
(1)人工干擾。謠言發(fā)布者常常會(huì)采取多種方法來逃避關(guān)鍵詞的匹配過濾。例如在敏感組合詞匯間夾雜了一些無意義的數(shù)字與符號(hào),如“抵@制!共&$產(chǎn)&0黨”。然而這類復(fù)雜多變的形式,卻并不影響人們正常的閱讀,這種情況直接進(jìn)行敏感詞庫(kù)匹配是無法解決的。
(2)準(zhǔn)確性。部分在謠言微博中出現(xiàn)的敏感詞,很多時(shí)候也會(huì)出現(xiàn)在正常微博的文本中致使對(duì)文本敏感得分的判定很容易出現(xiàn)偏差。即大多詞匯只有在特定的語境中才會(huì)顯示出其謠言的特性。
(3)分詞問題。網(wǎng)絡(luò)用語越來越隨意,新詞、未登錄詞等層出不窮以及謠言具有時(shí)效性等使得傳統(tǒng)的分詞工具不適用于此類文本,從而對(duì)謠言識(shí)別帶來影響。
對(duì)于第一類人工干擾的謠言文本,即夾雜符號(hào)的敏感詞的檢測(cè)與識(shí)別,筆者將通過擴(kuò)充停用詞解決,對(duì)待測(cè)文本分詞之后進(jìn)行去停用詞等預(yù)處理方法來解決;對(duì)于第二類準(zhǔn)確性的問題,筆者引入位置權(quán)重以及敏感度權(quán)重來抽取敏感詞,將詞匯在謠言與正常微博中的詞頻比以及位置權(quán)重(詞匯是否處于標(biāo)題中)作為衡量的因素,同時(shí)對(duì)種子詞集進(jìn)行相似詞、關(guān)聯(lián)詞擴(kuò)展;對(duì)于第三類分詞問題,筆者提出基于敏感熱度的L-CPBL抽詞算法摒棄了傳統(tǒng)的分詞工具,基于內(nèi)聚度以及外聚度來提取文本片段,以更加適用于網(wǎng)絡(luò)社交文本。
3.2? 總體設(shè)計(jì)
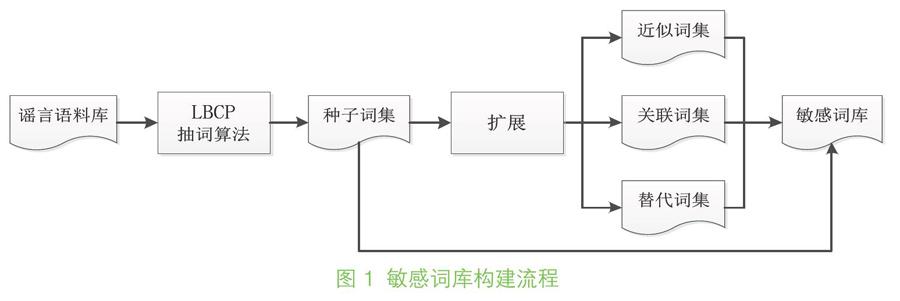
本研究中網(wǎng)絡(luò)謠言敏感詞庫(kù)構(gòu)建的基本思路是:首先收集網(wǎng)絡(luò)謠言語料,然后利用抽詞算法構(gòu)建種子詞集,進(jìn)而對(duì)種子詞集進(jìn)行擴(kuò)展得到完備的謠言敏感詞庫(kù),其總體流程如圖1所示:
圖1? 敏感詞庫(kù)構(gòu)建流程
因?yàn)槟壳暗姆衷~軟件大多具有普適性,用來針對(duì)某一領(lǐng)域發(fā)現(xiàn)特定詞、敏感詞、新詞效果不佳,因此種子詞采集沒有直接分詞,而是設(shè)計(jì)了LBCP(Location- Based Cohesion and Polymerization)算法進(jìn)行抽詞,通過計(jì)算詞的內(nèi)聚度和外聚度,結(jié)合詞權(quán)重和位置權(quán)重得到種子詞集;然后對(duì)種子詞集從近似詞、關(guān)聯(lián)詞和替代詞等方面進(jìn)行擴(kuò)展,最終合并成為謠言敏感詞庫(kù)。
3.3? LBCP抽詞算法
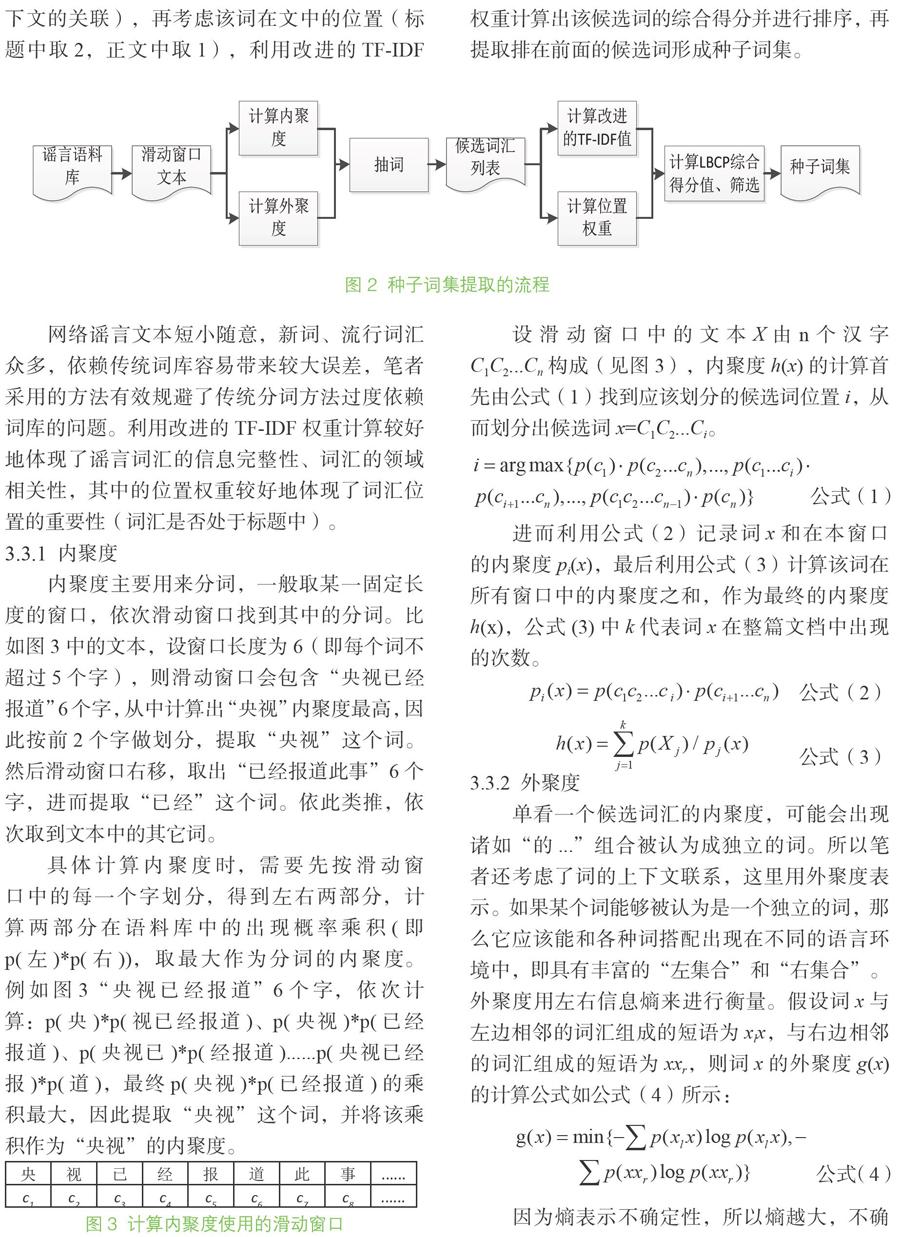
LBCP抽詞算法是考慮了詞語位置和上下文信息的抽詞過程,其提取謠言種子詞集的流程如圖2所示。
LBCP抽詞算法首先設(shè)置一個(gè)滑動(dòng)窗口,從中提取候選詞匯,計(jì)算候選詞匯的內(nèi)聚度(表示該詞的聚合程度)、外聚度(描述該詞與上下文的關(guān)聯(lián)),再考慮該詞在文中的位置(標(biāo)題中取2,正文中取1),利用改進(jìn)的TF-IDF權(quán)重計(jì)算出該候選詞的綜合得分并進(jìn)行排序,再提取排在前面的候選詞形成種子詞集。
圖2? 種子詞集提取的流程
網(wǎng)絡(luò)謠言文本短小隨意,新詞、流行詞匯眾多,依賴傳統(tǒng)詞庫(kù)容易帶來較大誤差,筆者采用的方法有效規(guī)避了傳統(tǒng)分詞方法過度依賴詞庫(kù)的問題。利用改進(jìn)的TF-IDF權(quán)重計(jì)算較好地體現(xiàn)了謠言詞匯的信息完整性、詞匯的領(lǐng)域相關(guān)性,其中的位置權(quán)重較好地體現(xiàn)了詞匯位置的重要性(詞匯是否處于標(biāo)題中)。
3.3.1? 內(nèi)聚度
內(nèi)聚度主要用來分詞,一般取某一固定長(zhǎng)度的窗口,依次滑動(dòng)窗口找到其中的分詞。比如圖3中的文本,設(shè)窗口長(zhǎng)度為6(即每個(gè)詞不超過5個(gè)字),則滑動(dòng)窗口會(huì)包含“央視已經(jīng)報(bào)道”6個(gè)字,從中計(jì)算出“央視”內(nèi)聚度最高,因此按前2個(gè)字做劃分,提取“央視”這個(gè)詞。然后滑動(dòng)窗口右移,取出“已經(jīng)報(bào)道此事”6個(gè)字,進(jìn)而提取“已經(jīng)”這個(gè)詞。依此類推,依次取到文本中的其它詞。
具體計(jì)算內(nèi)聚度時(shí),需要先按滑動(dòng)窗口中的每一個(gè)字劃分,得到左右兩部分,計(jì)算兩部分在語料庫(kù)中的出現(xiàn)概率乘積(即p(左)*p(右)),取最大作為分詞的內(nèi)聚度。例如圖3“央視已經(jīng)報(bào)道”6個(gè)字,依次計(jì)算:p(央)*p(視已經(jīng)報(bào)道)、p(央視)*p(已經(jīng)報(bào)道)、p(央視已)*p(經(jīng)報(bào)道)......p(央視已經(jīng)報(bào))*p(道),最終p(央視)*p(已經(jīng)報(bào)道)的乘積最大,因此提取“央視”這個(gè)詞,并將該乘積作為“央視”的內(nèi)聚度。
央 視 已 經(jīng) 報(bào) 道 此 事 ......
c1 c2 c3 c4 c5 c6 c7 c8 ......
圖3? 計(jì)算內(nèi)聚度使用的滑動(dòng)窗口
設(shè)滑動(dòng)窗口中的文本X由n個(gè)漢字C1C2...Cn構(gòu)成(見圖3),內(nèi)聚度h(x)的計(jì)算首先由公式(1)找到應(yīng)該劃分的候選詞位置i,從而劃分出候選詞x=C1C2...Ci。
公式(1)
進(jìn)而利用公式(2)記錄詞x和在本窗口的內(nèi)聚度pi(x),最后利用公式(3)計(jì)算該詞在所有窗口中的內(nèi)聚度之和,作為最終的內(nèi)聚度h(x),公式(3)中k代表詞x在整篇文檔中出現(xiàn)的次數(shù)。
公式(2)
公式(3)
3.3.2? 外聚度
單看一個(gè)候選詞匯的內(nèi)聚度,可能會(huì)出現(xiàn)諸如“的...”組合被認(rèn)為成獨(dú)立的詞。所以筆者還考慮了詞的上下文聯(lián)系,這里用外聚度表示。如果某個(gè)詞能夠被認(rèn)為是一個(gè)獨(dú)立的詞,那么它應(yīng)該能和各種詞搭配出現(xiàn)在不同的語言環(huán)境中,即具有豐富的“左集合”和“右集合”。外聚度用左右信息熵來進(jìn)行衡量。假設(shè)詞x與左邊相鄰的詞匯組成的短語為xlx,與右邊相鄰的詞匯組成的短語為xxr,則詞x的外聚度g(x)的計(jì)算公式如公式(4)所示:
公式(4)
因?yàn)殪乇硎静淮_定性,所以熵越大,不確定越大,也就是這對(duì)詞左右搭配越豐富,選擇越多。計(jì)算一個(gè)文本片段的左信息熵和右信息熵,如果該文本片段的信息熵偏大,就可以把它看作一個(gè)獨(dú)立的、可以抽取出來的高頻謠言詞匯。
3.3.3? 改進(jìn)的TF-IDF權(quán)重
通過內(nèi)聚度和外聚度得到基于謠言語料的大量新舊詞匯,然后可以利用這些詞的權(quán)重進(jìn)行篩選。本文權(quán)重基于TF-IDF計(jì)算,但是做了如下改進(jìn):①由于舊新聞重復(fù)散播或者同一條謠言僅僅修改了人名、地名、手機(jī)號(hào)碼等張冠李戴型的謠言比較多,因此對(duì)文檔頻率要求較高,而對(duì)于逆文檔頻率要求并不高,不要求詞語對(duì)文檔有獨(dú)特的標(biāo)識(shí)性,因此對(duì)于TF-IDF公式中TF和IDF給予不同的權(quán)重(公式(5)中增加λ,使得TF的權(quán)重值大于IDF的權(quán)重值); ②消除了文檔長(zhǎng)度的不同對(duì)詞權(quán)重的影響(公式(5)中增加分母,進(jìn)行余弦歸一化處理),同時(shí)通過對(duì)詞頻取對(duì)數(shù)來消除詞頻大小差異對(duì)權(quán)重計(jì)算的影響。詞x改進(jìn)的TF-IDF權(quán)重計(jì)算如公式(5)所示:
公式(5)
其中,N為微博總條數(shù),λ是詞頻TF的權(quán)重,tf和idf分別表示詞x的TF值和IDF值,公式(5)右邊的分母利用謠言微博中出現(xiàn)的每個(gè)詞x的TF值tfi和IDF值idfi進(jìn)行余弦歸一化處理。
3.3.4? 位置權(quán)重
針對(duì)微博謠言來說,微博標(biāo)題或者話題中的詞匯比內(nèi)容詞匯更具有代表性,更能反映出微博的主題,也就更能反映出微博主題的謠言敏感度。對(duì)微博文本中詞x的單個(gè)位置權(quán)重值定義如公式(6)所示:
公式(6)
對(duì)微博內(nèi)容進(jìn)行掃描,如果有“【】”或者“[]”或者#,則將其視為微博的標(biāo)題或者話題,將其單個(gè)位置權(quán)重值為2,否則為1。詞x位置權(quán)重為公式(7)所示:
公式(7)
其中,w2(x)為詞匯的位置權(quán)重。Li表示某條微博i中詞x的位置權(quán)重值,D表示包含詞x的微博總條數(shù)。
3.3.5? 抽詞算法流程
LBCP抽詞算法的步驟如下:
Step 1: 利用公式(1)、公式(2)、公式(3)進(jìn)行分詞(詞的長(zhǎng)度不大于某個(gè)閾值t),并計(jì)算各分詞x的內(nèi)聚度h(x);
Step 2: 利用公式(4)計(jì)算各分詞x的外聚度g(x),求得每個(gè)詞的內(nèi)聚度和外聚度之和,篩選出其和大于某閾值θ的詞匯;
Step 3: 對(duì)篩選出的詞計(jì)算其改進(jìn)的TF-IDF權(quán)重w1(x)和位置權(quán)重w2(x),根據(jù)公式(8)計(jì)算綜合得分值;
LBCP(x)=w1(x)×w2(x)? ? ? ? 公式(8)
Step 4:按綜合得分LBCP(x)進(jìn)行排序,取前M個(gè)詞匯作為種子詞集。
3.4? 擴(kuò)展詞集
為了實(shí)現(xiàn)對(duì)謠言敏感詞的有效擴(kuò)展,筆者主要從種子詞集的近似詞、關(guān)聯(lián)詞以及替代詞3個(gè)方面進(jìn)行詞庫(kù)的擴(kuò)展。
3.4.1? 近似詞集
Word2Vec方法計(jì)算的詞向量能反映詞的上下文和語義關(guān)系,因而近似詞集的擴(kuò)展主要通過詞向量Word2Vec進(jìn)行計(jì)算,再通過聚類找種子詞的相似詞,從而得到基于上下文和語義關(guān)系的近似詞,其流程如圖4所示:
圖4? 種子詞集的近似詞集擴(kuò)展流程
3.4.2? 關(guān)聯(lián)詞集
單個(gè)敏感種子詞可能出現(xiàn)在謠言中,也可能出現(xiàn)在正常微博中,比如“免費(fèi)”這個(gè)詞,它既可能出現(xiàn)在不良廠商的微博謠言中,也可能出現(xiàn)在正規(guī)商家的微博宣傳中,但當(dāng)“免費(fèi)”和“轉(zhuǎn)發(fā)”共現(xiàn)時(shí),它就極大可能是謠言。因此,對(duì)于每個(gè)種子詞計(jì)算其高頻率共現(xiàn)的詞匯,即與之相關(guān)度高的詞匯,這些詞匯有助于提高謠言的識(shí)別率。
筆者采用互信息的方法來尋找種子詞關(guān)聯(lián)詞集。種子詞的關(guān)聯(lián)詞集的構(gòu)造流程如圖5所示:
圖5? 種子詞的關(guān)聯(lián)詞集的構(gòu)造流程
但是謠言中這樣產(chǎn)生的成對(duì)詞互信息較高,詞頻卻較低,這樣對(duì)于謠言的識(shí)別作用不大,因此在互信息計(jì)算上加入了詞頻信息,計(jì)算如公式(9)所示:
公式(9)
其中,p(x,y)為詞x和y的詞頻。
3.4.3? 替代詞集
謠言信息發(fā)布者通常會(huì)采取多種方式來逃避敏感詞匹配過濾,比如把謠言敏感詞進(jìn)行中英文的轉(zhuǎn)換或者縮寫等,因此也需要找出種子詞的替代詞集。這樣的詞處理量并不多,本研究通過人工來完成,比如:
(1)拼音:拼音代替漢字,如“拐走”——“guai走”。
(2)英文:英文代替漢字,為種子詞的英文翻譯。
(3)縮寫或簡(jiǎn)寫:種子詞的常用縮寫形式,如“神州六號(hào)”——“神6”。
經(jīng)過以上3種擴(kuò)展,最終將種子詞集與各擴(kuò)展詞集合并構(gòu)建了網(wǎng)絡(luò)謠言的敏感詞庫(kù)。
4? 實(shí)驗(yàn)
4.1? 數(shù)據(jù)集
實(shí)驗(yàn)爬取了新浪微博社區(qū)管理中心、“謠言粉碎機(jī)”以及各地區(qū)辟謠平臺(tái)上發(fā)布的30 034條謠言。同時(shí)爬取了包括中國(guó)新聞網(wǎng)、央視新聞等35 000余條正常微博作為正類數(shù)據(jù)。這些數(shù)據(jù)都經(jīng)過了包括去噪聲、去停用詞等處理過程。去噪主要是刪除了總長(zhǎng)度不足5個(gè)字的微博,這類微博多攜帶信息較少,處理的意義不大,刪除后可提高處理效率。
4.2? 提取種子詞集
利用第3.2節(jié)中種子詞的抽取思路,將微博謠言文本中長(zhǎng)度不超過閾值t(本文取值為9)的文本都當(dāng)作潛在的詞,通過樣例數(shù)據(jù)實(shí)驗(yàn)確定內(nèi)聚度和外聚度的閾值,最后提取出所有不大于閾值t的候選詞。在處理過程中,把全部微博謠言語料作為一個(gè)整體,利用LBCP抽詞算法提取候選詞43 363個(gè)。候選詞的內(nèi)聚度、外聚度及其在謠言微博和正常微博中的詞頻如圖6所示:
圖6? 候選詞匯的內(nèi)聚度、外聚度及詞頻
在上述結(jié)果的基礎(chǔ)上,結(jié)合位置權(quán)重因子,根據(jù)LBCP綜合值進(jìn)行排序,取前300個(gè)作為謠言種子詞集。通過LBCP抽詞算法挑選出來的部分種子詞集如表1所示:
4.3? 種子詞集的擴(kuò)展
(1)近似詞集擴(kuò)展。利用Word2Vec工具計(jì)算得到300個(gè)種子詞集的詞向量,再分別計(jì)算各個(gè)詞向量維度上的均值,計(jì)算得到種子詞集的均值向量。用詞集的平均向量利用KNN模型聚類,得到300個(gè)種子詞最相近的詞。實(shí)驗(yàn)中共取到與種子詞集同屬一類的1 785個(gè)詞作為擴(kuò)展的近似詞,形成的近似詞集如表2所示:
(2)關(guān)聯(lián)詞集擴(kuò)展和替代詞集。計(jì)算種子詞集與語料庫(kù)中其他詞的互信息的大小,并降序排列,得到最終有175個(gè)詞匯的關(guān)聯(lián)詞集。如“拐走”的擴(kuò)展詞包括:找到、造謠、逝去、倒霉、最近、詛咒、資助、真相、折磨等。
種子詞替代詞集包含了300個(gè)種子詞的拼音、英文以及縮寫簡(jiǎn)寫形式,如幫忙的替代詞有:Help、bangmang、bm等,酬金的替代詞有:Remuneration、fee、pay、choujin、cj等。
至此,整個(gè)謠言敏感詞庫(kù)構(gòu)建完成,敏感詞庫(kù)包含種子詞集300個(gè),近似詞集1 785個(gè),關(guān)聯(lián)詞集175個(gè),替代詞集300個(gè),共計(jì)2 260個(gè)。
4.4? 微博謠言識(shí)別
實(shí)驗(yàn)另外爬取了2018年1月到2018年3月期間,新浪微博“謠言粉碎機(jī)”以及各地區(qū)辟謠平臺(tái)上發(fā)布的5 000條謠言數(shù)據(jù),同時(shí)爬取了包括中國(guó)新聞網(wǎng)、今日頭條、央視新聞在內(nèi)的微博大V賬號(hào)的正常微博5 000條。將這? ? 10 000條微博作為測(cè)試數(shù)據(jù),以驗(yàn)證敏感詞庫(kù)對(duì)謠言識(shí)別的提升作用。
從混合的10 000條微博數(shù)據(jù)中提取傳統(tǒng)特征和敏感詞特征,將其作為輸入數(shù)據(jù)。傳統(tǒng)特征包括發(fā)布該微博的用戶信息(用戶粉絲數(shù)、關(guān)注數(shù)、注冊(cè)事件、已發(fā)布微博數(shù)量、是否驗(yàn)證用戶)、微博的結(jié)構(gòu)特征(轉(zhuǎn)發(fā)數(shù)量、微博的長(zhǎng)度、是否包含”@”、是否包含標(biāo)簽、是否包含URL、是否含有表情符號(hào)、標(biāo)點(diǎn)符號(hào)的使用情況、是否含有第一人稱等)以及每條微博所有詞的詞向量加和平均值。敏感詞特征包括敏感詞的個(gè)數(shù)和敏感詞得分總和。
利用以上提取的微博特征,通過隨機(jī)森林、SVM、GBRT、CNN、BiLSTM、TextCNN等分類模型構(gòu)建微博謠言分類器。由于重點(diǎn)在謠言的識(shí)別,因此,本文要求謠言的召回率(本身是謠言且被正確識(shí)別出來的比例)盡量大,準(zhǔn)確率盡量高。實(shí)驗(yàn)中采用十折交叉驗(yàn)證,多種算法的準(zhǔn)確率和召回率在加入敏感詞庫(kù)特征前后的對(duì)比結(jié)果如表3所示:
通過實(shí)驗(yàn)可知,當(dāng)敏感詞特征和傳統(tǒng)特征融合之后,各種分類方法的準(zhǔn)確率和召回率都有大幅的提升,其中BiLSTM的準(zhǔn)確率超過95%,召回率也接近90%。可以看出,謠言敏感詞庫(kù)的構(gòu)建在提升微博謠言的識(shí)別率方面達(dá)到了預(yù)期的效果。
5? 結(jié)語
網(wǎng)絡(luò)謠言敏感詞庫(kù)是謠言識(shí)別的重要基礎(chǔ),筆者旨在構(gòu)建敏感詞庫(kù)并用輔助實(shí)驗(yàn)證明對(duì)謠言微博識(shí)別的有效性。利用大量語料庫(kù),筆者構(gòu)建了一個(gè)基于敏感熱度L-CPBL抽詞算法及其相似詞和擴(kuò)展詞的謠言敏感詞庫(kù)。第一步是種子詞集的提取,L-CPBL抽詞算法是一種無詞典參考的快速抽詞算法,同時(shí)結(jié)合改進(jìn)的LTC權(quán)重以及位置權(quán)重因子,對(duì)謠言敏感詞庫(kù)的種子詞集的提取更準(zhǔn)確;然后基于詞向量模型空間優(yōu)化以及聚類算法對(duì)種子詞集進(jìn)行擴(kuò)展,綜合得到適用于謠言的敏感詞庫(kù)。筆者構(gòu)建的敏感詞庫(kù)適用于微博類社交短文本,并且構(gòu)建過程不依賴于人工專家的識(shí)別挑選,可基于語料庫(kù)同步更新,因此節(jié)省了時(shí)間與費(fèi)用,提高了效率。
筆者創(chuàng)建的謠言敏感詞庫(kù)具有時(shí)效性,需要不斷收集大量謠言語料,而謠言語料需依賴官方公布的謠言信息作為標(biāo)注語料,使得敏感詞庫(kù)的更新需要消耗較多的時(shí)間和資源,可對(duì)敏感詞庫(kù)的更新進(jìn)行進(jìn)一步研究,引入時(shí)序算法或者從傳播的方面進(jìn)行研究,以便更好地解決時(shí)效性問題。
參考文獻(xiàn):
[1] 徐建民,王金花,馬偉瑜.利用本體關(guān)聯(lián)度改進(jìn)的TF-IDF特征詞提取方法[J].情報(bào)科學(xué),2011, 29(2): 279-283.
[2] 周曉. 基于互聯(lián)網(wǎng)的情感詞庫(kù)擴(kuò)展與優(yōu)化研究[D]. 沈陽(yáng): 東北大學(xué), 2011.
[3] 劉耕,方勇,劉嘉勇.基于關(guān)聯(lián)詞和擴(kuò)展規(guī)則的敏感詞庫(kù)設(shè)計(jì)[J].四川大學(xué)學(xué)報(bào)(自然科學(xué)版), 2009, 46(3): 667-671.
[4] 徐琳宏,林鴻飛,潘宇,等.情感詞匯本體的構(gòu)造[J]. 情報(bào)學(xué)報(bào), 2008,27(2): 180-185
[5] 侯麗,李姣,侯震,等.基于混合策略的公眾健康領(lǐng)域新詞識(shí)別方法研究[J].圖書情報(bào)工作, 2015,59(23):115-123.
[6] QUAN C, REN F. Construction of a blog emotion corpus for Chinese emotional expression analysis[C]//Proceedings of conference on empirical methods in natural language processing. Stroudsburg:Association for Computational Linguistics,2009:1446-1454.
[7] PENG F, FENG F, MCCALLUM A. Chinese segmentation and new word detection using conditional random fields[C]//Proceedings of international conference on computational linguistics. Stroudsburg: Association for Computational Linguistics,2004:562-569.
[8] 周強(qiáng).漢語謂詞組合范疇語法詞庫(kù)的自動(dòng)構(gòu)建研究[J].中文信息學(xué)報(bào), 2016,30(3): 196-203.
[9] CHEN K J, MA W Y. Unknown word extraction for Chinese documents[C]// Proceedings of international conference on DBLP. Taipei: Morgan Kaufmann Publishers, 2002:169-175.
[10] 彭云,萬常選,江騰蛟,等.基于語義約束LDA的商品特征和情感詞提取[J].軟件學(xué)報(bào), 2017,28(3):676-693.
[11] CHEN H, LYNCH K, BASU K, et al. Generating, integrating and activating thesauri for concept-based document retrieval[J]. IEEE intelligent systems and their applications, 1993,8(2):25-34.
[12] YU S,CAI D,WEN J,et al. Improving pseudo-relevance feedback in web information retrieval using Web page segmentation[C]//Proceedings of the 12th international conference on World Wide Web. New York: ACM, 2003:11-18.
[13] PNOTE J M,CROFT W B. A language modeling approach to information retrieval[C]//Proceeding of the 21st International ACM SIGIR conference on research and development in information retrieval. New York: ACM, 1998:275-281.
[14] PEDERSEN T, KULKARNI A. Identifying similar words and contexts in natural language with sense clusters[C]// Proceedings of the 20th national conference on artificial intelligence. Pittsburgh: AAAI Press, 2010:1694-1695.
[15] TURNEY P D, LITTMAN M L. Measuring praise and criticism: inference of semantic orientation from association[J]. ACM transactions on information systems, 2003, 21(4):315-346.
[16] NEVIAROUSKAYA A,PRENDINGER H,ISHIZUKA M. SentiFul: a lexicon for sentiment? analysis[J].IEEE transactions on affective computing,2011,2(1):22-36.
作者貢獻(xiàn)說明:
夏? 松:設(shè)計(jì)模型, 完成實(shí)驗(yàn),修改論文;
林榮蓉:采集數(shù)據(jù),進(jìn)行實(shí)驗(yàn),撰寫論文初稿;
劉? 勘:提出研究思路,設(shè)計(jì)研究方案,修改論文與定稿。
Construction of Sensitive Thesaurus for Network Rumors
——Taking the Microblog Rumors as an Example
Xia Song? Lin Rongrong? Liu Kan
School of Information and Safety Engineering, Zhongnan University of Economics and Law, Wuhan 430074
Abstract: [Purpose/significance] The network rumors seriously influent the spread of normal information on the internet. The purpose of this paper is to construct a sensitive lexicon on microblog rumors and to improve the recognition accuracy of the network rumors. [Method/process] According to the characteristics of microblogs short text on social networking platforms, this paper focuses on construction of the microblog sensitive thesaurus, which is built up through LBCP algorithm and extension of multiple level words. At first, the method directly extracts words through LBCP algorithm, which considers the cohesion and polymerization of rumor words. And then, based on the core words, multiple level words are expanded to get sensitive thesaurus. [Result/conclusion] In addition to the features of the text, user characteristics, propagation characteristics, emotional analysis, and rumor features based on sensitive thesaurus are exploited. Experimental results show that the accuracy of microblogs rumor recognition can be improved greatly based on sensitive thesaurus.
Keywords: sensitive thesaurus? ? word embedding? ? feature space? ? network rumors
基金項(xiàng)目:本文系國(guó)家社會(huì)科學(xué)基金資助項(xiàng)目“基于文本挖掘的網(wǎng)絡(luò)謠言預(yù)判研究”(項(xiàng)目編號(hào):14BXW033)研究成果之一。
作者簡(jiǎn)介:夏松(ORCID:0000-0001-7700-6185),講師,博士;林榮蓉(ORCID:0000-0002-5141-6503),碩士研究生;劉勘(ORCID:0000-0002-9686-9768),教授,博士,通訊作者, E-mail: liukan@zuel.edu.cn。
收稿日期:2019-06-18? ? ? ? 發(fā)表日期:2019-09-11? ? ? ? 本文責(zé)任編輯:劉遠(yuǎn)穎
