基于數據用語智能分詞技術的數據關聯方法
2018-12-12 19:31:54張新陽張梅馬文程永新
科技傳播 2018年22期
張新陽 張梅 馬文 程永新
摘 要 當前數據資產梳理以及數據標準建立過程中,對其中所遇到的數據命名不統一、中文語義復雜、難以建立數據關聯等難點問題進行分析,提出了一套基于中文智能分詞及大數據字符串分析技術的數據用語標準建立方法以及建立數據關聯的方法。通過將該方法應用的數據資產管理項目中,實現了對某企業45套業務系統,10萬多張表、70余萬數據字段以及數百個業務接口的全自動梳理,建立了跨業務系統的數據標準體系和數據關聯地圖,為企業的數據資產進一步分析、挖掘、變現提供了有利支撐。
關鍵詞 數據治理;數據關聯;智能分詞;數據標準
中圖分類號 TP3 文獻標識碼 A 文章編號 1674-6708(2018)223-0121-03
隨著IT技術的發展,未來10年內,數據將成為一個重要的財富創造來源,并且將越來越多地被視為一項值得重視的企業資產,數據資產日益成為企業的重要利潤潛力增長點。為此,各企業急需梳理沉淀十數年以來各業務系統的數據,希望從中整理出屬于數據資產的有價值數據,并面向數據應用建立起相應的數據模型,為大數據平臺的數據分析和數據挖掘提供支撐服務,麥肯錫認為“大數據是指其大小超出典型數據軟件抓取、儲存、管理和分析范圍的數據集合”。在創建和應用大數據的這個過程中,以下這些問題尤為凸顯,成為數據資產梳理的難點。
1)企業內各業務平臺系統建設跨越時間長,系統復雜,且由多個項目實施建成。IT系統的建設目標以實現業務需求為首要目標,未考慮后期的數據集成需要。因此各業務平臺系統中存在對同一個業務術語的不同定義形式,造成跨系統的數據難以建立關聯,甚至同一業務系統中都存在對相同業務術語的不同定義。
2)雖然企業已經開始對數據標準體系做建設,但是針對既有業務系統,出于經濟考慮,不可能做大面積的重構處理,只能對新上線系統做規范化要求。而大量的對企業有重要價值的數據資產是沉淀在原有業務系統中的,如何將數據標準與現有系統中的數據做關聯成為一個難點問題。
3)中文語言的博大精深,一方面豐富了人們的語言表達,但也因此存在大量的近似用語。不同環境背景下的語言和組詞均有差異,這也是造成制訂數據標準困難的主要原因,難以形成一套適應所有環境的統一數據標準體系。
以上問題在建立企業內部或跨行業的數據標準體系并盤活現有企業數據資產時成為數據管理者所面臨的難點,如何建立不同業務系統,甚至不同行業之間的數據標準體系,并將數據標準應用到既有系統,成為建立跨系統的數據集成平臺所需跨越的鴻溝。
1 正文
本文基于中文的智能分詞技術,論述一種基于數據標準用語智能分詞的跨系統數據關聯梳理方法,并說明應用此方法的梳理展現效果。
1.1 梳理數據用語字典
數據梳理的第一步是建立起企業內或行業內業務術語的數據用語字典。數據用語字典包括數據庫中的表名用語、字段名用語、系統的接口用語、報表中的指標用語等。用語的來源可以是系統建設時的需求規范、設計規范、接口規范等文檔,也可以從現有系統的表結構逆向采集獲取。用語字典的形式可以用如下形式體現,如圖1。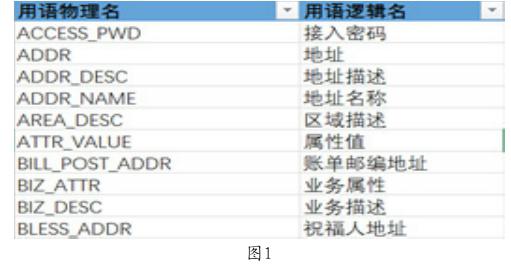
用語物理名是用語在數據庫字段或數據庫表命名時的體現,而用語邏輯名是具備某個特定業務術語描述的中文體現。
這個數據用語字典,將是我們要作為跨系統數據關聯的數據基礎。
1.2 建立數據用語單詞庫
對于已建立的數據用語字典,其用語的定義是面向某個具體的業務術語的描述,其中包含了一個或多個中文詞語。
通過智能分詞技術,可以實現將用語自動拆分為多個詞語的組合。例如“年收入額”可以拆分為“年”和“收入”“額”三個有具體涵義的字或詞語,拆解出的詞語或字,可以命名為詞素或單詞。
收集整理拆分出的單詞或詞素,可以得到一個涵蓋行業或者企業所有業務系統的用語單詞庫。其展現形式如圖3。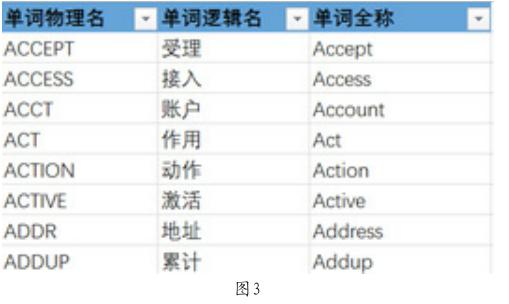
單詞物理名為一個詞語在業務系統中使用時的名稱,用語數據庫表、字段、接口、接口屬性、口徑等定義使用。單詞邏輯名作為一個詞語的中文名稱,用語面向用戶的可視化涵義展現,單詞全稱作為中文名稱的英文全名備注。
1.3 建立單詞同義詞庫
建立上述步驟的用語單詞庫后,分析發現對于每個詞語在語言使用都可以存在多個同義詞或近義詞,又或者同一個單詞的邏輯名存在多個不同的單詞物理名的情況。在不同的業務系統中,由于系統設計開發人員的習慣不同,造成其使用的名稱不一致。例如“額”這一業務術語,在某些業務系統中可能會命名為“金額”,“管理員”這一詞語,在另一系統中也可能定義為“管理者”,而同一個單詞“區域”,有些系統會命名其物理名為“AREA”,而另一些系統可能會命名為“ZONE”或“REGION”。這些都會造成不同的系統的使用人員或數據分析人員在數據集成時數據無法直接建立關聯。
實現不同系統之間能對具有同樣含義的詞語建立起關聯,需要將每個詞語可能存在的同義詞或近義詞進行整理。這一步驟可以借助于行業專業詞典以及同義詞典等工具書籍的電子版本,通過大數據分析技術獲取單詞庫中各單詞的同義詞列表。如圖4的物理名同義詞列表。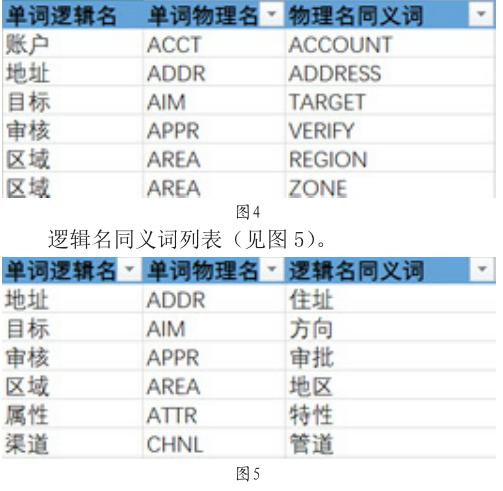
1.4 推舉數據標準單詞
當一個業務在各業務系統中或行業中有規范做數據標準定義時,可以將行業規范作為數據標準的來源。但目前有很多行業或企業并無統一規范的數據標準定義,而各業務系統也在各自的專屬功能領域運行上10年之久,如何形成一套符合絕大多數人習慣的標準術語描述則成為一大難點。
基于前面所述的數據用語單詞庫以及單詞同義詞庫,可以建立起在用語單詞中的同義詞關聯關系。當一個單詞具有多各同義詞時,通過檢索這個單詞及同義詞在所有業務系統中的用語使用次數,獲取應用得最多的一個詞語,并將此詞語作為暫定數據標準單詞,而具有同義詞含義的其他單詞則作為此數據標準單詞的同義詞。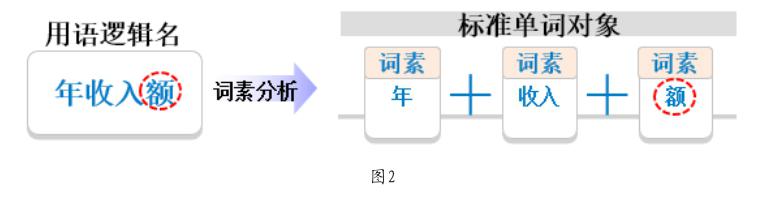
1.5 建立數據標準用語檔案庫
數據標準單詞確定后,可以將前面梳理出的系統中使用的用語字典做標準化處理。將用語智能分詞為單詞,對每個單詞獲取其標準化單詞后,重新組裝為符合數據標準定義的用語,其過程如圖6所示。
1.6 建立數據關聯
通過建立數據標準用語檔案庫,也可以得到每個用語與數據標準用語之間的對應關系。當存在多個系統中的不同用語對應同一個數據標準用語時,可以認定這兩個用語不管是不是在同一個業務系統中,其數據應具備相關性,具備數據關聯分析及進一步關聯數據挖掘使用的價值。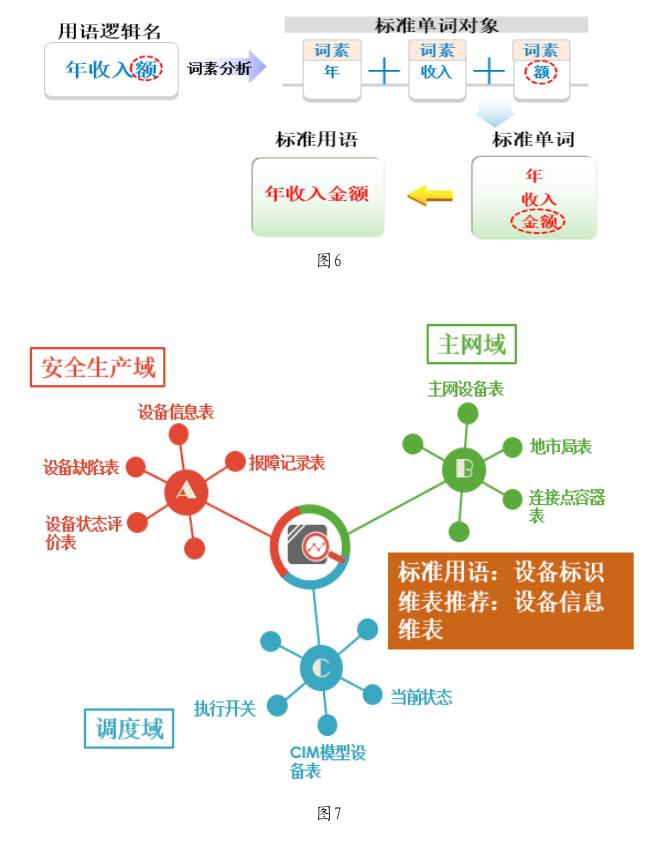
2 結論
隨著電力業務集約化、精益化、標準化的要求越來越高和信息化支撐能力的不斷提升,數據治理已成為電力企業信息系統集中建設(一級部署)、大數據應用、智能分析決策應用的重要基石。企業在進行跨業務系統數據梳理時,面對大量沉淀數據往往不知如何下手,各數據的命名規范性問題作為長期影響企業進一步挖掘數據價值的攔路虎存在,本文應用當前已經成熟的大數據字符串處理技術以及中文智能分詞技術,將系統中原本需要靠繁重的人工識別的數據關聯,賦予系統自動化處理的能力,能夠大幅提升數據資產梳理的效率,減少人工成本,為挖掘各業務系統中的健在數據資產價值提供有力的幫助。
參考文獻
[1]張志剛,楊棟樞,吳紅霞.數據資產價值評估模型研究與應用[J].現在電子技術,2015,38(20):44-51.
[2]Gartner.Top ten strategic technology trend for 2012[EB/OL].[2011-11-05].http://www.gartner.com.
[3]巨克真,魏珍珍.電力企業級數據治理體系的研究[J].電力信息與通信技術,2014,12(1):7-11.
[4]成于,思施云濤.面向專業領域的中文分詞方法[J].計算機工程與應用,2018,54(17):30-34,109.
[5]張生,杰霍丹.基于語義信息的中文分詞研究[J].電腦知識與技術,2018,14(22):184-186.
