基于Hadoop的工程造價費用估算與信息管理系統設計
2018-12-03 03:49:08蘭溯源
機械設計與制造工程 2018年11期
蘭溯源
(延安大學建筑工程學院,陜西 延安 716000)
隨著我國建筑業的不斷發展,工程造價行業積累了大量的數據信息,這些信息的積累,為工程造價信息共享和挖掘奠定了基礎。目前,工程造價行業還存在一些比較突出的問題,如信息互通困難,使得工程造價單位和管理部門數據共享不充分,存在“信息孤島”的現象。同時部分工程造價信息數據更新慢,沒有充分體現出其應有的價值。如何對這些海量數據進行存儲和挖掘,提高這些數據在工程領域的應用效率,成為業內思考和研究的重點。朱淵[1]以輸變電工程為背景,采用Web技術構建了一個可用于輸變電工程造價管理的系統,運用該系統工作人員可對工程造價進行預算、及時查看工程進度等;周文瓊等[2]采用BIM/BLM構建工程決算系統,通過該系統可實現工程決算的可視化。但目前工程造價信息共享不足,“信息孤島”現象依然存在。針對數據共享以及考慮到當前海量的造價信息存儲、分析問題,本文基于Hadoop架構體系構建一個可供工程造價行業查詢工程造價預算與信息管理的系統,改變當前信息共享差、數據利用效率低下的狀況,以此為工程造價行業提供更多有價值的信息,促進工程造價行業的整體發展。
1 系統角色與需求分析
構建工程造價費用估算與信息管理系統的目的是利用云計算技術對工程造價數據進行挖掘,提高工程造價行業的信息利用率。根據設計目的以及結合造價行業的具體業務,設計7種不同的角色,這些角色在該系統中擁有不同的業務需求,具體如圖1所示。
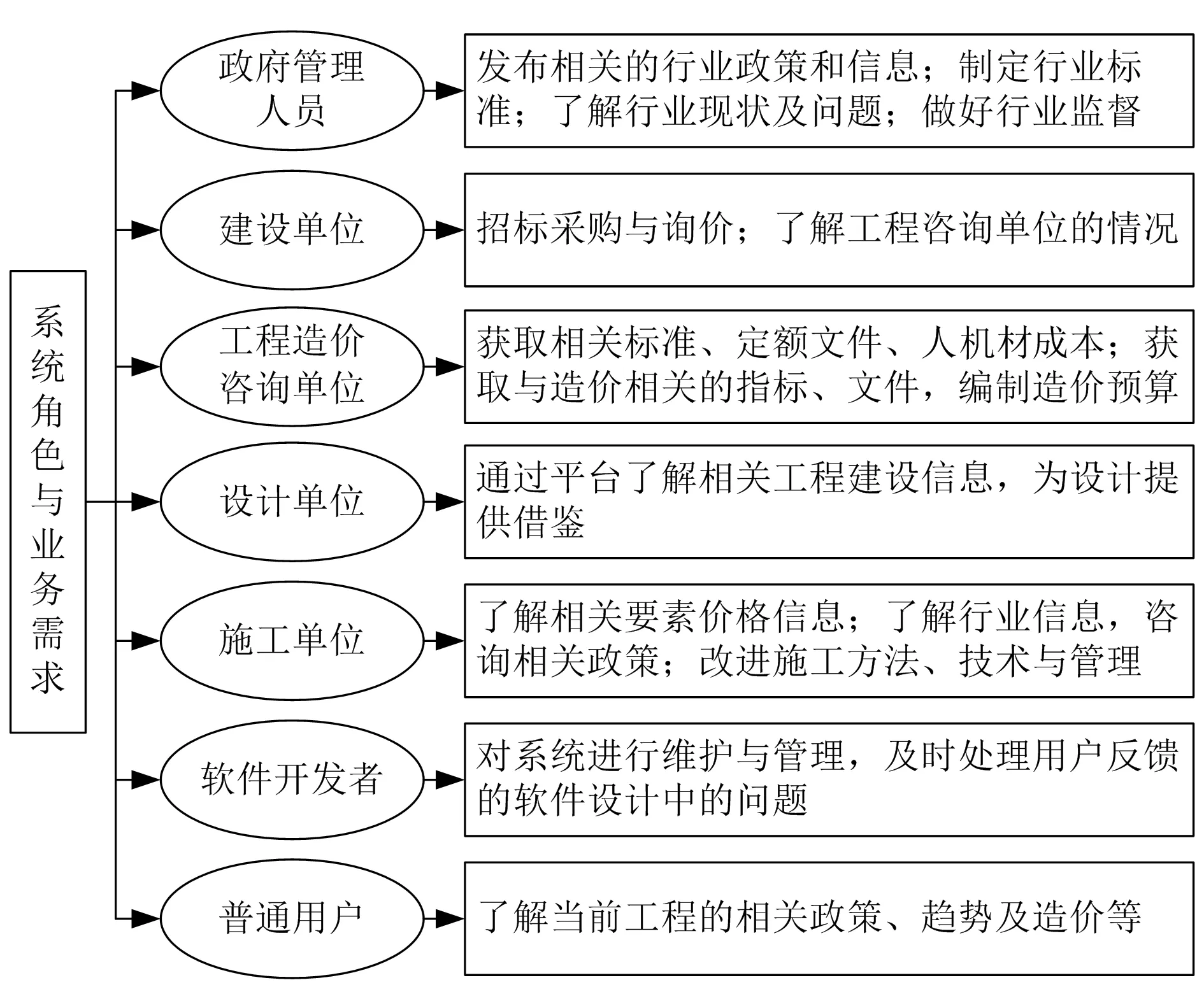
圖1 不同角色的業務需求分析
從圖1可以看出,工程造價信息管理平臺是以信息的共享和利用為基礎的。信息管理平臺本身就促進了整個行業信息共享的效率,因此在該系統的設計中,另一個要關注的問題就是如何利用系統中海量的工程造價信息,提供工程造價估算與預測功能,為工程管理者提供借鑒與參考。
2 系統整體架構搭建
根據以上的設計目標和業務需求,在設計中首先應滿足基本業務需求,其次再考慮系統的長遠發展,以便擴展系統的功能。本系統構建目的是實現工程造價行業信息的共享,促進造價業務的協同,并通過投資預測等功能,為造價行業提供相關的決策依據。考慮到數據量龐大,采用Hadoop架構搭建系統,將系統分為數據集成層、數據存儲層、數據處理分析層、數據輸出展示層。系統整體架構如圖2所示。
通過圖2看出,不同層具有不同的功能。
數據集成層是整個系統數據的來源,這些數據可以來自MySql數據庫,也可以來自Sql Servers數據庫,還可來自其他的數據庫。換句話說,這些數據可以是結構型數據,也可以是非結構型數據,數據的類型包括文字、圖片、音頻等。為方便對這些數據的存儲和查詢,在數據源與數據存儲層之間使用Sqoop工具,通過該工具可實現關系型數據庫與Hadoop間的交換。
數據存儲層采用HDFS、Hbase等組件,通過分布式文件存儲系統和統一的接口即可完成對不同節點下文件的訪問。Hbase主要負責對非結構化的數據進行存儲。
數據處理分析層采用MapReduce并行處理技術、Hive技術等,以完成對數據的計算和查詢。通過MapReduce并行技術提高運算速率,采用Hive提高查詢效率。
數據輸出展示層則是將查詢的結果展示給用戶。
3 功能模塊設計
系統設置了信息分析與發布、信息采集、信息檢索、用戶注冊與登錄、數據分析、系統維護與管理等模塊,如圖3所示。
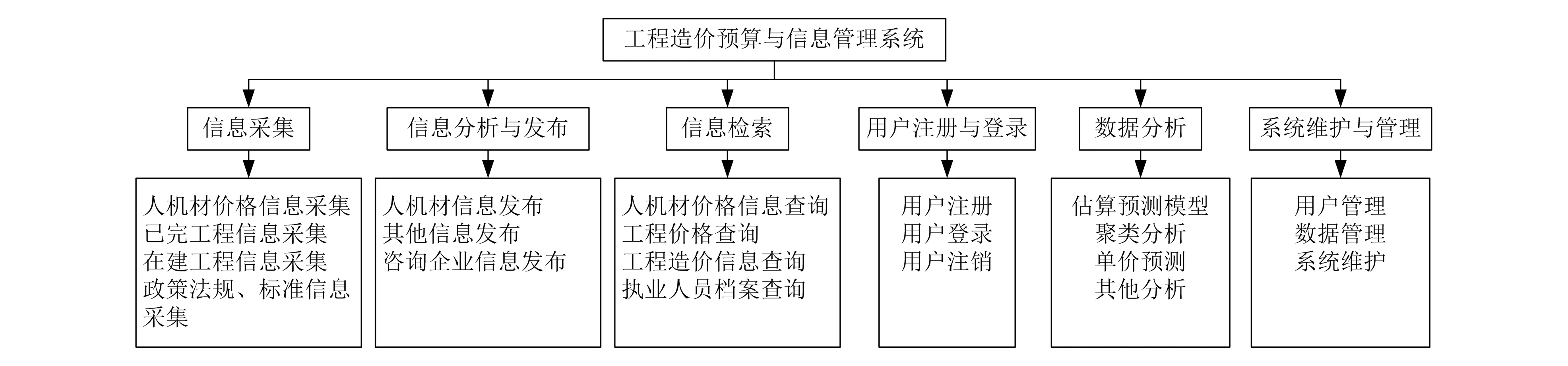
圖3 系統功能模塊
4 系統詳細設計
4.1 用戶登錄設計
進入登錄頁面,用戶輸入登錄名和密碼,與后臺服務器中存儲的登錄名和密碼進行比對,如一致則進入到工程造價預算與信息管理系統主界面;如不一致,則返回重新登錄。具體流程如圖4所示。
4.2 工程造價估算模型構建
工程造價估算模型的構建是本系統的重點。目前,用于工程造價估算的模型很多,其建模方法包括神經網絡算法、灰色關聯分析算法等。本文在總結以往方法優缺點的基礎上,選用灰色關聯分析算法進行工程造價估算模型的建立。該方法的基本思路是根據序列曲線幾何形狀的相似度[3],來判斷兩工程的造價之間聯系是否緊密。
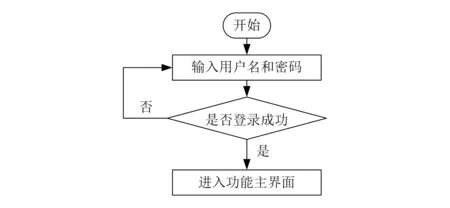
圖4 系統登錄流程設計
如項目造價變化趨勢一致或者是相似,則認為兩者之間的關聯度較高;如變化趨勢區別較大,則認為兩者之間的關聯度低。對于工程建設項目來講,影響工程造價的因素很多,因此在進行項目投資估算時,通過工程項目特征相似度進行關聯分析。具體的思路是:選取與待測項目特征比較接近的工程項目若干,然后采用灰色關聯度分析法篩選出與待測工程最為接近的n個典型工程,對這些典型工程的平均投資額進行計算,最后得到預測工程的投資額度。
具體測算步驟為:
1)選取測算指標,包括工程結構、內裝形式、給排水方式等。
2)根據上述關鍵指標,篩選出同類型的工程項目,然后將估算工程的單方造價與類似項目的特征信息進行系數賦值。本文將該系數值設定為0.5。
3)計算估算工程項目與典型工程的關聯度。
假設有P個典型工程,其包含8個特征參數,分別為結構形式、內墻裝飾、外墻裝飾、給排水、暖通、強電、弱電、電梯等,可以得到工程的參數序列集合Xi:
(1)
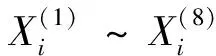
①求取t。
(2)
式中:X(1)~X(8)為同類型工程各特征參數的平均數;t為選定的特征參數與同類型工程特征參數平均數的差的絕對值。
②找出t中的最大差值tmax和最小差值tmin,并計算關聯度系數:
(3)
式中:moi為關聯度系數;q為第q個特征參數。
③計算關聯度roi:
(4)
式中:n為被比較的特征參數個數。
4.3 綜合單價預測模型構建
除整體的工程造價估算以外,還需對某個工程的單項造價進行預測。本文引入殘差自回歸預測模型對工程的綜合單價進行預測,并采用并行計算技術,以提高綜合單價預測的準確性和計算效率。具體的預測流程如圖5所示。
4.4 信息聚類設計
為進一步提高Hadoop框架下海量數據信息挖掘的效率,引入k均值聚類算法對工程造價庫中的數據進行聚類。
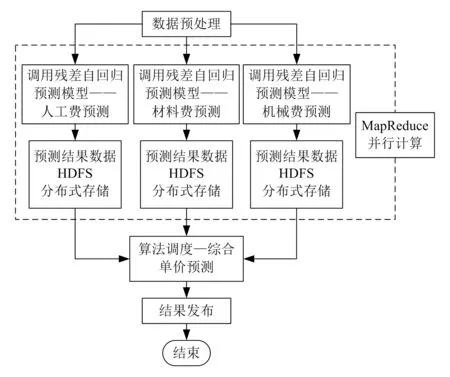
圖5 綜合單價預測流程
在聚類算法中,最關鍵的是確定初始k值和中心點[4-5]。本文使用k均值聚類法對系統中的信息進行挖掘分類時,對中心點的選擇進行了改進,即改變以往只選擇一個中心點作為聚類點的做法,在比較數據樣本的距離后,選擇距離盡可能遠的兩個樣本作為初始的中心點,即對于給定的數據集A={x1,x2,…,xm},xm∈Rd,選擇兩個樣本距離最長的點作為中心點,然后計算每個樣本與這兩個點之間的距離。具體過程設計為:
1)選取樣本中距離最長的兩點s,t作為中心點,即dst=dmax。
2)分別計算其他樣本與s,t中心點之間的距離。若樣本xi(i=1,2,…,P)與樣本xs和xt的距離存在|xi-xs|<|xi-xt|,則將xi歸入數據集As中,反之歸入數據集At中。由此得到新的兩類數據集As和At。
3)計算新數據集As和At中的樣本到xs的距離,分別用d1max和d2max表示,取兩者中的較大者,設為d3=max{d1max,d2max},對應的數據記為xu。若d3>0.5dst,那么將該數據標記為第三個聚類的中心點。
4)以此類推,直至找不到符合條件的樣本,停止分類。
在運行上述算法的同時,運用MapReduce分布式處理技術對數據進行分布式聚類。
4.5 在線查詢模塊設計
為提高系統的實用性,在系統中加入在線查詢功能。用戶在輸入關鍵詞后,可及時查到工程價格信息、材料成本信息、造價指數等。具體流程如圖6所示。
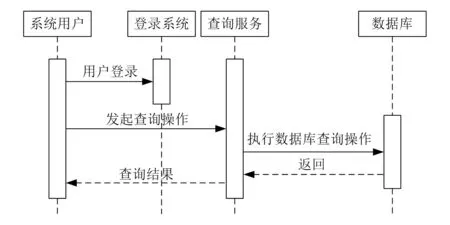
圖6 在線查詢實現流程
5 系統測試
5.1 測試環境搭建
為驗證本系統的可行性,需對系統進行測試。硬件環境:部署5臺計算機,1臺為主節點,4臺為子節點。計算機的CPU為四核 core i7,內存為8GHz,硬盤為500G。
軟件環境:操作系統為Windows 2008 Server;開發工具為JDK 1.6.25;Hadoop 的版本為Hadoop 0.20.2。
5.2 性能測試
根據上述的節點部署,選擇4個子節點計算機對數據進行測試,得到如圖7所示的結果。
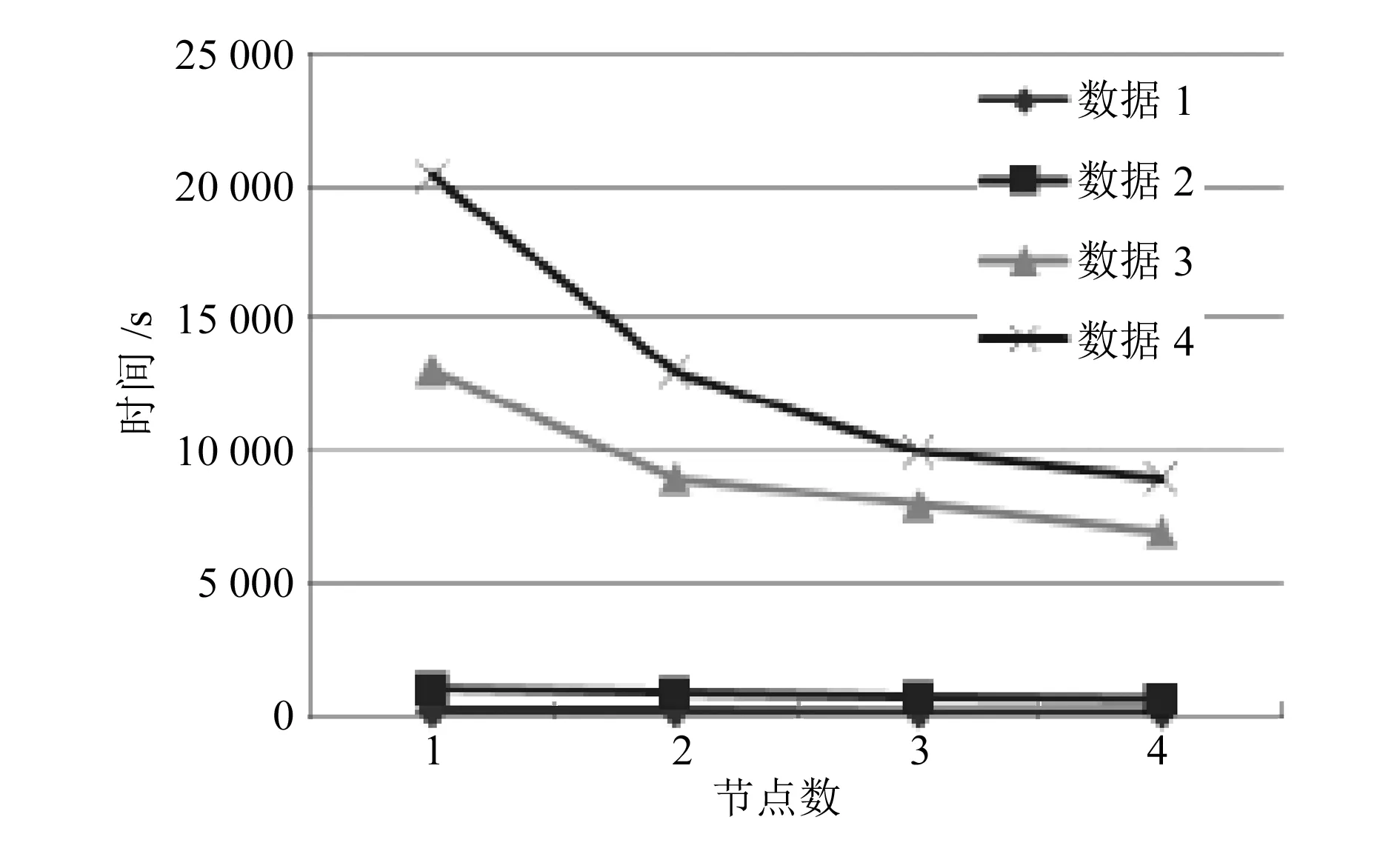
圖7 數據處理時間
從圖可以看出,在數據相同的情況下,當子節點超過3個時,數據處理的速度明顯加快。說明通過分布式部署的方式,可提高大規模數據的處理效率。
5.3 功能測試
以用戶登錄、造價信息查詢為例進行功能測試。當用戶輸入用戶名和密碼后,可直接進入到系統主界面。登錄界面如圖8所示。
圖8 登錄界面
對不同區域的造價信息進行查詢,如點擊“成都”→“建筑工程”,可以得到如圖9所示的造價信息界面。
6 結束語
本文提出的關聯度投資估算方法,在一定程度上可快速估算出工程的整體造價,進一步拓展了工程管理系統的功能,也促進了工程造價行業信息的共享。本文系統的構建借助了大數據框架體系,可提高系統運行的效率。

圖9 行業造價信息界面
