信息檢索中支持隱式時間查詢的文檔排名方法
2018-11-17 01:25:54王晶晶吳勝利
計算機工程與設計 2018年11期
王晶晶,吳勝利
(江蘇大學 計算機科學與通信工程學院,江蘇 鎮江 212013)
0 引 言
時態信息檢索(temporal information retrieval)[1]中部分查詢的內容未包含明確形容時間的詞匯,但符合此查詢檢索需求的文檔大多數在某個特定的時間區間,稱這種類型的查詢為隱式時間查詢。如用戶提交一個查詢“上海世博會”,用戶感興趣的時間區間很有可能是世博會的舉辦時間:2010年5月1日至10月31日。針對這種類型查詢,研究人員提出一些分析查詢時間意圖的方法,如Kanhabua等通過前k個文檔的時間戳分析查詢的時間意圖[2];Gupta等提出一種模型,同時考慮文檔的發布日期和文檔內容中的時間詞匯對檢索結果的影響,在不同時間區間(如年、月、日)下分析滿足用戶檢索需求文檔對應的時間區間[3];Kanhabua等利用查詢日志識別事件對應的實體,然后通過機器學習算法對實體進行分類[4];Lin等建立了一個能夠提取時間表達式的檢索模型,同時考慮查詢和檢索結果之間的時間相關性以及文本相關性因素[5]。
本文結合DBpedia知識庫和排名前k個文檔內容中的時間詞匯這兩種方法分析查詢時間意圖,在此基礎上計算各文檔的時間相關性得分,最后線性結合內容相關性得分和時間相關性得分對文檔重新排序。
1 方 法
文檔集C={d1,d2,d3,…,dn},其中文檔di={w1,w2,w3,…,wm,t1,t2,t3,…,tn},關于文檔主題詞匯wm的集合記作dword,文檔中與時間相關的詞匯tn的集合記作dtime[8]。
針對隱式時間查詢,計算文檔相關性得分排序的流程如圖1所示,主要過程如下:
(1)在文檔集中構建索引,計算文檔集中每個文檔與用戶查詢的相關性得分,從高到低排序,得到初始排名結果;
(2)利用DBpedia語義網和初始排名結果中排名前k個文檔中的時間詞匯,分析查詢時間意圖,通過排名模型計算文檔與用戶查詢在時態方面的相關性得分;
(3)線性結合內容相關性得分和時間相關性得分對結果重排。
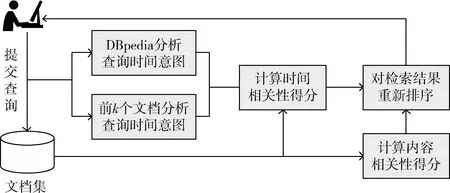
圖1 隱式時間查詢排名算法流程
此算法中主要包括分析查詢時間意圖和利用檢索模型對文檔排序兩部分,下文中將分做詳細介紹。
1.1 確定查詢時間意圖
假如用戶希望查詢某位公眾人物或者歷史上曾經發生的某個重大事件,本文提出利用語義網DBpedia獲取與該查詢相關的時間信息,并作為該查詢的時間意圖;否則通過排名前k個文檔內容中的時間詞匯確定查詢的時間意圖。
1.1.1 利用DBpedia確定時間意圖
DBpedia知識庫是一種特殊的語義網絡,從維基百科頁面中提取的結構化的信息,存儲了大量的由資源描述框架描述定義的實體[6]。除此以外,可以通過鏈接訪問網絡上的其它數據集,強化檢索功能[7]。
在本文中,我們通過SPARQL語言查詢DBpedia知識庫中某位公眾人物或者歷史上曾經發生的某個重大事件的具體日期,確定查詢的時間意圖。
1.1.2 排名前k個文檔確定時間意圖
若查詢的內容不是關于歷史事件或者人物,首先對文檔集構建索引,檢索得到僅考慮內容相關性的前k個文檔,這些文檔中出現頻率較高的時間點能夠滿足用戶查詢時間意圖的概率較大。因此,把前k個結果中出現頻率超過m次的時間點的集合作為用戶查詢的時間意圖[8]。
1.2 檢索模型
隱式時間查詢q由查詢主題qword和時間意圖qtime兩部分組成,通過如下公式計算每個文檔d的最終得分S(q,d)
(3) 動物園的安全警示是否充足。根據城市動物園管理規定第三章第二十一條:動物園管理機構應當完善各項安全設施,加強安全管理,確保游人、管理人員和動物的安全。動物園方應該設置足夠多且位于醒目位置的警示牌、在危險區域安排足夠多的巡邏車、安裝數量充足的監控攝像頭保證二十四小時的不停歇監控, 在發現游客有危險舉動時應立即上前勸阻與阻攔。
S(q,d)=α·S′(qword,dword)+(1-α)·S″(qtime,dtime)
(1)
α是調節內容相關性和時間相關性的參數,下文中介紹3種計算時間相關性得分的方法。
1.2.1 語言模型
基于語言模型計算時間相關性得分的方法如下[9]

(2)
在某些情況下,兩個時間點Q和T表現形式不同,但實際上指向同一個時間段,即具有相同的時間意圖。所以在計算P(Q|T)值時有必要考慮時間因素存在的不確定性,下文介紹兩種計算P(Q|T)的方法。
第一種方法是比較Q與T兩個時間點的時間間隔,如果兩個時間點Q與T的時間間隔在n天內,P(Q|T)為1,否則結果為0

(3)
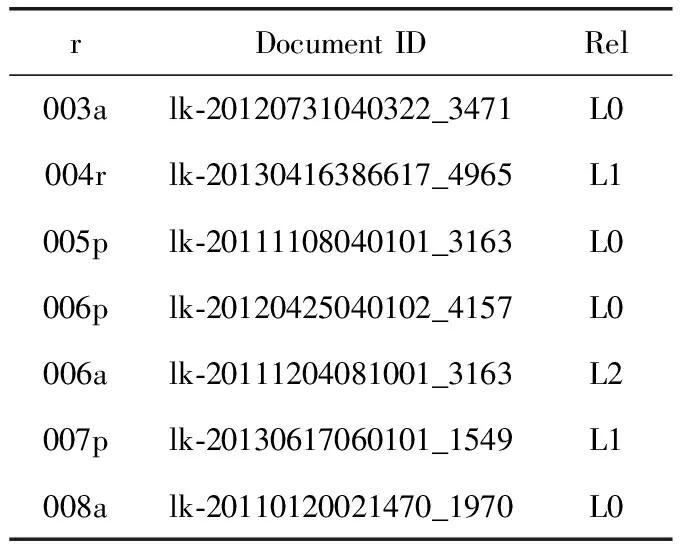
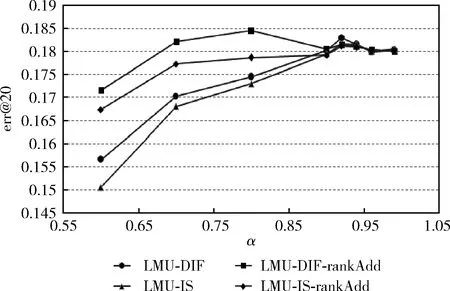
第二種方法把與查詢中的某個時間點Q前后相差n天的區間內的時間點組成一個集合Q′={t|Q-n (4) 1.2.2 度量空間模型 Matteo等提出在度量空間下計算時間相似性,計算查詢和文檔中時間點的曼哈頓距離[10]。文檔d中的時間區間[a,b],查詢q時間意圖區間為[c,d],使用式(5)計算查詢q與文檔d時間區間的曼哈頓距離 δsym([a,b]Q,[c,d]D)=|a-c|+|b-d| (5) 通過曼哈頓距離值對文檔降序排序,使用式(6)得到的結果即為時間相關性得分 (6) 其中,rank是文檔對應的排名位置。 查詢:實驗中共使用50個查詢,每個查詢由標識符id,查詢關鍵詞title,查詢意圖的詳細描述description,查詢子主題subtopic(用戶可能希望通過檢索了解的問題,包括不考慮時間因素的子主題atemporal、關注過去發生事情的子主題past、關注近期發生事件的子主題recency和關注未來發生事件的子主題future)等組成,查詢示例見表1。本文選取各個查詢中時間意圖在過去時間區間的past子主題進行實驗。 表1 查詢示例 評價相關性:NTCIR會議文檔集為每個查詢提供了判斷文檔與查詢相關性的評價文件,部分評價文件的內容見表2。“r”為評價相關性子主題標識,由查詢編號和子主題類型組成;Document ID為文檔的唯一標識; Rel是判斷文檔在該子主題下的相關性,L0代表文檔與查詢不相關,L1代表文檔與查詢部分相關,L2代表此文檔與查詢非常相關,完全滿足查詢需求。 表2 部分評價文件示例 實驗中使用的幾種排名方法定義如下:LMU-DIF方法通過式(3)計算P(Q|T)從而計算時間相關性得分,內容相關性得分為Indri的原始得分進行0-1規范化后的結果;LMU-DIF-rankAdd和LMU-DIF使用同一個方法計算時間相關性,但是區別在于LMU-DIF-rankAdd方法首先使用公式score=1/(rank+60)把初始排名轉換為分數,然后通過式(7)0-1規范化得分。相似地,LMU-IS和LMU-IS-rankAdd方法利用式(4)計算P(Q|T)得到時間相關性得分并規范化。使用式(5)計算時間相關性得分,兩種不同規范化得分的方法分別記作Metric和Metric-rankAdd。除此以外,本文還與Kanhabua等[2]提出的兩種方法性能進行比較, QW方法利用查詢內容中的關鍵詞分析時間意圖,NLM使用前k個文檔的創建日期分析查詢時間意圖,然后在查詢時間意圖的基礎上計算時間相關性得分 (7) 考慮時間不確定性的因素,本文實驗中設置時間間隔為7天,k值為200[8]。 前文1.1.1節中提出一種通過DBpedia分析查詢時間意圖,038號查詢是此類查詢的一個示例,線性結合內容相關性和時間相關性得分重排后結果的MAP,RP,nDCG@20這3個指標值如圖2所示。比較發現,各方法的指標值都高于基準值,表明在檢索模型中考慮時間因素有利于提升檢索性能,本文提出的通過DBpedia分析查詢時間意圖方法具有可行性。 圖2 利用DBpedia計算時間相關性得分重排后指標值 使用前文中得到的最優參數進行實驗,結果表明,考慮時間相關性重排后排名結果中個別指標比Baseline略低,其它模型的性能都有所提升,說明在檢索模型中考慮文檔與查詢在時間方面的相關性具有一定的意義,有利于檢索出更多符合用戶需求的文檔。在所有的排名模型中LMU-DIF和LMU-DIF-rankAdd方法中大多數的指標值比其它方法高,表明以式(3)為基礎計算時間相關性得分作為內容相關性得分,然后對文檔重新排序的方法性能更優[12]。 圖3和圖4顯示不同內容相關性和時間相關性權重(α值)對LMU-DIF,LMU-IS,LMU-DIF-rankAdd,LMU-IS-rankAdd這4種方法err@20指標的影響。這兩個指標變化趨勢都是先上升到峰值后下降,數據表明檢索模型中應合理分配內容相關性和時間相關性權重,否則會降低檢索結果的性能。 分析圖3中4種方法的變化趨勢可以得出結論,當α小于0.9時,LMU-DIF-rankAdd方法指標值更高;而α值大于0.9以后,各方法的性能比較相近,LMU-DIF略勝一籌。綜合比較,LMU-DIF-rankAdd在取最優時間相關性權重時,指標值高于其它方法,性能更優。 圖3 不同α值下err@20指標值變化趨勢 圖4中展示不同α值下P@20指標的變化趨勢,LMU-DIF-rankAdd和LMU-IS-rankAdd這兩個使用式(6)規范化時間相關性得分的兩個方法變化趨勢比較相似,另外兩個規范化Indri系統得分的方法變化趨勢比較相似,可見不同分數規范化方法對檢索新能存在影響。當各方法取最優的時間相關性權重時,LMU-DIF和LMU-IS方法指標值更高,性能更優。 圖4 不同α值下P@20指標值變化趨勢 本文提出一種提高隱式時間查詢文檔排名性能的方法,該方法首先分析隱式查詢的時間意圖,計算時間相關性得分,最后線性結合時間相關性和內容相關性得分對文檔重新排序。實驗結果表明我們提出的方法一定程度上有利于提高隱式時間查詢的檢索性能,返回更多滿足用戶查詢意圖的檢索結果。然而,有些用戶檢索的內容可能是周期性舉辦的事件,如奧運會、世界杯等,查詢的時間意圖可能是多個時間區間。如何分析此類查詢的時間意圖,滿足查詢時間意圖的多樣性,是今后工作中需要研究的問題。
2 實 驗
2.1 實驗設置

2.2 實驗結果


3 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科學大眾(2022年11期)2022-06-21 09:20:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
臺聲(2016年2期)2016-09-16 01:06:53
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
