基于卷積模型的農業問答語性特征抽取分析
2019-01-05 08:02:44張明岳吳華瑞朱華吉
農業機械學報 2018年12期
張明岳 吳華瑞,2 朱華吉
(1.國家農業信息化工程技術研究中心, 北京 100097; 2.北京農業信息技術研究中心, 北京 100097;3.農業農村部農業信息軟硬件產品質量檢測重點實驗室, 北京 100097)
0 引言
問答社區是基于互聯網,以用戶提出問題、回答問題和討論問題為主的知識服務社區,能夠更好地滿足互聯網用戶獲取信息和交流知識的需求,是目前自然語言處理(Natural language processing,NLP)和信息檢索(Information retrieval,IR)領域備受關注、具有廣泛發展前景的研究方向[1-2]。“中國農技推廣APP”作為服務于農技人員的專業平臺,用戶每天在農技問答模塊發布的提問有上萬余條,這類文本具有稀疏性、實時性、不規范等特點,加劇了問題文本關鍵詞特征的稀疏化,難以充分挖掘特征之間的關聯性,如何從數據集中方便、快捷地挖掘有效信息并提供更高質量和智能化的農業信息服務已成為農業信息分類領域文本挖掘的主要任務之一。傳統的人工篩查需要消耗大量的人力、物力,并且很難高效地完成對無效冗余數據的處理。目前常用的人工特征分類及淺層分類學習模型雖然能夠輔助完成數據篩查及剔除等工作,但由于其過分依賴人工選取特征和分類器性能,不具備從數據中自動抽取和組織信息的能力,導致經典的文本分析方法在短文本處理上的適用性下降[3-4]。因此利用計算機實現農技冗余問答自動、智能篩查是“中國農技推廣APP”需要解決的一個重要問題。神經網絡模型具有靈活性和多樣性的特點,在序列標注[5]、語義匹配[6]、情感分析[7]等自然語言處理任務中表現出較好的性能,由于該類模型能夠以端到端的方式進行訓練,自動學習特定任務并挖掘文本內的大量語義關系,有效減少了傳統的統計機器學習方法中人工設定大量特征等相關工作[8]。
目前結合神經網絡模型開展自然語言處理的相關應用已經取得了一定成果,其中卷積神經網絡(Convolutional neural network,CNN)在情感分析和文本分類領域得到很好的應用[9-12]。由于農業領域一直缺乏大規模可用的數據庫,因此關于這方面的研究還較少,只有個別研究者針對農業特定領域研究神經網絡模型在農業問答系統的應用,但仍處于起步階段。趙明等[13]構建了基于Word2vec和雙向門控循環單元神經網絡(Bi-directional gated recurrent unit,BIGRU)的番茄病蟲害問句分類模型,對番茄病蟲害智能問答系統用戶問句進行高效分類。針對傳統的句子相似度算法準確率較低的問題,梁敬東等[14]通過構建基于 Word2vec和長短期記憶網絡(Long short-term memory,LSTM)的神經網絡計算問句相似度,并在水稻常問問題集(Frequently asked question,FAQ)中的問句上進行驗證,以提高系統回答的準確性。以上研究的開展為神經網絡應用于農業知識問答系統提供了參考和可行性依據,但關于神經網絡應用于文本多樣性、情感極性等農業文本特征挖掘方面仍有不足,關于利用卷積神經網絡檢驗農技推廣提問數據的精確性和可靠性方面尚未見報道。
為了實現農技推廣社區問答情感特征信息的有效挖掘和表達,本文利用基于卷積神經網絡模型的知識自動化的方法,有針對性地引入農業詞庫字典進行中文分詞和詞向量表示[15],利用卷積神經網絡提取文本情感表達作為文本特征向量,用于情感分類,并進一步針對其重要的結構參數和訓練策略進行優化和改進,構建一種基于卷積神經網絡的農業問答情感極性特征抽取分析模型,以實現農技推廣提問的精確高效識別。
1 數據采集與預處理
1.1 樣本采集
本文數據集來源于“中國農技推廣APP”農技問答模塊,以2017年8月上線到2018年4月產生的130多萬條提問數據作為基礎樣本。由于人工標注百萬級樣本十分困難,參照文獻[16-18]使用的文本分類數據集量級,根據月份選取8 000條數據作為試驗樣本集。其中人工標注有效及無效提問各3 000條作為學習數據集,用于卷積神經網絡訓練和優化參數驗證,人工選擇樣例如表1所示。剩余2 000條樣本數據作為模型效果驗證的測試集,由于測試集是在訓練集和驗證集選取之后選取,已經較大限度地保證了訓練與測試數據集文本的不重疊,因此可以將測試結果的平均準確率作為文本模型的識別效果評價指標[19]。
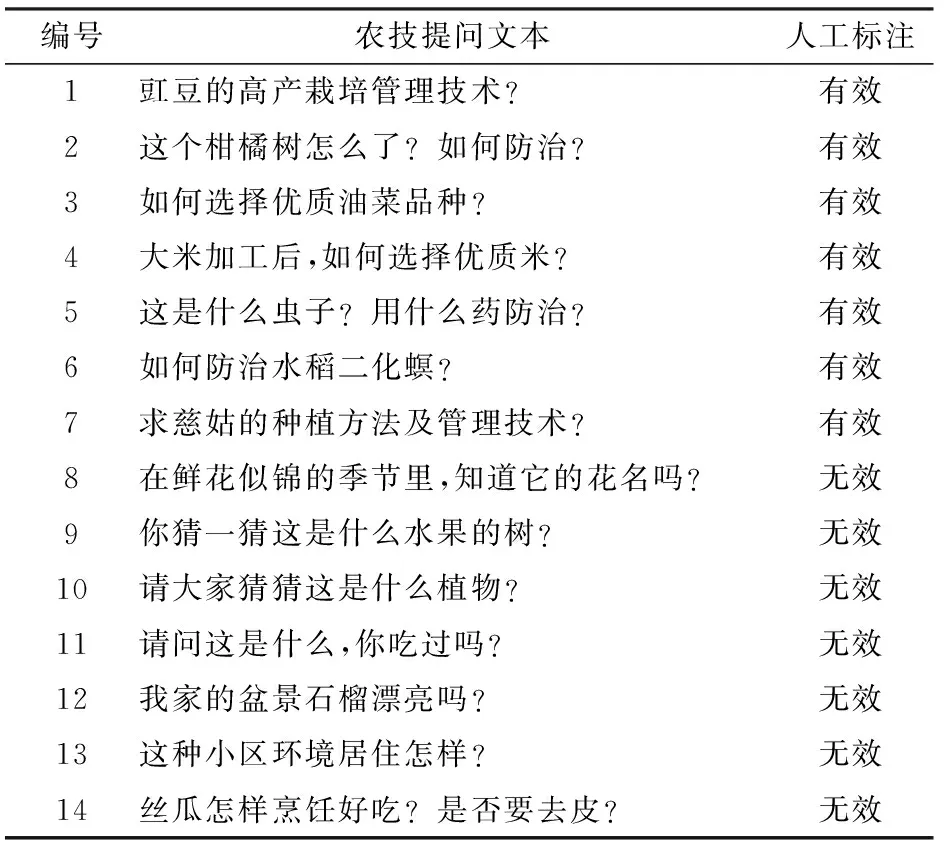
表1 人工選擇樣例Tab.1 Worked examples of manual annotation
1.2 數據集預處理
中文文本需要進行預處理轉換為數字形式,以便能夠被計算機識別。為最大程度地保留原始中文文本的特征及語義信息,減少信息損失,需要對文本進行去噪、分詞、向量表示等預處理操作,主要步驟如圖1所示。
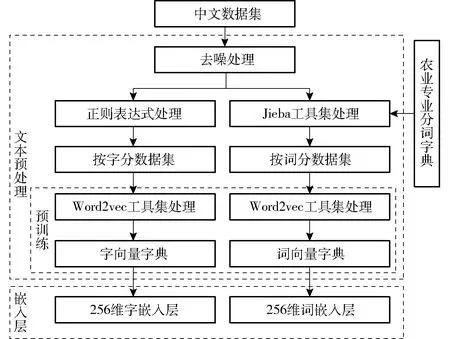
圖1 數據預處理過程示意圖Fig.1 Schematic of data preprocessing
(1)去噪:數據集中原始數據包含中文特殊字符、英文特殊字符、空格等多種類型的符號信息,不利于語性特征抽取。因此使用正則表達式對數據集進行去噪處理,僅保留中文、英文、字母、數字等通用特征信息。
(2)分字與分詞:利用Python正則表達式對數據集中每條語句的漢字進行分割形成分字數據集。由于中文分詞[20]主要依賴語義與語境,而農技提問又包含很多農業專業詞匯,基礎分詞庫很難滿足要求,本試驗還需要建立農業專業詞匯的自定義分詞字典。參照文獻[21]選擇搜狗農業詞匯大全中的8 874個詞匯作為農業專業分詞字典,再利用Jieba分詞工具包對數據集進行精確模式分詞形成分詞數據集[22]。
(3)生成詞向量:使用Word2vec工具集的Skip-gram模型[23]對分字集和分詞集進行預訓練,具體操作方法是對文本中的字、詞等元素的出現頻率進行統計,通過無監督訓練,獲得作為語料基礎構成元素的字、詞對應的指定維度的向量表征,最終生成指定維度的字向量和詞向量。
(4)文本向量化:為便于神經網絡訓練,文本數據需要轉化為字或詞嵌入,具體操作是將樣本中每個字或詞替換成對應的向量表示,將文本轉化為向量組。對樣本每條數據的字或詞進行統計,選擇字或詞數最多的那條文本的字或詞個數作為文本向量維度,其余提問長度不足的通過0來補齊。
2 基于卷積神經網絡模型的農業數據篩查方法
自KIM[10]研究了利用卷積神經網絡處理自然語言后,大量研究人員在其基礎上做了拓展與優化,盡管文本分類模型變得越來越豐富,但所有模型的基本架構都與圖2相近。基本思路是字或詞經過嵌入層后利用不同神經網絡結構提取局部、全局和上下文信息,經過全連接層合并到一起,最后利用不同分類器進行文本分類得到結果。
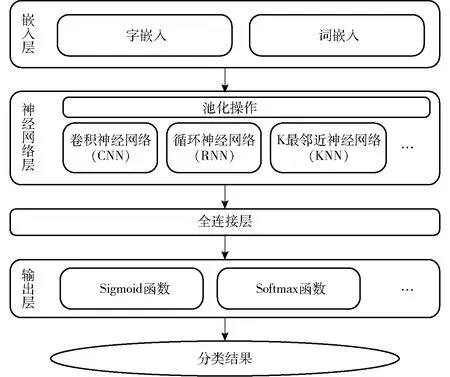
圖2 文本分類基本架構Fig.2 Basic structure of text categorization
本文在基本架構基礎上進行了拓展,增加了卷積層數以及更多尺度的卷積核,同時在激活之前增加了批標準化進行規范化處理,全連接層中也增加了批標準化處理,最后使用Softmax邏輯回歸作為分類器,進行數據的語性特征抽取。
模型中卷積核的尺寸與數量對于CNN的性能至關重要。輸入語料通過i個不同的卷積核卷積,生成j個不同的特征圖,卷積層滿足公式
(1)
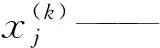
f(·)——批標準化及激活函數
Mj——輸入圖像的特征量
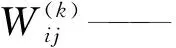
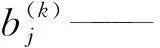
針對各層分布不均和精度彌散等問題,在進行激活之前使用批標準化(Batch normalization,BN)來規范響應,同時加快網絡收斂,防止過擬合。具體公式為
(2)
(3)
(4)
yi=γi+β=BNγ,β(xi)
(5)
式中x——輸入值
m——批量化的數目
γ、β——學習參數

ε——常量,用來保證值的穩定性
yi——結果輸出值
BNγ,β(·)——批標準化函數
參考CLEVERT等[24]的試驗,模型激活函數使用修正線性單元(Rectified linear unit, ReLU),公式為
f(x)=max(0,x)
(6)
根據文本分類的特性,需要在一定程度上降低卷積層參數誤差造成的估計均值偏移所引起的特征提取的誤差,試驗選用Max-pooling作為池化方法。網絡的訓練階段使用批量隨機梯度下降法(Mini-batch stochastic gradient descend)。
本文使用Softmax邏輯回歸來做特征分類器(對應Softmax loss損失函數),進行實際文本的語性特征抽取[25]。最終確定的卷積神經網絡結構如圖3所示。
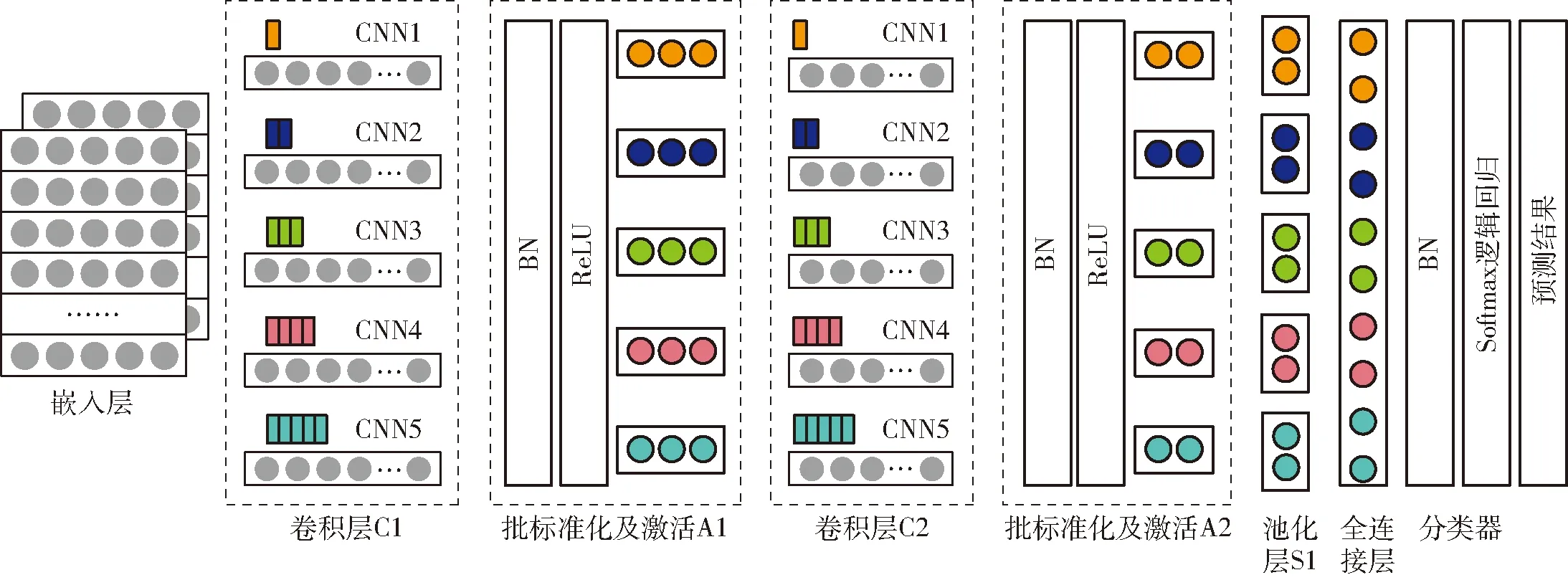
圖3 基于文本的卷積神經網絡結構示意圖Fig.3 Schematic of text-based convolution neural network
3 試驗及結果分析
3.1 硬件及軟件
本試驗處理平臺為聯想臺式計算機,處理器為Intel(R)Core(TM)i5-4590、主頻3.30 GHz、內存8 GB、容量120 GB金士頓固態硬盤,運行環境為:Windows 10專業版 64位,軟件環境為Python 3.6.5和Tensorflow 1.8.0。
3.2 試驗操作流程
(1)輸入層
輸入層為經過預處理的256維詞嵌入,對分詞后數據集的詞組個數進行統計,可以得到數據集中最多詞數為58個,即每條提問的詞向量維度為58×256。將輸入數據順序打亂并隨機排列,選取前面90%(5 400條)作為訓練數據,后面10%(600條)作為驗證數據。訓練次數設置為200次,每批次輸入500條,共計輸入2 200批次,圖4為輸入層中“植物”一詞的向量示例。
(2)卷積層
卷積層的作用是特征提取,設置卷積核長度為58,窗口層數為5,每層窗口滑動尺寸分別是1~5,卷積核每個窗口特征映射數為200,所以第1層卷積核W1的尺寸為(1~5)×58×1×200,第2層卷積核W2的尺寸為(1~5)×58×200×200。
(3)池化層
池化層的作用是特征壓縮,在進行池化前使用了批標準化進行處理。最后連接一個Softmax邏輯回歸分類器,用于將壓縮好的特征映射到輸出層。S1對前面的特征圖進行了最大池化操作,每批次得到500個1 000維的特征圖。
(4)Softmax分類器
經過訓練,最后剩下的神經元由Softmax分類器將其拼合成為一維列向量,全連接到輸出層,計算出屬于每類特征輸出的概率值。
(5)輸出層
比較分類器中計算出的語性特征概率值,將結果歸類到概率最大的一組,然后合并歸類結果并保存到prediction.csv文件中,識別結果樣例如表2所示,表中“○”表示識別結果與真實值相同,“X”表示識別結果與真實值不同。
3.3 結果與誤差分析
采用試驗所描述的卷積神經網絡結構使用訓練樣本來訓練模型,網絡權重初始化采用標準差為0.01、均值為0的高斯分布,樣本迭代次數均設置為200,批處理尺寸設置為100,設置權重參數的初始學習速率為0.001,動量因子設置為0.9。對上述訓練集做2 600次迭代訓練,其訓練曲線如圖5所示。
從圖5可以看出,隨著迭代次數不斷增加,模型分類誤差逐漸降低。當訓練迭代到2 000次時訓練集的識別準確率最高達到98.6%,迭代到2 200次時驗證集的識別率最高達到93.5%,且從第1 400次迭代以后訓練集和驗證集兩者的誤差差值趨于穩定,說明模型狀況良好,卷積神經網絡達到了預期的訓練效果。由試驗可以確定訓練達到2 200次以后模型對樣本的識別準確率趨于擬合,將訓練次數設定為2 200能夠使模型得到充分訓練。
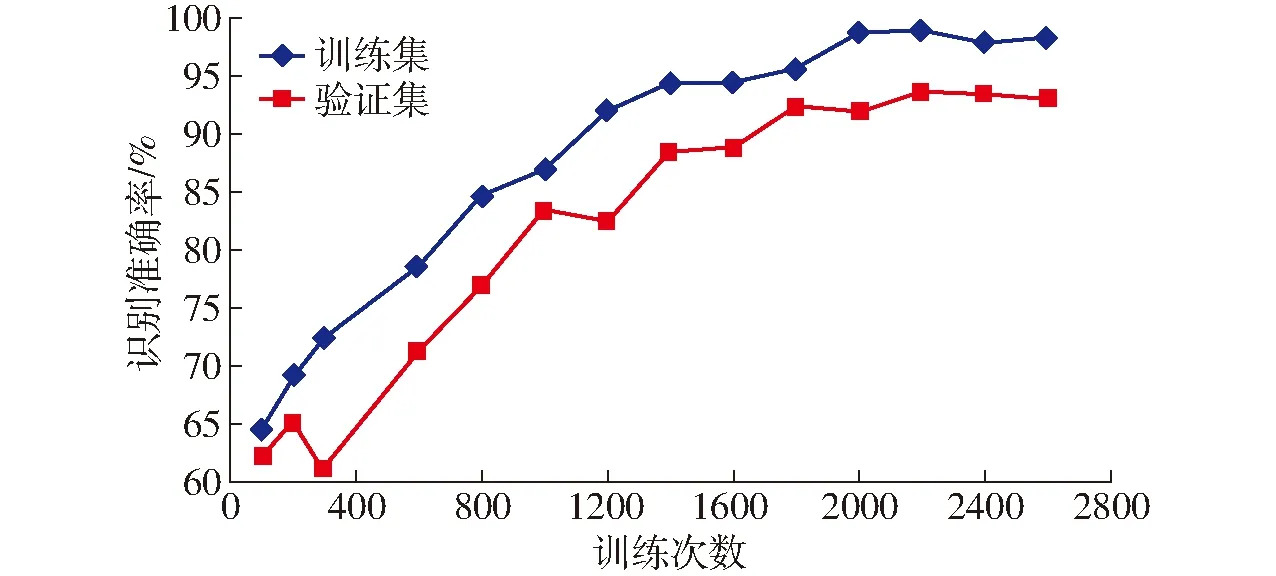
圖5 迭代次數與識別準確率關系曲線Fig.5 Diagram of relationship between number of iterations and accuracy
為了驗證不同類型嵌入層對模型效果的影響,分別使用字向量嵌入、詞向量嵌入以及經過農業字典分詞的詞向量嵌入作為輸入層,對試驗模型進行2 200次的迭代對比訓練,識別結果如圖6所示。
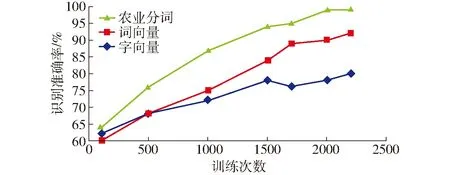
圖6 不同嵌入層迭代次數與識別準確率關系曲線Fig.6 Diagram of relationship between number of iterations and accuracy in different embedded layers
由圖6可以看出,隨著迭代次數增加,各模型識別準確率均不同程度增加,當上漲到一定程度后各模型識別率趨于穩定。經過2 200次訓練,詞向量嵌入的識別準確率最高達到92%,字向量嵌入的識別準確率最高達到80%,經過農業字典分詞的向量嵌入識別準確率是三者中最高的,接近99%。試驗證明,輸入層使用分詞嵌入能夠比分字更好地表達文本特征,針對所屬領域使用專用的詞匯進行細化分詞后會更加充分地表達文本特征。
通過表3可以看出,增加卷積核滑動窗口個數以及窗口特征映射層數能夠有效增加模型的識別準確率。當模型參數增加到一定程度后繼續增加參數寬度和深度,模型的識別準確率很難繼續提升,但模型需要的訓練時間更長。通過模型參數比較,設定卷積核的窗口寬度為5、映射特征層數為200的訓練模型能夠在現有軟硬件的條件下較好地滿足試驗要求。
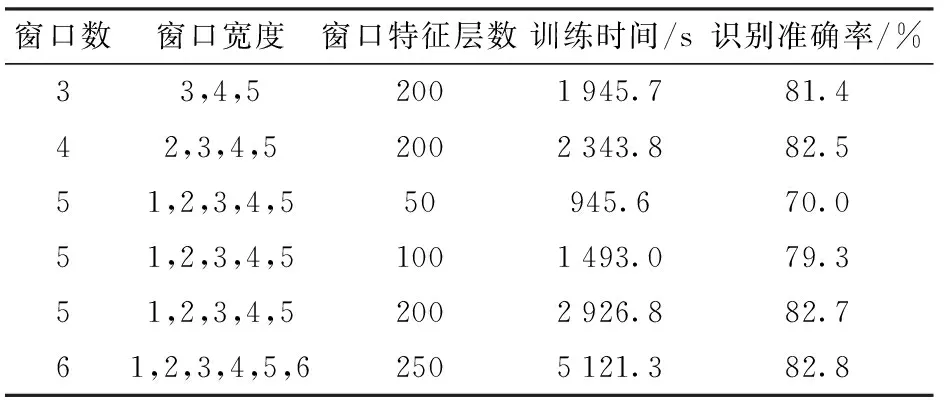
表3 試驗模型參數的比較Tab.3 Comparison of experimental model parameters
為了進一步證明提出方法的性能,將其與現有的JOHNSON等[26]提出的One-hot詞表示法+CNN的文本分類方法、ASEERVATHAM等[27]提出的SVM分類器方法、DANTI等[28]提出的文檔矢量空間表示模型(DVSM)+詞間距離度量分類方法、ZHANG等[29]提出的KNN分類器方法以及使用Dropout代替Batch-Normalization執行標準化的CNN分類方法等5種文本分類方法進行比較,對測試集的2 000條提問數據進行識別,各種分類方法的篩選性能如表4所示。
通過表4可以看出,各類算法都能夠對測試集進行有效的特征篩選,本文使用方法在6種算法中識別準確率最高,達到了82.7%。盡管文獻[26]的方法也使用了CNN模型,但由于輸入層使用的是One-hot方法,其準確率只達到68.2%,明顯低于其他篩選方法,說明Word2vec的Skip-gram模型能夠更高效地表示語料特征,也證明了輸入層的文本處理方式對于模型訓練結果存在較大影響。雖然文獻[27]方法在測試集中的識別準確率比文獻[28]方法高出1.1個百分點,但是精確率和F1度量值明顯不如后者,這也間接說明相鄰分詞之間的關聯語意對識別結果存在影響。使用Batch-Normalization規范響應相較于卷積神經網絡常用的Dorpout標準化方法能夠加快收斂,使訓練更加充分,防止過擬合,顯著提高識別準確率,識別準確率高出6.3個百分點。綜合表4列出的各類文本分類方法,本文提出的基于CNN優化模型因為權值共享機制減少了網絡中的可訓練參數,有效降低了模型復雜度,具有更好的泛化能力,因此相較于其他機器學習模型取得了更好的分類效果[30]。卷積神經網絡的核心特點是每個卷積層包含數個卷積核及大量特征面,通過池化操作大量減少模型中的神經元個數,增強了模型表達能力,因此對輸入空間的平移不變特征更具魯棒性,有效防止訓練過擬合[31]。盡管卷積神經網絡模型訓練時間遠高于表4其他分類方法,但通過權值共享、局部連接、批標準化增強、池化操作等使本文方法具有更少的連接和參數、更易于訓練,具有自動抽取語性特征并且得到更多分類特征的特點。
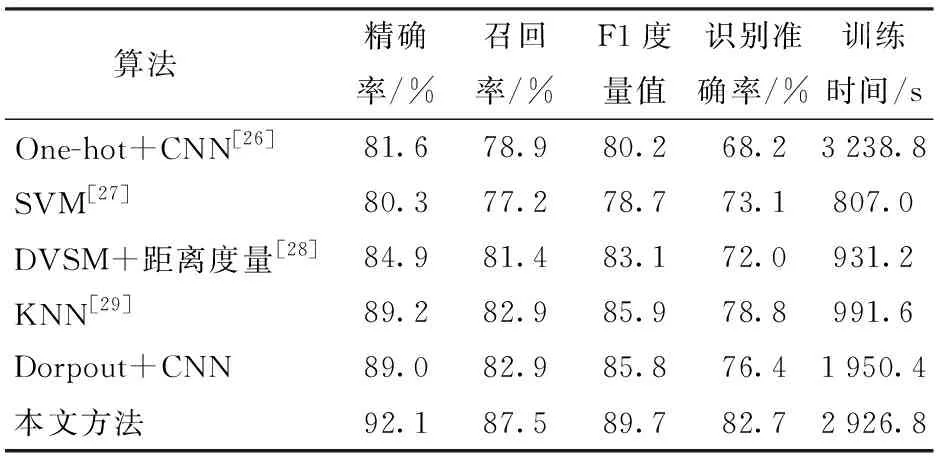
表4 各種分類方法的比較Tab.4 Comparison of various classification methods
4 結論
(1)研究方法滿足實際應用需求。通過卷積網絡模型篩選數據,減小了人工篩查的工作強度,避免了傳統識別方法中復雜的預處理和特征篩選過程,提高了算法優化效率,對測試集特征識別準確率達到82.7%。
(2)優化輸入層表示及模型結構能顯著提高識別效果。不同類型嵌入層對于篩選結果也有較大影響,使用農業專業詞典進行分詞處理的嵌入層在模型學習效率和識別準確率上都有提高。另外使用Batch-Normalization替換Dropout訓練后識別效果相較于Dropout標準化的卷積神經網絡識別準確率提升了6.3個百分點,對比其他類型的文本分類模型識別效果也具有明顯優勢。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
