自動駕駛中的計算機視覺技術研究
2018-11-28 06:30:50北京市海淀實驗中學高三五班王一名
科技創(chuàng)新與品牌 2018年11期
文/北京市海淀實驗中學高三五班 王一名
1 背景概述
自動駕駛不僅可以避免因司機酗酒或疲勞引起的交通事故,而且基于自動駕駛的快速反應能力及時刻在線的監(jiān)控系統(tǒng),還能緩解交通壓力,使得公共道路交通資源得到更有效地分配。
目前自動駕駛被分為五個等級:1級,輔助駕駛,通過駕駛環(huán)境對方向盤和加減速中的一項操作提供駕駛支持,其他的駕駛動作都由人類駕駛員進行操作;2級,半自動駕駛,通過駕駛環(huán)境對方向盤和加減速中的多項操作提供駕駛支持,其他的駕駛動作都由人類駕駛員進行操作;3級,高度自動駕駛,或者稱有條件自動駕駛,由自動駕駛系統(tǒng)完成所有的駕駛操作,根據(jù)系統(tǒng)要求,人類駕駛者需要在適當?shù)臅r候提供應答;4級,超高度自動駕駛,由自動駕駛系統(tǒng)完成所有的駕駛操作,根據(jù)系統(tǒng)要求,人類駕駛者不需要對所有的系統(tǒng)請求做出應答,包括限定道路和環(huán)境條件等;5級,全自動駕駛,在所有人類駕駛者可以應付的道路和環(huán)境條件下,均可以由自動駕駛系統(tǒng)自主完成所有的駕駛操作。
目前,國內(nèi)已有多家廠商投入自動駕駛的研究。京東已開始使用自動駕駛送貨機器人進行快遞的配送。百度在7月4日的開發(fā)者大會上宣布其量產(chǎn)自動駕駛巴士阿波羅龍已達到L4級,且其對外開放了自動駕駛平臺apollo用于幫助汽車行業(yè)及自動駕駛領域研究者搭建自動駕駛系統(tǒng)。Google旗下的自動駕駛公司W(wǎng)aymo預計在今年實現(xiàn)自動駕駛商用。
2 用于自動駕駛的計算機視覺技術
自動駕駛系統(tǒng)是一個集合多種學科技術的復雜系統(tǒng)。通常來說自動駕駛大體上可以分為三個模塊:(1)運動控制模塊,此模塊用于控制汽車的速度、轉向、剎車燈行為;(2)行為決策模塊,該模塊用于根據(jù)汽車所處的環(huán)境決策出汽車下一步需要采取的運動方式,該模塊需要依賴GPS系統(tǒng)及計算機視覺系統(tǒng),GPS系統(tǒng)用于對汽車運動的路徑做全局規(guī)劃,而計算機視覺系統(tǒng)則主要根據(jù)路況實時調(diào)整汽車行駛策略;(3)環(huán)境感知模塊,該模塊用于感知周圍的環(huán)境尤其是車輛、行人、路障等對汽車行駛有影響的環(huán)境信息,該模塊主要通過激光雷達、毫米波測距雷達、超聲波傳感器等精密儀器對車輛周圍物體進行感知,同時,計算機視覺系統(tǒng)也會在該模塊中起到輔助定位的作用。
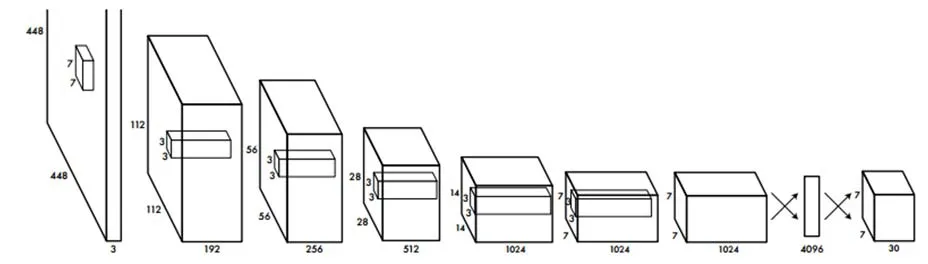
圖1 YOLO的網(wǎng)絡結構圖

圖2 YOLO圖像分解示意圖
可以看到,計算機視覺技術在自動駕駛系統(tǒng)中承擔著十分重要的任務。本章將對自動駕駛中的計算機視覺技術做簡要介紹。
2.1 用于行為決策的計算機視覺技術
在自動駕駛中,車輛需要根據(jù)交通標志、道路地標、前后車轉向燈等信息制定下一步的行駛策略。而識別這些交通信息需要首先使用目標檢測對目標進行定位。
由于車輛在行駛時通常速度較快,因此自動駕駛對于系統(tǒng)反應速度要求極高。目前已有多種達到實時速度的目標檢測算法,而這些目標檢測算法多采用了回歸方法,下面以YOLO(圖1)為例,介紹采用回歸方法的目標檢測算法。圖1為YOLO的網(wǎng)絡結構圖。
該方法與基于候選框推薦方法的最大區(qū)別為該方法在輸出層直接將候選框位置和候選框內(nèi)目標類別進行回歸。而候選框推薦方法,如faster rcnn(圖2),采用先使用一個區(qū)域推薦網(wǎng)絡確定目標位置再對候選框內(nèi)目標進行識別并微調(diào)候選框位置的方法。
YOLO將一張圖像分解為S*S個網(wǎng)格,每個網(wǎng)絡負責預測中心落在該網(wǎng)格的目標的位置和類別,如圖2所示。
圖2中,每個網(wǎng)格均需要對目標候選框位置、候選框含有目標物體的置信度、候選框內(nèi)目標的類別及該候選框預測的準確度進行預測。其中目標候選框位置會給出B個預測值,每個預測值為一個包含四個元素的向量(x,y,w,h)。其中,(x,y)分別為目標候選框左上角點的橫縱坐標,(w,h)分別為目標候選框的寬度和高度。候選框還有目標物體的置信度為一個0到1之間的值。此外,模型會對候選框內(nèi)的目標進行類別預測,若存在C個類別,則給出C個對應類別的置信度。候選框預測的準確度計算公式為:
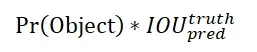
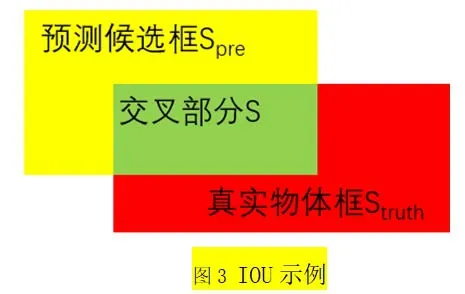
其中,Pr(Object)為目標中心落在該網(wǎng)格內(nèi)的情況,若目標落中心在該網(wǎng)格內(nèi)則其值為1,否則為0。第二項則為預測候選框和真實物體框的IOU值,圖3為IOU示例。
IOU計算方式為:
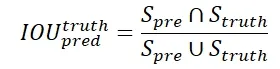
每個網(wǎng)格輸出一個S*S*(5*B+C)的向量作為該網(wǎng)格的預測值。
訓練YOLO時,損失層使用的損失函數(shù)為:
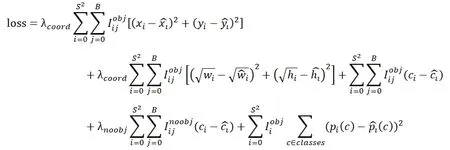
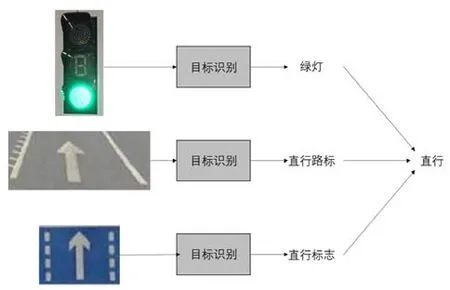
圖4 自動駕駛決策流程示例圖
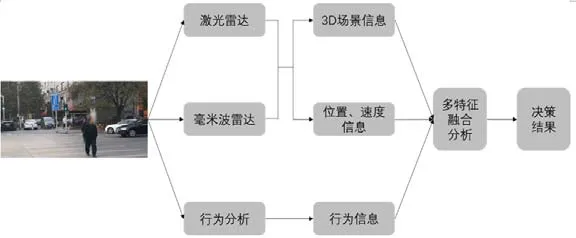
圖5 多特征行人軌跡預測流程示意圖
該損失函數(shù)每項都含有I,使得只有當存在目標中心落在網(wǎng)格內(nèi)時才會產(chǎn)生誤差損失,并且每個格子僅對中心落在其內(nèi)的目標產(chǎn)生損失。
而由于在目標檢測時,大部分網(wǎng)格內(nèi)不含目標的中心點,如果對每個網(wǎng)格預測值取相同權重則容易過擬合,因此對于沒有目標的網(wǎng)格其權重設置為一個小于1的值,而有目標的網(wǎng)格其權重設置為1。同時,由于候選框位置預測結果的向量維度通常小于類別數(shù)目,若兩者權重一致也不合理,因此在位置預測損失項前加入權重一個大于1的值,而類別預測損失項權重為1。當類別預測數(shù)量小于位置預測結果維度時,的值應調(diào)整為小于1。
在檢測到目標后仍可使用計算機視覺技術對交通信息進行識別,例如對于紅綠燈信號信息可直接通過RGB值進行判斷,對于道路交通標志牌或道路地標可使用模板匹配或目標識別算法(圖4)對其內(nèi)容進行識別,而對于道路車道線可使用Candy邊緣檢測等方法進行檢測。
計算機視覺技術用于自動駕駛決策流程示例圖如圖4所示。
2.2用于環(huán)境感知的計算機視覺技術
目前環(huán)境感知工作主要由激光雷達、毫米波測距雷達等精密儀器完成,但是仍需要計算機視覺技術在環(huán)境感知中發(fā)揮輔助作用。
在自動駕駛系統(tǒng)中,通常使用激光雷達測量遠距離物體距離,使用毫米波雷達測量近距離物體距離。但是使用雷達進行測距受天氣影響極大,在大雨、濃霧、濃煙等環(huán)境中激光傳播距離急劇衰減,例如,在晴天時CO2激光雷達作用距離可達10至20千米,而在壞天氣時,其作用距離會降至1千米以內(nèi)。以高清視頻圖像為基礎的目標檢測雖然也會受到惡劣天氣的影響,但相較激光雷達而言其所受影響較小,仍可對遠距離物體進行一定程度的識別。
另一方面,對于行人這樣的小目標,Stixel(sticks abovethe ground in the image,棒狀像素)是目前效率最高的行人檢測方法,它是2008年由奔馳和法蘭克福大學Hern’an Badino教授推出的一種快速實時檢測障礙物的方法,其每秒檢測幀數(shù)可達到100幀以上。此外Stixel還可用于生成可行駛區(qū)域。
3 計算機視覺技術在自動駕駛中的發(fā)展
目前自動駕駛中面臨著小目標、強遮擋、高動態(tài)三大難題。而自動駕駛環(huán)境中的行人同時具備了這三種特征。因此,行人檢測是自動駕駛需要重點解決的問題。
行人相較車輛最大的特點就是其運動方向難以預測,如果自動駕駛車輛檢測到行人就剎車等待行人通過,在人流量較大的路口將難以前進;而若自動駕駛車輛在判定安全可通行時,行人突然加速或變向則很可能發(fā)生交通事故。因此僅僅根據(jù)行人是否靜止及行人當前的運動速度判斷行人接下來的運動軌跡是無法保證行車安全的。
由于行人的運動模式具有復雜性,因此在對行人進行運動軌跡預測時需要考慮多特征多模態(tài)。預測行人運動軌跡時,首先要解決的問題就是行人的行為分析,即分析行人接下來準備采取的行動。例如,一個行人站在路旁,有可能是在等待合適的通行時機穿過街道,也可能是單純的在等待某人。此時如果能根據(jù)一些特征,如行人是否在留意往來車輛,識別出該行人的行為,就能輔助自動駕駛汽車做出正確的行為決策。又如,一個行人正在橫穿馬路,如果其注意到了來往的車輛,其突然加速或變向的可能性就會很小,而若其未注意來往車輛,則此時自動駕駛汽車應注意對此人進行避讓,防止其突然加速或變向。使用計算機視覺技術,對行人進行行為分析,有助于自動駕駛系統(tǒng)做出更正確的決策。
同時,多種傳感器會傳回多種模態(tài)的數(shù)據(jù),利用這些數(shù)據(jù)可以提取到行人的多種特征包括行人朝向、位置、行為、前進速度、前進途徑是否有障礙等。在預測行人運動軌跡時,需要將這些來自不同傳感器的多種特征結合起來,進行綜合分析。圖5為使用多特征進行行人軌跡預測的流程示意圖。
4 總結
隨著人工智能技術及精密儀器的發(fā)展,自動駕駛技術已取得了一定的成果,但是由于真實駕駛環(huán)境的復雜性,自動駕駛仍面臨著如小目標難檢測、被遮擋目標難識別、高動態(tài)目標難預測等問題。計算機視覺技術在自動駕駛中發(fā)揮了極其重要的作用,但是這些難題不是單一學科的發(fā)展能夠解決的。要解決這些問題必須綜合各學科的長處,從多種角度出發(fā),利用多個模態(tài)的信息進行綜合分析。
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
軍民兩用技術與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
科技傳播(2019年22期)2020-01-14 03:06:34
消費導刊(2017年20期)2018-01-03 06:26:40
家庭影院技術(2017年9期)2017-09-26 03:41:45
