基于本體的信息推送技術研究
2018-11-22 02:23:56沈陽理工大學信息科學與工程學院鄒依彤
電子世界 2018年21期
沈陽理工大學信息科學與工程學院 鄒依彤
引言:文章主要介紹個性化推送服務中的三個方面:本體、用戶興趣模型的建立和最后的推送機制,從而證明方法的有效性。
1 關于本體的建立
1.1 本體
本體是概念的集合,它的五個要素是概念、規則、屬性、關系、實例。
因此,可將本體形式化的表示為:(C,AC,R,AR),其中:C是概念集合,表示的是對象的集合,包括概念的名稱以及概念所表示的“事物”,也就是實例。AC表示的是每一個概念所具有的屬性的集合。屬性包括:名稱、解釋(定義)、值域、數據類型、舉例。如:電影屬性包括:電影代碼、電影片名、上映時間、電影類型、導演、演員、適用對象。而電影類型的屬性又包括:名稱、解釋、數據類型、實例。R是概念之間關系的集合,主要考慮概念之間的父類、子類、以及上下位等層次關系。類之間的關系一方面定義了類的公理:如:等價類、全不同、不相交等客觀關系,另一方面定義了概念之間的相互作用:如:previous、hasPart、isPartof、requires,也可定義概念之間的特殊關系。AR是每個關系的屬性集合。
1.2 本體的構件流程
構建領域本體時,流程如下:1)確定構建領域本體的應用范圍;2)舉出領域內的關鍵術語、概念;3)查找已有的相關本體進行復用;4)定義類并構建層次結構圖;5)定義領域本體的相關規則;6)定義類的屬性;7)創建實例;8)利用后續實驗對本體的構建進行評價及推理檢驗,一旦出現問題,就需要對類的層次結構圖及領域本體規則重新加以改進。
建立好本體模型之后,當用戶想搜索某個主題時,就不僅得到了關于該主題的解釋,而是把和該主題相關的內容、以及該主題的例子都推送給了用戶,實現數據之間的關聯。
2 用戶的興趣模型
主動推送服務的個性化主要體現在針對不同的用戶提供最符合用戶需求和最感興趣的服務列表,主動推送的前提是對用戶的需求進行語義分析,根據用戶的偏好等因素選取并推薦服務,為了對各種類型的網絡資源實現個性化的服務推薦,就必須了解用戶的個性化需求,這就需要獲取、分析用戶信息,建立合適的用戶興趣模型。用戶興趣模型是服務推送的前提,是個性化服務的基礎,直接涉及到服務的質量。
2.1 用戶的興趣模型的建立步驟
首先進行文檔預處理,其目的是抽取特征詞并計算各特征詞的權重,步驟如下:①詞匯分析:刪除一些對文檔校驗無關的詞,并處理一些特殊字符,比如數字、連字符以及字母大小寫等;②詞干提取:即詞根化處理(在中文里就是分詞過程);③訓練文檔聚類;④選取特征詞。
下面介紹這一過程涉及到的幾個重要算法:
步驟②中,傳統的分詞方法是逆向最大匹配分詞法,但是由于該方法只能驗證是否匹配成功,而無法對匹配成功的詞條進行記錄,因此從簡單、減少歧義的角度出發,也便于后續工作,分詞技術采用改進后的逆向最大匹配分詞法,其基本過程為:首先計算出詞表中最長的詞,將其長度記為n,則循環從句首截取長度為n的字符串,讓它去匹配此表中的字符串,如果此表中有候選詞匹配成功,則在文檔中刪除該字符串,并記錄下每一個匹配成功的字符串,循環上述步驟,設定循環結束的條件為句子長度為空,循環結束。當在此表中找不到任何一個詞條與當前候選字符串匹配時,就將該字符串的首字符刪去,用截取后的長度為n-1的字符串去和詞表中的詞條相比對,若仍匹配失敗,則繼續在其頭部刪除一個字符,用長度為n-2的字符串進行匹配,直至匹配成功。例如:若有這樣一個句子:我愛北京天安門,假設詞表中最長的詞有四個字,則n=4,則第一次從句尾抽取長度為4的字符串,顯然“京天安門”存在字符串的耦合,因此在詞表中未查到該詞,匹配失敗。則需刪除字符串首字符得到“天安門”,在詞表中找到該詞條,匹配成功,并將其記錄下來,以此類推,最后句子被切分為由特征詞構成的“我/愛/北京/天安門” 全部切分完畢,生成分詞結果。之后將經過分詞處理后的特征詞,進行權重的計算,從而合理地篩選出有意義的特征詞,減少冗余特征詞對后續工作造成的干擾。
步驟③中,訓練文檔的聚類,這一步驟的目的:一是要足夠體現目標文檔的特征,二是要能將目標文檔與其他類文檔區分開。因此需要對文檔進行特征選擇,常用的特征算法主要有:文檔頻率、信息增益、文本證據權等。其中,應用較廣泛、各方面性能較好的是信息增益算法,該算法描述如下:
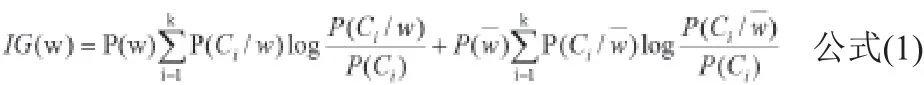
其中,P(w)是指詞條w在文檔集中出現的概率;P(ci)為第i類文檔出現的概率,即此類型的文檔數量與全部文檔數量之比;P(Ci /w)為詞條w與ci類文檔共同發生的條件概率。從公式中可看出,雖然考慮某類文檔中某些詞條不出現的概率,具有其合理性,但它對分類造成的影響遠小于文檔中詞條出現的概率,因此,對該公式加以改進,使其具備更好的合理性。由于本公式的第一項對分類結果是強相關的,因此引入文本證據權參數,文本證據權本身是用來增大P(Ci)和P(Ci/w)之間的差異,但是該參數加到該公式中,作用是增大P(ci/ w)和之間的差異,設定w和類別強相關,使第一項式子值增大,提高其權重,從而增大詞條出現的概率對分類造成的影響。改進后的信息增益公式如下:
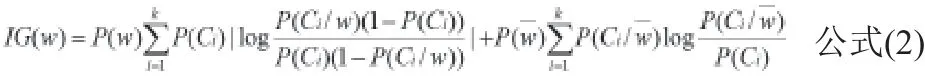
步驟④:選取特征詞過程中,首先要對特征詞項進行權重的計算,是指通過考察詞條在文檔中出現的次數等相關信息,確定其對文本內容的價值,這里采用歸一化的TF-IDF權重計算法來求取特征詞的權重。該算法的思想是:不同類別的文檔中在特征項的出現頻率上會有很大差異,因此文本分類時特征詞的選擇應該重要參考特征項的頻率信息,得出這樣一個判斷:如果某個候選特征詞在大多數文檔中出現的頻率都較高,那么這樣的特征詞就不如那些只在某些文檔中出現的特征項重要。
2.2 訪問興趣度的計算
首先根據用戶一次訪問中形成的所有特征詞的權重,建立訪問向量,它是用戶一次訪問的形式化表示。將其描述為:
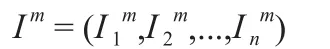
其中,Iim表示用戶第m次訪問的特征詞Fi的權重大小,該向量可由文檔集矩陣D生成,將文檔集矩陣作行映射即得到用戶的訪問向量對于用戶的任意一次訪問,用戶之前的所有訪問歷史由用戶的前n次訪問的訪問向量構成。
經上述處理后,得到的矩陣就是降維后的用戶訪問歷史矩陣,為了方便對后續工作的描述,將該矩陣稱為初始用戶興趣矩陣。
接下來依據特征詞分類規則,采用Rocchio分類器對用戶興趣初始矩陣中的特征詞進行分類,其基本思想是使用訓練集為每個類構造一個原型向量,給定一個類,訓練集中所有屬于這個類的特征詞對應向量的分量用正數表示,所有不屬于這個類的特征詞對應向量的分量用負數表示,然后把所有的向量加起來,得到的和向量就是這個類的原型向量,定義兩個向量的相似度為這兩個向量夾角的余弦,逐一計算訓練集中所有特征詞和原型向量的相似度。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
湘江法律評論(2016年0期)2016-06-15 20:29:32
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
