基于多線程和翻譯的網絡爬蟲鳥類音頻數據采集系統設計與實現
2018-11-20 11:54:14劉江劉國璽張雁呂丹桔
現代計算機 2018年30期
劉江,劉國璽,張雁,呂丹桔
(西南林業大學大數據與智能工程學院,昆明 650224)
0 引言
隨著信息技術,網絡技術的發展,Internet成為匯聚信息的中心載體。如何高效便捷地收集和提取In?ternet上的信息,是一項巨大的挑戰。網絡爬蟲是按照一定規則,能夠自動地對萬維網網頁信息進行下載的計算機程序或腳本。聚焦網絡爬蟲是在網絡爬蟲的基礎上設計的,可以按照用戶需求選擇性地對網頁信息進行提取,極大地節省了資源[1-3]。因為建立鳥類聲音樣本庫和鳥鳴分類識別系統都需要大量的鳥類音頻數據作為支撐,通過對鳥類聲音爬取關鍵字信息的搜索,未能搜索到有關鳥類聲音爬取的程序或腳本。在考慮實際運用的情況下,本文采用多線程、網絡爬蟲、翻譯等技術設計并實現了鳥類音頻數據采集系統。該系統的建立有助于豐富鳥類聲音樣本庫,最終實現花費較少資源能夠大量獲取關于鳥類音頻文件和鳥類信息的目標,解決了人工采集聲音效率低、投資大、風險高、質量差,人工對鳥類音頻數據搜集、整理速度慢、耗費時間長、工作內容繁瑣等問題。
1 系統設計的目標功能
鳥類音頻數據采集系統的目標是通過網絡爬蟲抓取互聯網上鳥類的音頻數據,構建豐富的鳥類聲音樣本庫。由于鳥類音頻數據的數據量比較大,本文在設計鳥類音頻數據采集系統的時候綜合考慮了相關因素,把采集系統建設分為兩個部分:一是數據抓取[4]部分,二是數據下載部分。該系統為了在硬件環境的支持下能夠最大限度地提升程序運行速率設計了多線程控制器[5];為了解決獲取外文網站信息時使獲取的信息能夠符合中文的語義表達方式的問題設計了翻譯模塊[6],對提取的信息進行翻譯處理。設計URL[7]管理器對URL進行管理,HTML獲取器下載頁面,HTML解析器解析下載的頁面,存儲模塊[8]數據庫存儲資源,下載器下載相關內容。
數據抓取部分在URL入口輸入進入URL后開始工作,抓取到與該URL相關的網頁信息,解析提取所有URL和所需數據,翻譯器對所需內容進行翻譯,最后把音頻數據的URL和相關信息提取保存到數據庫中。數據下載部分通過對數據庫信息的讀取,URL管理器處理后交給下載器進行下載。
2 系統的流程設計
為了解決鳥類音頻文件的數據量較大,爬取頁面較多,爬取外文網站信息時不符合中文的語義表達方式等問題設計鳥類音頻數據采集系統,其基本流程圖如圖1所示:
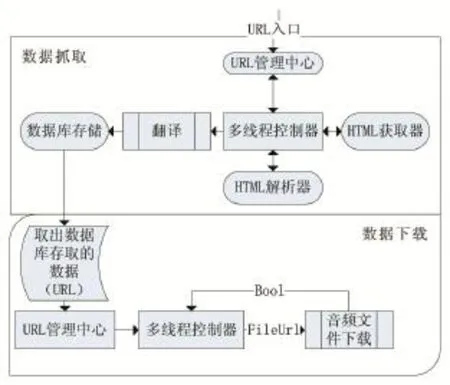
圖1 系統基本流程圖
本系統分為數據抓取部分和數據下載部分。數據抓取部分包括六個模塊:URL管理中心、HTML獲取器、HTML解析器、多線程控制器、HTML翻譯器和數據庫存儲,這六個模塊共同完成數據抓取并存儲于數據庫的整個過程。數據下載部分包括四個模塊:數據讀取、URL管理中心、多線程控制器、文件下載,這四個模塊完成數據下載到本地的整個進程。
2.1 數據抓取部分
(1)URL管理中心
為了解決URL指向循環和URL重復等問題設立URL管理中心,URL管理中心的作用是管理待爬取的URL和已經爬取過的URL,每個網頁爬取的信息都包含指向其他網頁的URL,其他網頁同樣會包含指向本網頁的URL。這樣URL的指向就存在循環,嚴重影響網絡抓取數據的速度,當兩個URL相互指向形成無限循環,就會導致程序運行出錯。設計URL管理中心能夠很好的解決這個問題,防止程序運行出錯。
(2)HTML獲取器
HTML獲取器負責把網頁中對應的信息下載到本地,這是整個爬蟲的核心部分。它從互聯網上查詢URL對應的網頁,將其內容按照HTML的格式下載到本地,便于后續分析處理。
(3)HTML解析器
HTML解析器對HTML獲取器下載的頁面進行解析,提取出頁面中包含的URL和數據。本系統實現的是定向網絡爬蟲,除了提取頁面中待爬取的URL,還提取了很多實驗所需數據。
(4)多線程控制器
為了解決程序運行的速率問題,減少運行時間,提高效率,本系統設計多線程控制器。多線程控制器的功能是對爬蟲程序的線程數加以控制,根據數據要求和系統性能對程序進行控制,最大限度的提高程序運行速率。
(5)翻譯
針對搜集外文網站數據時語言、語義不同且不符合中文的語言表達方式,分析理解這些數據困難等問題設計翻譯模塊。此模塊負責對HTML提取解析后的數據進行翻譯、注解。在翻譯模塊中調用百度翻譯的API[9]實現對提取出來的內容進行翻譯,翻譯之后將數據提交到數據庫進行存儲。
(6)數據庫存儲
為了存儲和讀取數據方便設計數據庫模塊,數據庫是根據實際需求設計,能夠對翻譯器提交過來的數據進行存儲。
2.2 數據下載部分
這部分實現的是對數據庫中數據的讀取與下載,讀取數據庫中保存的信息和URL,將讀取信息提交給URL管理中心對URL進行管理,多線程控制器對下載程序進行控制,音頻文件下載是為了實現對數據庫中的URL進行訪問,下載鳥類音頻文件。
2.3 數據抓取流程
數據抓取部分流程如圖2所示,由流程圖可知在爬蟲程序中,URL管理器用來管理待爬取的URL列表和已經爬取過的URL列表,從URL管理器中取出URL,判斷該URL是否被爬取過,如果是未爬取過的URL,則將此URL發送給HTML下載器。HTML下載器對該URL指定的網頁進行下載存儲在本地服務器中,HTML解析器對下載器下載的頁面進行解析,解析出網頁內容和URL,解析器把URL提交給URL管理器,只要URL滿足程序運行條件程序就一直運行,對網頁進行下載、解析、翻譯最后保存到數據庫,直到程序結束運行。
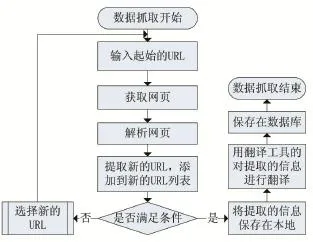
圖2 數據抓取流程圖
2.4 數據下載流程
數據下載流程如圖3所示,由數據下載的流程圖可知系統從數據庫中提取數據,經URL管理器處理之后,把URL傳遞給下載器直接訪問音頻數據的URL對鳥類音頻數據進行下載,直到所有數據下載完成結束程序。
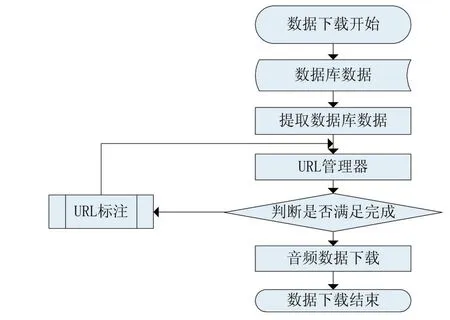
圖3 數據下載流程圖
3 多線程和翻譯的實現
為了提升程序運行的速度,在串行網絡爬蟲的基礎上,設計多線程網絡爬蟲程序。爬蟲程序開始執行后,程序向網頁發送訪問的請求,程序等待網頁做出響應。根據等待的時間來衡量爬蟲的效率,等待的時間越長,效率就越低。當程序采用多線程的時候,程序與網頁進行通信等待的時間有所降低,提高了數據抓取的和數據下載的效率。
當搜集目標網站的數據信息的語言與系統所需信息的語言不一致時,需要對爬蟲收集的數據進行加工處理,使其符合中文的語義表達習慣,但人工對數據進行整理,翻譯需要耗費較多的人力、物力,增加實驗任務。在網絡爬蟲程序中增加翻譯模塊可直接對網頁數據進行翻譯,使其符合中文的語義表達方式、語義規則。翻譯模塊的實現是通過調用百度翻譯的API對數據進行處理的,通過調用API編譯程序代碼實現翻譯功能,最終滿足于實際運用的需求。
4 系統測試
軟件測試環境如下:操作系統:Windows 10家庭版;CPU:I5 4700M;內存:8G;網絡帶寬:100Mb;應用工具:Python 3.6。
在考慮了計算機的硬件配置和數據應用的情況下,測試分為對國內網站爬取和國外網站爬取進行。
4.1 對某國內聲音網站的爬取
表1為爬取某國內網站的實驗數據,表2是為下載某國內網站的實驗數據。

表1 某國內網站數據爬取

表2 某國內網站音頻文件下載
4.2 對某國外聲音網站的爬取
表3為爬取某國外網站的實驗數據,表4是為下載某國外網站的實驗數據。

表3 某國外網站數據爬取

表4 某國外網站數據下載
4.3 測試結果分析
本系統分別爬取國內和國外網站數據進行測試實驗,經過系統爬取整理之后實驗數據滿足具體應用需求。實驗中耗費較少的時間資源能夠爬取到大量的信息,多線程爬取和下載都速率都比較快,耗費資源少。人工對實驗結果進行查看,發現爬取外文網站的信息符合中文的表達規范和語義要求,綜合來看本次實驗結果滿足系統建立的需求。實驗研究發現當線程數達到一定程度時數據的下載速度與網絡帶寬有關,受網絡帶寬[1]的影響。當線程數達到200,下載速度通過360測速工具測試知道速度為8000KB/s,接近當前帶寬的最大速率。在調用不用翻譯工具對數據進行翻譯的對比實驗中,我們發現很多專業名詞的解釋更加符合中文語言規則的是百度翻譯工具。
5 總結與展望
鳥類聲音樣本庫的豐富度決定鳥鳴分類識別系統的識別效果,基于多線程翻譯網絡爬蟲的鳥類音頻數據采集系統的設計與實現解決了在萬維網上獲取鳥類音頻文件,鳥類知識信息等問題,豐富了鳥類聲音樣本庫。本系統的建立,能夠便捷高效地獲取鳥類音頻數據,滿足具體應用需求,解決了人工采集聲音效率低、投資大、風險高、質量差,人工對鳥類音頻數據搜集、整理速度慢、耗費時間長、工作內容繁瑣;人工處理翻譯外文數據效率低、耗費資源多等問題。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
