基于SqueezeNet的輕量化卷積神經網絡SlimNet
2018-11-30 01:46:56董藝威
計算機應用與軟件 2018年11期
董藝威 于 津
(汕頭大學工學院計算機科學與技術系 廣東 汕頭 515063)
0 引 言
計算機視覺(Computer Vision)賦予計算機看見并理解世界的能力,包括圖像分類、目標定位、目標識別、實例分割等任務。圖像分類是計算機根據圖像內容將其歸類,是上述其他任務的基礎,有重要的研究意義。
自2012年Krizhevsky等憑借AlexNet[1]贏得ILSVRC12的圖像分類冠軍以后,研究學者們開始關注卷積神經網絡在圖像分類中的應用。隨后,在AlexNet的基礎上,提出如ResNet[2]等很多表現優異的卷積神經網絡,在ILSVRC圖像分類中獲得優異的成績。通過設計更深更復雜的結構以獲得更高分類精度(即深度學習)。上述卷積神經網絡結構參數量高達數兆,識別一張圖片需要上百億次浮點運算次數。運行這些結構需要大量內存空間和計算資源,一般是工作站級別的設備。
現實中,人們希望將卷積神經網絡部署到手機、無人機和無人駕駛汽車等移動設備中,用于圖像分類和目標檢測等計算機視覺任務。移動設備內存少、計算能力小。研究學者提出設計適用于移動設備的卷積神經網絡,即輕量化結構。輕量化結構是指結構分類精度滿足應用需求,結構參數量和計算量均未超出移動設備的能力。輕量化結構具有如下優勢:一般采用空中下載OTA技術將訓練好的結構部署(安裝或更新)到移動設備,輕量化結構加快了部署過程,節省移動數據流量;移動設備內存少、計算量小,輕量化結構符合移動設備的硬件要求。
2016年,Iandola等[3]借鑒了Inception模塊的設計思想,提出Fire模塊,以此提出首個輕量化卷積神經網絡結構SqueezeNet。不同于Inception模塊中對特征圖進行獨立的多尺度學習的做法,Fire模塊先對特征圖進行維度壓縮,然后對這些特征圖做多尺度學習后進行拼接。此外,Fire模塊僅采用1×1卷積和3×3卷積,并未使用更大的卷積,有效減少結構參數量。在維持AlexNet的分類精度情況下,SqueezeNet的結構參數量僅為AlexNet的1/50。SqueezeNet存在以下兩點不足:AlexNet是2012年提出的結構,分類精度低于近些年的結構,沒有可比性;雖然SqueezeNet結構參數量較小,但與AlexNet相比其所占計算資源幾乎相同。
為了降低結構計算量,2014年,Sifre等[4]首次提出深度可分卷積(Depthwise Separable Convolution),以此改進AlexNet,在保持分類精度的情況下,減少了結構的訓練時間和參數量。受Sifre啟發,文獻[5]采用深度可分卷積替換InceptionV3中的常規卷積(Standard Convolution)。同時指出去掉3×3卷積和1×1卷積之間的ReLU能夠加速訓練并提高分類精度,以此提出Xception[6],在相同參數量的情況下,分類精度上勝過InceptionV3。
受到Xception啟發,2017年谷歌的Howard等借用深度可分卷積代替常規卷積,借鑒VGG[7]中逐層設計的思想,提出了MobileNet[8]。MobileNet的主要工作在于使用深度可分卷積替代常規卷積來降低卷積神經網絡的參數量和計算量,設計面向移動設備的輕量化結構。實驗證明,與VGG相比,在很小的分類精度損失情況下,MobileNet參數量是VGG的3%,計算量是VGG的4%。使用深度可分卷積的MobileNet在輕量化設計中起到了啟蒙作用。但MobileNet存在以下問題:采用VGG的直筒結構性價比較低,ResNet等結構已證明通過殘差學習能提升結構分類精度。
深度可分卷積包含深向卷積(Depthwise Convolution)和點向卷積(Pointwise Convolution)。深向卷積是單通道學習特征,點向卷積使得各個通道間信息流通。其中1×1卷積占據了大部分的計算量。在MobileNet中1×1卷積在參數量占74.59%,在計算量上占94.86%。
為了減少1×1卷積所占計算量比例,2017年曠視科技的孫劍等在1×1卷積中引入分組卷積,提出1×1分組卷積(Pointwise Group Convolution),但分組卷積導致分組通道間信息不流通。他們提出在結構中添加通道交叉操作使得分組通道間信息重新流通。文獻[9]在MobileNet的基礎上,添加了殘差學習,提出ShuffleNet。ShuffleNet在分類精度、結構參數量和計算量上均優于MobileNet。
2018年,谷歌的Sandler等[10]對MobileNet進行改進,提出MobileNetV2。他們提出反轉殘差模塊(Inverted Residuals),其特點是先擴張后卷積再壓縮。這樣做的目的是為深度可分卷積提供更多的通道,從而提高結構的學習能力。他們還發現去掉通道壓縮層的非線性變換能夠提升分類精度。實驗證明,和MobileNet相比,MobileNetV2在分類精度、結構參數量和計算量上均有了改善。在ImageNet-1k數據集上,MobileNetV2分類精度提升2%,參數量減少30%,計算量減少50%。
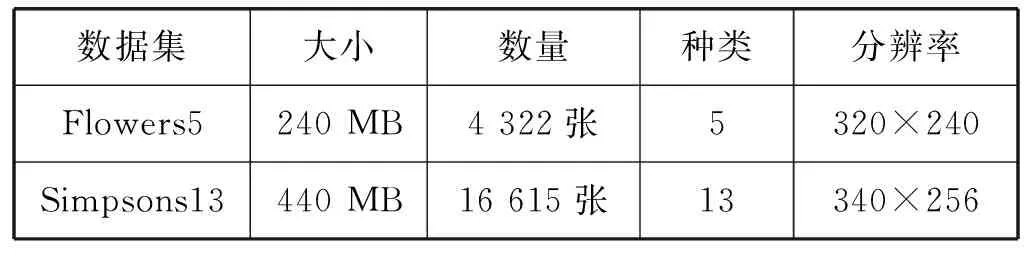
本文提出兩種設計策略:分組瓶頸和奇異瓶頸,并使用上述策略改進SqueezeNet,提出輕量化結構SlimNet。與SqueezeNet相比,SlimNet在Flowers5數據集上分類精度提高17%,在Simpsons13數據集上分類精度提高9%,在結構參數量上降低34%,在計算量上降低75%。
1 輕量化結構SlimNet
SqueezeNet在分類精度和結構計算量上與AlexNet持平,其結構參數量為1.24兆,而AlexNet結構參數量為61.10兆。SqueezeNet計算量與AlexNet持平,不利于部署在移動設備上。經過推導Fire模塊的計算量,發現導致計算量過高的原因有:壓縮層輸入通道數量較大,用于降低通道數量的1×1卷積操作占計算比例高;擴展層輸出通道數量較大,用于特征學習的1×1和3×3卷積操作計算較多。本文針對如何降低計算量而展開研究。
1.1 分組瓶頸
為改進結構以減少結構計算量,提出分組卷積,它能夠有效降低結構的參數量和計算量。常規卷積對輸入整體進行卷積操作,如圖1(a)所示。分組卷積中的分組是針對輸入通道而言,在圖1(b)中,輸入通道分為兩組。每組輸入獨立進行卷積操作,分組得到的輸出拼接后作為整體輸出。

(a) (b)圖1 常規卷積和分組卷積
當輸入為W1×H1×C1(W1代表Width,指輸入通道寬度;H1代表Height,指輸入通道高度;C1代表Channel,指輸入通道數量),卷積核大小為h×w,一共有C2個,則輸出數據為H2×W2×C2。對于常規卷積和分組卷積,其參數量和計算量如表1所示,其中分組數量為g。

表1 常規卷積和分組卷積對比
從表1可見,分組卷積有效減少了結構的參數量和計算量,但存在分組通道間信息不流通的問題。
為了解決分組卷積引起的分組通道信息不流通問題,本文研究近年來的卷積神經網絡結構,發現ResNet中的瓶頸模塊或許能夠解決這個問題。瓶頸模塊如圖2所示。瓶頸模塊先使用1×1卷積縮減輸入通道數量(通道數量由256變為64),再對64個通道進行3×3卷積以學習特征,最后使用1×1卷積恢復通道數量(通道數量由64變為256)。在模塊中通道數量經歷了先減少再不變最后增加的過程,類似于瓶頸,所以叫瓶頸模塊。這樣做的目的是減少3×3卷積的輸入和輸出通道數量(均為64),以減少結構的訓練時間。圖2中右邊一條線連接輸入和輸出,為恒等映射,其目的是使用殘差學習。

圖2 瓶頸模塊
因瓶頸模塊中1×1卷積的輸入或輸出通道數量較大,3×3卷積的輸入和輸出通道數量較小,故本文提出1×1卷積使用分組卷積以減少結構的參數量和計算量,3×3卷積使用常規卷積以使得分組通道間信息重新流通,并命名為分組瓶頸,如圖3所示。使用分組瓶頸可解決分組通道間信息不流通的問題,而不需要額外操作(ShuffleNet使用通道交叉操作來解決分組通道間信息不流通的問題)。
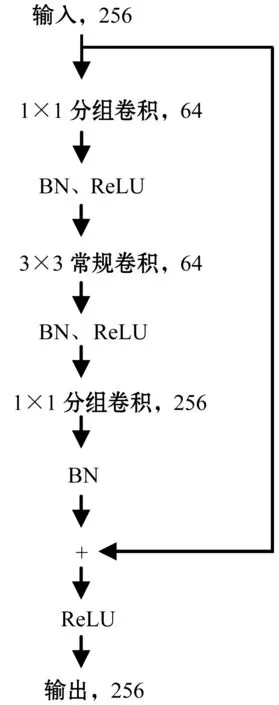
圖3 本文提出的分組瓶頸
1.2 奇異瓶頸
2017年Sandler等在MobileNetV2中提出線性瓶頸的設計策略。線性瓶頸指,刪除用于通道縮減的1×1卷積后的非線性變換能夠提高分類精度,如圖4所示。在線性瓶頸中,下面的1×1卷積沒有非線性變換(即ReLU)。由此本文提出舍去用于通道擴增的1×1卷積后的非線性變換,提升了分類精度,并通過實驗驗證上述想法的可行性。由于改進后的模塊僅一次非線性變換,故叫奇異瓶頸。在圖5中,舍去上面的1×1卷積的非線性操作。
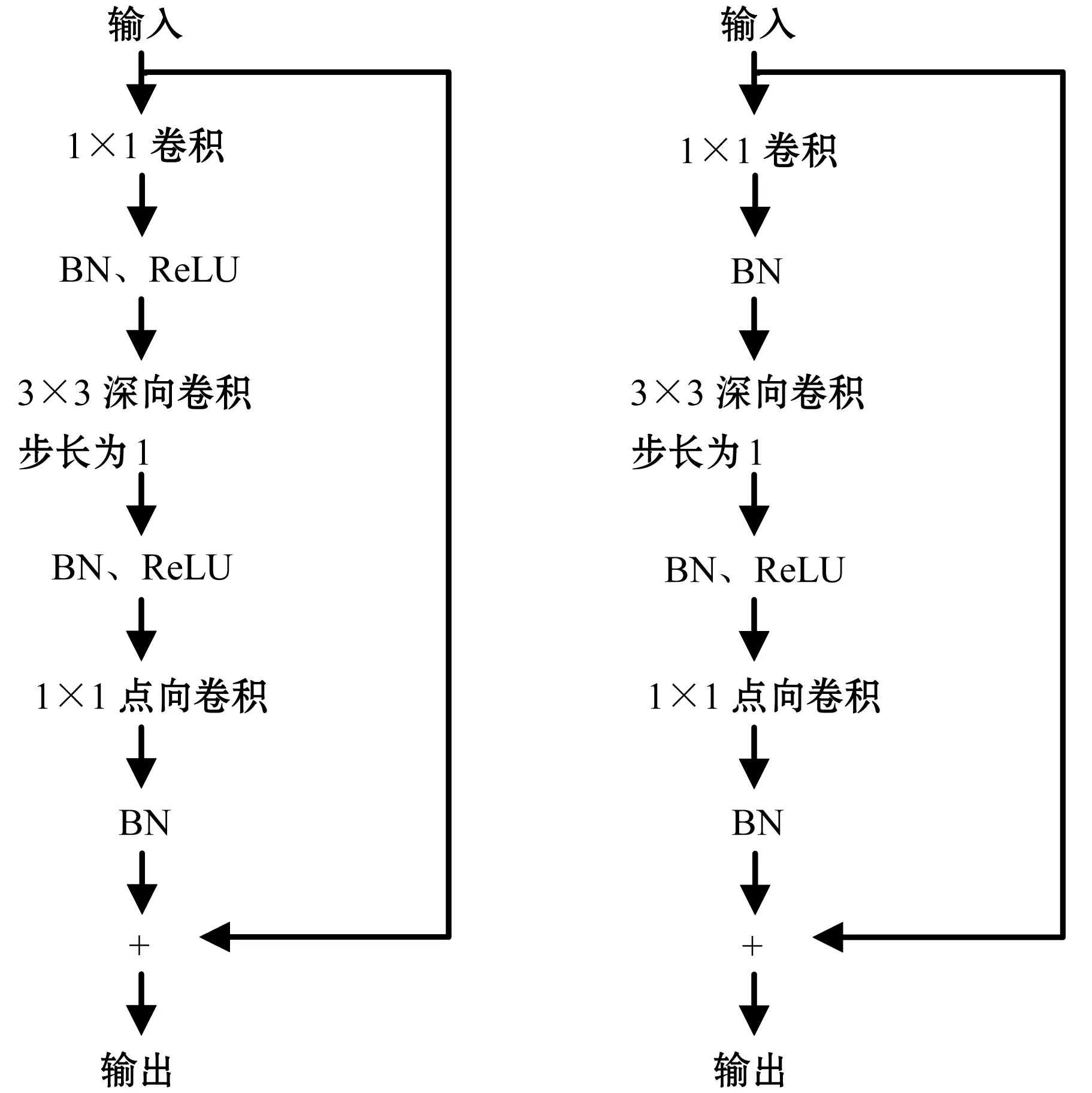
圖4 線性瓶頸 圖5 本文提出的奇異瓶頸
1.3 SlimNet
本文使用上述策略改進SqueezeNet,并引入批歸一化BN(Batch Normalization)[11],改進SqueezeNet的Fire模塊。改進SqueezeNet的整體結構后級聯Slim模塊,增加池化層和Slim模塊的數量,添加Softmax,提出SlimNet。
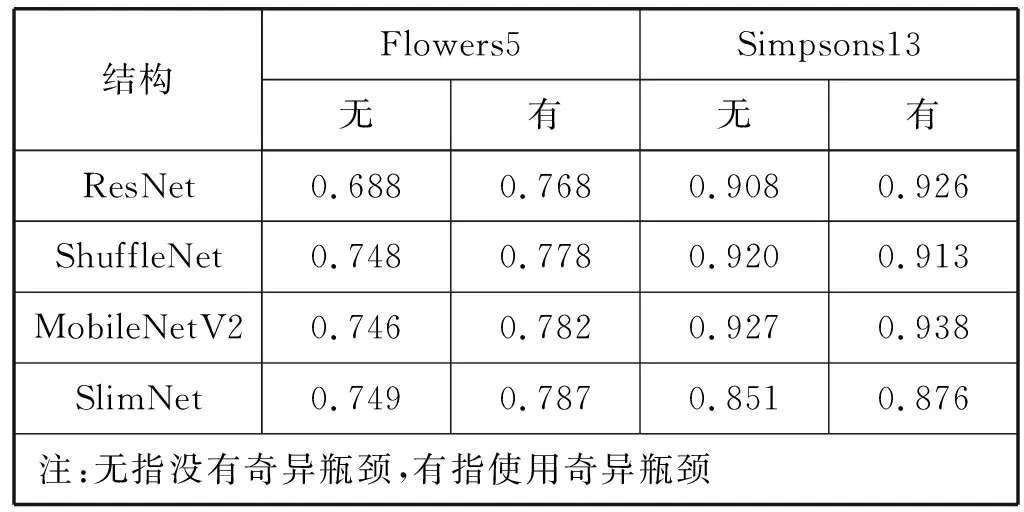
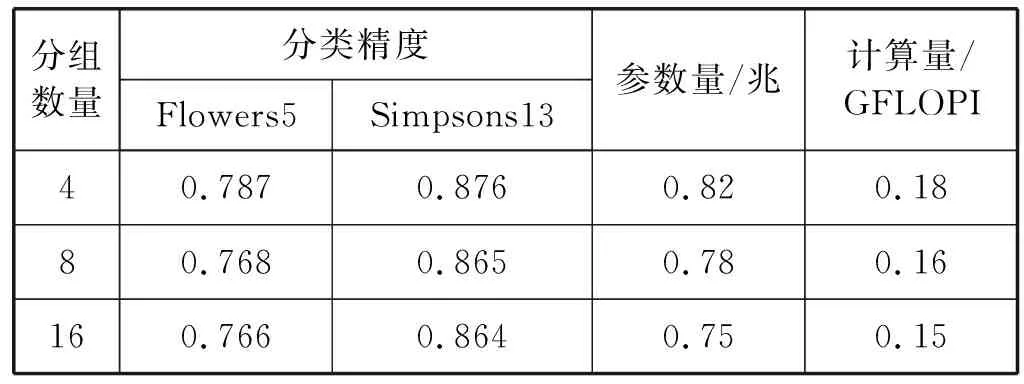
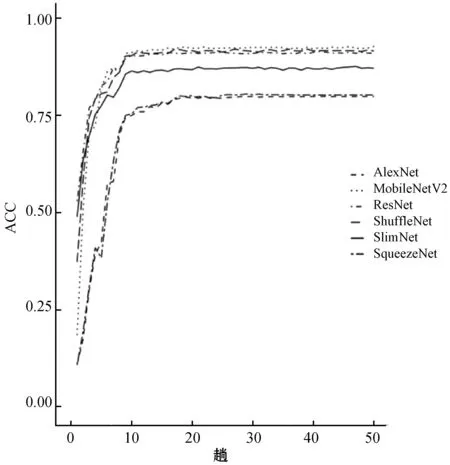
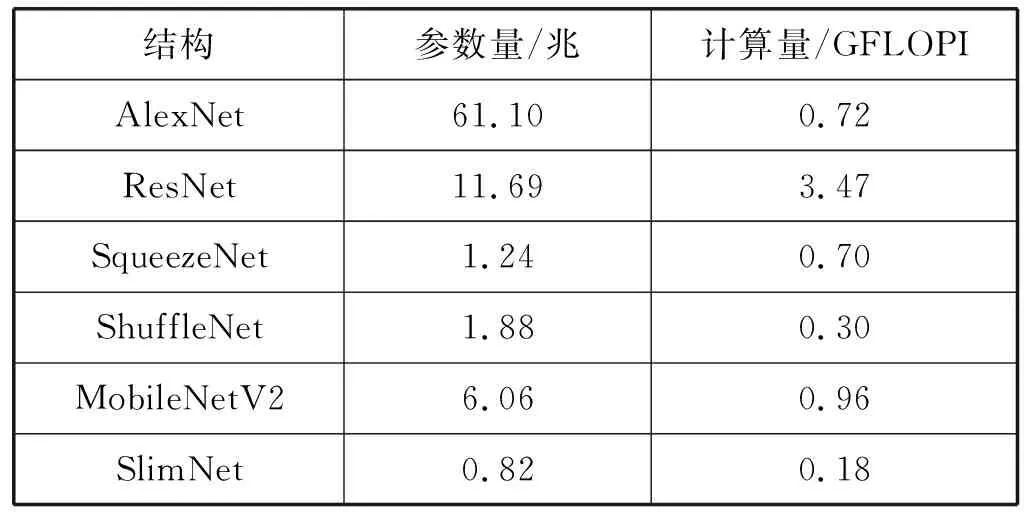
Fire模塊沒有采用瓶頸設計,為了使用分組瓶頸進行改進,先將Fire模塊改進成瓶頸模塊,再引入分組瓶頸。具體講,減小Fire模塊中3×3卷積的輸出通道數量,使其有輸入輸出通道數量相同,后接1×1卷積用于擴增通道數量,形成瓶頸模塊。使用分組瓶頸,對模塊中的1×1卷積采用分組卷積。使用奇異瓶頸,舍去1×1卷積的非線性變換。此外,發現Fire模塊中沒有批歸一化。批歸一化能夠加速訓練過程,提高分類精度。添加批歸一化后,本文提出Slim模塊,如圖6所示。Slim模塊由壓縮層、卷積層和擴展層組成,設有四個超參數,分別是壓縮層和擴展層的分組組數g、壓縮層卷積核數s、卷積層卷積核數c和擴展層卷積核數e,其中s=c,s 圖6 Slim模塊 將Slim模塊級聯形成卷積階段以進行圖像特征學習,后接分類器用于圖像分類。由于Slim模塊和Fire模塊輸入和輸出通道的寬、高、數量都相同,本文按照SqueezeNet整體結構的方式級聯Slim模塊,并在結構中額外增加一個池化層和兩個Slim模塊。SqueezeNet最后一層卷積層采用1×1卷積用以改變輸出分類數量,將通道數量從512擴增至1 000。該操作占用大量的計算,于是去掉該卷積層,增加全連接層用于改變輸出分類數量。此外,在結構最后添加Softmax函數。Softmax函數用于多分類過程,將結構的輸出值映射到0~1的范圍內,且輸出之和為1,可以看作是概率。SlimNet的整體結構如表2所示。 表2 Slim整體結構 考慮到結構針對不同數據集的普遍適用能力,本文采用兩個不同的數據集:Flowers5[12]和Simpsons13[13],如表3所示。 表3 數據集概況 實驗環境如下:操作系統為Ubuntu 17.10,顯卡驅動為NVIDIA 384.81,CUDA 9.0,PyTorch 0.3.0。使用Torchsummary記錄結構的參數量。使用R語言環境下的Tidyverse庫繪制實驗折線圖。 超參數設置如下:輸入圖像分辨率為224×224,批大小為16個,損失函數為交叉熵,優化方法為隨機梯度下降,學習速率為0.001,動量為0.9,步長為8,Gamma值為0.1,趟數為50。 使用測試集分類精度、結構參數量和結構計算量作為評估指標。分類精度選取結構在訓練過程中最高的測試集分類精度,以度量結構的能力上限。本文使用Torchsummary來記錄結構的參數量。結構計算量指結構推斷一張圖片所需浮點數運算次數GFLOPI(Giga Floating-Point Operations Per Image)。通過計算得到結構計算量,精簡已有公式[14]后得到如下公式: Complexity=2×C1×C2×w×h×W2×H2 (1) 式中:Complexity指結構計算量;C1指輸入通道數量,C2指輸出通道數量;w和h指卷積核的寬和高;W2和H2指輸出通道的寬和高。 實驗首先使用分組瓶頸和奇異瓶頸修改已有結構,通過評估指標分析策略的有效性。然后對比不同分組數量下SlimNet的評估指標,以分析分組數量對SlimNet的影響。最后將SlimNet同其他結構進行比較,突出SlimNet的實用價值。 選取采用瓶頸結構的ResNet和SlimNet進行驗證。其中ResNet層數為50層,分組數量均取4。實驗分別在有無分組瓶頸兩種情況下,將各個結構在兩個真實數據集上進行訓練,得到最高測試集分類精度,如表4所示。分組瓶頸對分類精度影響不大。在ResNet中引入分組瓶頸,分類精度沒有明顯變化,說明分組瓶頸有效解決了分組卷積引起的分組通道間信息不流通的問題。SlimNet中引入分組瓶頸后,發現在Simpsons13數據集上分類精度有所降低。由此可見,不同于ResNet中“1”字型結構, SlimNet中“人”字型結構抑制了分組瓶頸的作用。 表4 分組瓶頸對分類精度的影響 同時,實驗記錄結構參數量,并計算結構計算量,如表5所示。分組瓶頸有效降低結構參數量和計算量。在ResNet中,分組卷積降低了27%的參數量和34%的計算量。在SlimNet中,分組卷積降低了25%的參數量和40%的計算量。 表5 分組瓶頸對結構參數量和計算量的影響 在對分類精度影響不大的情況下,分組瓶頸大幅度降低結構的參數量和計算量,是一種有效的輕量化設計策略。 選擇ResNet、ShuffleNet、MobileNetV2和SlimNet,通過實驗比較奇異瓶頸對分類精度的影響。其中ResNet層數為50層。實驗分別在有無奇異瓶頸兩種情況下,將各個結構在兩個真實數據集上進行訓練,得到最高測試集分類精度,如表6所示。 表6 奇異瓶頸對分類精度的影響 從表6可見,奇異瓶頸在各個結構上均能提升分類精度。在Flowers5數據集上,奇異瓶頸使得分類精度提高4.8%。在Simpsons13數據集上,奇異瓶頸使得分類精度提高1.2%。奇異瓶頸對分類精度的提高幅度與其自值有關,即分類精度越高,提高幅度越小。值得注意的是,對于ShuffleNet,在Simpsons13數據集上,無奇異瓶頸的情況下有著更高的分類精度,這可能和ShuffleNet自身結構有關。 分組數量分別選擇1、2、4、8和16。其中,分組數量為1相當于常規卷積。分組數量均選擇2的指數是為了能夠整除通道數量。最大選擇16是因為SlimNet中最小的通道數量為16。實驗結果如表7所示。 表7 分組數量對SlimNet的影響 續表7 從表7可見,分組數量從1增加到16,在Flowers5數據集上分類精度降低2%,在Simpsons13數據集上分類精度降低3%,訓練時間也相應增加3分鐘和8分鐘,參數量減少32%,計算量降低50%。由此可見,損失少量的分類精度,可以得到參數量和計算量的大幅度降低。在分組數量從4增加到8時,SlimNet在Simpsons13數據集上的分類精度降低1.1%,而結構參數量降低5%,結構計算量降低11%。由此可見,當分組數量從4增加16的過程中,參數量和計算量的減少幅度逐漸降低。為了保持較高分類精度,本文建議分組數量為4較佳。 值得注意的是,在Flowers5數據集上,分組數量為4的分類精度高于分組數量為1和2的,這是因為Flowers5數據集自身存在問題,SlimNet在Flowers5數據集上的訓練過程不穩定,有較大的起伏(具體原因在下節分析)。但從實驗角度考慮,Flowers5數據集能一定程度上反映結構特性,且訓練時間較短,便于結構多次改進和實驗的重復迭代,所以本文依舊選擇了Flowers5數據集。 選擇了AlexNet、ResNet、SqueezeNet、ShuffleNet、MobileNetV2作為對比結構。ResNet選用18層是因為在實驗數據集上分類精度較高,具有可比性。SlimNet分組數量為4。 首先,在Flowers5數據集上進行比較,各個結構的訓練過程如圖7所示。結構均在20趟(Epoch)后趨于收斂。其中AlexNet和SqueezeNet在30趟后幾乎無波動,而其余結構一直保持上下波動,這是由于其余結構中添加了批歸一化層導致每趟訓練改變每層的輸入使得分類精度無法穩定在一個值。在ImageNet-1K數據集上AlexNet和SqueezeNet分類精度相同,在Flowers5數據集上分類精度不同,說明Flowers5數據集自身存在問題影響到了兩個結構的分類精度。SlimNet取得最高的分類精度可能是受到Flowers5數據集影響,不能真實反映SlimNet在其他數據集上的分類精度。從整體上看,相較于其他結構,SlimNet在Flowers5數據集上分類精度最高。 圖7 各結構在Flowers5數據集上的訓練過程 同時,在Simpsons13數據集上進行比較,各個結構的訓練過程如圖8所示。使用批歸一化的ResNet、ShuffleNet、MobileNetV2和SlimNet在20趟后趨于收斂。未使用批歸一化的AlexNet和SqueezeNet在30趟后趨于收斂。批歸一化能夠加速結構訓練過程,因此本文在改進過程中引入批歸一化,分類精度由低到高依次是AlexNet、SqueezeNet、SlimNet、ResNet、ShuffleNet和MobileNetV2。可見SlimNet比SqueezeNet有更高的分類精度。此時,AlexNet和SqueezeNet分類精度幾乎相同,說明Simpsons13數據集和ImageNet-1K數據集特性接近,則Simpson13能夠真實反映SlimNet的分類精度。從整體上看,相較于其他結構,SlimNet在Simpsons13數據集上能收斂到較好的分類精度。 圖8 各結構在Simpsons13數據集上的訓練過程 兩個數據集中,發現各結構在第8趟前后均出現不同程度的分類精度突然下降的現象。在第1趟時,ShuffleNet和SlimNet均有較高的分類精度,ResNet次之,MobileNetV2、AlexNet和SqueezeNet最低。需要指出,MobileNetV2在兩個數據集上的表現差異較大,因為其對數據集的質量有著較高的要求,不利于在現實任務中應用。 比較各個結構的參數量和計算量,如表8所示。AlexNet有最大的參數量,計算量卻居中。AlexNet中三個全連接層的參數占據大部分參數空間,全連接層導致結構參數多。但其結構層數(8層)較少,卷積部分參數少,故計算量不大。ResNet有著適中的參數量,計算量卻特別大,這是由于ResNet使用全局平均池化層(全局平均池化層在Network In Network中最早提出)取代全連接層,大大減少結構參數量,但ResNet使用了過多的層數(18層)進行3×3卷積,使得計算量過大。SqueezeNet使用較少3×3卷積使得參數量很小,但有18層,其中包含大量的1×1卷積使得計算量過大。ShuffleNet使用分組卷積和深度可分卷積,結構參數量和計算量均較小。MobileNetV2一方面使用深度可分卷積以減少參數量和計算量,另一方面為了增加分類精度,使用反轉殘差在模塊內增加通道數量導致參數量和計算量的增加,故參數量和計算量居中。SlimNet使用分組瓶頸,使得結構的參數量和計算量均為最小。 表8 各結構的參數量和計算量比較 和SqueezeNet相比,SlimNet在Flowers5數據集的分類精度提高17%,在Simpsons13數據集的分類精度提高9%,參數量減少了34%,計算量上減少了75%。實驗證明,本文提出的SlimNet具有一定的實用價值。 分組瓶頸和奇異瓶頸使得本文提出的策略改進SqueezeNet的輕量化結構SlimNet在分類精度、結構參數量和計算量上均優于SqueezeNet。 但SlimNet在分類精度上稍低于ShuffleNet和MobileNetV2。這是由于SlimNet和SqueezeNet采用了相近的整體結構,可改進整體結構以提高分類精度。本文的實驗數據集包含圖片類別(分別是5和13)稍小,在ImageNet-1K數據集(種類為1 000)上分類精度未知因此可提高實驗環境,以測量SlimNet在ImageNet-1K上的分類精度。未來還可進一步研究SlimNet在目標檢測等計算機視覺其他領域中的可行性。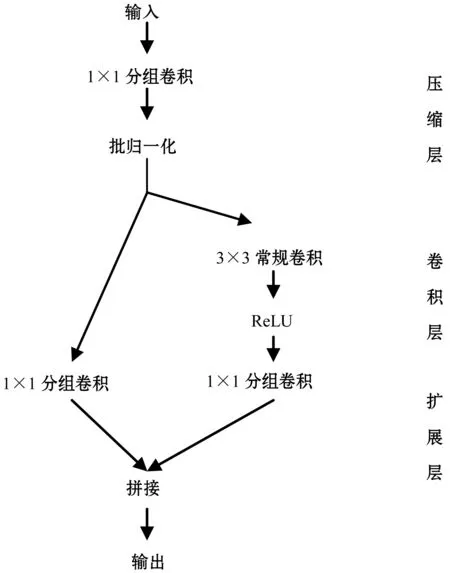

2 實驗分析
2.1 分組瓶頸的驗證


2.2 奇異瓶頸的驗證
2.3 分組數量的影響

2.4 結構比較

3 結 語
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
