基于BP神經網絡的應聘人員與崗位匹配度模型設計與應用
2018-11-22 02:24:02四川中電啟明星信息技術有限公司張開智關利海
電子世界 2018年21期
四川中電啟明星信息技術有限公司 張開智 關利海 林 云
隨著信息技術的發展,企業已普遍使用網絡招聘平臺作為主要的招聘工具,且能夠更高效的招聘到所需人才。本文重點對應聘人員的勝任力因素進行分析,并基于BP神經網絡算法構建應聘人員與招聘崗位匹配度類模型,應用于企業招聘過程中應聘人員的簡歷分類、人員篩選,為企業招聘工作效率的提升及信息系統的改進提供參考。
1 引言
人力資源作為企業中最核心的資源, 尤其需要對人崗匹配實現最優化。人崗匹配有兩層含義:一是崗位所要求的能力需要有人完全具備;二是某人具備的能力完全能勝任此崗位素質要求。在招聘畢業生工作中,需重點關注崗位所要求的條件與應聘人員的符合程度。在企業信息化管理水平不斷提升的大背景下,人力資源部門招聘方式、招聘管理工具也呈現出系統化、標準化趨勢。企業通過構建個性化的招聘管理系統,實現招聘過程管理的全覆蓋,可有效提高招聘工作效率、降低招聘成本,同時也提高了公司的品牌影響力。但是,在實現招聘信息化管理后,仍然發現在應聘人員的簡歷篩選、崗位符合程度的判斷,仍需要投入大量人力來通過線下完成、且篩選效果不理想,入職后人員流失率較高。因此,針對應聘人員的崗位匹配度、關鍵勝任因素,通過應用分析框架、數據挖掘、模型創建、訓練驗證等大數據分析步驟進行深入研究,為進一步提高企業人員招聘入職率與招聘工作效率做理論指導與參考。
2 構建應聘人員與崗位匹配度評價指標體系
應聘人員與崗位匹配度評價指標體系設計的原則:評價指標應盡量可以量化,如學歷、外語水平等,保證評價的客觀性;評價指標與崗位職責要求統一原則;依據以上原則,本文以應聘人員的學歷、院校類型、所學專業、籍貫、外語水平五個評價指標做為匹配的主要因素,如表1所示。
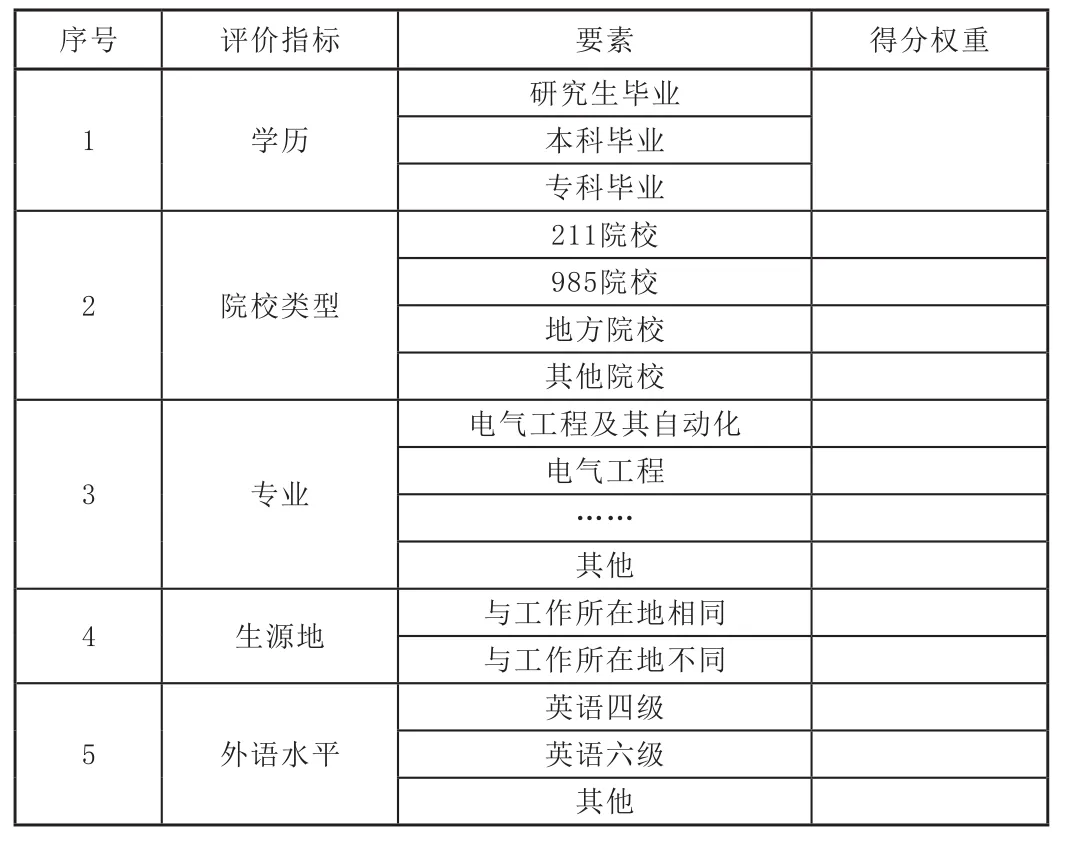
表1 應聘人員與崗位匹配度評價指標體系
3 基于BP神經網絡的應聘人員與崗位匹配度模型
當確定應聘人員評價指標后,把應聘人員的某一評價指標視為一個輸入項,結合崗位要求以員工評價指標的具體得分做為該輸入項的值,經過網絡計算產生的輸出為該人員與所應聘的崗位匹配度系數。
人工神經網絡是數據挖掘技術之一,其中誤差反向傳播( error back propagation,BP) 網絡由于結構簡單和從樣本中提取規則的強大能力而使它應用最為廣泛。在實際應用中,選擇相似崗位已錄用優秀人員做為樣本數據,并對其進行反復訓練,訓練后所獲取網絡的各神經元間相互聯接的權值就能反映該匹配模型的特征,這時把新的應聘人員特征值輸入,網絡模型就能計算出人員與崗位的匹配結果。BP網絡使用BP算法來對網絡中各層間的權系數進行修正,逼近任意非線性函數,屬于一種有指導的學習算法( 即需要歷史樣本數據訓練網絡) ,常用于預測、分類、評價處理。對于 BP 網絡有一個非常重要的定理,即對于任何在閉區間內的連續函數都可以用單隱含層的 BP 網絡逼近,因而一個三層的 BP 網絡就可以完成任意的 n 維到 m 維的映射?。本文采用的是的隱含層為一層的三層BP神經網絡模型,如圖1所示。
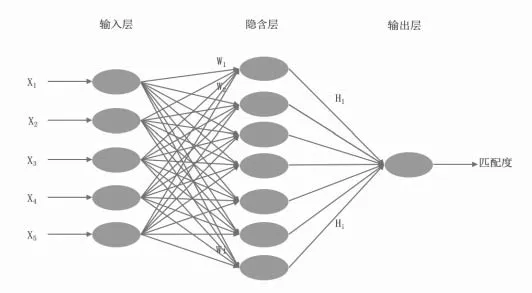
圖1
Wij為輸入層與隱含層之間連接單元的權重值,Hi為隱含層與輸出層之間連接單元的權重值。在BP神經網絡中,誤差函數如下:
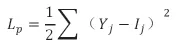
我們對每一層的輸出進行非線性的轉換,f為非線性轉化函數,又稱為激活函數,定義如下:
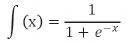
4 應聘人員與崗位匹配度模型訓練
通過選擇上一年度應聘人員做為訓練數據,計算各項指標權重系數,并有針對性的篩選典型已錄用人員與未錄用人員,經過專家評判建立訓練數據矩陣(表2)。
設置網絡隱含層神經元個數為7,訓練次數為8萬次,其計算輸結果分別為:[[0.99971218]、[0.99698468]、[0.00175201]、[0.00181902]、[0.00153838]],與預期結果已經非常相近,說明BP神經網絡能夠準確的模擬應聘人員與崗位的匹配度計算,且具有較高的精度。
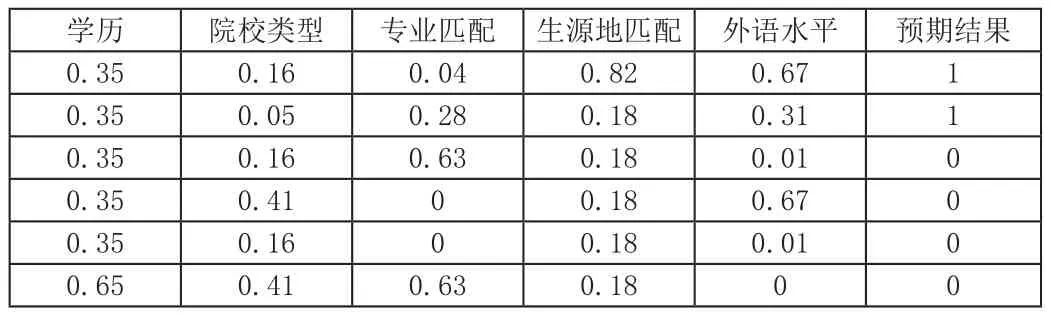
表2
經過訓練獲得的W1-i神經元權重系數矩陣:

經過訓練獲得的H1-i神經元權重系數矩陣:
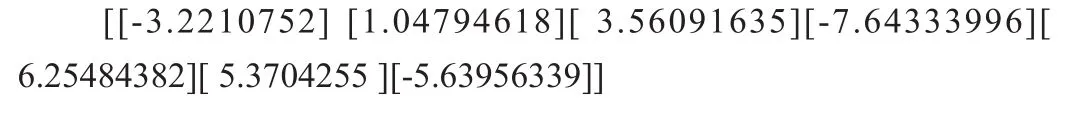
5 應聘人員與崗位匹配度模型應用
以新應聘人員的各項評價指標得分做為輸入,代入應聘人員與崗位匹配度模型,由此計算出的結果做為崗位匹配度評判系數。基于BP神經網絡的應聘人員與崗位匹配度模型擁有不斷學習的能力,可以有效地克服傳統評價方法中指標權重的人為影響因素,具有更開放、更靈活的特點。

表3
6 結語
本文對應聘人員與崗位匹配度模型及評價指標體系的構建進行了探討,將人工智能理論BP神經網絡算法應用 于解決招聘過程中應聘人員與崗位匹配度的學習與計算,構建了人崗匹配評價模型,可用于人員與崗位匹配度預測,也可提高應聘人員簡歷分類與篩選效率。其突出優點就是具有很強的非線性映射能力和柔性的網絡結構。網絡的中間層數、各層的神經元個數可根據具體情況任意設定,并且隨著結構的差異其性能也有所不同。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
