基于Faster R-CNN的榆紫葉甲蟲識別方法研究
2018-12-04 02:13:50董本志聶麗酈景維鵬
計算機工程與應用 2018年23期
董本志,聶麗酈,景維鵬,崔 航
東北林業大學 信息與計算機工程學院,哈爾濱 150040
1 引言
榆樹是東北地區常見樹種,也是重要的經濟樹種和觀賞樹種,但在其生長過程中經常受到害蟲侵擾。準確識別害蟲判別災害情況,對有效治理蟲災有重要意義,利用圖像處理方法可有效對其進行識別。
目前利用圖像處理對昆蟲進行識別的方法為:先使用圖像去噪[1]、圖像分割等[2]方法對圖像進行預處理,然后采用灰度直方圖[3-4]、隨機森林算法[5]、方向梯度直方圖(Histogram of Oriented Gradient,HOG)[6]、詞袋算法(Bag of Words,BOW)[7-8]等算法提取圖像的特征,最后將提取到的特征送入支持向量機(Support Vector Machine,SVM)[9]、前饋神經網絡(Back Propagation,BP)[10]、自組織映射網絡(Self Organizing Map,SOM)[11]等分類器中,對提取到的特征信息進行分類表達。但上述識別方法均需人為參與到特征提取模板和特征提取算法的設計中,往往加入了先驗知識,具有很強的主觀性,影響分類器的判斷。同時,針對昆蟲這種目標小、紋理特征多樣、結構豐富、姿態多樣、種間相似度高的目標[12],很難人工設計出有效描述昆蟲典型特征的模板與算法。
深度學習模型由數據直接驅動特征的提取,可以利用像素之間的位置特征,自主學習出數據間許多容易被人忽視的潛在特征,有效解決了特征提取模板針對性不強的問題。深度學習模型中卷積神經網絡在圖像處理方面有較廣泛的應用,如漢字識別驗證碼[13]、道路中車輛識別[14]等。目前最成熟且應用最廣泛的深度卷積神經網絡模型Faster R-CNN[15]將目標檢測的候選區域生成、特征提取、分類、位置精修四個步驟統一到一個深度網絡架構之內,形成了統一的體系結構。識別復雜背景中的目標時具有很好的魯棒性和很強的辨別待識別物體間的細微差別的能力。同時,利用數據自主驅動模型提取特征,有效克服了傳統識別分類方法中依賴于人工設計特征提取模板的局限性,可較好地識別出自然環境中復雜背景下的目標,因此本文采用Faster R-CNN網絡對榆紫葉甲蟲進行框定。但是標準Faster R-CNN網絡模型是針對標準數據集VOC2007的20分類任務設計的,生成的初始候選框為固定的三種尺寸、三種比例,用其識別榆紫葉甲蟲時,初始候選框的長寬比不符合榆紫葉甲蟲的長寬比形態學特征,容易造成候選框冗余過大。加之榆紫葉甲蟲的甲殼反光,在框定榆紫葉甲蟲目標時會出現誤差,在榆紫葉甲蟲和榆樹葉片豁口或孔洞相鄰時或者兩只榆紫葉甲相鄰時框定誤差尤其嚴重。因此,本文使用Faster R-CNN模型識別榆紫葉甲蟲時,對初始候選框生成網絡進行改進,使其生成的初始候選框更加貼合榆紫葉甲蟲本身的特征,減少周圍復雜環境造成的影響,以提高識別精度。
2 基于K-means聚類算法的Faster R-CNN網絡模型
為得到符合榆紫葉甲蟲長寬比形態學特征的初始候選框,可以用聚類算法對樣本的長寬值進行統計,得出最理想的候選框長寬比。目前常用的幾種聚類算法有K-means聚類、層次聚類、SOM聚類、FCM聚類。其中K-means聚類算法是基于距離的聚類算法,使聚類后每個子類內的點到當前類中心點的距離之和最小,符合本文的聚類需要。本文以最小化子類內的點到當前類中心點距離之和為目標函數,通過計算評價聚類結果中各子類的類內緊密程度與類間分離程度關系的BWP(Between-Within Proportion)指標來確定最佳聚類中心點個數kopt,對n個榆紫葉甲蟲訓練樣本矩形標簽的長寬比值X{x1,x2,…,xn}進行聚類。這里kopt的計算方法見公式(1)。
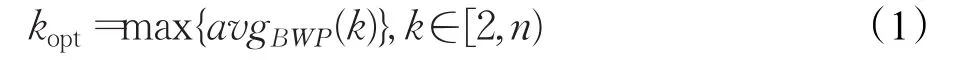
令聚類中心點個數k在[2,n)內循環,計算各k值對應的所有樣本的BWP值的平均值avgBWP(k),kopt的值取令avgBWP(k)最大值時對應的k值,計算方法見公式(2)。
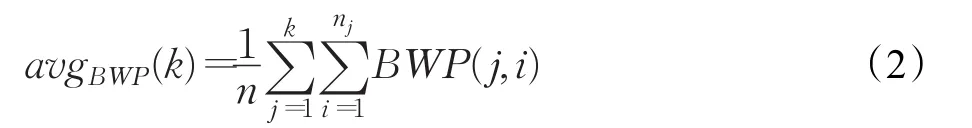
其中BWP(j,i)是最小類間距離和類內距離的衡量指標,其計算方法見公式(3)。
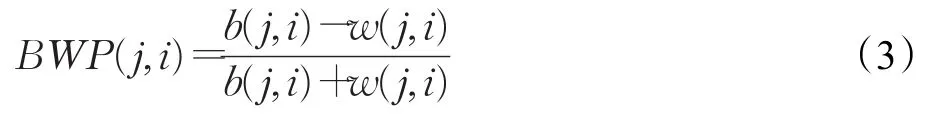
公式(3)中b(j,i)為最小類間距離,是第 j類中第i個樣本到其他每個類中樣本的平均距離最小值,其計算方法見公式(4);w(j,i)為類內距離,是第 j類中第i個樣本到其第 j類中其他所有樣本的平均距離,其計算見公式(5)。
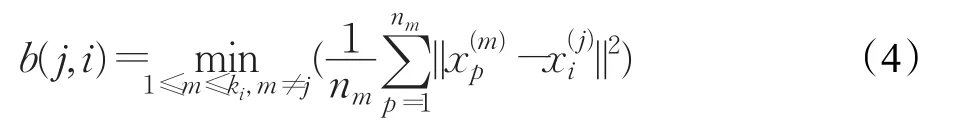
其中 j∈[1,ki],i∈[1,nj]。nj為第 j類的樣本數;m和j表示類標;表示第 j類的第i個樣本;表示第m類的第 p個樣本;nm表示第m類的樣本數;表示平方歐氏距離。
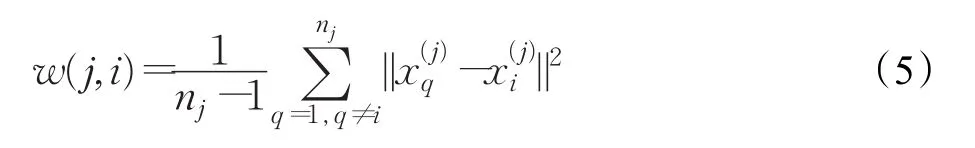
其中nj表示第 j類的樣本數,表示第 j類的第q個樣本。
通過計算得到kopt的值后,可同時得到kopt個聚類中心點,可以用集合A={A1,A2,…,Akopt}表示。A中的元素可以用來代替標準網絡生成的初始候選框的長寬比值0.5、1、2,生成更加符合榆紫葉甲蟲長寬比形態學特征的初始候選框,減少框定誤差。
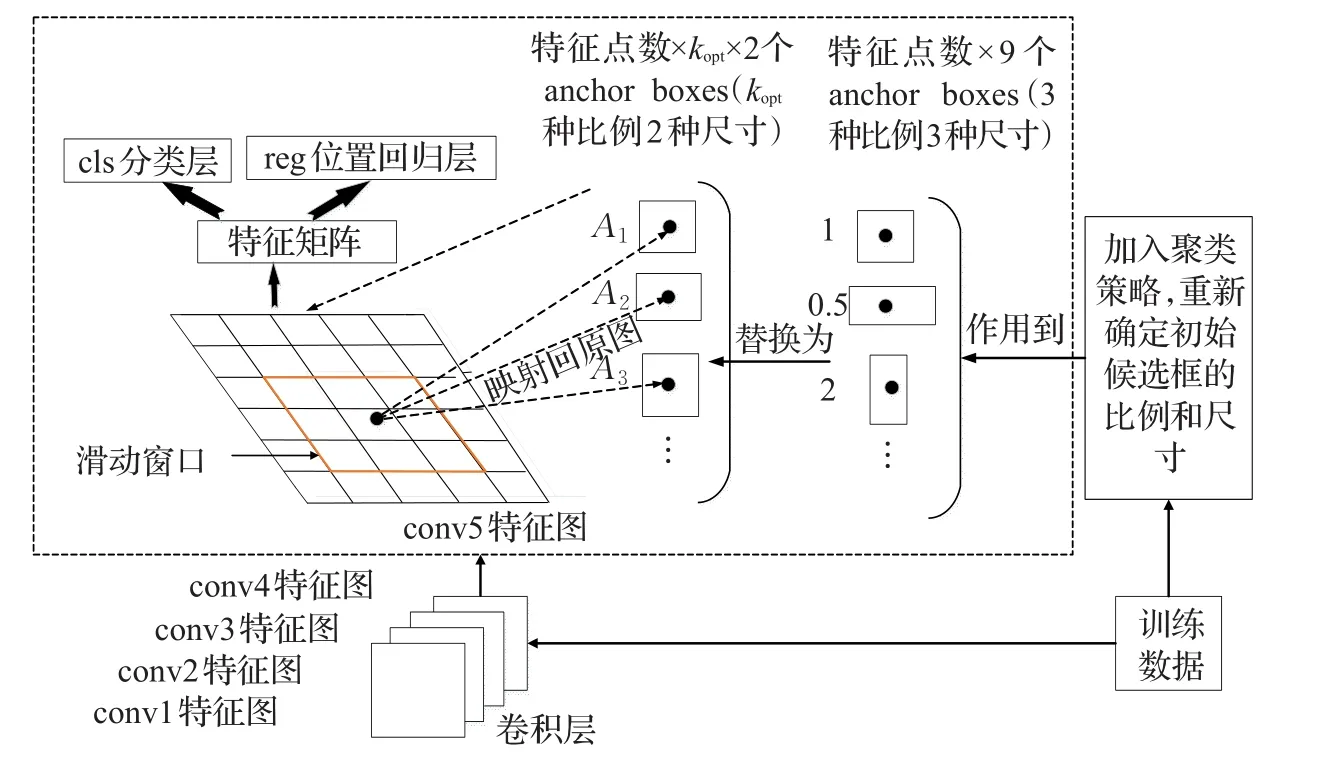
圖1 改進的Faster R-CNN網絡示意圖
調整了初始候選框的生成比例后,進一步對初始候選框的生成尺寸進行調整。標準網絡生成的初始候選框的三種尺寸固定為1282,2562,5122,但是由于榆紫葉甲蟲的尺寸相對于VOC2007標準數據集中的飛機、汽車、馬等目標類別的尺寸來說占據整張圖像比例很小,屬于小目標。而5122這種尺寸對于榆紫葉甲蟲來說冗余過大,導致位置精修時的初始候選框邊框平移量過大,容易造成框定不準。因此,本文舍棄這種尺寸的候選框,以提高檢測的準確率。
改進的Faster R-CNN網絡示意圖如圖1所示。
改進主要涉及到初始候選框生成文件generate_anchor.py和候選框層文件proposal Layer.py。首先,在proposal Layer.py文件中的類proposal Layer(Caffe.Layer)里根據公式(1)~(5)定義一個用來對訓練數據集標簽長寬比值進行聚類的函數K_means,返回值為kopt和{A1,A2,…,Akopt}。然后,將兩個返回值傳給generate_anchor.py文件中的generate_anchors函數,用{A1,A2,…,Akopt}代替標準網絡中候選框生成比例0.5、1、2。其中generate_anchors函數根據傳入的參數生成生成conv5特征圖上的特征點數×kopt×2個初始候選框。在對網絡進行訓練前,先對訓練樣本矩形標簽的長寬比值進行聚類,并對生成初始候選框的面積加以調整。這樣在Faster R-CNN網絡后面的全連接層部分,在分類層得分大于0.6的初始候選框會進入后面的位置回歸層進行候選框的四個邊框的精修。由于改進后的Faster R-CNN網絡模型生成的初始候選框更加符合榆紫葉甲蟲本身的形態學特征,所以初始候選框四周冗余較標準網絡生成的初始候選框少。對初始候選框四邊框精修時,四個邊框從初始位置平移到標準位置時的平移量較少,使得復雜背景對框定的干擾較少,從而能夠更加準確地判定出邊框精修的終止位置,達到更為準確的對目標榆紫葉甲蟲進行框定的目的。
3 實驗
3.1 實驗環境
本文實驗軟件平臺采用linux Ubuntu 16.04 LTS系統、label Image 1.3.2、pycharm 2.7.3、openCV 2.4.6,硬件環境是4 GB內存,Intel?Core?i5-5450M CPU@2.50 GHz,主頻3.4 GHz的計算機。
3.2 實驗數據
實驗數據采集地點為東北林業大學帽兒山實驗林場,以其30~40年生的大葉榆、大果榆、裂葉榆、春榆等榆樹上榆紫葉甲蟲為研究對象。拍攝到3 000張像素大小為4 000×6 000的圖片數據。對數據集進行篩選以避免錯誤、重復和模糊的圖像并人工標注,同時按照7∶1∶2的比例隨機抽取訓練數據集、驗證數據集、測試數據集。
3.3 實驗結果及分析
根據本文樣本數據集得出聚類中心數kopt=3,中心點分別為A1=0.64、A2=0.99、A3=1.27。用三個新的生成初始候選框的長寬比值代替標準網絡的生成初始候選框的長寬比值0.5、1、2,網絡改進前后的初始候選框生成的尺寸和比例框圖如圖2所示。其中,圖2(a)為按照標準初始候選框生成比例和尺寸規則生成的候選框情況,圖2(b)為加入聚類策略和調整了初始候選框的尺寸的網絡的生成候選框情況。兩圖均為以O點為中心生成的候選框,圖2(a)中的三個藍色框為最大尺寸的三種比例候選框,三個紅色框為中間尺寸的三種比例候選框,三個黃色框為最小尺寸的三種比例的候選框。

圖2 網絡改進前后的初始候選框生成比例和尺寸框圖
從圖2中可以看出,藍色候選框尺寸對于榆紫葉甲蟲來說冗余過大,在后面全連接層精修回歸過程中易受復雜背景中諸多特征的干擾,造成誤圈。紅色框和黃色框的長寬比例不符合榆紫葉甲蟲本身的長寬比形態學特征,在邊框精修時四個邊框平移的位移過大,易受復雜背景的干擾。在某一局部區域計算的損失小于規定閾值時就會停止回歸,造成邊框平移中斷或者平移過大,出現框定過大或者過小的情況。圖2(b)中去掉了藍色尺寸的三種比例的候選框。同時,針對紅色框和黃色框的情況,在相同尺寸下利用聚類生成新的初始候選框的長寬比,使其更加符合榆紫葉甲蟲本身的生物學特性。在后面的回歸過程受復雜的背景影響較小,可排除大部分復雜背景干擾圈定更為準確。
榆紫葉甲蟲和葉片豁口或孔洞相鄰時,標準網絡模型與加入聚類策略和調整了生成候選框尺寸Faster RCNN網絡輸出結果對比圖如圖3所示。其中,圖3(a)~(e)為標準網絡的檢測效果圖,圖3(f)~(j)為改進后的網絡輸出結果圖。圖3(a)與(f)、(b)與(g)、(c)與(h)、(d)與(i)、(e)與(j)分別為同一張圖像的兩個模型的輸出結果。圖中黃色圓圈部分為和榆紫葉甲蟲相鄰的葉片豁口或孔洞。
從圖3(a)~(e)可以看出,由于榆紫葉甲蟲的形狀、顏色等特征與葉片豁口相似,會出現框定榆紫葉甲蟲范圍時將臨近的葉片豁口也框定進去,造成框定范圍冗余的現象。并且由于榆紫葉甲蟲的甲殼反光,標準模型會將一部分榆紫葉甲蟲識別為背景,出現框定不全的現象。而改進后的網絡模型,減少了葉片豁口對榆紫葉甲蟲框定結果的影響,框定范圍比較準確,如圖3(f)~3(j)所示。實驗結果證明,經過對生成初始候選框網絡的改進,在框定有葉片豁口干擾的榆紫葉甲蟲圖片時,取得了優于標準候選框的效果。
相鄰榆紫葉甲蟲框定結果對比,如圖4所示。其中,圖4(a)~(e)為標準網絡的檢測效果圖,圖4(f)~(j)為改進候選框生成網絡的輸出結果圖。圖4(a)與(f)、(b)與(g)、(c)與(h)、(d)與(i)、(e)與(j)分別為同一張圖像的兩個模型的輸出結果。
從圖4中可以看出,圖4(a)將兩只榆紫葉甲蟲框定到一起;圖4(b)中將一只榆紫葉甲蟲包含于另一只的范圍內;圖4(c)中兩只榆紫葉甲蟲范圍均未框定完全;圖4(d)中框定的榆紫葉甲蟲范圍冗余過大;圖4(e)中的兩只榆紫葉甲蟲范圍均未圈定完全。這是由于兩只榆紫葉甲蟲特征相似且位置相臨,相似的特征對框定結果造成干擾,而改進候選框生成網絡模型有效的解決了標準網絡模型出現的問題,如圖4(f)~(j)。由此可見,在兩只榆紫葉甲蟲相鄰的情況中,改進后的網絡比標準網絡框定效果更好。

圖3 榆紫葉甲蟲和葉片豁口或孔洞相鄰時網絡模型改進前后輸出效果對比圖
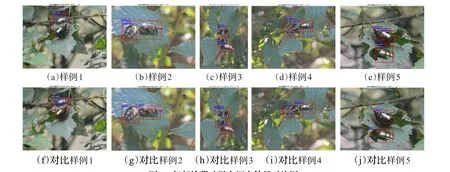
圖4 相鄰榆紫葉甲蟲框定結果對比圖

圖5 候選框生成網絡改進前后的榆紫葉甲蟲和與其特征相似的昆蟲識別效果對比
由于榆樹花甲蟲和盾瘤胸葉甲蟲也是榆樹常見害蟲之一,且和榆紫葉甲蟲形態類似,在采集圖像時很容易采集到這兩種蟲,造成錯誤框定,如圖5所示。其中,圖5(a)~(e)為標準網絡的檢測效果圖,圖5(f)~(j)為改進候選框生成網絡輸出結果圖。圖5(a)與(f)、(b)與(g)、(c)與(h)、(d)與(i)、(e)與(j)分別為同一張圖像的兩個模型的輸出結果,圖5(a)與(f)、(b)與(g)、(c)與(h)為盾瘤胸葉甲,圖5(d)與(i)、(e)與(j)為榆樹花甲蟲。由實驗結果可以看出,標準網絡模型存在誤將與榆紫葉甲蟲形態相似的昆蟲框定出來的現象,而改進候選框生成網絡后的模型不會輸出這樣的結果圖,只將榆紫葉甲蟲框定出來,其余種類的昆蟲將不會框定出來。
分類實驗中,對于結果的處理,一般僅用一種指標很難得到對算法的正確評估的。所以,一般用精準率(Precision,P),召回率(Recall,R)來共同對算法進行評估。衡量的最終指標是識別的平均精度值AP。一般將以召回率和準確率為橫縱軸的PR曲線與兩坐標軸圍成的面積作為衡量指標。
準確率的計算公式如下:

召回率的計算公式如下:

TP(True Positives)是模型預測為正樣本實際為正樣本的特征數量,FP(False Positives)是模型預測為正樣本但實際是負樣本的特征數量。TN(True Nagetives)是模型預測為負樣本實際也為負樣本的特征數量,FN(False Nagetives)是模型預測為負樣本但實際為正樣本的特征數。其中,準確率P指檢索出的榆紫葉甲蟲數量與此次檢索得到的檢測框的數量的比值,衡量的是查準率。召回率R指檢索出的榆紫葉甲蟲數量與數據集中所有榆紫葉甲的數量的比值,衡量的是查全率。因為準確率和召回率不可兼得,本文選擇AP作為衡量實驗效果好壞的指標。將曲線與橫縱坐標圍成的面積作為AP的值。
改進前后模型的PR(Precision-Recall)曲線如圖6所示。
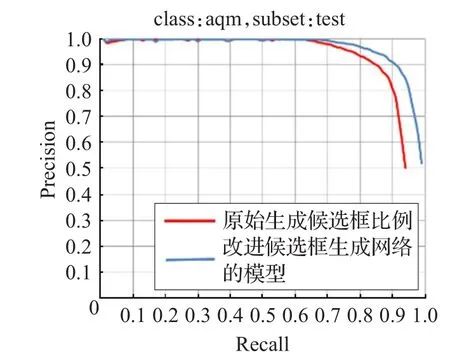
圖6 改進候選框生成網絡模型和標準網絡模型的PR曲線
從圖6中可以看出,改進后的網絡框架測試結果的AP曲線與橫縱坐標軸的面積大于標準框架輸出的測試結果與坐標軸的面積,即改進后的網絡框架的輸出平均精度高于標準網絡框架。同時通過圖3~圖5實驗輸出效果對比圖可以看出,改進后的模型輸出的識別效果圖圈定的目標范圍更加精準,且不會出現誤識別其他種類昆蟲的情況,識別精度從90.58%提升至94.73%。
4 結束語
本文提出了一種基于聚類算法的自適應Faster R-CNN網絡模型用以榆紫葉甲蟲的識別:通過利用K-means算法結合BWP指標對訓練數據的矩形標簽的長寬比值進行聚類,利用聚類中心點代替標準網絡中生成初始候選框的長寬比例,使生成的初始候選框更加符合榆紫葉甲蟲長寬比形態學特征,減少邊框精修時的平移量,提高了識別精度。實驗結果表明,本文提出的基于K-means的Faster R-CNN算法有效解決了傳統識別算法中特征提取模板的局限性,并針對初始候選框不貼合待識別目標造成的誤差加以改進,提高了識別準確率。改進后的網絡在框定單只榆紫葉甲蟲、榆紫葉甲蟲與葉片豁口或孔洞相鄰、榆紫葉甲蟲相鄰時和其他與榆紫葉甲特征類似種類的昆蟲的框定效果均優于標準網絡。測試相同數據集時的準確率優于標準網絡模型,證明了改進后的網絡的優越性。
猜你喜歡
幼兒畫刊(2023年3期)2023-05-26 05:39:28
光學精密工程(2022年13期)2022-08-02 08:53:30
計算機工程與應用(2022年1期)2022-01-22 07:46:48
小哥白尼(野生動物)(2021年4期)2021-07-29 08:15:46
小哥白尼(野生動物)(2021年1期)2021-07-16 08:02:50
計算機工程與科學(2021年4期)2021-05-11 01:59:36
北京園林(2020年2期)2020-01-18 03:30:56
火力與指揮控制(2018年3期)2018-04-19 11:43:39
現代園藝(2017年13期)2018-01-19 02:28:02
童話世界(2017年8期)2017-05-04 04:08:36
