商立方體分布式查詢研究
2018-11-19 10:58:52張正凡都儀敏
軟件導刊 2018年11期
關鍵詞:實驗
張正凡,都儀敏
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
0 引言
在過去的幾十年里,數據處理主要集中在傳統單機數據庫上。隨著大數據時代的到來,市場瞬息萬變,企業需要快速、有效地從歷史數據中獲得對市場變化的預測,或從歷史數據中獲得經驗進行決策分析[1-2]。數據倉庫的出現,為數據立方體的聯機分析處理(Online Analytical Processing,OLAP)提供了平臺[3-4]。但隨著歷史數據的積累,對數據立方體操作在時間、空間上存在巨大挑戰。因此,許多學者針對數據立方體壓縮技術相繼提出了不同的壓縮模型[5]。例如冰山立方體、封閉立方體、商立方體、濃縮立方體等,其中冰山立方體需要預先設定一個最小閾值,按照預先定義的約束條件對原始數據立方體進行剪枝操作,只保留符合約束條件的方體;封閉立方體通過計算等價類,將由等價類上界構成的集合進行物化,舍棄其它所有單元,通過具有代表性的封閉單元響應對原始數據立方體的查詢[6];濃縮立方體是相應原始數據立方體的一個子集,對于原立方體中基于同一條基本單元組聚集而得、且具有相同聚集值的多個格,在濃縮立方體中僅存儲其中無*值的一個格,通過該剪枝方式減小數據文件體積[7];而商立方體在封閉立方體的基礎上保留了等價類的上下界,更好地保持了類似區間的模型[8]。同時,由于商立方體保存了整個等價區間,可以保證區間內所有數據單元都具有相同聚集值,因此商立方體對非單調聚集函數具有很強的支持性。在此基礎上,文獻[9]提出了一種分層封閉立方體查詢算法,通過增加層號限制查詢的中間結果從而提高效率。與此同時,大數據技術的發展帶來了Hadoop、Spark等分布式系統[10-11],MapReduce編程模型也逐漸應用廣泛[12],一些傳統算法可以通過MapReduce模型改造后在分布式系統上運行。文獻[13]提出了一種基于QC-Tree的商立方體查詢算法,并在Hadoop集群中加以實現,但在MapReduce模型中,尤其在shuffle過程中需要經常對磁盤進行I/O操作[14],因Spark具有基于內存的特性,所以非常適用于需要迭代計算的大數據運算[15],甚至有些程序在Spark中運行速度比在Hadoop中快上百倍[16]。
目前針對在Spark集群上的商立方體研究較少,因此本文從商立方體基本概念出發,提出一種基于Spark平臺的商立方體分布式查詢算法,該算法首先將商立方體進行分片,然后將待查詢單元通過廣播形式發送到各Worker節點,最后通過查詢函數對查詢單元進行查詢操作。
1 商立方體OLAP模型
設C是基本表r上計算得到的數據立方體,其數據單元c=(a1,a2, …,an:ma),其中,ai是維屬性值(可能為ALL),1≤I≤n,ma是度量值。當維屬性值中存在k(0≤k≤n)個非ALL的值時,則c是k維數據單元。給定數據單元u∈C,v∈C,u和v間具有如下關系:
定義1(元組覆蓋):u∈C,v∈C,對于?ai,1≤I≤n,如果滿足以下條件,則稱v覆蓋u或u被v覆蓋:①如果v(ai) ≠All,則u(ai)=v(ai);②如果v(ai)=All,則u(ai) =any。
例如:u(S1, *,R1: 18)覆蓋v(S1,T2,R1: 12),w(S1,T1,R1: 6)。
定義2(基本元組集):給定數據單元c∈C,c的基本元組集BTS(c)={t|t∈r且t≤c},即所有上卷到數據單元c的基本表元組集合,或單元c覆蓋的基本表元組集合。例如:BTS((S1,T1,R1∶6)) = {(S1,T1,R1∶6)},BTS((S1,*,R1∶18))={(S1,T2,R1∶12), (S1,T1,R1∶6)}。
定義3(等價關系≡):當u,v滿足BTS(u) =BTS(v),則u和v等價,記為u≡v。例如:現有元組(S1,*,R1∶18)和元組(S1, *, *∶18),并且BTS((S1,*,R1∶18))=BTS((S1,*,*∶18))={(S1,T2,R1∶12),(S1,T1,R1∶6)},則兩個元組等價,標記為(S1,*,*:18)((S1,*,*:18)。
定義4(等價類):基本元組集相等的元組集合。如給定數據單元u、v,若u≡v,則u、v屬于同一等價類。
定義5(等價類的上界):在等價類C中,對所有c∈C,B為c中的屬性值集合構成的元組。若UP=(a1,a2,a3,...,an)是等價類C的上界,對于第i維屬性值ai必須滿足如下條件:①若{ai|ai(UP}=*,則{ai|ai∈B}可以為任意值;②若{ai|ai(UP}=s,則{ai|ai∈B}=s。
定義6(等價類下界):等價類中非ALL的維度值最多的數據單元集合。
定義7(等價區間):C為數據立方體所有等價類的集合,對于所有c∈C,q為c的上界,p為c的下界,則p與q組成一個等價區間,記作[q,p]。
定理1:落在等價區間內的單元,其基本元組集相等。
證明:給定數據單元u,v,w∈C,設u≤w≤v,u≡v。首先由u≡w≡v,可以得到BTS(u)?BTS(w)?BTS(v),又u≡v,則BTS(u)=BTS(v),因此BTS(w)=BTS(u)=BTS(v),w≡u≡v,得證。
定理2:若u≡v,則對于任何聚集函數,u和v的度量值必然相等。
證明:由u(v,得BTS(u)=BTS(v),既然兩者基本元組集相同,通過相同的聚集函數計算,聚集值即度量值,必然相等。
需要注意的是,若C存在兩個數據單元c1和c2,且兩者基本元組集相等,則度量值相等;但若度量值相等,基本元組集卻不一定相等。
例如:對于求平均的聚集函數avg,設u=(*,1,*),v=(*,1,1),且BTS(u)={(1,1,1:5),(2,1,2:5)},BTS(v)={(1,1,1:5)},在這種情況下,u>v,且u、v的度量值都是5,但基本元組集不相等。
2 分布式商立方體OLAP查詢
通過上文對商立方體定義的描述,等價區間查詢匹配過程如圖1所示。
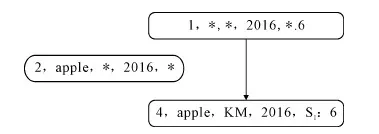
圖1 等價區間查詢匹配
設一個商立方等價區間,其中a1=(apple,KM,2016,S1:6)為下界,a2=(*,*,2016,*:6)為上界,若此時待查詢元組為a3=(apple,*,2016,*),a2覆蓋a3覆蓋a1,且a1與a2的聚集值均為6。因此,根據定理1,可以得到待查詢單元a3的聚集值也為6,響應查詢即可。
但是在實際查詢過程中,由于基本表數據巨大,生成的商立方體也會很大。為了省去不必要的覆蓋判斷,對商立方體進行分層,將層數作為掃描操作的依據,若待查詢單元落在某一商立方體上下界之間,則其層數也必在上下界層數之間。
基于以上原理,提出商立方體的分布式查詢算法(Distributed Quotient Cube Query Algorithm):
輸入:quotientCube (等價區間的集合)
queryArray (帶查詢元組集)
輸出:equivalentRegion (匹配到的等價區間)
load base table from hdfs
loading mapping data
DFS processing to generate quotient_cube
generate queryArray randomly
broadcast(queryArray);
sc.parallelize(3).mapPartitions(partRDD => {
for i = 0 to test_query_cells.size
for j = 0 to quotientCube.size
if( quotientCube[j] includes queryArray[i])
Cache hit; break;
end if
end for
end for})
在程序執行前,預先將基本表存儲在HDFS文件系統中。在本例中采用HDFS的默認分區策略。數據在文件系統中以block形式存放,大小默認為128M,每個block對應一個RDD分區。Spark執行時,創建SparkContext對象,對象為程序入口,同時讀取配置文件信息,并以該配置運行整個Spark程序。
首先從HDFS中加載基本表,以及映射關系表,通過一系列轉化操作,將基本表中字符串根據映射關系轉化成數字類型的RDD,然后通過DFS算法生成商立方體quotientCube,并生成用以測試的待查詢單元queryArray。然后對待查詢單元賦值給一個廣播變量,廣播變量通過廣播的形式將本地RDD復制到遠程節點上以待查詢。最后根據覆蓋關系,若帶查詢元組能被某一等價區間覆蓋,則直接響應查詢,并開始下一元組的查詢,若不能覆蓋,則直接開始下一輪查詢。
3 實驗分析
3.1 實驗環境
本實驗以Scala語言編寫,Scala版本號為2.10.4,操作系統為Ubuntu 16.04(X86_64),Hadoop 版本為Hadoop-2.6.0,Spark 版本為Spark-1.6.1 -bin- hadoop- 2.6,JDK 版本為jdk 1.8.0_151。
Spark集群環境的計算機有3臺,主要配置見表1。
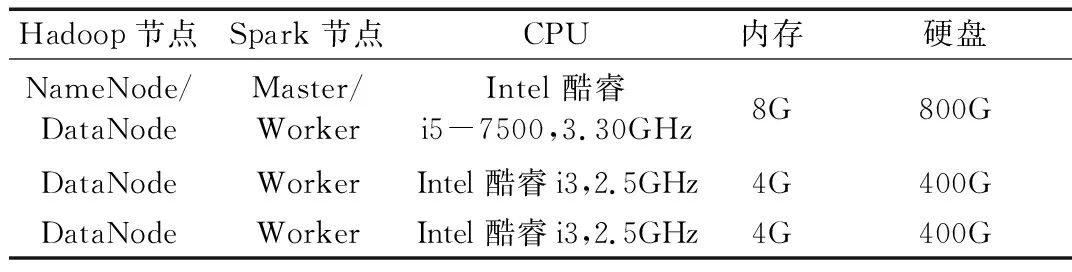
表1 實驗環境配置
3.2 實驗結果與分析
本實驗將Spark環境下商立方體分布式查詢與單機環境下的商立方體查詢進行對比,測試本文提出的分布式商立方體查詢算法(DQCQ算法)性能。測試數據采用Food Mart數據集。實驗結果如圖2所示。

圖2 Spark環境與單機環境對比
在實驗中,每隔2萬次輸出程序運行時間。由圖2可以看出,在查詢次數相同的情況下,并行情況下的查詢性能幾乎是單機條件下的兩倍。因為運行分布式系統占用一定性能,且存在分區、廣播等同步操作,雖然集群有3個節點,但是查詢速度無法達到單機的3倍。
在第二次實驗中,將集群節點數作為參數,通過改變集群節點數量測試算法性能。實驗結果如圖3所示。

圖3 節點數對查詢速度的影響
在本實驗中,將查詢次數限定在10萬次,從1個節點增加到5個節點。通過實驗結果可以得出,隨著集群節點增加,查詢時間越來越少,因為節點變多,進行查詢的單元隨之增加,所以在總數不變的情況下,查詢時間變少。
綜上所述,在實際應用場景中,本文提出的DQCQ算法查詢性能較好,且隨著集群規模的擴大,算法性能隨之擴大。實驗結果與理論預期一致。
4 結語
本文基于商立方體的基本結構,提出了一種商立方體分布式查詢的優化算法,并在Spark環境下實現。通過對比實驗可以看出,在Spark環境下商立方體的分布式查詢具有一定的可行性和較高的效率。
本文對數據集進行隨機劃分,但考慮到節點間的負載均衡,建設采用邊劃分或點劃分進行數據集劃分,確保集群中某些節點不會過度負載而降低算法性能;本文提出的算法需要等待商立方體全部物化后才能開始查詢,由于初始化需要等待,可以考慮動態查詢商立方體,通過邊查詢邊物化完善商立方體。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
