軌道交通線網大數據的建模和存儲方案
2018-12-13 09:07:06陳莉莉張賽橋
計算機應用與軟件 2018年12期
陳莉莉 張賽橋 胡 波
(南瑞集團(國網電力科學研究院)有限公司 江蘇 南京 210032)
0 引 言
隨著城市軌道交通建設的加快,各個城市的地鐵線路逐漸向線網化發展,軌道交通的線網數據類型越來越多,數據量也越來越大,海量的數據匯集到軌道交通指揮中心。在軌道交通領域,如何有效地收集、整理、存儲、處理和分析這些結構化和非結構化數據,進行深度的數據挖掘和數據分析,挖掘其中有價值的信息,從而提高軌道交通的運營水平,提升科學決策、信息服務和安全保障能力,增加效益降低成本,已日益成為業界關注的重點。
目前軌道交通指揮中心的已有數據倉庫建設案例還比較少,而且都采用MPP架構的數據倉庫進行結構化數據存儲。但是隨著數據量的增大和數據類型的增多,MPP的價格高昂、擴展成本太高、不能存儲非結構化數據、不能進行流處理的弱點暴露出來。Hadoop平臺有著不同于MPP的架構和數據處理方式,它的結構更靈活,存儲的數據量級更大,支持高并發和實時處理,易于擴展,而且實現成本相對較低。但是Hadoop的數據存儲中沒有索引,底層數據塊比MPP大很多,所以數據精準查詢、表與表相組合查詢的速度比MPP要慢。以往在軌道交通線網中心的MPP數倉,采用比較多的是基于三范式建模的數據建模方法。Hadoop平臺的特點是相對廉價,適合做批量數據查詢,但少量精準查詢和復雜的多表聯合查詢效率低,所以三范式建模不能照搬到Hadoop平臺。因此要針對Hadoop平臺的特點,選用合適的組件,對軌道交通的線網大數據中的結構化數據,設計以維度建模為主的數據建模方法,規避Hadoop平臺的缺點并最大限度發揮其優點,從而實現線網大數據的安全和高效的存儲和訪問。針對此特點,星形模型得到了比較多的應用。
對于以往的軌道交通指揮中心的非結構化數據,比如視頻、圖像、語音、日志文件、頁面抓取等,都采用磁盤陣列,只實現存儲備份功能,無法實現全文檢索以至于進一步的分析。在軌道交通運營中,需要分析非結構化數據,即進行數據的內容檢索和處理,本文引入了Hadoop平臺取代磁盤陣列的存儲模式。
本文描述了一種軌道交通指揮中心的海量線網大數據的數據建模和存儲方法,實現高效的軌道交通指揮中心的線網大數據的數據存儲和即席檢索,以及進一步的數據挖掘和數據分析,進而指導軌道交通運營的功能。
1 結構化數據模型
如圖1所示,線網指揮平臺把從數據源采集的結構化數據,其中大部分為時序數據,先作為臨時數據存入HBase;再經過數據清洗轉換,存入基礎數據區;公共層數據存在Hive里;面向應用的數據集市層,比如指標分析、客流分析、設備維護等,存在Hive里。
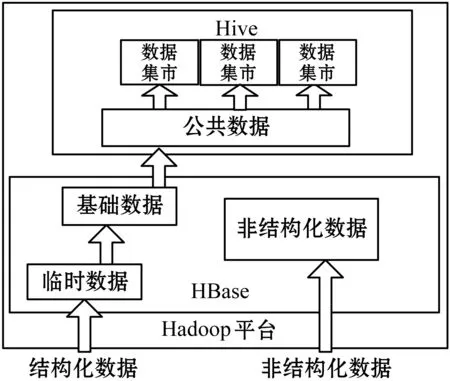
圖1 線網大數據的數據組織和存儲結構
在數據的概念建模階段,Hadoop和MPP并沒有不同。從線網數據中抽象出來的主題和關聯方式都相似。我們列出軌道交通的各個主題:路網、設備、行車、票務、渠道、事件、OD、當事人等。
1.1 HBase的RowKey組織型式
把軌道交通各個線路采集來的各個子系統的結構化的時序數據,匯集到線網指揮中心的大數據平臺,平臺采用Hadoop架構。對輸入數據以小文件的方式組織起來,采用Avro格式存入HBase中的臨時數據區。
臨時數據區的小文件是不同的線路集成商送上來的每條線路的數據。先要對臨時數據進行格式規整,以統一格式存入歷史數據區。對歷史數據,參照它的具體應用,采用范式建模的方法,以近源的格式存儲到HBase中。
線網大數據中的結構化數據有兩類:一類是設備點變化的時序數據,另一類是客流進出站的OD時序數據。
對于設備點變化的時序數據,HBase的RowKey以輸入數據點的全線網唯一性索引和該數據點的數據變化時間組合而成。對于前者是以字符串作為關鍵字建模,RowKey的組織形式為:

線路車站應用設備點類型點變化時間
前面6個區拼成的字符串是每個數據點的索引值,最后一個區是點變化時間。這樣的分級組成方式,易于理解又實現了全線網的統一,方便進行數據擴展和新線接入。而且變化時間在長期上會呈現均勻分布的形式,容易實現把數據平均分布存儲于不同的數據節點,保證各數據節點間的壓力平衡。
軌道交通指揮中心的指標分析中有大量的對點的一段時間內變化進行批量讀入的需求,這種存儲格式可以一次性讀入時間序列在一段時間內的變化數據,實現高效的數據訪問。
類似的情況,對于客流進出站的OD時序數據,RowKey的組織形式為:

卡號進出站時間
1.2 Hive建表型式
歷史數據經過數據治理后,根據軌道交通指揮中心的具體數據應用,設計各自的數據集市,這些數據集市的表存儲到Hive中。對這些數據集市提煉出共同的通用數據作為中間層,這些數據也存入Hive中。Hive中表的數據模型按照Hadoop本身的特點設計,采用維度建模方法設計,對數據進行降范式處理;在線網中,把原有線路數據模型中分小表存儲的不同的屬性的數據,根據具體需求整合到一張大表中重復存儲,以增大數據存儲空間換取有效縮短讀取時間。采取的方法有:
1) 對于ISCS數據,把線路中以點為中心的建表方式改為線網中以設備為中心的建表方式,即把每個設備的所有點都集中存在一張表里。
2) 對于客流數據,把OD和相關列車運行時刻表組合存儲為一張表。
3) 對于行車數據,把列車實際運行圖和計劃運行圖、司機信息、列車狀態信息、滿載率等相關信息組合存儲為一張表。
2 結構化數據實施方案
軌道交通各線路采集的各子系統的采樣數據,其實是一種結構化的時序數據,匯集到線網指揮中心的大數據平臺。圖2中,線網指揮中心的Hadoop平臺通過Kafka總線獲取線路端的數據,作為實時流處理的輸入,通過Spark Streaming在線處理后,直接輸出到展示平臺。
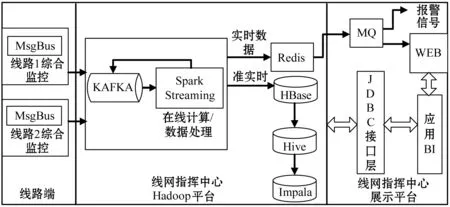
圖2 Hadoop平臺的流處理方案
對于輸入的數據,可以分為以FTP方式上傳的批量數據,或從Kafka總線接收實時流數據,實時流數據經過整理后和FTP方式上傳的數據存入臨時數據區。每一條時序數據用Json串的方式存儲每個數據點的索引、變化時間、值和狀態,一段時間內的數據變化組成一個文件。輸入數據以小文件的組織方式存入HBase中的臨時數據區。
臨時數據區存儲的數據來源是城市軌道交通的不同線路,而線路集成商不相同造成數據格式的不同。因此首先要對這些數據進行格式規整,再存入基礎數據區長期保存。HBase的RowKey以輸入數據點的線網唯一性索引和數據變化時間的組合。各個輸入點是以字符串作為關鍵字的線網級統一的數據模型,比如:南京三號線浮橋站BAS應用的1號風機,它的轉速是個數字量類型的點,在2017年7月18日12∶35∶55的236 ms這個時間發生了一次變化,于是RowKey就記為:
njl3.fq.bas.fj1.dig.zs#20170718123555236。
這樣的存儲方式充分考慮線網數據的擴展性,支持線網全數據接入。
經過數據治理后的歷史數據,針對軌道交通指揮中心的數據應用,對每個應用設計各自的數據集市,存儲到Hive中。再提取出每個數據集市的通用數據,建表存入Hive中。
按照Hadoop本身的特點設計存儲表,對數據進行降范式處理,采用大寬表的方法,避免表與表之間的Join操作。通常一個設備有幾十個采集點,將這些不同數據點聚合到一張大表中存儲,每個點的不同屬性以結構體的方式組織到大表中。對客流數據的OD分析的中間結果,每一張地鐵卡對應卡號為索引的進出站記錄,以及和列車時刻表結合時計算出的這位乘客于某個時間從某個閘機進入某站,然后于某個時間乘某趟列車,在某個換乘站轉車,轉了幾次車后到達終點站,到達時間,從某個閘機出站,上述所有的信息,都聚合成一條記錄存儲。
比如,圖3的BAS專業的廢水泵設備,表征這個設備屬性狀態的有一系列數字量和模擬量點。這些點在MPP的點表里逐行存儲,在Hadoop里把它合并進一張設備表里。

圖3 設備和點的對應關系
數據存入Hive,可以利用Impala和Solr等組件,采用NOSQL技術,加快對數據的訪問。
3 非結構化數據存儲
針對軌道交通指揮中心的大量非結構化數據,其類型大致有視頻、音頻、圖片、檔案文件、日志文件、網頁抓取等。軌道交通領域的這些文件都不太大,即便是視頻文件,由于軌道交通指揮中心建設有線網CCTV中心存儲視頻,線網指揮中心的視頻都是小段,文件基本上均小于100 MB,因此,都可以存儲到HBase中,并在HBase中另外建表存儲元數據,實現對非結構化數據的進一步檢索和內容分析。
這些非結構化數據和文件存儲,操作瓶頸不在CPU,而在磁盤IO和內存,所以采用Snappy技術做文件壓縮,以CPU運算減少內存和磁盤IO操作。
由于文件數量多,所以存儲的分區目錄組織方式為文件來源應用,分為五類:歷史檔案、應急指揮、系統日志、報表、網絡抓取內容,如表1所示。按照具體應用分類,對后四種每半年為一期實現文件歸檔,用于對非結構化數據的進一步檢索和內容分析。
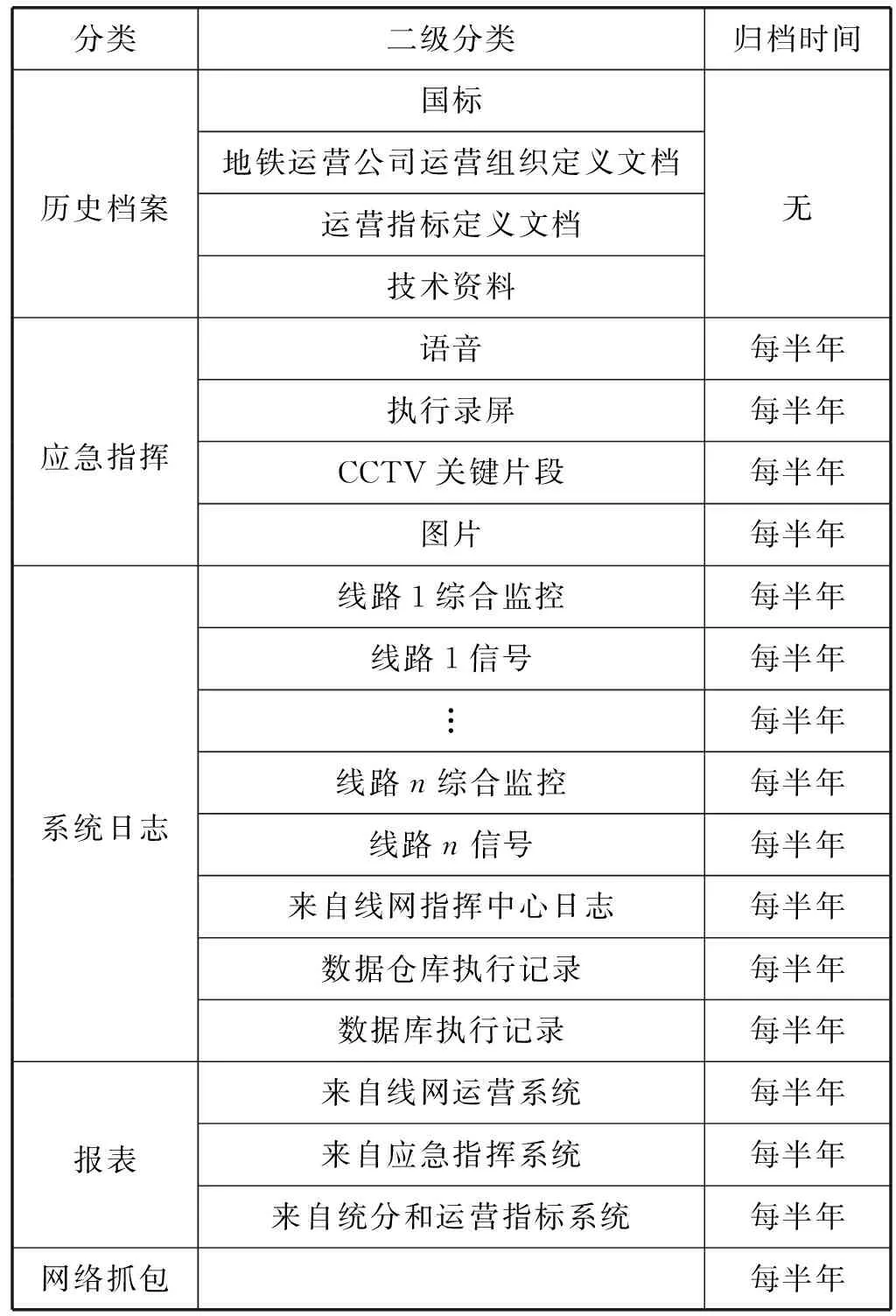
表1 非結構化數據分類方法
4 結 語
數據中心是線網指揮中心的重要組成部分,有效利用線網中生成的海量數據,提高軌道交通的運營管理水平,幫助地鐵企業充分發掘潛在的數據價值,是線網指揮中心的重要功能。
Hadoop平臺具有廉價、靈活、易擴展等特點,將在線網數據中心得到廣泛應用。本文將Hadoop平臺應用于軌道交通線網數據中心,在數據建模和數據存儲方面的獨特之處做了介紹。概括說來就是時序數據的標準化,以及以維度建模為主,采用空間換時間的方法,用寬表和冗余存儲方法來獲得高效的數據查詢和數據分析結果。本文描述的建模和存儲方法,在實際搭建軌道交通大數據中心平臺的驗證過程中,滿足了實時性和大批量存儲的要求,取得了令人滿意的效果。
