基于L1-L2聯(lián)合范數(shù)約束的中藥近紅外光譜波長選擇
2018-12-13 09:15:10李四海
計(jì)算機(jī)應(yīng)用與軟件 2018年12期
任 真 李四海
(甘肅中醫(yī)藥大學(xué)信息工程學(xué)院 甘肅 蘭州 730000)
0 引 言
中藥具有物質(zhì)成分多、作用機(jī)理復(fù)雜等特點(diǎn),保證中藥產(chǎn)品質(zhì)量的可靠穩(wěn)定是實(shí)現(xiàn)中藥現(xiàn)代化必須要解決的關(guān)鍵問題。近紅外光譜分析技術(shù)是20世紀(jì)90年代以后迅速發(fā)展起來的一種新型在線檢測技術(shù),具有簡便、低成本、不破壞樣品等優(yōu)點(diǎn),已在農(nóng)業(yè)、食品、石油化工、藥物質(zhì)量控制等領(lǐng)域得到廣泛應(yīng)用。在中藥質(zhì)量控制方面,近紅外光譜能夠快速、準(zhǔn)確地鑒別中藥材的真?zhèn)巍⒎N類和產(chǎn)地,并且能夠快速測定中藥材中有效成分的含量以及中藥輔料的品質(zhì)[1-2]。
近紅外光譜信號具有維度高、變量多重共線性嚴(yán)重等特點(diǎn)[3]。文獻(xiàn)[4]用隨機(jī)蛙跳算法(Random-frog)對生物柴油近紅外光譜進(jìn)行波長選擇,分別建立了生物柴油含水量的偏最小二乘和支持向量機(jī)預(yù)測模型,取得了較好的效果。文獻(xiàn)[5]建立了金銀花醇沉過程中綠原酸含量的偏最小二乘回歸模型,通過競爭自適應(yīng)抽樣CARS變量選擇方法,提高了模型的預(yù)測精度。以上研究表明,基于波長變量選擇的近紅外光譜建模方法能夠有效提高模型的預(yù)測能力。
現(xiàn)有的波長變量選擇方法大多是封裝式的:通過遍歷搜索,找到變量空間的最優(yōu)特征子集,使模型的均方根誤差最小。由于特征子集的搜索采用前向、后向或蒙特卡洛隨機(jī)搜索策略,對每一個特征子集的評價(jià)都需要重新訓(xùn)練模型,計(jì)算開銷較大。嵌入式特征選擇是機(jī)器學(xué)習(xí)中一類重要的特征選擇方法,其通過最小化目標(biāo)函數(shù),使得特征選擇和模型訓(xùn)練融為一體,同步完成,由于L1范數(shù)的稀疏特性,嵌入式特征選擇能夠自動實(shí)現(xiàn)變量選擇,降低模型的過擬合風(fēng)險(xiǎn),提高模型的可解釋性。
本文通過在偏最小二乘回歸模型中同時(shí)引入L1和L2正則項(xiàng),建立一種嵌入式的光譜特征變量選擇方法。將光譜變量選擇和預(yù)測模型的建立融合在一起,解決光譜數(shù)據(jù)存在的多重共線性問題,提高了偏最小二乘回歸模型的可解釋性,實(shí)現(xiàn)了對當(dāng)歸中藁本內(nèi)酯含量的快速、準(zhǔn)確檢測。
1 正則偏最小二乘回歸算法設(shè)計(jì)
1.1 L1正則與稀疏性
正則化具有產(chǎn)生稀疏模型的能力[6-9],Tibshirani[10]提出的線性回歸Lasso模型通過將嶺回歸中的L2正則項(xiàng)替換為L1正則項(xiàng),使模型具有變量選擇和數(shù)據(jù)降維能力。
假設(shè)自變量矩陣X∈Rn×p,因變量Y∈Rn×1,線性回歸的Lasso模型為:
(1)
式中:‖·‖2表示L2范數(shù),β為回歸系數(shù)向量,‖β‖1表示所有回歸系數(shù)的絕對值之和,為L1范數(shù)罰,λ為懲罰系數(shù)。Lasso模型的解可通過坐標(biāo)下降算法求得[11]:
對于i=1,2,…,p

1.2 偏最小二乘回歸
偏最小二乘回歸(PLSR)是主成分分析(PCA)和典型相關(guān)分析(CCA)的有效結(jié)合,其對CCA方法進(jìn)行了進(jìn)一步拓展。PLSR能有效解決高維變量之間的多重共線性問題,在近紅外光譜的定量分析中得到了廣泛應(yīng)用[14]。
假設(shè)X和Y分別為光譜數(shù)據(jù)矩陣和待測含量矩陣,X∈Rn×p,Y∈Rn×q,X和Y的每一列均為零均值且標(biāo)準(zhǔn)差為1。
PLSR首先從X和Y中提取第一對主成分u1和t1,滿足:Var(u1)→max,Var(t1)→max,Corr(u1,t1)→max。即u1和t1最大化且二者的相關(guān)性最大化。然后計(jì)算X和Y殘差并根據(jù)殘差繼續(xù)提取下一個主成分。由于各投影方向之間相互正交,抽取的特征位于不同的投影方向,因此偏最小二乘能夠有效去除變量之間的多元共線性。PLSR的最優(yōu)主成分個數(shù)一般通過交叉驗(yàn)證方法確定。
1.3 正則偏最小二乘回歸
近紅外光譜數(shù)據(jù)具有高維度、小樣本的特點(diǎn)。PLSR的投影向量是所有原始波長變量的線性組合,一方面,將部分噪聲變量也納入投影向量參與模型擬合會使有效變量的回歸系數(shù)產(chǎn)生衰減,導(dǎo)致預(yù)測精度下降;另一方面,當(dāng)p>>n,即p遠(yuǎn)大于n時(shí),投影向量包含所有的原始波長變量導(dǎo)致模型可解釋性不強(qiáng)。針對上述問題,在偏最小二乘回歸模型中引入正則項(xiàng),建立正則偏最小二乘回歸RPLS算法,RPLS可形式化為如下的最優(yōu)化問題:
(2)
s.t.αTα=1
式中:η、λ1和λ2均為常量,用于初始化算法,c為主成分載荷系數(shù)向量α的副本且與α取值相近。 式(2)可通過交替迭代算法求解[15]:
1) 固定c,求解α。對固定的c,式(2)變?yōu)椋?/p>
(3)
s.t.αTα=1
令Z=XTY,η′=(1-η)/(1-2η),則式(3)可重寫為:
(4)
s.t.αTα=1
式中的α可通過拉格朗日乘子法求解。
2) 固定α,求解c。對固定的α,式(2)變?yōu)椋?/p>
(5)
問題轉(zhuǎn)化為因變量為ZTα的彈性網(wǎng)問題[16],c可以通過LARS算法求解[17]。

式中:Z1=XTY/‖XTY‖為第一投影方向單位向量。
Step2 當(dāng)k≤K時(shí)

1.4 算法參數(shù)選擇
對于單因變量回歸問題,一般取η=1/2,λ2→∞。因此,算法的關(guān)鍵參數(shù)有兩個:L1正則項(xiàng)系數(shù)λ1和最優(yōu)主成分個數(shù)k。
λ1用于控制選擇的波長變量個數(shù),其值越大,選擇的波長變量數(shù)越少,模型可解釋性越好,但參與建模的變量數(shù)過少會導(dǎo)致模型預(yù)測能力下降。因此,λ1的選取要權(quán)衡稀疏度和模型預(yù)測能力,通過實(shí)驗(yàn)選擇最優(yōu)的λ1值。
最優(yōu)主成分的個數(shù)k通過留一交叉驗(yàn)證法計(jì)算得到的Qk2值來確定[18]。
Qk2= 1-PRESSk/SS(k-1)
(6)
式中:PRESSk為使用前k個主成分對預(yù)留樣本預(yù)測誤差的平方和,SS(k-1)為使用前k-1個主成分對所有樣本擬合誤差的平方和。當(dāng)Qk2≥0.097 5時(shí),認(rèn)為第k個主成分作用顯著。
2 模型的建立
2.1 實(shí)驗(yàn)數(shù)據(jù)
采集甘肅不同產(chǎn)地的當(dāng)歸樣本76個,使用美國Thermo公司的Nicolet-6700型近紅外光譜儀掃描得到所有樣本的近紅外光譜,光譜范圍為4 000 cm-1~10 000 cm-1,全譜共包括1 557個波數(shù)變量。76個當(dāng)歸樣本的近紅外光譜如圖1所示。

圖1 當(dāng)歸樣本的近紅外光譜
為消除基線漂移并提高光譜信號的信噪比,對原始光譜進(jìn)行一階導(dǎo)數(shù)結(jié)合正交信號校正預(yù)處理。當(dāng)歸中藁本內(nèi)酯的含量采用高效液相色譜法(HPLC)測定[19]。
2.2 波長變量選擇
將樣本劃分為訓(xùn)練集和測試集,訓(xùn)練集樣本56個,測試集樣本20個。使用訓(xùn)練集建立正則偏最小二乘回歸模型對當(dāng)歸近紅外光譜進(jìn)行波長變量選擇,因變量為當(dāng)歸中的藁本內(nèi)酯含量。訓(xùn)練集和測試集中藁本內(nèi)酯含量的分布情況見表1。

表1 訓(xùn)練集和測試集中藁本內(nèi)酯含量分布
實(shí)驗(yàn)中用eta參數(shù)控制變量選擇個數(shù)和模型稀疏度,對eta和k的最優(yōu)組合采用網(wǎng)格尋優(yōu)法確定。設(shè)定主成分k的搜索范圍為[2,8],步長為1,eta的搜索范圍為[0.7,0.9],步長為0.1。最優(yōu)波長變量子集通過權(quán)衡訓(xùn)練集上的預(yù)測均方根誤差和波長變量個數(shù)來最終確定。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 波長變量選擇結(jié)果
根據(jù)主成分?jǐn)?shù)k和參數(shù)eta的搜索范圍,共得到21個波長變量子集,分別建立以上變量子集在56個訓(xùn)練樣本上的偏最小二乘回歸模型。不同變量子集在測試集上的預(yù)測結(jié)果對比如圖2所示。

圖2 k和eta對選擇波長變量個數(shù)的影響
從圖2可知,主成分個數(shù)k和eta對選擇的波長變量個數(shù)都會產(chǎn)生影響,變量個數(shù)隨著k的增加而增加,其中eta參數(shù)對變量個數(shù)的影響較大,eta值越大,選擇的波長變量個數(shù)越少。當(dāng)eta為0.7時(shí),選擇變量個數(shù)最少為100個,最多為119個,模型的擬合效果很好,但參與建模的變量過多,模型的可解釋性不強(qiáng)。當(dāng)eta為0.8時(shí),選擇變量個數(shù)最少為42個,最多為67個,此時(shí)選擇的變量仍然過多。當(dāng)eta為0.9時(shí),選擇變量個數(shù)最少為15個,最多為22個。綜合考慮選擇變量個數(shù)和模型的預(yù)測能力,本文選擇eta=0.9,k=3為最優(yōu)參數(shù),此時(shí)共選擇16個波長變量。分別為5 164.4 cm-1、5 218.4 cm-1、5 222.3 cm-1、5 226.1 cm-1、5 230.0 cm-1、5 233.9 cm-1、5 237.7 cm-1、5 241.6 cm-1、5 245.4 cm-1、5 249.3 cm-1、5 253.1 cm-1、5 257.0 cm-1、5 260.9 cm-1、5 704.4 cm-1、5 708.3 cm-1、 5 712.1 cm-1。根據(jù)近紅外光譜的特征峰理論,所選擇的波數(shù)大多位于C=O基團(tuán)的伸縮振動吸收峰附近,與當(dāng)歸中的內(nèi)酯類化合物有關(guān),這說明所選擇的波長變量具有較好的化學(xué)意義。
3.2 不同預(yù)測方法結(jié)果對比
使用RPLS選擇的16個波長變量,在56個訓(xùn)練樣本上建立偏最小二乘回歸模型,取前3個主成分。對20個測試樣本中的藁本內(nèi)酯含量的預(yù)測結(jié)果見圖3。
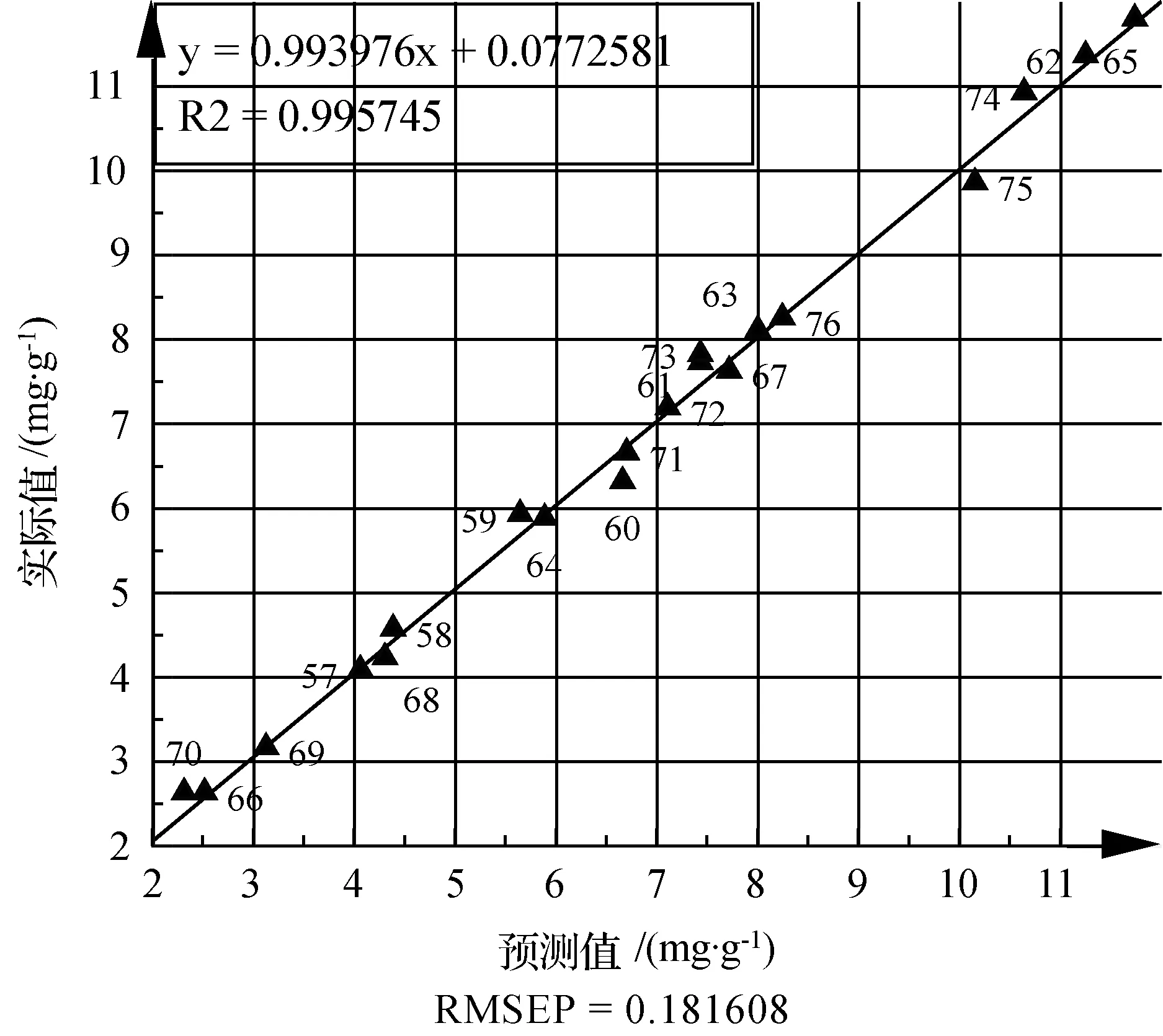
圖3 藁本內(nèi)酯預(yù)測值和實(shí)際值對比
從3可以看出,預(yù)測值和真實(shí)值之間非常接近,預(yù)測均方根誤差RMSEP(root mean square error of prediction)為0.181 6,決定系數(shù)為0.995 7。RMSEP的計(jì)算公式如下:
(7)
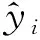
為進(jìn)一步說明本文波長變量選擇方法的有效性,將RPLS與目前近紅外光譜分析中常用的CARS、Random-frog等波長變量選擇方法進(jìn)行了對比分析。CARS算法迭代次數(shù)為1 200次,5折交叉驗(yàn)證,從1 200個子模型中選擇交叉驗(yàn)證均方根誤差最小的模型。Random-frog算法變量迭代次數(shù)為1 000次,實(shí)驗(yàn)中迭代達(dá)到200次時(shí)選擇的變量結(jié)果基本穩(wěn)定。根據(jù)三種方法所選擇的變量,分別建立PLSR模型,表2對比了不同的波長變量選擇方法的預(yù)測性能。

表2 不同變量選擇方法的預(yù)測結(jié)果對比
從表2可以看出,與全譜建模相比,根據(jù)CARS和隨機(jī)蛙跳選出的重要變量建模,能夠獲得與全譜建模相當(dāng)?shù)念A(yù)測性能。但隨機(jī)蛙跳需要預(yù)先設(shè)置種子變量,然后采用蒙特卡洛抽樣技術(shù),將其他波長變量依次添加到種子變量中形成不同的變量子集,根據(jù)均方根誤差確定最優(yōu)的波長變量子集,其迭代次數(shù)和變量選擇結(jié)果均依賴于種子變量初始值,算法的計(jì)算開銷較大。與CARS和隨機(jī)蛙跳相比,RPLS波長變量選擇方法通過設(shè)置eta和k的值來控制變量選擇個數(shù),并不是以變量子集的預(yù)測均方根誤差來衡量變量子集的優(yōu)劣,而是在變量稀疏性和預(yù)測能力之間取得折中,方法更為穩(wěn)健。RPLS方法選擇的波長變量數(shù)最少,預(yù)測性能優(yōu)于CARS和隨機(jī)蛙跳,且所選擇的變量具有較好的化學(xué)意義,模型可解釋性較好。
4 結(jié) 語
通過在偏最小二乘回歸模型中引入L1和L2范數(shù)罰正則項(xiàng),建立了正則偏最小二乘波長選擇方法。該方法能夠?qū)⒔t外光譜中噪聲變量在主成分上的載荷系數(shù)置為0,保留有效變量,達(dá)到選擇重要變量的目的。與CARS和隨機(jī)蛙跳變量選擇方法相比,RPLS變量選擇方法在選擇的波長數(shù)、模型的預(yù)測精度及可解釋性等方面均具有一定優(yōu)勢。
本文提出的正則偏最小二乘波長選擇方法對噪聲變量和有效變量施加相同的懲罰,對主成分載荷系數(shù)的估計(jì)是有偏估計(jì)。如何減弱甚至消除對有效變量的懲罰,得到載荷系數(shù)的近似無偏估計(jì),提高近紅外光譜波長變量選擇的針對性將是下一步的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
