基于差分隱私保護的譜聚類算法
2018-11-23 00:58:50鄭孝遙陳冬梅劉雨晴汪祥舜孫麗萍
計算機應用 2018年10期
關鍵詞:實驗
鄭孝遙,陳冬梅,劉雨晴,尤 浩,汪祥舜,孫麗萍
(1.安徽師范大學 計算機與信息學院,安徽 蕪湖 241002; 2.網絡與信息安全安徽省重點實驗室(安徽師范大學),安徽 蕪湖 241002)(*通信作者電子郵箱zxiaoyao_2000@163.com)
0 引言
近年來,隨著互聯網與信息技術的蓬勃發展,海量數據的產生可以為研究者們提供許多有效的信息資源,對這些海量數據進行挖掘分析可以得到非常有價值的信息,其中聚類分析是有效手段之一,但是在聚類的過程中也存在著隱私泄露的風險。
目前,國內外研究者圍繞隱私安全保護問題做了大量的工作,從已有的隱私保護技術來看:k-匿名及其擴展的保護模型技術已被廣泛使用。該方法通過存儲至少k條記錄來隱藏一條數據記錄從而達到隱私保護的目的,但是在攻擊者掌握特定背景知識的情況下,它就存在不能抵抗一致性攻擊的可能。為了克服這一缺點,研究者們不斷嘗試加以改進而出現了l-多樣性[1]、t-鄰近[2]、(a,k)-匿名[3]、泛化和隨機化[4]等隱私保護技術。
如今關于聚類分析在隱私保護方面的應用越來越多,而且聚類作為數據挖掘和機器學習的主要技術之一被廣大學者所研究,聚類分析中常用的隱私保護技術有數值擾動、數值旋轉、數值匿名等方法。Oliverira等[5]在2004年提出一種基于新的空間數據轉換方法RT(Rotation-based Transformation),該方法的基礎是基于幾何的旋轉變化來隱藏信息,并能保證旋轉前后的屬性依舊具有有效性;其缺點在于只能對低維度的數據進行變換,維度較高時會損耗數據的真實信息,計算量也較大,并且難以避免一致性攻擊造成的隱私泄露。Mukherjee等[6]在2006年針對文獻[5]算法不易推廣到其他應用場景中的問題而提出了一種新的采用傅里葉變換的數據擾動方法,其優點是在實現敏感信息隱藏的同時能夠保持數據值的有效性,并保證歐幾里得集中式和分布式場景中的距離精度很高。目前的研究在聚類的基礎上加上差分隱私技術的研究還不夠成熟,最早提出這一想法的是2005年Blum等[7]給出的利用差分隱私和k-means相結合的算法,使用管理員的身份將噪聲引入到查詢響應中來維護單個數據庫條目的隱私。隨后Dwork等[8]在2010年對基于差分隱私的k-means算法進行了更進一步的分析和改進,提出了一種可以計算查詢函數和查詢序列敏感度的算法。國內的李楊等[9]提出了ε-差分隱私保護下的IDPk-means方法,該方法可以應對攻擊者具有任意背景知識的攻擊,并且很好地改善了數據聚類后的可用性問題,但是此方法不能解決分布式環境下的隱私泄露安全問題。因此,在2016年李洪成等[10]提出了在分布式環境下滿足ε-差分隱私的k-means算法,解決了傳統隱私保護模型無法在分布式環境中應對任意背景知識攻擊的問題。吳偉民等[11]基于文獻[9]提出了滿足ε-差分隱私保護的DP-DBScan算法,是應對傳統的DBScan聚類算法存在的隱私泄露問題而研究出來的,該算法的實驗結果表明與傳統的DBScan聚類算法相比,加入拉普拉斯噪聲的DP-DBScan算法能保持數據的有效性并實現隱私保護。劉曉遷等[12]基于聚類的匿名化技術,并利用差分隱私保護模型對發布數據進行保護,該方法通過聚類實現匿名化,對匿名分化的數據添加隨機噪聲來擾動數據的真實值以實現隱私保護,并提高數據的可用性。目前,針對聚類方法結合差分隱私的研究還比較少,本文主要針對譜聚類算法,開展基于差分隱私保護的譜聚類算法研究。
本文主要針對聚類算法存在隱私泄露的問題,利用譜聚類算法將社交關系圖網絡化,使得具有社交關系的聚類在一起,為了防止這種社交關系泄露,在通過相似性函數計算權重時加上差分隱私的拉普拉斯隨機噪聲來進行擾動達到隱私保護的作用。
1 相關工作
1.1 譜聚類算法
目前,譜聚類算法在國內得到廣泛的應用和研究,最常應用的領域有機器學習、大數據挖掘、圖像分割、文本挖掘等[13]。該算法的流程簡單,并且與傳統的k-means和最大期望(Expectation Maximization, EM)算法相比適用性更強,在任何的數據樣本空間中都會聚類出最好的聚類效果。譜聚類的主要思想是基于圖譜理論的分割技術,該算法將樣本數據看成無向帶權圖中的一個個頂點,然后利用相似性函數計算出各頂點之間的值,權重值代表各個頂點間的相似度,然后采用圖譜的分割準則將數據分割聚類。
一般譜聚類算法的相似性函數采用余弦函數和高斯函數,具體定義如下:
(1)

(2)
圖分割算法準則主要有以下幾個準則:
1)圖分割最小分割法準則:
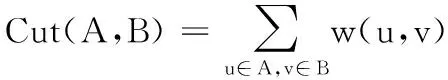
(3)
2)規范化分割準則:
(4)
3)最小最大分割準則:
(5)
4)比例分割準則:
(6)
譜聚類算法的主要算法流程如算法1所示。
算法1 譜聚類算法。
輸入n個數據點集,聚類數目k。
輸出 得到k個簇劃分。
a)通過高斯核函數的距離公式計算相似性矩陣;
b)利用相似矩陣構建鄰接矩陣N和度矩陣G;
c)由第b)步得到的鄰接矩陣和度矩陣求出拉普拉斯矩陣L=G1/2NG1/2;
d)得到拉普拉斯矩陣后選取前k個最大特征值對應的特征向量;
e)將特征向量標準化,然后將樣本數據點映射到基于一個或多個確定的降維空間中去;
f)基于新的數據點空間,將特征矩陣的每一行看成一個樣本點利用k-means將它聚為k類。
1.2 差分隱私
差分隱私保護模型具有嚴格的數學理論基礎,該模型的基本思想是對數據添加噪聲來達到隱私保護的目的[14]。該保護方法不需要關心攻擊者的強大計算能力和任何的背景知識,即使攻擊者擁有除一條記錄以外的所有數據記錄也能保證這條記錄的敏感信息不會被披露,這種機制能夠對樣本數據中個體敏感信息進行特定的保護,而且還不會引起數據分布的變化。差分隱私的具體定義如下:
定義1 假設數據集D和D′是相鄰數據集,兩個數據集完全相同或至多相差一條數據記錄,給定一個隨機算法S,Range(S)是算法S的取值范圍,RM是數據集上的輸出結果, Pr[X]是事件X的披露風險,則算法S滿足ε-差分隱私的保護模型定義:
Pr[S(D)=RM]≤exp(ε) Pr[S(D′)=RM]
(7)
隱私披露風險的值由隨機算法S控制,通過限制ε的大小來控制隱私保護的安全度:ε越小引入的隨機噪聲越大,隱私保護安全性越高;ε越大引入的隨機噪聲越小,隱私保護安全性越低。
定義2 對于函數F:D→Rd的敏感度定義如下:
(8)
其中:‖*‖1表示一階范數;F是查詢函數;d是記錄數據的屬性維度;D和D′是至多相差一條數據記錄的數據集;R表示的實數空間。
由定義1可以看出隨機函數的選擇與攻擊者的背景知識無關,所以任意一條記錄的增加或者刪除都不會影響查詢結果的輸出。該定義從理論上滿足了差分隱私對隱私披露風險的要求,而具體的實現還是依靠添加噪聲機制來實現。
1.3 兩種噪聲機制
實現差分隱私保護的噪聲添加機制有兩種:一種是基于數值型的拉普拉斯噪聲機制;另一種是針對非數值型數據的指數機制[15]。
1.3.1 拉普拉斯噪聲機制
文獻[16]中提出了對于數值型的數據采用拉普拉斯機制對數據的真實值進行擾動來達到隱私安全保護。其定義如下:
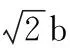
Laplace(b)=exp(-|x|/b)
(9)
其概率密度函數表達形式是:
p(x)=exp(-x/b)/(2b)
(10)
其累積分布函數的表達形式是:
D(x)=[1+sgn(x)×(1-exp(x/b))]/2
(11)
其概率密度函數如圖1所示。
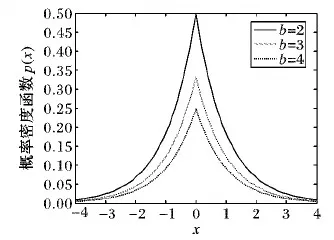
圖1 拉普拉斯概率密度函數Fig. 1 Laplace probability density function
假設數據集為D,查詢函數是F,查詢結果是F(D),添加噪聲的函數為W,其響應值定義如下:
W(D)=F(D)+Laplace(ΔF/ε)
(12)
則稱W(D)滿足ε-差分隱私保護。
1.3.2 指數機制
Laplace機制僅適用于查詢結果是數值型的數據,而在實際的生活應用中許多數據的查詢是非數值型的,因此在文獻[8]中提出了一種非數值型的算法。該算法定義如下:設隨機算法F,查詢結果集為R,t是R中某一個體,在這種機制下函數u(D,t)中t是所有輸出項的選中項。若算法F以exp((εu(D,t))/(2Δu))的概率從查詢結果集中選擇并輸出的是t,那么稱此算法滿足ε-差分隱私的保護模型定義。
由此可以看出,當ε越大,被選出輸出的概率就越大;當ε較小時,選中輸出的概率就變小。
2 差分隱私保護的譜聚類算法分析
2.1 算法描述
與傳統的k-means相比,基于圖分割理論的譜聚類算法的適用性更強,不容易陷入局部最優解,能夠對社交網絡中非凸型的數據進行聚類。該算法把數據點看成一個個頂點,然后利用相似矩陣將樣本點鏈接一起,采用子圖最優的分割理論來劃分。其中相似矩陣計算的是兩個樣本點之間的權重值,而這種權重可以理解為樣本點的親密度。對于數據的發布者來看,如何在發布數據的同時不泄露它們的親密度關系是本文的研究重點。因此本文采用差分隱私結合譜聚類的方法,在相似性矩陣上加上滿足拉普拉斯分布的隨機噪聲來達到隱私保護的目的。
基于差分隱私的譜聚類算法流程如下:假設p={p1,p2,…,pn}和q={q1,q2,…,qn}是n維空間中的兩個樣本集,譜聚類算法的原理就是利用相似性函數計算樣本數據集的相似性,值越大相似性越高,聚為一類的可能性就越大。同時這種相似性也可以理解為社交網絡中的關系親密度,為了確保這種親密關系不被泄露,在計算相似性時加上差分隱私的拉普拉斯噪聲來隱藏潛在的數據信息,從而實現隱私安全的保護。
算法2 基于差分隱私的譜聚類算法。
輸入 UCI數據集data。
輸出 標簽label。
1)
定義聚類種類k,根據給定的label計算出k的值;
2)
初始化k_near=100和?=0.9;
3)
fori=1 torow
4)
forj=1 torow
5)
ifi≠j
6)
dis_matij←exp(-‖pi-qj‖2/(2σ2));
7)
dis_matii←0;
8)
end if
9)
end for
10)
end for
11)
保留k_near的權重值Affinity[i,j],根據積累分布函數(11)生成隨機噪聲,并添加進去;
12)
計算度矩陣和拉普拉斯矩陣的值du[i,j]、laplas[i,j];
13)
求拉普拉斯矩陣的前k大特征值和對應的特征向量;
14)
15)
利用k-means進行聚類,得到聚類后的label值;
2.2 算法分析
3 實驗
3.1 實驗數據集
本文采用來自于UCI Knowledge Discovery Archive database (http://archive.ics.uci.edu/)數據集中的liver、 pima、sonar、balance四個數據集進行實驗。各數據集信息如表1所示。
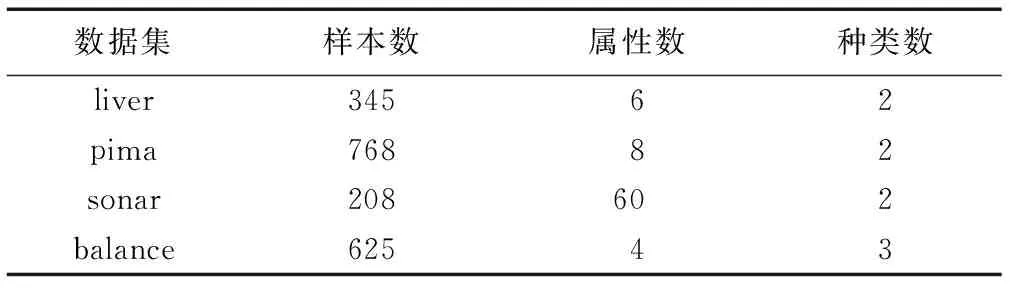
表1 UCI數據集Tab. 1 UCI datasets
本文首先對四個數據集liver、 pima、sonar、balance進行預處理,使其每個屬性值都在區間[0,1],對四個數據集分別進行譜聚類算法和差分隱私譜聚類算法實驗,因為實驗的偶然性,所以進行20次實驗,對比20次實驗結果的平均值。然后調整相似性函數σ的值,如0.1、0.5、0.9、1、2、4、6、8、10和12來確定最佳的聚類狀態,并用精確度作為聚類結果的輸出。從圖2可以看出,聚類效果比較好的σ維持在1~2。

圖2 參數σ對聚類結果的影響Fig. 2 Effect of parameter σ on clustering results
3.2 實驗配置環境
主要采用Matlab軟件編程來實現本文算法。實驗的軟硬件環境如下:
1)硬件環境配置:Intel i5 處理器,4 GB內存。
2)軟件環境配置:Matlab R2013b編程軟件,操作系統Windows 7 64位旗艦版。
3.3 實驗結果與分析
根據前文的實驗設置,本文完成了四個數據集上的對比實驗,圖3~6分別給出了四個數據集擾動前后的實驗對比情況。
由圖3可知,對于數據集liver,運用差分隱私的譜聚類算法和只用譜聚類算法在聚類效果上是差不多的,說明本文算法可以在具有隱私保護的前提下,保證了數據集liver的聚類有效性。
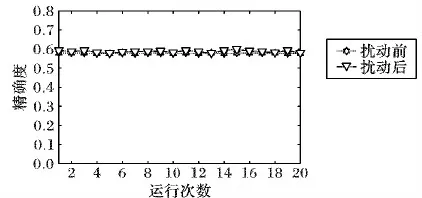
圖3 liver數據集擾動前后的精確度結果比較Fig. 3 Accuracy results comparison of dataset liver
由圖4可知,對于數據集pima,精確度平均分布在0.6~0.7,分布較為穩定,而擾動前后的對比,雖然總體上是加擾動前聚類效果要好,但是此條件下并不能滿足隱私保護,所以擾動后的算法仍然具有可用性。

圖4 pima數據集擾動前后的精確度結果比較Fig. 4 Accuracy results comparison of dataset pima
由圖5可知,對于數據集sonar,其運行的總體情況是加入拉普拉斯噪聲要比不加噪聲好,精確度平均分布在0.5~0.6,而干擾后的算法在隱私保護的前提下可以達到聚類效果的最好狀態。

圖5 sonar數據集擾動前后的精確度結果比較Fig. 5 Accuracy results comparison of dataset sonar
由圖6可知,對于數據集balance的運行結果總體都比未擾動的效果更好,其精確度的平均值穩定在0.4左右,而加入擾動后的值平均在0.5左右,提高了聚類的有效性。同時,經過擾動后的權重因隨機點的選取,可能會出現樣本點更好的聚類在樣本中心點附近,所以出現擾動后結果優于擾動前。

圖6 balance數據集擾動前后的精確度結果比較Fig. 6 Accuracy results comparison of dataset balance
對比圖3~6,對于不同的四個數據集,在與譜聚類算法和差分隱私譜聚類算法對比實驗中,擾動前的精確度總體比擾動后的結果要高一些。總體來說,本文算法在實現隱私保護方面具有較好的成效,同時得到的聚類精確度也較高。
4 結語
本文針對傳統的聚類算法存在隱私泄露的風險,以及幾個經典的聚類保護算法,如k-means、DBScan、k-medoids等,在社交網絡應用中還存在的一些不足,利用譜聚類算法對處理凸型的空間數據和高維度的數據不容易陷入局部最優解的優勢,開展具有隱私保護的譜聚類算法研究。首先計算樣本數據集之間的樣本相似性作為數據點之間的權重值,再利用差分隱私算法對權重值添加拉普拉斯分布的隨機噪聲,通過干擾權重值達到隱私保護的目的。實驗結果表明,干擾后的數據不僅可以實現隱私保護,還保證了聚類的有效性。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
