基于ADTree改進(jìn)算法的輪胎大數(shù)據(jù)質(zhì)量分析①
2018-11-14 11:36:24許曉彬李敏波
計(jì)算機(jī)系統(tǒng)應(yīng)用 2018年11期
許曉彬,李敏波,2
1(復(fù)旦大學(xué) 軟件學(xué)院,上海 200433)
2(復(fù)旦大學(xué) 上海市數(shù)據(jù)科學(xué)重點(diǎn)實(shí)驗(yàn)室,上海 200433)
1 引言
隨著信息化融入工業(yè)化進(jìn)程,越來(lái)越多的工業(yè)企業(yè)已經(jīng)完成了自動(dòng)化、信息化建設(shè)[1],企業(yè)產(chǎn)業(yè)鏈的各個(gè)環(huán)節(jié)都涉及到信息技術(shù)的應(yīng)用,如生產(chǎn)監(jiān)控、成品檢測(cè)、產(chǎn)品銷(xiāo)售等.傳感器、RFID等技術(shù)與ERP、MES等信息管理系統(tǒng)已經(jīng)應(yīng)用于制造企業(yè)生產(chǎn)經(jīng)營(yíng)管理中并積累大量的工業(yè)數(shù)據(jù).相比于互聯(lián)網(wǎng)大數(shù)據(jù),工業(yè)大數(shù)據(jù)的數(shù)據(jù)類型更豐富、來(lái)源更多樣性[2].海量的工業(yè)大數(shù)據(jù)蘊(yùn)含了價(jià)值巨大的生產(chǎn)制造與質(zhì)量信息,這些信息能為企業(yè)帶來(lái)豐厚收益[3].
本文選取輪胎行業(yè)制造大數(shù)據(jù)作為工業(yè)大數(shù)據(jù)研究背景,通過(guò)整合輪胎企業(yè)各個(gè)生產(chǎn)環(huán)節(jié)的多源異構(gòu)數(shù)據(jù),構(gòu)建結(jié)構(gòu)化質(zhì)量分析數(shù)據(jù)集; 對(duì)質(zhì)量分析數(shù)據(jù)集進(jìn)行決策樹(shù)或關(guān)聯(lián)分析挖掘,可以幫助輪胎企業(yè)發(fā)現(xiàn)產(chǎn)品制造過(guò)程中的質(zhì)量異常及其影響因素,不僅能夠精確定位質(zhì)量問(wèn)題,還能幫助企業(yè)改善工藝流程參數(shù),降低產(chǎn)品的不合格率,從而實(shí)現(xiàn)企業(yè)質(zhì)量與效益的提升.傳統(tǒng)的ADTree算法不適用于大數(shù)據(jù)量的數(shù)據(jù)挖掘,本文改進(jìn)了ADTree決策樹(shù)算法,提升了其性能,使其適用于輪胎大數(shù)據(jù)質(zhì)量分析.
2 相關(guān)研究
隨著大數(shù)據(jù)概念的火熱,國(guó)內(nèi)外對(duì)工業(yè)大數(shù)據(jù)的研究也逐漸興起.Yan等提出了工業(yè)大數(shù)據(jù)問(wèn)題的一種框架,并介紹了智能制造、工業(yè)大數(shù)據(jù)帶來(lái)的挑戰(zhàn),如可靠性與安全性[4].張潔等[5]提出了一種大數(shù)據(jù)驅(qū)動(dòng)的"關(guān)聯(lián)+預(yù)測(cè)+調(diào)控"決策模式,幫助企業(yè)深層次地挖掘工業(yè)生產(chǎn)規(guī)律,提供精準(zhǔn)決策.楊枝雨使用決策樹(shù)算法對(duì)工業(yè)印花質(zhì)量問(wèn)題進(jìn)行了分析,改善了印花質(zhì)量的穩(wěn)定性[6].國(guó)內(nèi)外的研究雖然較為系統(tǒng)的闡述了工業(yè)大數(shù)據(jù)的背景、意義及解決方案,但結(jié)合具體行業(yè)或企業(yè)工業(yè)大數(shù)據(jù)進(jìn)行詳細(xì)分析挖掘的實(shí)例并不多,其中一個(gè)重要原因是工業(yè)大數(shù)據(jù)必須從工業(yè)企業(yè)處獲得,即工業(yè)大數(shù)據(jù)領(lǐng)域里,真實(shí)數(shù)據(jù)的獲取是制約學(xué)者們開(kāi)展研究的一個(gè)難題[7].
針對(duì)制造企業(yè)質(zhì)量異常數(shù)據(jù)分析,可以采用ADTree、FP-Growth[8]等算法.本文選取的是ADTree算法,在工業(yè)大數(shù)據(jù)應(yīng)用場(chǎng)景下,常規(guī)的ADTree算法在處理大數(shù)據(jù)方面稍顯低效.Pfahringer等[9]提出了ADTree的構(gòu)建優(yōu)化方案,主要將z值改進(jìn)為Zpure,作為一種剪裁技術(shù),但這種方法需要在大量迭代后才有效果,并且實(shí)驗(yàn)中數(shù)據(jù)集最多只有50 000條左右,效果還有提升的空間.楊碧姍等[10]提出了一種快速可拓展的ADTree優(yōu)化構(gòu)建算法BICA (Bottom-up Induction for Constructing ADTree),該算法設(shè)計(jì)了新的數(shù)據(jù)結(jié)構(gòu)AVW-set,這個(gè)集合大小不受數(shù)據(jù)集大小制約.同時(shí),該算法提出了自底向上的歸納算法,避免了一些冗余計(jì)算,提升了評(píng)估效率.但是,算法中AVW-set的生成與合并算法時(shí)間復(fù)雜度較高,完全可以進(jìn)一步優(yōu)化.此外,生成算法中還存在修改零權(quán)重值的問(wèn)題.本文在BICA算法的基礎(chǔ)上,主要針對(duì)以上兩點(diǎn)進(jìn)行了改進(jìn),使算法更為完善.在應(yīng)用方面,由于ADTree算法只能針對(duì)二分類問(wèn)題,所以將ADTree結(jié)合實(shí)際應(yīng)用的研究較少,Watcharapasorn等用ADTree算法對(duì)營(yíng)養(yǎng)不良導(dǎo)致病人在手術(shù)中出現(xiàn)意外這一問(wèn)題進(jìn)行了分析[11].本文在改進(jìn)ADTree算法的基礎(chǔ)上,將其應(yīng)用于輪胎大數(shù)據(jù)質(zhì)量分析,實(shí)現(xiàn)算法與實(shí)際質(zhì)量異常的影響因素分析問(wèn)題相結(jié)合.
3 輪胎質(zhì)量分析需求與數(shù)據(jù)集成
3.1 輪胎質(zhì)量分析需求
隨著工業(yè)市場(chǎng)競(jìng)爭(zhēng)的越來(lái)越激烈,制造企業(yè)要想得到客戶的認(rèn)可,高質(zhì)量的產(chǎn)品是不可或缺的[12].在大數(shù)據(jù)時(shí)代,如何利用工業(yè)大數(shù)據(jù)的挖掘技術(shù),從海量生產(chǎn)制造數(shù)據(jù)中尋找影響質(zhì)量的因素,實(shí)現(xiàn)產(chǎn)品質(zhì)量的有效控制與改善,從而提高產(chǎn)品質(zhì)量已經(jīng)成為急需解決的問(wèn)題,這使得質(zhì)量數(shù)據(jù)分析成為工業(yè)大數(shù)據(jù)的重要應(yīng)用需求,需求包括:
(1)輪胎產(chǎn)品生產(chǎn)全過(guò)程的質(zhì)量追溯;
(2)輪胎生產(chǎn)過(guò)程的質(zhì)量合格率統(tǒng)計(jì)分析;
(3)輪胎質(zhì)量異常的影響因素分析.
質(zhì)量數(shù)據(jù)分析流程主要為數(shù)據(jù)獲取、數(shù)據(jù)預(yù)處理、數(shù)據(jù)分析和分析整理步驟.其中,數(shù)據(jù)分析主要使用數(shù)據(jù)挖掘來(lái)進(jìn)行,采用多種算法進(jìn)行分析可以確保分析的完整性,起到互補(bǔ)的作用.輪胎的質(zhì)量分析可以采用關(guān)聯(lián)分析的方法,挖掘出輪胎生產(chǎn)環(huán)節(jié)中的特征指標(biāo)(例如主機(jī)手、設(shè)備、批次、工藝參數(shù)等)與輪胎質(zhì)量檢測(cè)結(jié)果之間的顯著關(guān)聯(lián)關(guān)系,實(shí)現(xiàn)對(duì)質(zhì)量問(wèn)題的追溯.除了關(guān)聯(lián)分析之外,針對(duì)二分類問(wèn)題(如輪胎質(zhì)量檢測(cè)分為合格和不合格兩種),可以使用決策樹(shù)中的ADTree算法進(jìn)行分析,這也是本文采用的挖掘算法.
總的來(lái)說(shuō),產(chǎn)品質(zhì)量異常數(shù)據(jù)分析有兩個(gè)難點(diǎn):
(1)由于工業(yè)數(shù)據(jù)體量龐大,使用傳統(tǒng)SPSS、WEKA等分析工具效率較低,一次處理數(shù)據(jù)量有限,本文主要使用HDFS+ Hive+Spark作為工業(yè)大數(shù)據(jù)質(zhì)量分析的技術(shù)支撐平臺(tái).
(2)傳統(tǒng)的ADTree算法效率有限,不太適合大數(shù)據(jù)分析,本文優(yōu)化了ADTree算法,提高了其性能.
3.2 輪胎質(zhì)量數(shù)據(jù)集成
輪胎大數(shù)據(jù)涵蓋了輪胎的整個(gè)生命周期,種類較多,輪胎企業(yè)非常看重其中的質(zhì)量大數(shù)據(jù).輪胎在整個(gè)生產(chǎn)過(guò)程中重點(diǎn)是硫化與成型工序,同時(shí)輪胎的動(dòng)平衡檢測(cè)是輪胎質(zhì)量檢測(cè)中的關(guān)鍵一環(huán)[13].與動(dòng)平衡檢測(cè)結(jié)果相關(guān)的數(shù)據(jù)包括輪胎的硫化數(shù)據(jù)、成型數(shù)據(jù).輪胎質(zhì)量異常數(shù)據(jù)集中所包含硫化機(jī)的溫度、壓力等屬性均是一系列時(shí)序數(shù)據(jù),對(duì)這些屬性進(jìn)一步細(xì)化抽取其統(tǒng)計(jì)指標(biāo)作為輔助性特征,這些統(tǒng)計(jì)特征包括平均值、方差、最大值、最小值等.對(duì)輪胎生產(chǎn)中的時(shí)序型數(shù)據(jù)分別計(jì)算上述統(tǒng)計(jì)指標(biāo),添加到質(zhì)量異常數(shù)據(jù)追溯分析數(shù)據(jù)集中作為后續(xù)分析的基礎(chǔ).
總體來(lái)說(shuō),輪胎質(zhì)量數(shù)據(jù)可以分為兩大類數(shù)據(jù),分別是質(zhì)量檢測(cè)數(shù)據(jù)和質(zhì)量生產(chǎn)數(shù)據(jù).質(zhì)量檢測(cè)數(shù)據(jù)是產(chǎn)品生產(chǎn)完成后進(jìn)行的檢測(cè)數(shù)據(jù)集,主要包括產(chǎn)品編號(hào)、各個(gè)檢測(cè)項(xiàng)目和檢測(cè)結(jié)果,其中動(dòng)平衡檢測(cè)結(jié)果包括三個(gè)指標(biāo)BAL_RANK,RO_RANK與UFM_RANK,每個(gè)指標(biāo)在1到5中取值,只要三個(gè)指標(biāo)中至少有一個(gè)指標(biāo)為4或5,則產(chǎn)品為不合格品.質(zhì)量生產(chǎn)數(shù)據(jù)是產(chǎn)品在生產(chǎn)過(guò)程中產(chǎn)生的相關(guān)數(shù)據(jù),主要包括產(chǎn)品編號(hào)、各設(shè)備編號(hào)、生產(chǎn)時(shí)間、班組、各操作人員,各工序的工藝參數(shù)集等.以上兩種數(shù)據(jù)可以用產(chǎn)品標(biāo)號(hào)關(guān)聯(lián)起來(lái),形成結(jié)構(gòu)化的質(zhì)量數(shù)據(jù)集.
輪胎生產(chǎn)制造的各種數(shù)據(jù)存儲(chǔ)在企業(yè)的MES、ERP等不同系統(tǒng)中,這些數(shù)據(jù)需要整合起來(lái).首先使用數(shù)據(jù)接口將這些數(shù)據(jù)存儲(chǔ)在關(guān)系型數(shù)據(jù)庫(kù)中.然后,利用Sqoop配置關(guān)系型數(shù)據(jù)庫(kù)與HDFS之間的數(shù)據(jù)連接[14],以增量導(dǎo)入的方式獲取所有質(zhì)量相關(guān)數(shù)據(jù),構(gòu)建大數(shù)據(jù)存儲(chǔ)中心來(lái)實(shí)現(xiàn)數(shù)據(jù)集中管理.接下來(lái)進(jìn)行數(shù)據(jù)預(yù)處理工作,如重復(fù)數(shù)據(jù)的去除、數(shù)據(jù)缺失處理等[15].最后,使用多表合并技術(shù),在Hive中集成前面獲取到的所有質(zhì)量數(shù)據(jù),去建立結(jié)構(gòu)化質(zhì)量分析數(shù)據(jù)集,該數(shù)據(jù)集將應(yīng)用于數(shù)據(jù)挖掘的進(jìn)一步分析[16].
4 基于ADTree決策樹(shù)的質(zhì)量分析
4.1 輪胎質(zhì)量大數(shù)據(jù)分析方法
圖1展示了質(zhì)量數(shù)據(jù)分析的流程,其中數(shù)據(jù)獲取和數(shù)據(jù)預(yù)處理已在3.2節(jié)闡述.質(zhì)量分析分為單因素分析與多因素分析.單因素分析即使用統(tǒng)計(jì)的方式,通過(guò)執(zhí)行HiveQL查詢語(yǔ)句,得到單個(gè)因素與不合格率的關(guān)系.對(duì)山東玲瓏輪胎公司的千萬(wàn)級(jí)輪胎質(zhì)量數(shù)據(jù)進(jìn)行單因素分析,可以得到一些初步結(jié)論,例如不同物料編碼的輪胎不合格率差異十分明顯,其中21種物料編碼的輪胎占產(chǎn)品總數(shù)的0.7%,卻產(chǎn)生了13.3%的不合格品.單因素分析同樣能排除一些影響因素,例如輪胎硫化班組分早、中、晚班,容易想到晚班的工人是否會(huì)因?yàn)榫Σ粷?jì)導(dǎo)致不合格率增加,但是統(tǒng)計(jì)結(jié)果表明三個(gè)班組的平均不合格率幾乎相同.
產(chǎn)品質(zhì)量的多因素分析使用數(shù)據(jù)挖掘的方法來(lái)找到造成不良品的影響因素.本文將使用ADTree決策樹(shù)作為輪胎質(zhì)量分析的算法,把輪胎生產(chǎn)過(guò)程中的硫化工序工藝參數(shù)特征值(內(nèi)溫、內(nèi)壓、模溫、板溫的最大值、最小值、平均值、方差)、硫化操作人員(CUR_ZJS_ID)、成型操作人員(ZJS_ID)、各生產(chǎn)設(shè)備(POT_ID,EQUIP_ID,EQUIP_CODE)、生產(chǎn)班次(CLASS)、生產(chǎn)車(chē)間(WOKR_SHOP_CODE)、生產(chǎn)模具(MOLD_ID)、生產(chǎn)批次(CUR_BATCH_ID)作為ADTree算法的輸入,并將qualified字段設(shè)為標(biāo)記字段,該字段為1代表產(chǎn)品合格,如果為2則代表產(chǎn)品不合格.ADTree算法將輸出一個(gè)決策樹(shù)作為挖掘結(jié)果.由于傳統(tǒng)的ADTree算法效率較低,無(wú)法進(jìn)行大數(shù)據(jù)下的分析,因此本文將對(duì)ADTree算法進(jìn)行改進(jìn).
4.2 傳統(tǒng)ADTree算法
ADTree算法由Freund和Mason提出[17],其優(yōu)點(diǎn)在于,它的分類準(zhǔn)確率往往比其他決策樹(shù)算法要高,可以同時(shí)處理離散型和數(shù)值連續(xù)型輸入?yún)?shù),并且能夠給出預(yù)測(cè)結(jié)果的置信度.ADTree不僅能做分類工作,其個(gè)別節(jié)點(diǎn)還可以評(píng)估自己的預(yù)測(cè)能力,因此在輪胎質(zhì)量分析問(wèn)題中,可以通過(guò)節(jié)點(diǎn)來(lái)分析導(dǎo)致最終質(zhì)量不合格的潛在影響因素.
ADTree算法適用于解決二分類問(wèn)題,例如輪胎質(zhì)量分析中的合格與不合格就是典型的二分類情況.ADTree的圖形顯示和傳統(tǒng)決策樹(shù)不同,它包括兩種節(jié)點(diǎn): 預(yù)測(cè)節(jié)點(diǎn)和決策節(jié)點(diǎn).決策節(jié)點(diǎn)對(duì)應(yīng)一個(gè)分裂測(cè)試,訓(xùn)練集的樣本經(jīng)過(guò)分裂測(cè)試后被劃分到相應(yīng)預(yù)測(cè)節(jié)點(diǎn)中.每個(gè)預(yù)測(cè)節(jié)點(diǎn)p對(duì)應(yīng)一個(gè)預(yù)測(cè)值,同時(shí)包括一部分樣本,劃分到某個(gè)預(yù)測(cè)節(jié)點(diǎn)的樣本集稱為F(p).
傳統(tǒng)ADTree算法的輸入包括兩個(gè)集合,第一個(gè)集合里的每一個(gè)元素包括了屬性向量和分類值,其中分類值的取值為1或–1(也可以為1或0),在輪胎質(zhì)量分析中分別代表不合格與合格.第二個(gè)集合是權(quán)重Wi(樣本i的權(quán)重)的集合.ADTree的構(gòu)建需要經(jīng)過(guò)T次迭代,每次迭代找到全局的最佳分裂測(cè)試,然后生成相應(yīng)的預(yù)測(cè)節(jié)點(diǎn)和決策節(jié)點(diǎn).最佳分裂測(cè)試通過(guò)(1)式取到最小值來(lái)獲得:
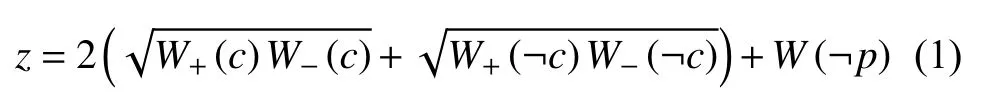
其中,c代表分裂測(cè)試,W+(c)即預(yù)測(cè)節(jié)點(diǎn)樣本中滿足c的正標(biāo)記權(quán)重和,W(?p)為不在預(yù)測(cè)節(jié)點(diǎn)里的樣本權(quán)重和.
4.3 ADTree改進(jìn)算法
傳統(tǒng)的ADTree算法受限于性能,不適用于大數(shù)據(jù)問(wèn)題.學(xué)者Pfahringer提出了一個(gè)新的公式:
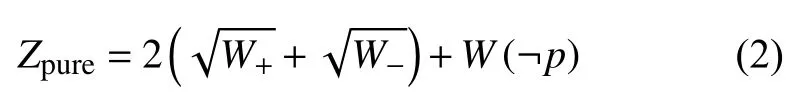
Zpure的計(jì)算不需要經(jīng)過(guò)分裂測(cè)試,只要累加F(p)的正負(fù)權(quán)重和即可.z和Zpure經(jīng)過(guò)拉普拉斯修正后,Zpure會(huì)成為z的下限.如果根據(jù)F(p)計(jì)算出來(lái)的Zpure已經(jīng)大于等于當(dāng)前迭代的最小z值,那么當(dāng)前F(p)的所有分裂測(cè)試評(píng)估值z(mì)都會(huì)大于等于當(dāng)前迭代的最小z值,所以這個(gè)節(jié)點(diǎn)不需要尋找更好的分裂測(cè)試,可以直接跳過(guò).這種優(yōu)化能提高傳統(tǒng)ADTree算法的性能,但效果有限.楊碧姍等提出了BICA算法,通過(guò)以空間換時(shí)間的策略,降低了計(jì)算評(píng)估值z(mì)的復(fù)雜程度,極大地提升了算法的性能.本文在BICA算法的基礎(chǔ)上做了進(jìn)一步優(yōu)化,并修正了原算法中出現(xiàn)的零權(quán)重值問(wèn)題,提出了ADTree改進(jìn)算法.
BICA算法定義了新的數(shù)據(jù)結(jié)構(gòu)AVW-set(以下簡(jiǎn)稱為set),set由ADTree算法需要處理的樣本集生成.表1是一個(gè)簡(jiǎn)單的樣本集,共有三條記錄,其中類別和權(quán)重是兩個(gè)樣本標(biāo)識(shí),類別為1代表不合格,類別為–1代表合格,而權(quán)重一般初始都設(shè)為1.除去樣本的標(biāo)識(shí),每個(gè)樣本有兩個(gè)屬性,分別是操作人員和內(nèi)溫最小值.樣本的每個(gè)屬性對(duì)應(yīng)一個(gè)set,如本例中就有兩個(gè)set,分別是操作人員的set和內(nèi)溫最小值的set.每個(gè)set有三個(gè)屬性,分別是屬性名、正標(biāo)記權(quán)重和與負(fù)標(biāo)記權(quán)重和.如果set記錄的屬性attr是連續(xù)型的,取所有屬性值v,記錄F(p)中滿足屬性attr≤v的正標(biāo)記權(quán)重和與負(fù)標(biāo)記權(quán)重和; 如果attr是離散型的,只記錄F(p)中滿足屬性attr=v的正標(biāo)記權(quán)重和與負(fù)標(biāo)記權(quán)重和.
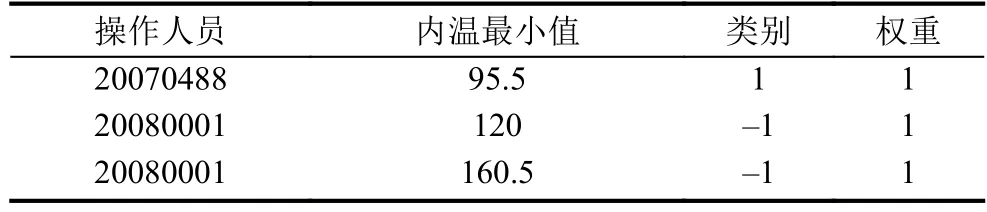
表1 預(yù)測(cè)節(jié)點(diǎn)p擁有的樣本集
以表1的樣本集為例,內(nèi)溫最小值屬性是連續(xù)型的.第一個(gè)值是95.5,在三個(gè)樣本中只有一個(gè)樣本的內(nèi)溫最小值小于等于該值,同時(shí)該樣本的類別為1,故取其權(quán)重1,算在正標(biāo)記權(quán)重和里.同理,第三個(gè)值是160.5,三個(gè)樣本的內(nèi)溫最小值都小于等于該值,統(tǒng)計(jì)這三個(gè)樣本的權(quán)重,得到正標(biāo)記權(quán)重和為1,負(fù)標(biāo)記權(quán)重和為2.構(gòu)建結(jié)果如表2所示.

表2 內(nèi)溫最小值的set
而操作人員屬于離散型值,且只有兩種值.20080001有兩個(gè)樣本,所以負(fù)標(biāo)記權(quán)重和為2.操作手的set構(gòu)建結(jié)果如表3所示.

表3 操作人員的set
BICA算法中的set在離散型屬性的正標(biāo)記權(quán)重和或負(fù)標(biāo)記權(quán)重和為0時(shí),會(huì)賦一個(gè)自定義的較小值,這是錯(cuò)誤的.Pfahringer在其論文[9]的第3節(jié)提到了權(quán)重和為0不會(huì)影響ADTree算法的結(jié)果,從解釋性來(lái)說(shuō),主機(jī)手20080001操作了兩個(gè)產(chǎn)品,都是合格的,如果正標(biāo)記權(quán)重和不設(shè)為0,那么這個(gè)主機(jī)手的合格率就不是100%了,這明顯也不合理.正確的做法是保留0這個(gè)值.
此外,BICA算法構(gòu)建連續(xù)型屬性的set時(shí),采用先掃描樣本集,獲得所有屬性值,然后對(duì)屬性值排序,再記錄每個(gè)屬性值的正負(fù)權(quán)重和的方式.假設(shè)樣本數(shù)量是X,不同屬性個(gè)數(shù)是Y,那么時(shí)間復(fù)雜度是O(X)+O(YlgY)+O(XY).本算法在獲取樣本集所有屬性值的同時(shí),直接記錄每個(gè)屬性值的權(quán)重和.待屬性值排序完畢后,從小到大掃描一遍,將權(quán)重和逐次累加即可,前兩步的時(shí)間復(fù)雜度不變,第三步的時(shí)間復(fù)雜度從O(XY)降到了O(Y),從而減少構(gòu)建set的時(shí)間.
所有屬性的set都建立完成后,將被統(tǒng)一放到AVW-group (以下簡(jiǎn)稱group)里作為一個(gè)集合.
在分裂測(cè)試中,如果屬性attr為連續(xù)型,每個(gè)分裂測(cè)試為attr≤(Vj+Vj+1)/2,即每?jī)蓚€(gè)相鄰數(shù)值的均值.如果屬性attr為離散型,分裂測(cè)試較為簡(jiǎn)單,直接是attr=Vj.這樣設(shè)計(jì)后,set起到的作用就是記錄了預(yù)測(cè)節(jié)點(diǎn)P的每個(gè)分裂測(cè)試c的正負(fù)標(biāo)記權(quán)重和.ADTree中的內(nèi)部預(yù)測(cè)節(jié)點(diǎn)的set可以根據(jù)下文介紹的自底向上的合并方法獲得,而傳統(tǒng)ADTree算法在每個(gè)預(yù)測(cè)節(jié)點(diǎn)計(jì)算z時(shí)都要計(jì)算這兩個(gè)值,效率較低.同時(shí),set的定義確保了該數(shù)據(jù)結(jié)構(gòu)的大小和樣本數(shù)量無(wú)關(guān),只和每個(gè)屬性的不同取值個(gè)數(shù)有關(guān).這樣,在計(jì)算Zpure時(shí),只需要掃描set的各個(gè)值即可,不需要像傳統(tǒng)ADTree算法一樣掃描整個(gè)樣本集.設(shè)計(jì)set不僅減少了正負(fù)標(biāo)記權(quán)重和的重復(fù)計(jì)算,其容量一般也遠(yuǎn)小于樣本數(shù)量,所以set占的空間并不大.
BICA算法的分裂測(cè)試評(píng)估改為自底向上的歸納來(lái)進(jìn)行,可以省去部分內(nèi)節(jié)點(diǎn)的group計(jì)算.每個(gè)預(yù)測(cè)節(jié)點(diǎn)都有對(duì)應(yīng)的group,這涉及到group的合并問(wèn)題.只要預(yù)測(cè)節(jié)點(diǎn)是ADTree的非葉子節(jié)點(diǎn),則取它的第一個(gè)決策子節(jié)點(diǎn),將其兩個(gè)后代節(jié)點(diǎn)的group合并成本節(jié)點(diǎn)的group.由于每個(gè)group包含多個(gè)set,所以合并時(shí)根據(jù)同屬性的set進(jìn)行合并.
對(duì)于離散型屬性的set,直接合并相同屬性的正負(fù)權(quán)重和即可.對(duì)連續(xù)型set合并,設(shè)合并后的set為P,待合并的set為X,Y,其中X,Y在構(gòu)建時(shí)已經(jīng)排序.整個(gè)過(guò)程通過(guò)歸并排序的算法持續(xù)進(jìn)行,x,y,p分別初始化為X,Y,P的末尾記錄.

算法1.連續(xù)型set合并輸入: 待合并setX,Y輸出: 合并后的setP當(dāng)x,y沒(méi)有全部指向set起始記錄時(shí):1)P[p].W+=X[x].W++Y[y].W+2)P[p].W-=X[x].W–+Y[y].W–3) IFX[x].value
同時(shí),BICA對(duì)連續(xù)型屬性進(jìn)行合并時(shí),會(huì)先掃描一遍兩個(gè)待合并的set,得到新set里的屬性值,再掃描一遍兩個(gè)待合并的set,計(jì)算出新set里的正負(fù)權(quán)重和.實(shí)際上,只需要對(duì)兩個(gè)待合并的set從后往前掃描一遍,就可以生成新的set,如上文的算法所示,這樣能減少合并的時(shí)間.通過(guò)set的合并,可以充分利用已知信息,不需要重復(fù)計(jì)算,同時(shí)合并的時(shí)間復(fù)雜度是線性的.而傳統(tǒng)的ADTree算法在評(píng)估z值時(shí),需要對(duì)每個(gè)預(yù)測(cè)節(jié)點(diǎn)的樣本的每個(gè)連續(xù)型屬性進(jìn)行排序,在大數(shù)據(jù)量情況下開(kāi)銷(xiāo)巨大.
本文對(duì)BICA算法中的ADTree構(gòu)建算法進(jìn)行了適當(dāng)改進(jìn).當(dāng)算法遍歷到葉子節(jié)點(diǎn)時(shí),如果葉子節(jié)點(diǎn)的正負(fù)標(biāo)記權(quán)重和不全為正數(shù),那說(shuō)明這個(gè)節(jié)點(diǎn)是完美分裂測(cè)試所生成的,不需要再做處理.原算法中缺少這一判斷,所以遍歷到葉子節(jié)點(diǎn)后一定會(huì)進(jìn)入算法的第4步,這會(huì)增加算法的時(shí)間.修改后的算法共T次迭代(即生成T個(gè)分裂測(cè)試),每次迭代用后序遍歷預(yù)測(cè)節(jié)點(diǎn)的方式,通過(guò)得到最小的z找到最佳分裂測(cè)試,生成新的預(yù)測(cè)節(jié)點(diǎn)p.算法不僅采用了Pfahringer等提出的Zpure剪裁技術(shù),也結(jié)合了BICA自底向上歸納評(píng)估的思想,分裂測(cè)試評(píng)估過(guò)程核心部分偽代碼如算法2.

算法2.ADTree評(píng)估算法輸入: 根節(jié)點(diǎn)r及根節(jié)點(diǎn)的F(p)輸出: 節(jié)點(diǎn)的group 1) 訪問(wèn)一個(gè)預(yù)測(cè)節(jié)點(diǎn)p 2) 如果p是葉子a) 根據(jù)F(p)計(jì)算group b) 計(jì)算p的正負(fù)權(quán)重和、Zpure,如果正負(fù)權(quán)重和不全為正數(shù),直接返回3) 否則(即p是內(nèi)節(jié)點(diǎn))a) 取p的第一個(gè)決策子節(jié)點(diǎn)d,d是p的決策子節(jié)點(diǎn)中的最佳分裂b) 取d的兩個(gè)預(yù)測(cè)子節(jié)點(diǎn)q與r,計(jì)算它們的group,然后分別作為輸入,遞歸調(diào)用本算法,這樣就起到了后序遍歷的作用c) 將q與r的group合并為p的group,計(jì)算p的正負(fù)權(quán)重和、Zpure 4) 如果當(dāng)前p的Zpure小于當(dāng)前最小的z,因?yàn)閆pure是z的下限,那么可能存在z比當(dāng)前最小的z還小,所以對(duì)于group里的所有set的所有值v a) 計(jì)算分裂測(cè)試c的z b) 如果z比最小的z還小,那么最小的z設(shè)為這個(gè)值,并且將分裂測(cè)試c設(shè)為最佳測(cè)試,p設(shè)為最佳分裂節(jié)點(diǎn)5) 對(duì)于p除了第一個(gè)決策子節(jié)點(diǎn)d的其余子節(jié)點(diǎn)d (如果存在的話)a) 取d的兩個(gè)子節(jié)點(diǎn)q與r,計(jì)算它們的group,然后分別作為輸入,遞歸調(diào)用本算法
5 質(zhì)量分析結(jié)果與算法性能實(shí)驗(yàn)
5.1 質(zhì)量分析結(jié)果
本文對(duì)山東玲瓏輪胎公司提供的千萬(wàn)級(jí)輪胎數(shù)據(jù)進(jìn)行質(zhì)量分析.本例選取的輪胎物料代碼是221003794,可用樣本數(shù)為308 880,其中質(zhì)檢合格306 471,不合格2409,不合格率約為0.78%.借助生成迭代次數(shù)為10的ADTree圖形進(jìn)行分析,如下圖所示,每一個(gè)橢圓形的節(jié)點(diǎn)是分裂測(cè)試,每個(gè)分裂測(cè)試有兩個(gè)矩形的子節(jié)點(diǎn),節(jié)點(diǎn)上的數(shù)字代表置信打分,本例中這個(gè)打分較高的話則代表該因素可能對(duì)質(zhì)量不合格有重要影響.
根據(jù)ADTree的挖掘結(jié)果,使用Hive數(shù)據(jù)庫(kù)對(duì)質(zhì)量數(shù)據(jù)進(jìn)行追溯,查詢ADTree挖掘出的質(zhì)量影響因素對(duì)產(chǎn)品不合格率的提升程度,可以得到如下結(jié)論:
1) 成型主機(jī)手20070488負(fù)責(zé)的產(chǎn)品中,合格17 952件,不合格1260件,不合格率高達(dá)約6.6%.這名主機(jī)手經(jīng)手了約6.2%的產(chǎn)品,卻產(chǎn)生了約52%的不合格品,可見(jiàn)其操作水平非常之低.
2) 其余主機(jī)手生產(chǎn)的輪胎,在平均內(nèi)壓<1.776時(shí),合格29 053件,不合格413件,不合格率約1.4%;平均內(nèi)壓在[1.776,1.817]時(shí),合格238 090件,不合格731件,不合格率僅為約0.3%; 當(dāng)平均內(nèi)壓>1.817時(shí),合格21 376件,不合格僅5件,不合格率幾乎忽略不計(jì).由此可見(jiàn),輪胎硫化過(guò)程的硫化機(jī)平均內(nèi)壓對(duì)于最后的質(zhì)檢合格與否起到了重要影響.
3、硫化批次是20161206時(shí),合格864件,不合格401件,不合格率高達(dá)31.7%.其中,經(jīng)手成型主機(jī)手20070488的951件產(chǎn)品更是有382件不合格,不合格率約為40.1%; 剩余314件產(chǎn)品有20件不合格,不合格率約為6.4%,也遠(yuǎn)高于平均不合格率.因此,該批次的生產(chǎn)出現(xiàn)了明顯的問(wèn)題.
以上挖掘結(jié)果反映出幾個(gè)問(wèn)題.首先是成型主機(jī)手20070488,這名主機(jī)手的生產(chǎn)操作水平差得離譜,嚴(yán)重影響了輪胎質(zhì)量,企業(yè)可以考慮對(duì)其進(jìn)行技能培訓(xùn),或者調(diào)離崗位.其次是輪胎加工中的平均內(nèi)壓,ADTree反映該工藝參數(shù)對(duì)輪胎質(zhì)量有較大影響,企業(yè)需要對(duì)照自身制定的工藝參數(shù),確保輪胎生產(chǎn)時(shí)平均內(nèi)壓處于合理范圍內(nèi).最后,硫化批次是20161206 (即2016年12月6日)時(shí),平均不合格率非常高,企業(yè)需要排查當(dāng)天的生產(chǎn)狀況,分析可能存在的問(wèn)題.
由于不同輪胎物料代碼經(jīng)過(guò)的設(shè)備、操作人員、生產(chǎn)工藝參數(shù)等均不相同,因此每種輪胎物料代碼的挖掘結(jié)果存在差異.但通過(guò)整理,可以總結(jié)出影響輪胎質(zhì)量的普遍規(guī)律:
1) 操作人員的水平好壞會(huì)影響輪胎質(zhì)量,個(gè)別操作人員經(jīng)手的輪胎不合格率會(huì)非常高,企業(yè)應(yīng)該及時(shí)采取人員改進(jìn)措施.
2) 輪胎生產(chǎn)過(guò)程中的平均內(nèi)壓對(duì)輪胎質(zhì)量有明顯影響,一般來(lái)說(shuō),如果平均內(nèi)壓偏低,那么輪胎的整體不合格率會(huì)有提升.因此,企業(yè)需要提高生產(chǎn)技術(shù),確保硫化過(guò)程的平均內(nèi)壓在合理范圍內(nèi).
3) 由于少量生產(chǎn)設(shè)備存在問(wèn)題,導(dǎo)致該設(shè)備生產(chǎn)的輪胎品種不合格率偏高.企業(yè)應(yīng)該及時(shí)維修設(shè)備或考慮購(gòu)置新設(shè)備,以此保證產(chǎn)品質(zhì)量.
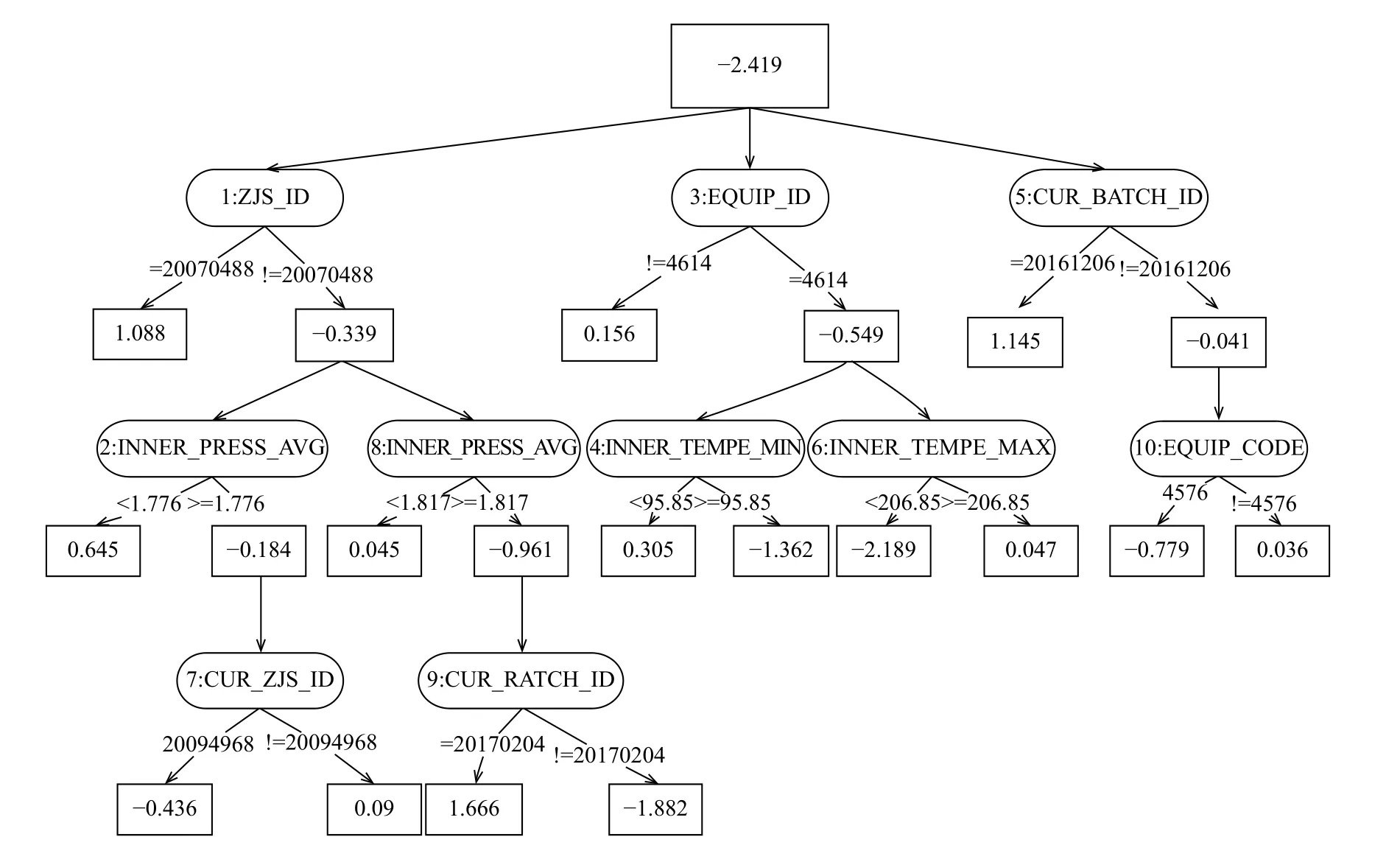
圖2 ADTree算法挖掘結(jié)果圖
5.2 算法性能實(shí)驗(yàn)
雖然現(xiàn)在已經(jīng)有了較為成熟的大數(shù)據(jù)處理技術(shù),但是算法本身的提升仍然會(huì)對(duì)整體性能有所提高.以輪胎質(zhì)量分析數(shù)據(jù)集物料編碼221005405、221003790作為實(shí)驗(yàn)的數(shù)據(jù)集,數(shù)據(jù)集大小為379 010.實(shí)驗(yàn)環(huán)境為Intel i5 7000,操作系統(tǒng)為Centos 6.8,4臺(tái)24 GB內(nèi)存,通過(guò)Java調(diào)用Spark并連接Hive進(jìn)行實(shí)現(xiàn).實(shí)驗(yàn)比較結(jié)果見(jiàn)表4所示.

表4 新算法實(shí)驗(yàn)結(jié)果比較
由實(shí)驗(yàn)可見(jiàn),BICA算法相比于Pfahringer等提出的傳統(tǒng)算法,在建樹(shù)時(shí)間上大大縮短了,這是因?yàn)锽ICA用了set和自底向上的評(píng)估思路,通過(guò)合并group這種利用已知數(shù)據(jù)的方法,減少了Zpure和z的計(jì)算量,節(jié)省了排序次數(shù); 在排序方面,Pfahringer的算法在評(píng)估連續(xù)型屬性時(shí)需要對(duì)整個(gè)數(shù)據(jù)集排序,而B(niǎo)ICA算法只對(duì)set中的屬性值排序,這也是性能提升的一方面.本算法改進(jìn)了BICA算法建立set,合并group的方式,優(yōu)化了時(shí)間復(fù)雜度,并且對(duì)樹(shù)的構(gòu)建算法也做了適當(dāng)改進(jìn),在其基礎(chǔ)上進(jìn)一步提升了性能.
內(nèi)存方面,由于算法的整體思路是以空間換時(shí)間,因此傳統(tǒng)的ADTree算法內(nèi)存占用較低,但新算法的內(nèi)存占用并不大,是可以接受的.
6 總結(jié)
隨著信息行業(yè)的快速發(fā)展,很多工業(yè)企業(yè)正在大力建設(shè)工業(yè)信息化,同時(shí)也積累了大量的工業(yè)數(shù)據(jù).在大數(shù)據(jù)時(shí)代的背景下,如何利用這些數(shù)據(jù)成為了關(guān)鍵問(wèn)題[18].通過(guò)分析、挖掘這些工業(yè)數(shù)據(jù),能夠得到許多對(duì)企業(yè)有價(jià)值的信息,使企業(yè)更好地發(fā)展.
本文選取輪胎行業(yè)大數(shù)據(jù)作為工業(yè)大數(shù)據(jù)研究的案例,分析了輪胎行業(yè)大數(shù)據(jù)的需求與數(shù)據(jù)特征,并開(kāi)展了輪胎質(zhì)量數(shù)據(jù)分析工作.先利用大數(shù)據(jù)技術(shù),將輪胎生產(chǎn)各個(gè)環(huán)節(jié)的多源異構(gòu)數(shù)據(jù)整合起來(lái),經(jīng)過(guò)預(yù)處理等流程,構(gòu)建出大規(guī)模的結(jié)構(gòu)化質(zhì)量分析數(shù)據(jù)集.本文重點(diǎn)介紹了使用改進(jìn)后的ADTree算法進(jìn)行輪胎質(zhì)量多因素分析,實(shí)驗(yàn)證明,改進(jìn)后的算法更適用于大數(shù)據(jù)背景下的數(shù)據(jù)挖掘.ADTree的挖掘結(jié)果經(jīng)過(guò)整理,可以找出影響輪胎質(zhì)量的重要因素,這種精確定位出來(lái)的問(wèn)題能夠幫助企業(yè)改善工業(yè)流程,降低產(chǎn)品的不合格率,從而實(shí)現(xiàn)企業(yè)效益的提升.
猜你喜歡
中學(xué)生數(shù)理化·八年級(jí)物理人教版(2021年12期)2021-12-31 03:23:08
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
中學(xué)生數(shù)理化·中考版(2020年10期)2020-11-27 01:59:48
中國(guó)生殖健康(2019年2期)2019-08-23 08:12:08
電子制作(2018年18期)2018-11-14 01:48:24
產(chǎn)品可靠性報(bào)告(2017年7期)2017-09-05 09:49:12
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
汽車(chē)觀察(2016年3期)2016-02-28 13:16:26
中國(guó)中醫(yī)藥現(xiàn)代遠(yuǎn)程教育(2014年11期)2014-08-08 13:23:44
中國(guó)質(zhì)量與標(biāo)準(zhǔn)導(dǎo)報(bào)(2014年1期)2014-02-28 22:21:28
