結(jié)合密集神經(jīng)網(wǎng)絡(luò)與長短時記憶模型的中文識別①
2018-11-14 11:36:24張藝瑋趙一嘉王馨悅董蘭芳
計算機系統(tǒng)應(yīng)用 2018年11期
張藝瑋,趙一嘉,王馨悅,董蘭芳
1(中國科學(xué)技術(shù)大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,合肥 230022)
2(遼寧省實驗中學(xué),沈陽 110031)
文本識別[1]分為印刷體識別和手寫體識別.目前這兩種識別都得到充分的研究,并普遍認(rèn)為印刷體字符識別中的關(guān)鍵問題已得到有效解決.但是對于印刷體字符識別而言,圖像質(zhì)量的嚴(yán)重下降會給識別造成極大的困難; 而關(guān)于中文字符識別[2],需要克服的難點更多,首先,中文類別較多,按照GB2312標(biāo)準(zhǔn),我們常用的一級漢字就有3755類; 其次,中文字符結(jié)構(gòu)復(fù)雜,它包括偏旁、部首和字根; 還有字符間形近字比較多,準(zhǔn)確區(qū)分形近字也大大增加了識別難度.所以,實際使用的文本識別技術(shù)還有很大的提升空間.
中文字符的識別方法主要分為結(jié)構(gòu)模式識別和統(tǒng)計模式識別[3].其中結(jié)構(gòu)模式識別是早期中文識別的主要方法,它根據(jù)字符自身的規(guī)律信息進行結(jié)構(gòu)特征提取,這些結(jié)構(gòu)特征包括字符輪廓特征、骨架圖像上提取到的反映字符形狀的特征等[4].基于結(jié)構(gòu)模式識別的主要優(yōu)點在于匹配精度高,區(qū)分相似字能力強; 但是由于其依賴結(jié)構(gòu)特征的提取,而特征的提取易受到干擾因素的影響,所以這種方法的抗干擾能力較差.隨著統(tǒng)計理論的發(fā)展,統(tǒng)計模式識別方法[5]逐漸成為中文字符識別的研究熱點,它提取將要被識別的統(tǒng)計特征,然后利用某些函數(shù)對這些特征進行分類.常見的統(tǒng)計特征包括網(wǎng)格特征、方向像素特征、穿越特征、外圍特征等.這種方法的主要優(yōu)點是具有良好的抗噪聲、抗干擾能力,對字符形變也有較強的魯棒性,但是對細(xì)節(jié)區(qū)分能力不強.
上述傳統(tǒng)方法都是基于手工設(shè)計、提取特征,這個過程不僅耗費人力,而且會積累誤差和噪音,極大地影響最后的識別效果.
近幾年,深度學(xué)習(xí)不斷發(fā)展,特別是深度卷積神經(jīng)網(wǎng)絡(luò)(CNN)[6]等模型在模式識別及計算機視覺領(lǐng)域的大量突破性成果的涌現(xiàn),為中文識別帶來新的活力;2013年富士通團隊采用改進的CNN網(wǎng)絡(luò)[7],在單個漢字識別方面取得了令人矚目的成績.
本文在深度學(xué)習(xí)的基礎(chǔ)上,針對多種字符,包括中文、英文、數(shù)字、特殊符號等,結(jié)合密集卷積神經(jīng)網(wǎng)絡(luò)DenseNet、雙向長短時記憶模型BLSTM和連接時域分類CTC進行文本行端到端的識別.采用DenseNet通過卷積、下采樣等操作提取圖像特征,并將生成的特征序列傳遞給BLSTM,相對于卷積神經(jīng)網(wǎng)絡(luò),BLSTM使用特殊的存儲記憶單元更充分的利用文本上下文特征進行建模,最后采用CTC對之前的特征信息進行解碼,輸出識別結(jié)果.這個網(wǎng)絡(luò)結(jié)構(gòu)可以接受任意長度的輸入序列,不要求對文本提前分割,在避免字符分割錯誤帶來誤差的同時,對于字符連接信息有一定程度的記憶能力,整體性能強,可以進一步提高文本識別率.
1 網(wǎng)絡(luò)結(jié)構(gòu)
1.1 DenseNet
深度卷積神經(jīng)網(wǎng)絡(luò)一個很重要的參數(shù)是深度.網(wǎng)絡(luò)深度的提升往往伴隨著網(wǎng)絡(luò)性能的提升,但是隨著網(wǎng)絡(luò)深度的加深,訓(xùn)練參數(shù)梯度消失的問題會愈加明顯,而DenseNet[8]的出現(xiàn)很好的解決了這個問題.
DenseNet是在Highway Networks[9,10],Residual Networks[11](ResNet)以及GoogLeNet[12]的基礎(chǔ)上被提出來的.不同于之前加深網(wǎng)絡(luò)或者加寬網(wǎng)絡(luò),DenseNet的提出者從卷積神經(jīng)網(wǎng)絡(luò)的特征序列入手,通過對特征序列的極致利用,簡化模型參數(shù),同時達(dá)到更好的效果.它的主要思想是跨層連接,網(wǎng)絡(luò)每一層的輸入都是前面所有層輸出的并集,而該層學(xué)習(xí)到的特征序列也會被直接傳給后面所有層作為輸入; 在上述過程中,信息流進行了整合,避免了信息在層間傳遞丟失和梯度消失的問題.
DenseNet一般由多個dense block和transition layer組成.圖1是DenseNet的主要結(jié)構(gòu)——dense block的示意圖.可以看出,H4層不僅直接用原始信息x0作為輸入,同時還使用H1、H2、H3層對x0處理后的信息作為輸入; 我們可以用一個非常簡單的式子描述dense block中每一層的變換,如式(1):
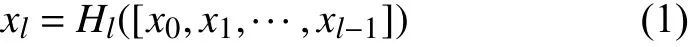
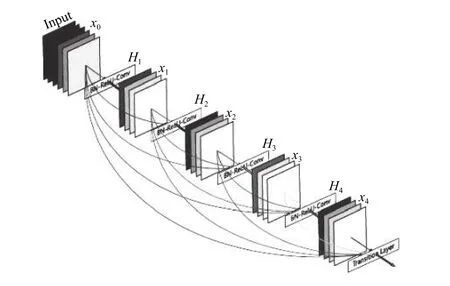
圖1 一個5層的dense block示意圖
相比于普通神經(jīng)網(wǎng)絡(luò)的分類器只依賴于網(wǎng)絡(luò)最后一層的特征,DenseNet可以綜合利用淺層特征,加強了特征的傳導(dǎo)和利用,減輕梯度消失的問題,所以更容易得到一個光滑的具有更好泛化性能的決策函數(shù).
1.2 BLSTM
傳統(tǒng)的遞歸神經(jīng)網(wǎng)絡(luò)(RNN)[13]展開后相當(dāng)于一個多層的神經(jīng)網(wǎng)絡(luò),當(dāng)層數(shù)過多時會導(dǎo)致訓(xùn)練參數(shù)的梯度消失問題的出現(xiàn),從而致使長距離的歷史信息損失.因此,傳統(tǒng)RNN在實際應(yīng)用時,能夠利用的歷史信息非常有限.為了彌補上述缺陷,Hochreiter等人[14]在1997年提出了LSTM單元結(jié)構(gòu),如圖2所示,它由1個記憶細(xì)胞和3個門控單元組成,記憶細(xì)胞用于存儲當(dāng)前的網(wǎng)絡(luò)狀態(tài),3個門控單元與記憶細(xì)胞相連,分別稱作輸入門、輸出門和遺忘門,它們控制信息的流動.在信息傳遞時,輸入門控制輸入到記憶細(xì)胞的信息流;輸出門控制記憶細(xì)胞到網(wǎng)絡(luò)其他結(jié)構(gòu)單元的信息流;遺忘門控制記憶細(xì)胞內(nèi)部的循環(huán)狀態(tài),決定記憶細(xì)胞中信息的取舍[15].LSTM的這種門控機制讓信息選擇性通過,使記憶細(xì)胞具有保存長距離相依信息的能力,并可以在訓(xùn)練過程中防止內(nèi)部梯度受外部干擾.
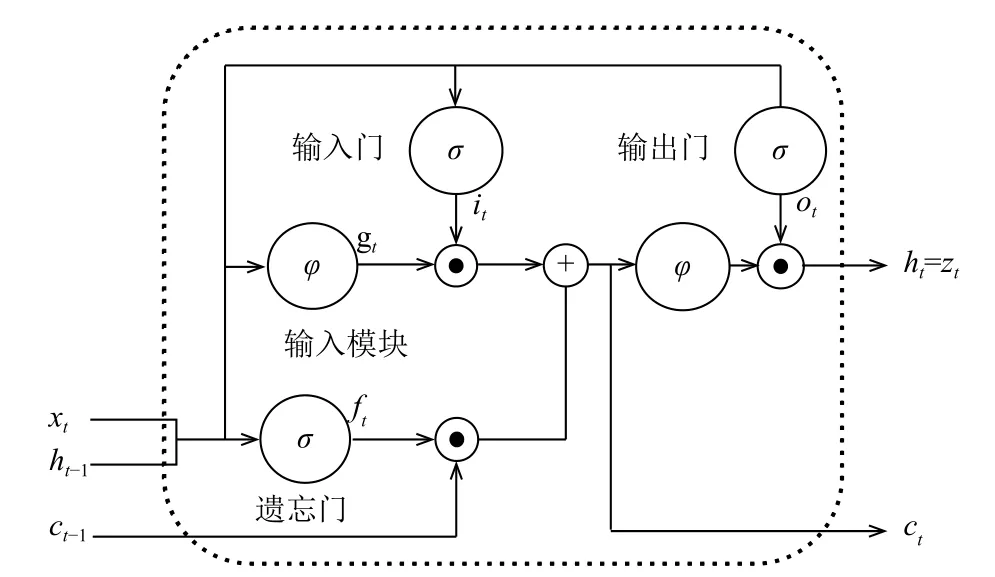
圖2 LSTM單元結(jié)構(gòu)圖
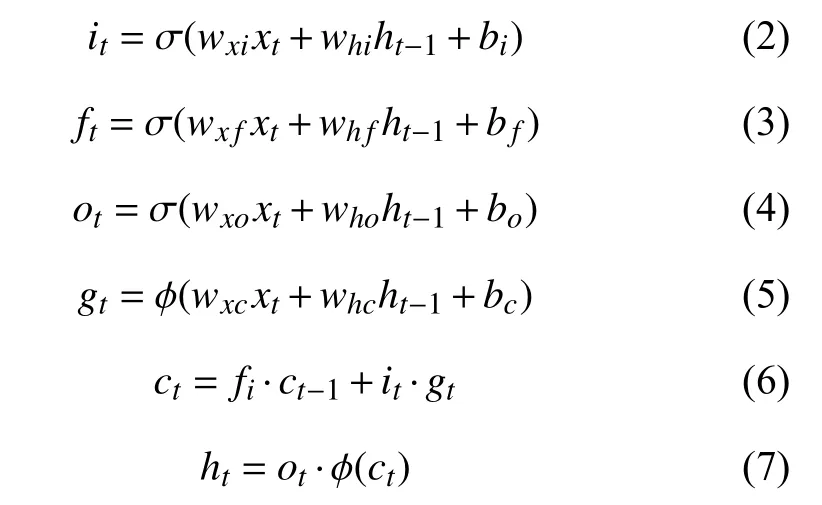

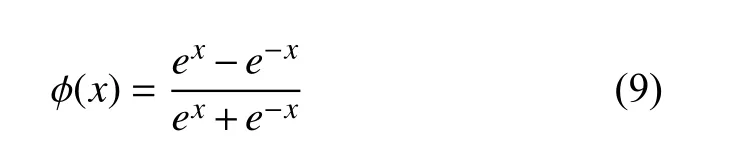
對于計算機視覺領(lǐng)域的很多任務(wù),如對模型的預(yù)測或識別,未來信息同歷史信息一樣重要.例如文本行識別,在識別當(dāng)前詞時,它之前與它之后的詞語信息都會對當(dāng)前詞的識別有所幫助.但是,前文描述的模型只能單向輸入,序列無法利用未來的信息.于是,Schuster等人[16]提出雙向RNN (BRNN)概念,它的核心思想是將序列信息分兩個方向輸入模型中,模型使用兩個隱藏層分別保存來自兩個方向的輸入數(shù)據(jù),并將相應(yīng)的輸出連接到相同的輸出層,如圖3所示.

圖3 BRNN在時間上的展開形式
圖3中,w1,w3表示輸入層到前向?qū)优c反向?qū)拥臋?quán)重,w2,w5表示隱含層自身循環(huán)的權(quán)重,w4,w6表示前向?qū)优c反向?qū)拥捷敵鰧拥臋?quán)重.
BLSTM將BRNN和LSTM這兩種改進的RNN模型組合在一起,即在BRNN模型中使用LSTM記憶單元,這樣可以更好的學(xué)習(xí)局部信息的相關(guān)性.
1.3 CTC
時域連接模型CTC[17]是一種直接標(biāo)記無分割序列的方法,適合于輸入特征和輸出標(biāo)簽之間對齊關(guān)系不確定的時間序列問題.它可以端到端地優(yōu)化模型參數(shù),并且對齊切分的邊界,使得針對輸入序列的每一幀,網(wǎng)絡(luò)能夠輸出一個標(biāo)簽或者空白標(biāo)志(‘-’).
CTC網(wǎng)絡(luò)的輸出層是在給定的輸入下,計算所有可能對應(yīng)的標(biāo)簽序列的概率,以求出標(biāo)簽概率最大的序列.對于一個長度為T的序列x,經(jīng)過神經(jīng)網(wǎng)絡(luò)計算映射,得到序列的輸出y,定義表示在t時刻標(biāo)簽為的概率,表示在整個標(biāo)簽集L∪{‘-’}上所有長度為T的序列集合,得到公式(10).
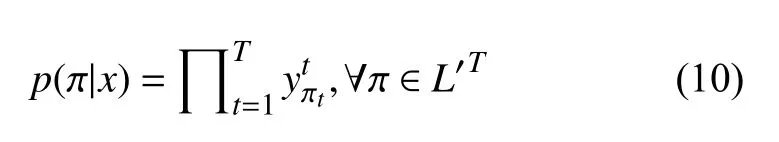
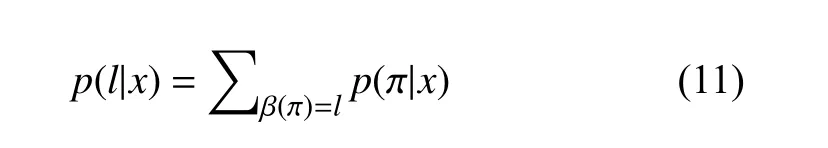
分類器的輸出應(yīng)為輸入序列最有可能的標(biāo)簽序列,如式(12)所示.
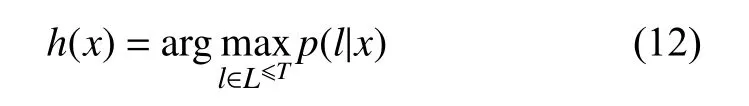
根據(jù)上述公式,目標(biāo)函數(shù)最小化上述概率的負(fù)對數(shù)似然.因為目標(biāo)函數(shù)是可導(dǎo)的,網(wǎng)絡(luò)可以通過標(biāo)準(zhǔn)的BP方法來訓(xùn)練.
2 整體模型
圖4是本文提出的模型整體架構(gòu)圖.
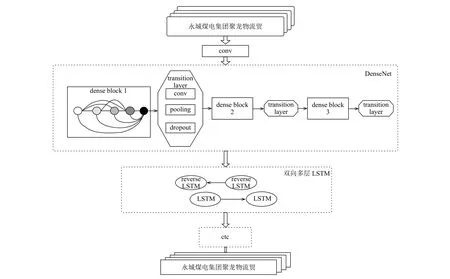
圖4 模型整體架構(gòu)圖
因為漢字種類繁多,結(jié)構(gòu)復(fù)雜,簡單的卷積神經(jīng)網(wǎng)絡(luò)已經(jīng)很難完全提取圖像細(xì)節(jié)特征,深層網(wǎng)絡(luò)又可能造成信息消失、參數(shù)繁多以及難收斂等問題,所以本模型選擇結(jié)構(gòu)簡單,但效果突出的DenseNet網(wǎng)絡(luò)結(jié)構(gòu)提取圖像底層特征.DenseNet網(wǎng)絡(luò)中的每個dense block中有4個Bottleneck layers,即BN-ReLU-Conv(1×1)-BN -ReLU- Conv (3×3)結(jié)構(gòu).該結(jié)構(gòu)中 Conv(1×1)可以減少輸入?yún)?shù)的數(shù)量; dense block結(jié)構(gòu)中每一層網(wǎng)絡(luò)都設(shè)計地很窄,只學(xué)習(xí)較少的特征序列,這樣可以減少網(wǎng)絡(luò)參數(shù),提高網(wǎng)絡(luò)效率,達(dá)到降低冗余性的目的.DenseNet網(wǎng)絡(luò)中的transition layer用來連接dense block,它由conv層、pooling層以及dropout層組成,conv層用來決定是否壓縮模型參數(shù); pooling層控制特征序列的大小,因為在dense block內(nèi)部,特征序列的空間維度是保持不變的,故而在兩個dense block之間進行下采樣; 最后插入dropout層,它是由Srivastava等人[18]在2014年提出的防止網(wǎng)絡(luò)過擬合的技術(shù),即在模型訓(xùn)練時按照一定的比例(本文設(shè)置為0.2)隨機選擇某些節(jié)點不工作,使得模型具有多模型融合的效果,可以降低網(wǎng)絡(luò)損失,提升網(wǎng)絡(luò)性能.為了不丟失圖像特征,本文沒有選擇全連接層作為DenseNet結(jié)構(gòu)的最后一層,而是直接用圖像的特征序列作為BLSTM的輸入.
接下來,多層的BLSTM提取時序信息.將DenseNet提取的多維特征序列,按照BLSTM層的輸入要求進行轉(zhuǎn)置,然后分別送給正向LSTM與反向LSTM層進行學(xué)習(xí),LSTM計算提取每張圖35列特征序列間的信息.
在BLSTM充分獲取數(shù)據(jù)間的特征后,運用CTC層對之前的訓(xùn)練數(shù)據(jù)強制對齊,實現(xiàn)無分割序列的標(biāo)簽工作.在當(dāng)前輸入下,CTC層計算每一列對應(yīng)到4001(本文字符種類數(shù)4000+1種空白)種標(biāo)簽元素上的序列概率分布,并將這些序列按照一定的規(guī)則進行映射后,統(tǒng)計每個標(biāo)簽序列的概率,求出最可能的標(biāo)簽序列并輸出.CTC轉(zhuǎn)錄層可獲得圖像的序列描述,即圖像的最終表示方式.
每個文本行圖像經(jīng)過DenseNet+BLSTM+CTC 3個主要環(huán)節(jié)得到最終的特征表達(dá),如算法1.
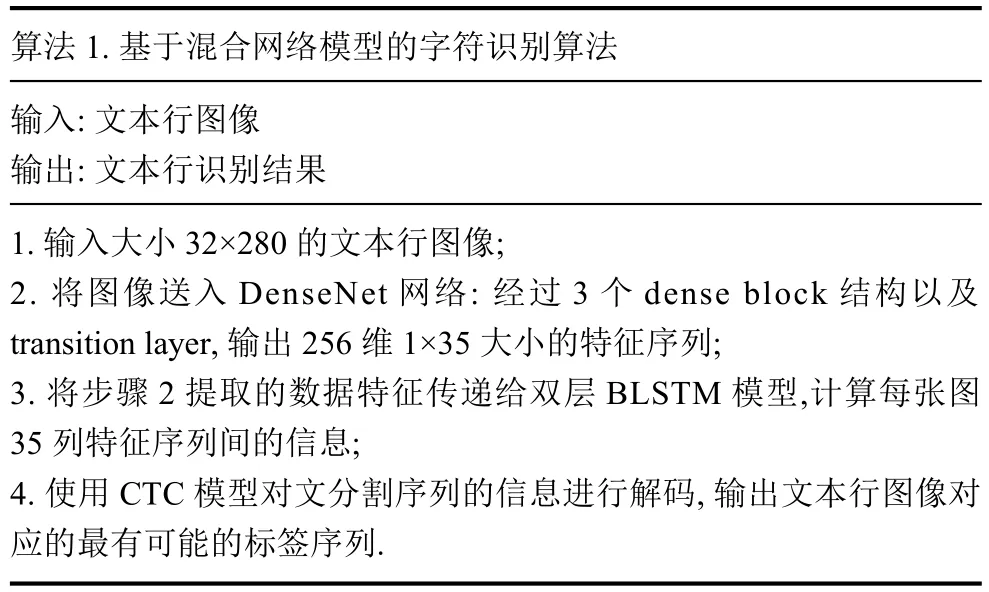
算法1.基于混合網(wǎng)絡(luò)模型的字符識別算法輸入: 文本行圖像輸出: 文本行識別結(jié)果1.輸入大小32×280的文本行圖像;2.將圖像送入DenseNet網(wǎng)絡(luò): 經(jīng)過3個dense block結(jié)構(gòu)以及transition layer,輸出256維1×35大小的特征序列;3.將步驟2提取的數(shù)據(jù)特征傳遞給雙層BLSTM模型,計算每張圖35列特征序列間的信息;4.使用CTC模型對文分割序列的信息進行解碼,輸出文本行圖像對應(yīng)的最有可能的標(biāo)簽序列.
3 實驗
3.1 實驗設(shè)置
實驗基于caffe框架.在Intel Core i7,內(nèi)存8 GB,顯卡GTX1080機器上進行訓(xùn)練,模型的初始學(xué)習(xí)率設(shè)為0.0001,學(xué)習(xí)率按照“multistep”方式更新.
3.2 實驗數(shù)據(jù)
由于發(fā)票上存在一些比較特殊的字體,而且發(fā)票上的印刷體字符圖像存在斷裂、粘連等情況,目前沒有相關(guān)已經(jīng)開源的訓(xùn)練數(shù)據(jù)庫,所以本文的實驗數(shù)據(jù)主要來自網(wǎng)上的印刷體圖像以及自己生成大規(guī)模的數(shù)據(jù).實驗圖像生成算法如算法2.

算法2.實驗圖像生成算法輸入: 文本編輯文件中4000類字符文本,包括的中文一級漢字3755個輸出: 250萬張文本行圖像Begin:1.fori=1,2,…,4000 2.將文本編輯文件中的第i個字符文本讀入程序3.使用OpenCV計算機視覺庫生成一張32×32的空白圖像4.使用freetype字體引擎將讀入的文本按照發(fā)票上的字體形式加載到空白圖像,同時設(shè)置圖像中字體的大小、圖像的空白比例等5.將原始圖像進行灰度化、二值化6.end for 7.讀取語料庫中的語句,按順序拼接上述步驟制作的單字圖像,以生成文本行圖像8.對圖像進行多種變換: 加入旋轉(zhuǎn)變化; 加入椒鹽噪聲; 高斯噪聲; 設(shè)置不同參數(shù)的腐蝕操作、膨脹操作; 對圖像反復(fù)進行拉伸操作; 加入彈性變換; 加入模糊操作等 //降低圖像質(zhì)量,擬合發(fā)票上的字符圖像9.將圖像調(diào)整至32×280大小,滿足網(wǎng)絡(luò)輸入要求10.重復(fù)7–9步,共生成250萬張圖像End
將實驗數(shù)據(jù)按照9:1的比例分成訓(xùn)練集與測試集,將圖像進行自適應(yīng)閾值二值化[19]后如圖5所示.

圖5 文本行圖像示例
3.3 實驗結(jié)果及分析
為了選取更合理的模型結(jié)構(gòu),本文對dense block的設(shè)置以及BLSTM的層數(shù)進行了多組對比實驗.
表1的實驗是在總卷積層數(shù)相同的情況下,改變dense block的結(jié)構(gòu),觀察識別效果.實驗1使用4個dense block,每個dense block內(nèi)部有6個卷積層,實驗2使用3個dense block,每個dense block內(nèi)部有8個卷積層,其中引入Bottleneck layers.從實驗結(jié)果來看,實驗2在識別率上表現(xiàn)更好,同時因為包含1×1的卷積層,參數(shù)也得到精簡.

表1 關(guān)于dense block的實驗數(shù)據(jù)表
基于表1的實驗結(jié)果,選取實驗2的dense block結(jié)構(gòu),再更改dense block內(nèi)部的Growth rate,即本模型中3×3卷積層產(chǎn)生的特征序列數(shù)量,觀察實驗性能.
表2中的實驗在DenseNet-B的基礎(chǔ)上進行.(DenseNet-B是指dense block中1×1卷積層產(chǎn)生的特征序列的數(shù)量是3×3卷積層的4倍,我們設(shè)3×3卷積層的Growth rate=k,則1×1卷積層應(yīng)有4k個特征序列.實驗3中Growth rate=16,實驗4為32) 觀察實驗結(jié)果發(fā)現(xiàn),實驗4比實驗3的識別結(jié)果稍有提升.

表2 關(guān)于Growth rate的實驗數(shù)據(jù)表
經(jīng)過多組實驗,本模型在確定DenseNet的dense block結(jié)構(gòu)后,對BLSTM的層數(shù)進行實驗.
同樣,本文對比了經(jīng)典的CNN模型和2015年大放異彩的ResNet網(wǎng)絡(luò)結(jié)構(gòu),如圖6所示.
表3列出了BLSTM分別取1層、2層以及3層時,對實驗性能的影響.對比表明,用兩層的BLSTM可以取得更好的識別率,而隨著層數(shù)的增加,模型的識別時間逐漸增加.分析認(rèn)為2層BLSTM能更好的提取文本間的信息,1層存在特征提取不充分的情況,而3層可能出現(xiàn)過擬合的情況.
首先將本文提出的模型與經(jīng)典的CNN+BLSTM+CTC模型進行對比,在同樣的實驗數(shù)據(jù)下,經(jīng)典的CNN模型的最高行識別率只有91.3%,明顯低于DenseNet模型的識別率,并且收斂速度沒有本文提出的模型快.接著,本文對ResNet+BLSTM+ CTC模型進行了多組測試,最后選取結(jié)果最好的模型與本文提出的模型進行對比.從圖6(a)可以看出,ResNet模型相比于經(jīng)典的CNN模型有較大的提升,行識別率為95.0%,而本文模型的行識別率達(dá)到96.68%.
分析圖6的(a)與(b)圖,可以看出,隨著網(wǎng)絡(luò)迭代次數(shù)的增加,三種模型都逐漸收斂,其中,DenseNet模型與ResNet模型收斂迅速; 當(dāng)模型效果趨于穩(wěn)定后,本文提出的模型識別準(zhǔn)確率最高,這也充分說明了DenseNet+ BLSTM+CTC結(jié)構(gòu)在識別率及收斂速度方面的優(yōu)越性.
為了更加充分地驗證本文模型的性能,我們又與Tesseract[20]OCR軟件進行了對比.在開源的OCR引擎中,Tesseract OCR是效果最好的.它最先由惠普實驗室開始研發(fā),至1995年時已經(jīng)成為OCR業(yè)內(nèi)最準(zhǔn)確的三款識別引擎之一.2005年,Google開始對Tesseract進行優(yōu)化.本文充分利用Tesseract可以自訓(xùn)練識別庫的優(yōu)勢,針對性地訓(xùn)練中文識別庫,并利用該識別庫實驗.
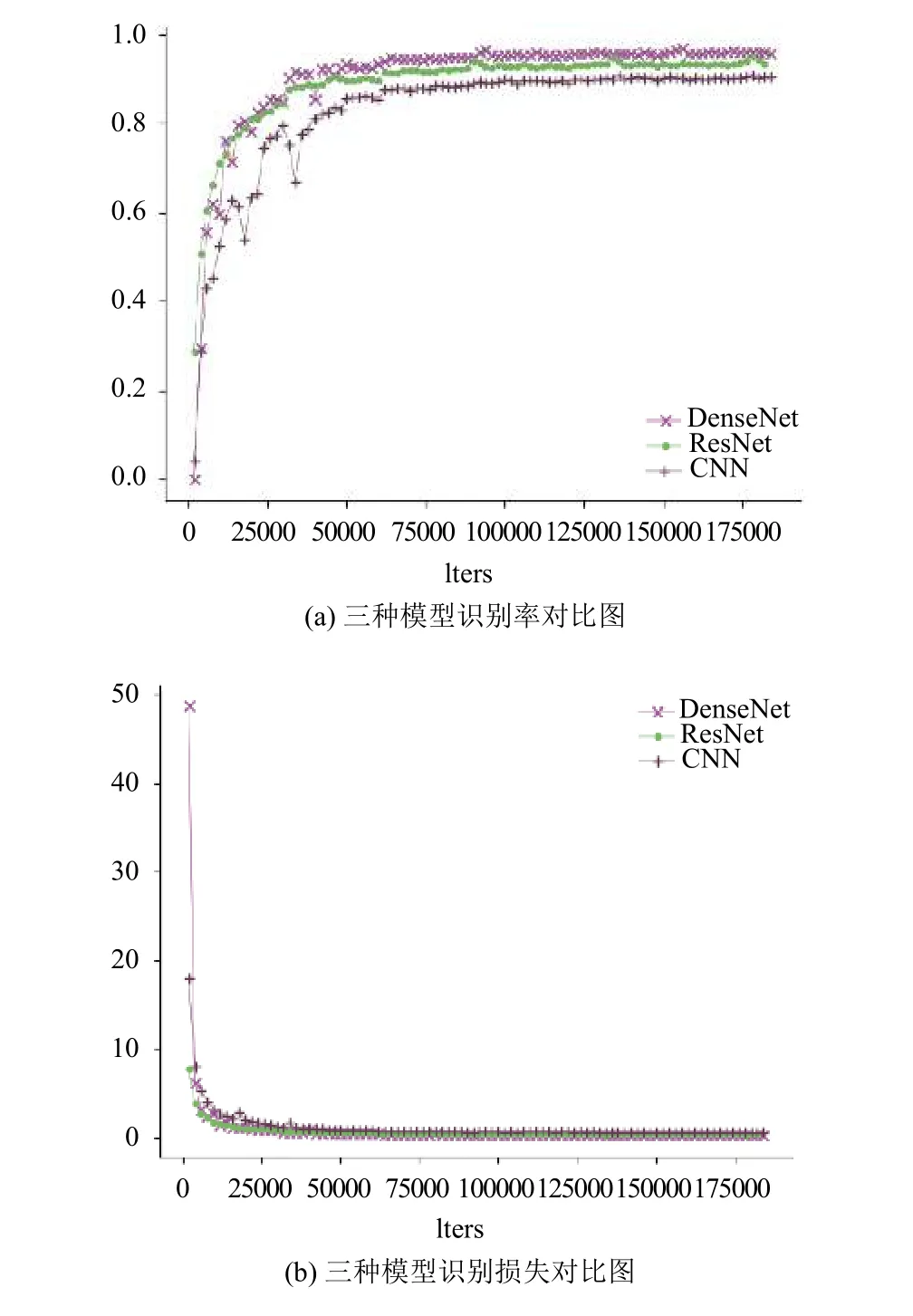
圖6 本文模型與ResNet模型識別性能對比圖

表3 BLSTM層數(shù)對實驗的影響

表4 兩種方法實驗對比
在進行Tesseract識別測試時發(fā)現(xiàn),對于很多文本行,Tesseract可能出現(xiàn)識別錯1個或2個字符的情況,所以它針對一行文本圖像完全識別正確的概率很低,但針對行中單個字符,它的識別率可以達(dá)到82.47%.對比發(fā)現(xiàn),本文提出的模型在單字識別率上提升了16.14%,而時間僅相當(dāng)于Tesseract的1/47,效果顯著.
4 結(jié)論
文本識別是一項很有挑戰(zhàn)性的任務(wù),尤其是中文識別.針對文本行圖像,本文首次提出DenseNet+BLSTM + CTC的端到端識別的混合架構(gòu).利用Dense Net自動提取文本圖像特征,多層卷積特征融合了低層形狀信息和高層語義信息,避免了手工設(shè)計圖像特征的繁瑣,減少特征計算的難度; 在分析圖像信息后,BLSTM提取字符圖像間相關(guān)性特征,并從兩個方向進行分析,前向?qū)訌那跋蚝蟛东@文本演變,后向?qū)臃捶较蚪N谋狙葑?有效的利用序列的上下文信息[21]; 最后將兩個方向的演變表達(dá)融合到CTC中,產(chǎn)生圖像的序列化表達(dá).實驗結(jié)果表明本文方法在識別率、識別時間、內(nèi)存占用多方面表現(xiàn)優(yōu)秀,并具有無限潛能,同樣適用于其他序列標(biāo)注任務(wù).
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
