基于專利保護的深度學習領域應用與發展研究
2018-11-21 19:14:46李婧雯
科學與財富 2018年29期
關鍵詞:深度學習
李婧雯
摘 要: 近年來,隨著計算能力的大大提高,基于海量數據和大規模參數的深度學習技術快速發展,引起了學術界和工業界的廣泛關注。
本文從專利保護的角度對深度學習的發展與應用展開了研究,通過對國內外重要申請人的專利申請量進行了統計與分析,同時對重要專利展開了研究與擴展,從知識產權的角度闡述了深度學習技術的應用和發展趨勢。
關鍵詞: 深度學習;專利申請;知識產權;技術發展
第一章綜述
1.1 背景和研究意義
近年來,在搜索引擎、推薦系統、圖像識別、語音識別等諸多領域,深度學習有著諸多重要的應用。傳統的統計機器學習中,一般要求模型使用者有大量領域知識作為基礎,需要對模型進行很多特征工程和人工調節,而且模型學習到的信息較為淺層。深度學習則利用大量的參數和數據,可以學習較為深層的特征。隨著互聯網產生海量的數據,深度學習得到了快速的發展,性能得到快速的提升[1]。
1.2 研究方法
本文數據來源于德溫特世界專利索引數據庫(DWPI)和中國專利文摘數據庫(CNABS),統計時間截止至2017年5月9號。在專利申請人的選取上,本文主要按照工業界和學術界兩個維度進行選擇,在學術界選取中科院、清華大學、北京大學、哈工大四所高校,學術界則選取了阿里巴巴、騰訊、百度三家主要的企業;同時,為了對比國內外此領域的發展狀況,我們還選取了部分國外的申請人進行分析,包括IBM、谷歌、微軟3家企業。
本文使用IPC結合關鍵詞的檢索方法進行研究,局限在單個IPC內進行檢索可能會由于分類不準導致漏檢,而單獨使用關鍵詞可能會導致引入檢索到很多不相關的專利。因此本文采用的方法是在多個IPC內使用關鍵詞進行檢索,保證結果的正確性。此外,本文還使用了典型案例進行研究,深入分析了深度學習的技術結構,指出了未來專利申請或者審核中需要注意的要點。
第二章重要申請人專利統計及分析
本章通過統計深度學習領域重要申請人的專利申請情況,以此分析該領域國內外、學術界和工業界的發展情況。我們主要通過兩個維度進行分析:第一是各個申請人的申請總量對比,以此作為不同申請人類型發展情況的分析依據;第二是統計典型申請人按照時間專利申請量的變化趨勢,由此分析整個領域的發展趨勢。
2.1 重要申請人專利量統計
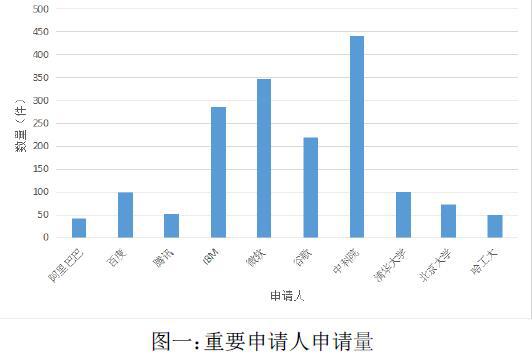
圖一反映了近5年基于深度學習領域重要申請人的專利申請情況,其中包括了多個申請人,在最近5年中深度學習領域的專利申請總量。
我們知道,在傳統機器學習領域中,大部分的專利都會來自于學術界、工業界的申請量會相對較小。但是從圖一可以看出,在深度學習領域,來自工業界的阿里巴巴、騰訊等也有一定的專利申請、并且數量與學術界的清華、北大等高校類似。說明國內工業界和學術界對此領域都非常關注。進一步分析,我們發現此領域是一個有著非常重要的實踐應用的領域,而不是一個僅僅局限在學術界的一個研究領域,很多深度學習技術,都可以直接應用到工業界的產品中,比如在搜索引擎中,需要判斷用戶的查詢與待檢索的文檔的相似程度,就需要利用自然語言處理判斷文本的語義距離,而深度學習近年來已被廣泛應用于自然語言處理。
換一個角度,隨著近年來人工智能尤其是深度學習的快速發展,從學術界的成果到工業界的產品的轉化周期越來越短,企業在這些領域的投入可以很快獲得收益,因此我們看到在深度學習領域,我們選取的幾個典型申請人中,工業界的專利申請量與學術界不相上下。由此可見,未來在類似的領域,尤其是深度學習和人工智能領域,專利保護的需求將會出現快速的增長。
其次,由圖一我們看出,國外企業相對于國內企業申請申請量更大,說明國內企業在此技術方向的投入不如國外企業大。我們分析其原因,國外的典型企業包括IBM、谷歌、微軟,都成立的單獨的實驗室用于前沿的學術研究,其中在深度學習領域有著較大的投入;相比之下,國內的企業目前在這方面的投入相對來講就低得多,因此在專利申請量方面自然也少了很多。由此,我們可以看出國外企業在深度學習領域已經取得了先發優勢,國內企業需要一定的時間和投入才能趕上最新的技術前沿發展,同時也需要注意專利領域的成果保護。
2.2 重要申請人申請量變化趨勢
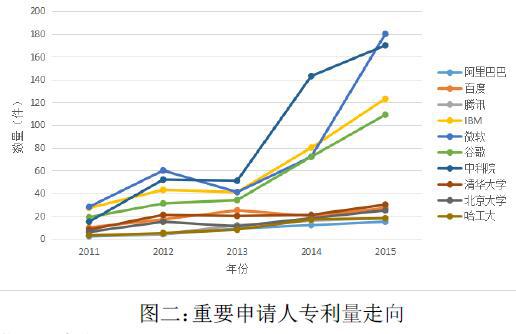
圖二展示了本文選取的重要申請人在本領域近幾年的申請量走向,從整體上看,從圖中可以觀察到所有申請人在該領域的專利申請量總體上呈逐年遞增趨勢,一方面說明了深度學習近幾年的發展勢頭越來越強勁,另一方面也說明了一個技術領域的快速發展可以通過其專利的發展的反應出來[5]。
對比國內外企業,從增長率我們可以看出,國外企業對技術發展的敏感程度較高,在深度學習發展起來之后,可以快速地投入資源進去;而國內企業雖然也有一定程度的增長,但增長率較低。由此可見,國內的企業對于前沿技術的敏感程度和重視程度目前還有很大的提高空間。抓住這些技術變化的拐點,才有機會在未來的商業競爭中取得優勢。
同時,我們看到國內的學術界和工業界的申請量對比,有著一定相關的變化趨勢,說明國內目前深度學習領域的產學結合較為完善,學術界的成果可以很快應用到工業界,工業界的重要企業也愿意投入一定的資源去進行深度學習的研究。由此我們看到,深度學習作為一項新技術,在產學結合方面有著快速發展的趨勢,利用這點趨勢,未來深度學習的發展將愈加火熱。
我們選取的重要申請人做該領域的技術帶頭人,其對深度學習領域的專利保護越來越重視,由此可見該領域越來越受到業界內各大企業和研究機構的重視,也意味著該領域的專利保護競爭會愈加激烈。可以預見,在未來的幾年,其專利申請量還會呈持續遞增的趨勢,未來的此領域專利保護工作將會愈加重要。
第三章深度學習重點專利技術分析
本章通過剖析國內外兩個典型的專利申請案例,一方面分析深度學習相關專利的特征,對此領域專利申請、審查、保護都有一定的意義;另一方面,通過分析重點專利,我們可以知道目前深度學習領域的主流技術特點,也可以預見其未來發展趨勢。
3.1 國內重點專利分析
在國內的重要申請人中,中科院在該領域的申請量最多,可見其在該領域的貢獻之大,在眾多重要專利中,我們找出如下一篇典型專利進行分析,其申請號為“CN201510270028”的專利中,公開了“一種基于深度語義特征學習的短文本聚類方法”[2]。
該申請公開了一種基于深度語義特征學習的短文本聚類方法,包括:通過傳統的特征降維在局部信息保存的約束下對原始特征進行降維表示,并對得到的低維實值向量進行二值化,做為卷積神經網絡[4]結構的監督信息進行誤差反向傳播訓練模型;采用外部大規模語料無監督訓練詞向量,并對文本中每個詞按詞序進行向量化表示,做為卷積神經網絡結構的初始化輸入特征學習文本的隱式語義特征;得到深度語義特征表示后,采用傳統的K均值算法對文本進行聚類[6]。
該申請是一個深度學習在自然語言處理領域的典型應用,通過神經網絡學習文本的語義表示,然后通過特定的類標簽訓練端到端的神經網絡,并結合了其他傳統的機器學習算法如降維技術、聚類技術等,這是一個深度學習用于自然語言處理的典型流程,該流程可以作為其他申請在該領域的對比范本。
3.2 國外重點專利分析
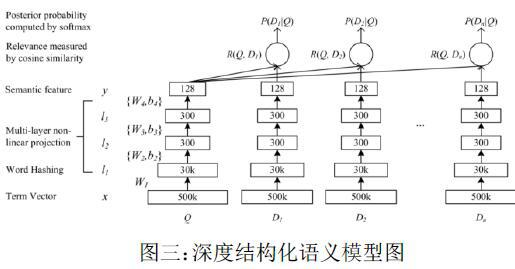
在國外的重要申請人中,微軟公司作為該領域在工業界較為核心的企業,有諸多本領域中的申請,例如,其公開的一篇專利號為“US20150074027A1”的申請中,公開了一種“Deep Structured Semantic Model Produced Using Click-Through Data”,提出了深度結構化語義模型[3]。
首先,我們看到此申請同樣是端到端的設計,實際上不只是本文提到的典型案例,在諸多相關的申請中有很多都是端到端的結構,說明這是深度學習所使用的主流方法。其次,由于數據不同、訓練目標不同,雖然都是端到端的結構,但是模塊的選擇和順序卻有著很大的不同。
該申請是深度學習領域中一個將數據與網絡結構結合的典型案例,我們知道深度學習是由數據驅動的學習過程,如何將數據與網絡結構結合起來是至關重要的,因此我們通過學習此案例,可以學習到如何針對不同的數據格式設計不同的輸入輸出結構。在比較深度學習技術的差異點時,數據結構的創新也是不容忽視的。
第四章總結與展望
本文通過從專利保護的角度出發,統計和分析了深度學習領域重要專利申請人的申請量和申請量趨勢,并進一步深入剖析了國內外的典型案例。一方面,我們看到深度學習在諸多領域有著重要的應用,技術發展愈發火熱,未來的專利保護競爭畢竟更加激烈,因此保護其健康發展有重要的意義;另一方面,我們看到深度學習的技術特征鮮明,其創新點的多樣化,如與其他技術結合、與需求結合、通過模塊的調整等,對進行發明點的構思、差異點和相似性的分析挖掘有一定的指導意義。
參考文獻
[1]Goldberg Y. A Primer on Neural Network Models for Natural Language Processing[J]. Computer Science, 2015.
[2]徐博, 許家銘, 郝紅衛,等. 一種基于深度語義特征學習的短文本聚類方法; CN104915386A[P]. 2015.
[3]Corporation M. Deep structured semantic model produced using click-through data[J]. 2016.
[4]Cun Y L, Boser B, Denker J S, et al. Handwritten digit recognition with a back-propagation network[C]// Advances in Neural Information Processing Systems. Morgan Kaufmann Publishers Inc. 1990:396-404.
[5]余凱, 賈磊, 陳雨強,等. 深度學習的昨天、今天和明天[J]. 計算機研究與發展, 2013, 50(9):1799-1804.
[6]孫吉貴, 劉杰, 趙連宇. 聚類算法研究[J]. 軟件學報, 2008, 19(1):48-61.
[7]吳曉婷, 閆德勤. 數據降維方法分析與研究[J]. 計算機應用研究, 2009, 26(8):2832-2835.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
