基于行為聲明的可信性測試方法與可信度計算研究①
2018-11-14 11:36:22于學軍
計算機系統應用 2018年11期
于學軍,肖 然
(北京工業大學 信息學部,北京 100124)
基于網絡的信息系統處在一個動態的開放環境中,人們可以通過網絡在任何時間任何地點進行信息的交互,這比傳統的信息系統在計算能力上有了顯著的提升,但與此同時,信息系統的可信性問題也成為當今互聯網時代面臨的重大挑戰[1–3].
本研究基于判定軟件行為可信的“言行一致”的思想.所謂“言行一致”思想指: “言”是指軟件的預期行為,“行”是指軟件的實際行為,“一致”指的是驗證系統“言”與“行”的一致性.“言行一致”思想體現了行為與預期的關系,符合目前學界對可信的定義[4].這也是上文所提出的本文依賴的可信標準.
行為聲明是指應用軟件針對自身行為進行描述的集合.在該集合中,行為包括軟件的所有功能性行為、可能侵犯用戶自身權利的行為、可能影響應用軟件正常運行的行為和可能引發無法預期的軟硬件環境配置改變的行為[4].
本篇論文的重點在于兩個方面,第一是探究適用于通用環境下的的基于行為聲明可信性測試方法.在基于行為聲明的測試方法中,本人提出了在軟件全生命周期下運用行為聲明保障軟件可信性的模型[4],得出了行為聲明在軟件開發過程中各個階段的作用.呂海庚提出在全生命周期可信過程保障模型的支撐下的Web 應用軟件的可信屬性.在此基礎上,提出了Web應用軟件可信性驗證模型,并在此驗證模型的支撐下,提出了軟件可信性測試方法[5].車樂林在針對行為聲明的可信測試研究中,基于移動端軟件的特點提出可信行為聲明的通用結構,將研究得出的可信行為聲明融入到應用的測試過程中,得出了基于可信行為聲明的移動應用測試模型和測試流程[6].劉妙晨以可信行為聲明的內容結構和 REST 應用軟件的結構特征及可信特征為基礎,提出基于行為聲明的 REST 風格Web 應用可信性測試方法[7].在這些研究中,都是側重于針對各軟件環境下的特點對行為聲明進行定義之后提出測試標準模型.在基于行為聲明的測試方法中,還未有對如獲取軟件運行的實際行為,如何感知到軟件行為的動作路徑的研究,本文將側重于此.動作路徑在本文是指:軟件發生行為時執行的一系列程序設定的集合.
第二個研究重點是提出可信度的計算方法,可信度在本文是指:軟件實際行為與行為聲明中行為的相似度.在可信度量方面,已有眾多學者提出自己的方法.韓冬冬等人提出了采用靜態hash度量值,動態行為特征值作為評判標準的的應用軟件可信性混合度量的設計方法[8].熊剛等人提出采用多屬性決策建模方法,設計了一種策略來建立可信指標樹,這種方法是在按需驅動的基礎上,采用動態的方法來完成.并為了減少主管權重計算的不確定性利用了模糊層次分析法,為了提高賦權操作的公平性采用主客觀權重相結合的方式.在可信評價階段,他們主要采用了指標數據效用轉換方法.可信屬性向量構造和向量減的相對近似度計算[9].趙玉潔等人運用因子分析法構建了針對Web軟件的可信性評價指標體系.在可信指標的權重計算上運用結構熵值法.為構造專家評價信息的模糊評價矩陣運用了改進的證據合成方法.在軟件可信性等級評價上運用了置信度識別準則[10].綦磊升等人提出了基于模糊層次分析法的可信評估方法,即將層次分析法和模糊綜合評判法相結合,克服了傳統層次分析法中人作為個體的主觀判斷會對結果有很大影響的缺點,使評估更加趨于合理[11].在以上研究中,選取行為特征值,專家評判和層次模糊分析法等的運用都側重于軟件行為的表現,提出相應的可信指標加以判斷,存在一定的主觀性.本文將側重于軟件行為的發生過程,針對軟件行為發生時的事件類型以及運行參數,運用K-means聚類方法提出一種分析模型,結合行為聲明對軟件行為是否可信進行判定.以及運用模型甄別相似行為是否可信.
1 測試方法的設計
本方法依據“言行一致”為判斷標準[12],通過將監控到的軟件實際行為與行為聲明作比較,判斷行為是否可信.方法的關鍵在于對軟件實際行為的監控,以及可信度的計算.
1.1 制定行為聲明
行為聲明由一系列軟件行為構成,那么在本節將闡述本文對軟件行為的表示方法.本實驗采用JSON對軟件行為進行表示,易于人閱讀和編寫.軟件行為可以看做完成一系列程序設定的過程.本方法中將程序設定分為三種類型事件,如圖1所示,根據是否可交互劃分為點擊事件與其他事件,在其他事件中再根據是否可見將事件劃分成可見的曝光事件與不可見的環境事件.
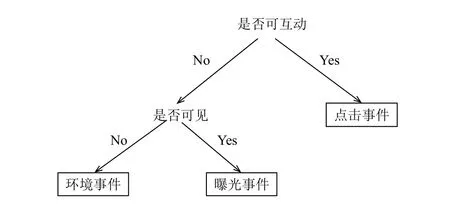
圖1 事件劃分
點擊事件表示當軟件應用展現給用戶的UI元素可點擊且點擊之后有反饋動作時觸發,比如一個按鈕被點擊會觸發點擊埋點上報按鈕的點擊事件.數據格式會攜帶觸發參數,預期關聯事件信息等.
曝光事件表示軟件應用展示給用戶的UI元素出現在界面上時觸發,比如一個圖片展示給用戶時會觸發曝光埋點上爆圖片的曝光事件.數據格式會攜帶一組曝光參數.
環境事件表示軟件應用發生不可見的動作時會觸發,比如調用系統的喇叭來播放音樂會觸發環境埋點的聲卡環境事件.數據格式會攜帶當前事件發生時的系統參數,比如內存使用率,網絡數據包等等.
一個“行為”即行為聲明,則是由以上三種類型的事件組成.可用如圖2中的結構表示.

圖2 行為聲明中“行為”的結構示意圖
1.2 融入測試工具
在軟件開發階段接入可信測試工具,如圖3所示是以Linux為例的測試包結構.通用結構包括三部分:接口模塊,埋點模塊,校驗模塊.接口模塊主要作用是向下封裝,向上提供入口.埋點模塊主要作用是在行為發生,在軟件的反饋動作路徑上會觸發埋點上報信息給服務端,服務端會對事件進行可信判定.校驗模塊主要作用是校驗軟件及模塊本身是否被篡改.
1.3 埋點上報
埋點在指安插在軟件動作路徑中的標記工具.每當軟件按照程序設定發生行為時,特定位置埋點就會被觸發,按照規則將該程序事件信息上報給判定系統[13].埋點模塊的目的,記錄軟件行為引發的埋點事件,從而做到動作路徑有跡可循,為之后可信判定做依據.
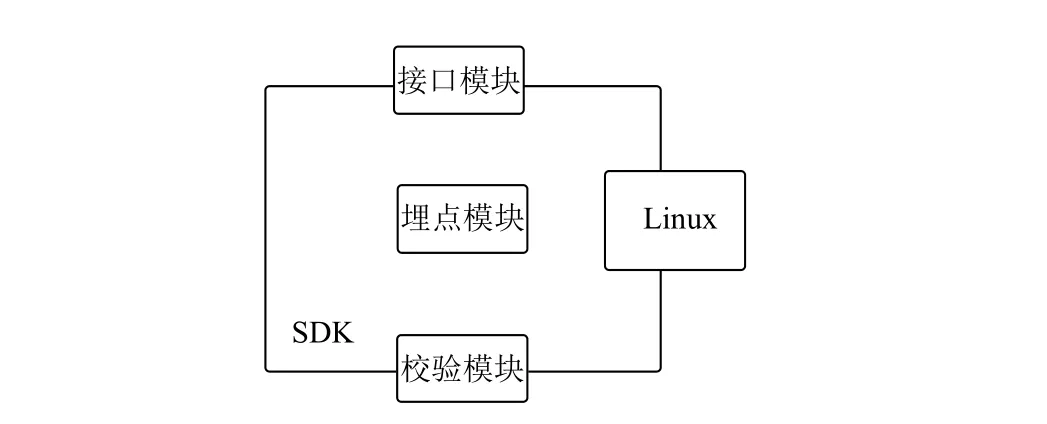
圖3 SDK示意圖
在1.1節中的行為聲明Action中,已經提到了關于程序事件的三種類型,即點擊事件、曝光事件和環境事件.如圖4中所示.
當一個行為發生時埋點的工作流程如圖5所示.首先,埋點模塊根據關鍵字event-Id去請求埋點數據源已獲得埋點的詳細.然后,埋點模塊獲得到埋點的詳細信息,根據埋點的類型去判斷對關聯標識的操作,如果是點擊事件則根據Unix 時間戳與event-Id組合生成唯一的關聯標識,并攜帶.如果是曝光事件或者環境事件則會直接讀取關聯標識,并攜帶.最后,埋點模塊將處理過的數據上傳給服務端.
1.4 埋點數據的解析
如圖6所示,服務端向客戶端提供三個接口用來分別接受三種不同類型的埋點事件,客戶端的埋點模塊會自動識別事件類型然后將數據發到指定接口.服務端在接收到數據后會按照以下流程對數據進行解析.
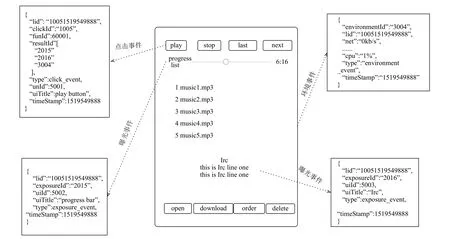
圖4 埋點樣例
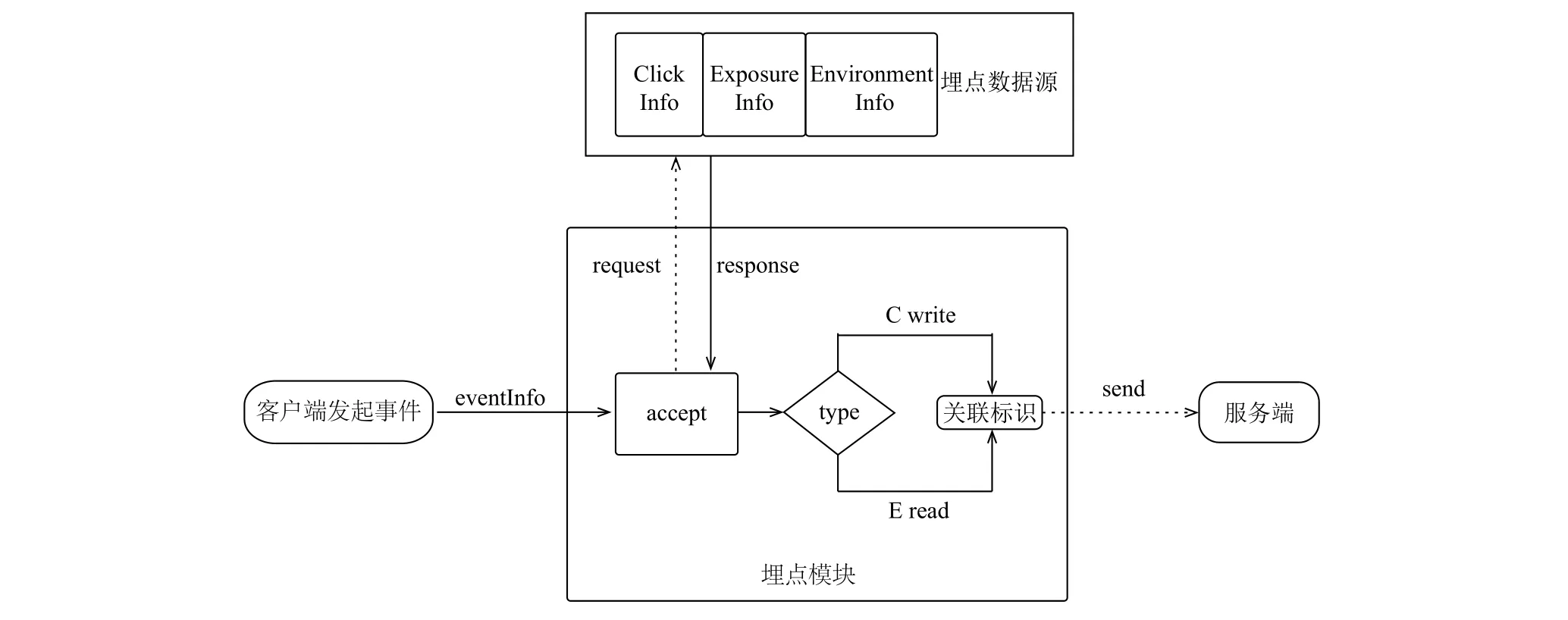
圖5 埋點工作流程
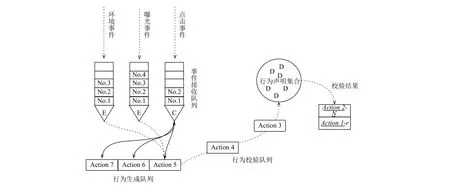
圖6 服務端解析數據示意圖
首先,將接收到的JSON格式數據解析成事件對象,之后放入事件隊列.事件隊列是服務端用來存放埋點事件的容器.三個事件隊列用來存放對應的三種埋點事件,在每個隊列中會根據事件到達先后順序排序,保證先進先出的相對順序.
然后,因點擊事件作為動作路徑開始標志,也就是行為開始的標志,點擊事件隊列會最先進行出隊操作.每當有點擊事件出隊時,就代表有一個行為已經發生.那么行為生成隊列會生成一個Action對象用來承載該行為.剛剛出隊的點擊事件會被該Action對象持有,點擊事件所攜帶的關聯標識會被賦予給該行為對象Action,供后續攜帶相同關聯標識的曝光事件和環境事件找到該Action對象并被其持有.同時點擊事件中的result關鍵字也將作為event匹配到所在Action對象的依據.所謂行為生成隊列換句話說,就是承載這些Action對象的集合.
之后,曝光事件和環境事件會像點擊事件一樣,進入對應的事件隊列,然后出隊,然后根據自身攜帶的關聯標識找到對應的Action對象,并被持有.這樣就完成了一個Action中埋點事件的組合.這樣完整的Action對象就可以代表一條動作路徑,代表一個軟件行為了.
最后,服務端會讀取行為聲明文件,將行為聲明解析成聲明隊列,即聲明集合.等待行為隊列組合完畢后,依次將行為隊列出隊與聲明比對,即通過埋點獲得的Action對象與行為聲明對象Declare對象比對.以此,來判定行為是否可信.
2 可信度計算的方法
2.1 可信判定指標
本方法提出將可信判定指標劃分為顯性指標和隱性指標.
顯性指標是指軟件動作路徑的匹配,即Action中的三種埋點事件的觸發是完全與行為聲明中一致的.舉例說明,如圖7(b)所示為行為聲明中對點擊按鈕播放網絡音樂的行為的JSON表示.可見,在“言”的Action中,點擊事件為動作路徑的開始,根據click中的resultID可知,預期將會觸發eventID為“2001”,“2002”,“3001”的埋點 (如圖 7(b)中右側虛線所示).顯性指標就是比較實驗監控到的Action中的event是否與行為聲明中Action的event一致.
其次,隱性指標指環境事件的系統相關參數,比如程序對內存的使用率,對網絡的使用情況等.設置隱性指標的目的在于檢測程序是否存在欺瞞上報,即在行為的動作路徑中不觸發埋點,或者發生的實際行為與埋點不符等.為了監控這類行為,在客戶端的測試模塊中,會在事件上報時自動填充的系統環境數據,以此來達到檢測異常的目的.如圖7中虛線標記的就是隱性指標.
可信判定的標準將從顯性指標無誤與隱性指標正常兩個方面制定.行為要首先滿足顯性指標無誤,再滿足隱性指標在正常范圍內,才會判定為可信行為.如圖7中的實線箭頭所示,比較“言”與“行”中的事件是否一致.完全一致則進行隱性指標的判斷,將在下一節闡述隱性指標的計算方法.若不一致,則當即終止判定,該 行為不可信.如圖8所示.
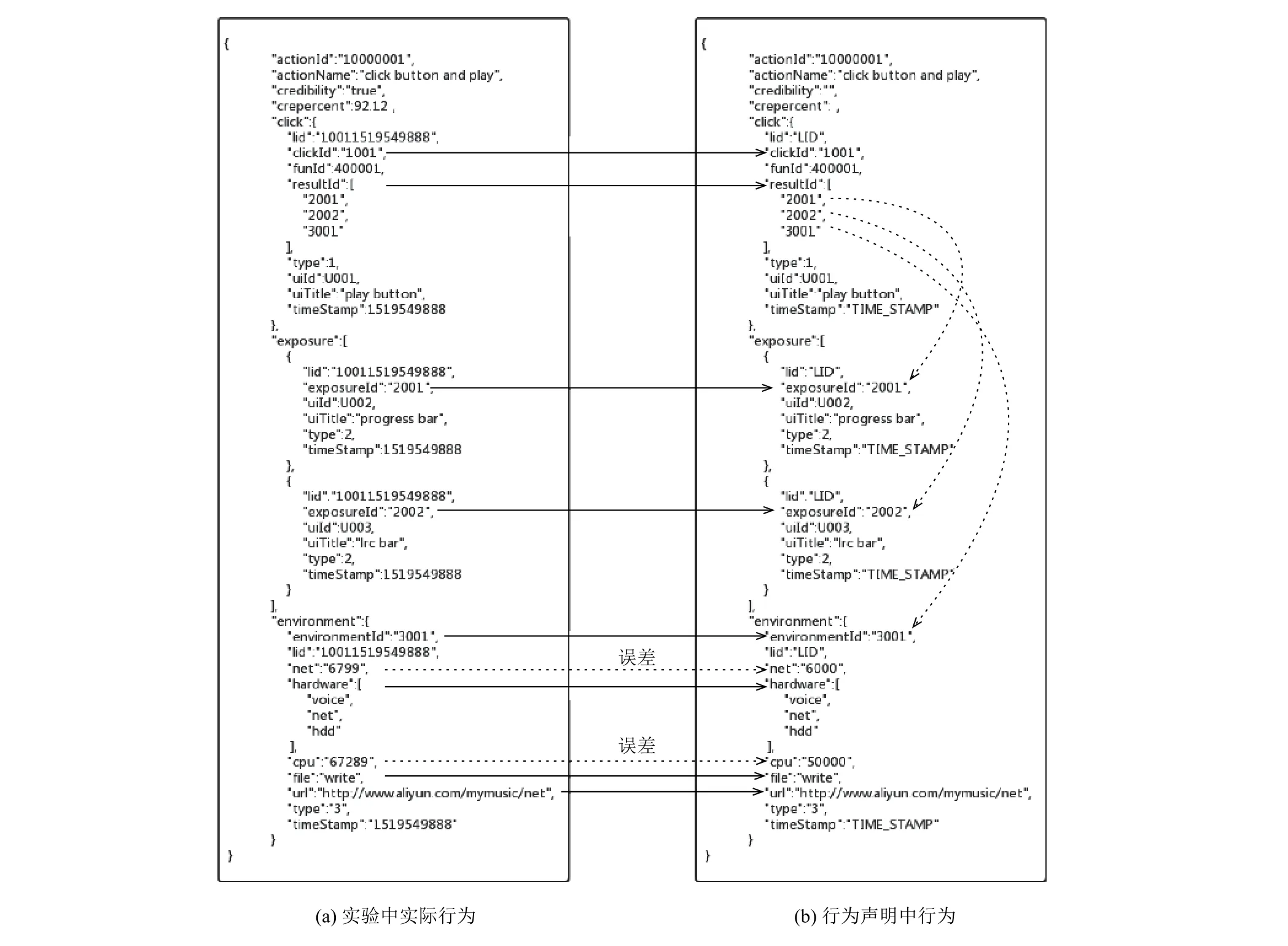
圖7 可信判定標準示意圖
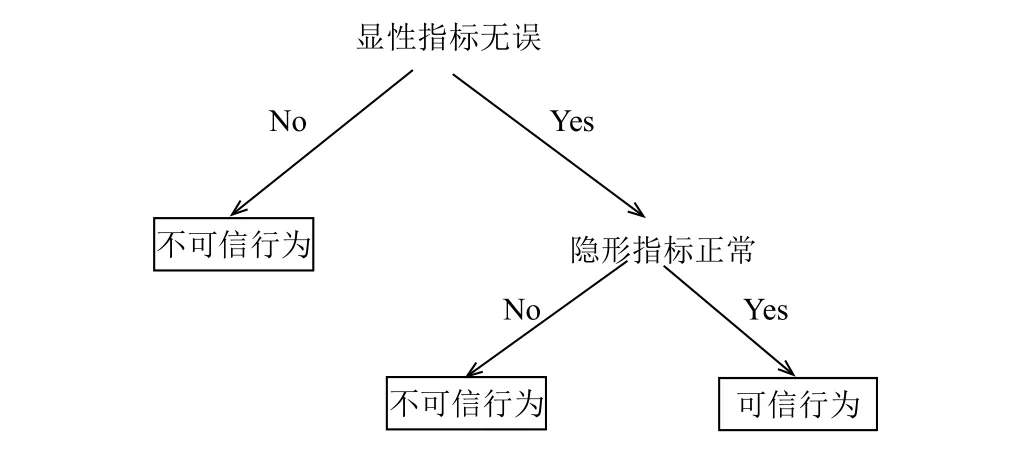
圖8 判定流程示意圖
2.2 隱性指標模型與可信度計算
隱性指標是隨環境事件(環境事件)上報的系統相關參數,目的是用于監控實驗程序發生行為時,對系統環境的使用度.以此對軟件行為的可信判定做輔助測評.理論上同一軟件行為對系統的使用度應該是相同的,但在實際環境中因軟件自身的操作或系統環境的實時性會造成誤差.隱性指標模型是抽象出來的解析隱性指標數據的方法,目的就是確定誤差范圍,以及根據誤差范圍對測試樣本可信度進行計算.
隱性指標模型運用K-means算法,并加入可信度計算規則.模型構造的流程如下:
(1) 通過對樣本行為進行多次實驗,得到樣本行為的隱性指標數據集合,下文稱之為樣本集.
(2) 在樣本集中根據歐式距離就算樣本集的中心質點O'.
(3) 以O'為中心去除樣本集中的噪點,之后再次計算得樣本中心質點O.
(4) 以O為中心,樣本集中最遠樣本數據的歐式距離為半徑的范圍即是樣本行為的隱性指標模型.
實驗中選取程序對內存的使用量和網絡訪問流量這兩個參數作為隱性指標模型的特征值,構造的二維模型示意圖如圖9(a)所示.可見,圓O是樣本行為的數據集,樣本數據集中在圓心附近,圓外的樣本數據為誤差范圍較大的噪點.
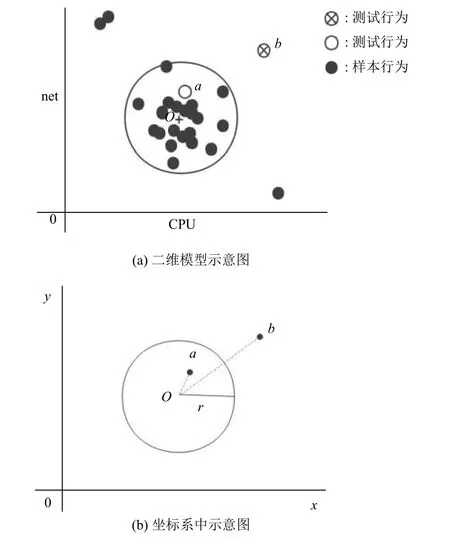
圖9 可信度計算示意圖
在隱性指標模型中,可見,可信行為樣本數據點都集中在圓心O附近.若我們用t(a,b)表示點b在以a為質心的模型中的可信度.那么我們規定: 質心O上的數據點可信度t(o,o)為100.00%; 可信度隨距離圓心的距離增大而減小; 以模型邊緣距離R為可信閾值,邊緣上的數據點可信度表示為t(o,r),該閾值可動態設定.模型內的數據可信度為高度可信,外部的數據點可信度為弱度可信,小于0.00%的為不可信.如圖7(a)中,測試行為數據點a在圓內,為高度可信; 測試行為數據點b在圓外且接近2R,則可信度接近0.00%為弱度可信.
可信度計算方法由顯性因子f與隱性指標模型數學抽象而來.顯性因子是表示顯性指標是否無誤,1代表滿足顯性指標要求,0代表不滿足顯性指標要求,顯性因子具有決定性作用.
隱形指標模型數學抽象以二維數據為例,如圖9(b)所示.在圖中以O為圓心,r為半徑的圓是樣本行為的數據范圍.采用歐式距離表示數據點間距離,如下表示16個參數特征下O點與x點的距離是:
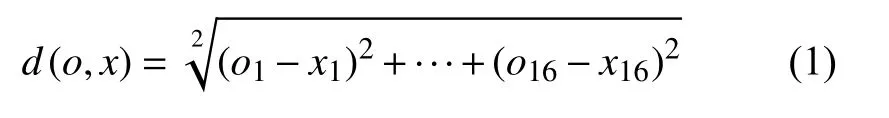
已知圓心O的可信度為t(o,o),規定圓邊緣r的可信度為t(o,r).若求任意數據點的可信度,可由單位距離下的可信度一致推導.如下所示:
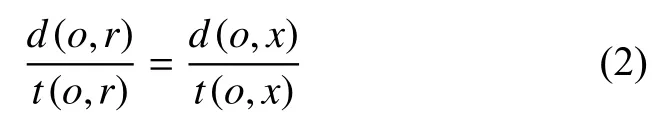
進一步得:
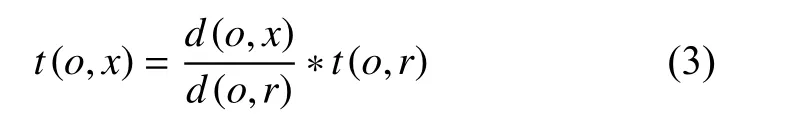
引入f表示具有決定作用的顯性因子以及質心的最高可信度t(o,o).那么點x的可信度t(o,x)就可表示為:
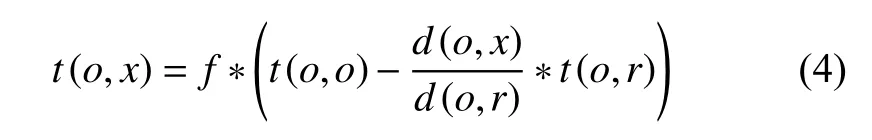
2.3 相似行為可信甄別
相似行為定義為: 在軟件行為的動作路徑中,會觸發相同的環境事件(環境事件)的兩個行為為相似行為.即兩個行為的動作路徑中,或者觸發的點擊事件和曝光事件不同,但都以相同的環境事件.比如圖10所示,圖10(a)表示點擊按鈕播放播放網絡音樂的JSON.圖10(b)表示音樂列表自動聯播到網絡音樂的JSON.圖10(a)和圖10(b)表示不同的行為,但是都會觸發environment-Id為3001的播放音樂環境事件.此環境事件中包括網絡流量,硬件支持,內存使用,文件讀寫,網絡訪問域名等參數.兩個環境事件的除了隱形指標有波動外,其余參數均相同.這樣這兩個行為就為相似行為.
相似行為的可信甄別是把相同環境事件下的隱性指標相似作為依據,運用隱性指標模型對相似行為作出可信判斷,看行為中是否存在期滿動作致使隱性指標異常情況.比如,在播放音樂的同時,偷偷將本地文件上傳但未上報該事件.這樣會使網絡流量增加,內存占比增高.通過埋點模塊可以監控到隱性指標的波動,由此甄別出相似行為是否可信.
如圖11所示,相同的環境事件(環境事件)D,E,F分別是隸屬于三個不同行為Action.可知這三個行為因環境事件相同而是相似行為.引入隱性指標模型后,D的數據集與E的數據集大部分重合,而F的數據集只有邊緣重合.則可判定F所屬的行為有很大概率存在期滿動作未上報.
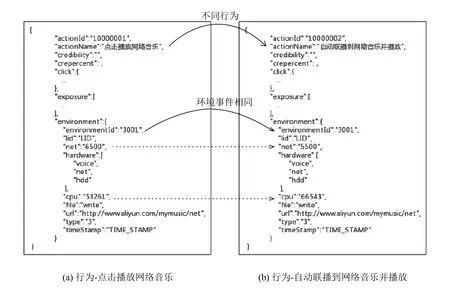
圖10 相似行為
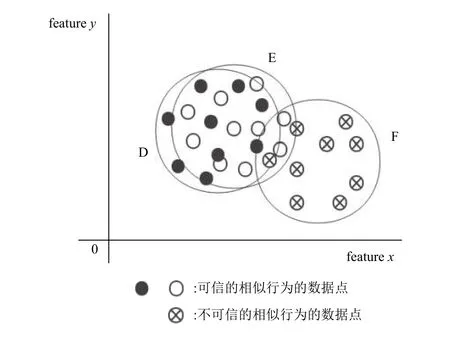
圖11 事件甄別示意圖
在相似行為的可信度計算上,其實是比較A,B兩個行為的隱性指標數據集的重合度.依據單個測試數據點對樣本數據集可信度,我們將問題轉化為B中的每一個數據點對A數據集的可信度之和的平均數.這樣就得到了A,B兩個相似行為的可信度.那么可以表示為:
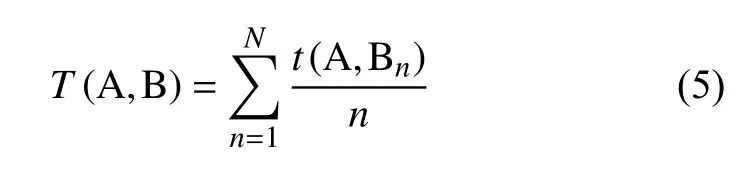
若A為可信行為,那么T(A,B)即為B相對于A的可信度.以此計算,達到相似行為甄別的效果.
3 驗證方法可行性
3.1 可信度計算分析
實驗案例的客戶端選取在Linux中運行實驗程序音樂播放器來完成,選取8個具有代表性的行為,分別是播放音樂,暫停,切換歌曲,打開文件和文件夾,拖動進度條以及下載歌曲.實驗程序涉及文件讀取,硬件調用,網絡訪問,內存占用等與系統相關的交互操作,已達到實驗的功能性覆蓋標準.對三種事件類型覆蓋全面,涉及的環境事件中的參數全面,且有相似行為,可供相似行為甄別分析.服務端選取Spring MVC架構的Java服務器支持,可以提供穩定的接口支持,訪問的并發處理,以及數據解析能力.
首先利用樣本行為制造可信行為的隱性指標模型.其次,對可信行為進行重復實驗,查看利用本方法得到的可信度是否準確[14].接著,在可信行為中加入其它行為,且隱瞞上報,由此制造出對應的8組不可信行為.最后對8組不可信行為進行重復實驗,查看可信度是否準確.在此展示選取的5次實驗的結果,如表1所示.
由此表得出,對環境事件影響較小的行為,在可信度計算中的可信度都達到了0.9以上.對環境事件波動較大的下載行為,可信度在0.68~0.90之間.
在對不可信行為的構造中,有兩種情形.第一,對動作路徑的破壞,即發生非預期行為,觸發非預期埋點事件,造成顯性指標的異常.根據上文定義的可信度計算公式,這一種情況會直接判定可信度為0.第二,是對環境事件的破壞,即發生期滿上報的行為,導致環境參數異常,造成隱形指標模型計算可信度下降.不可信行為的5組數據如表2所示,其中Action的括號里內容為對行為的異常處理.
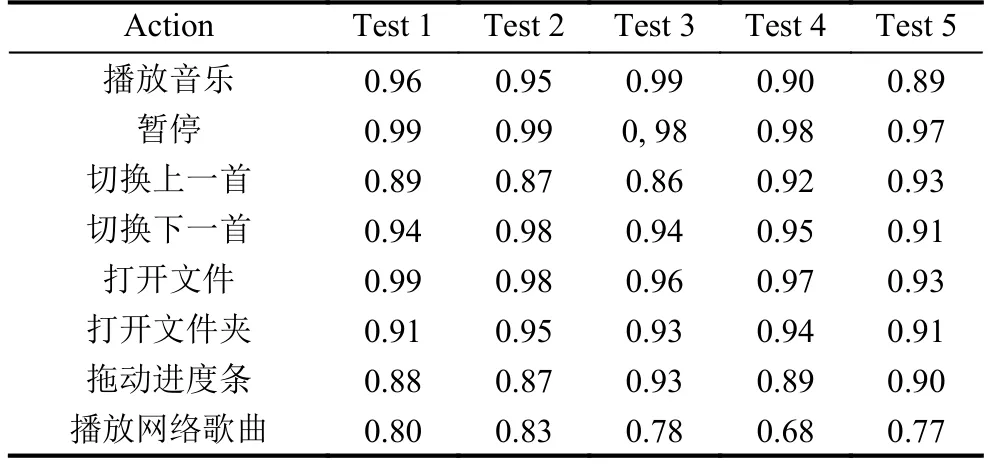
表1 實驗中可信行為的5組可信度
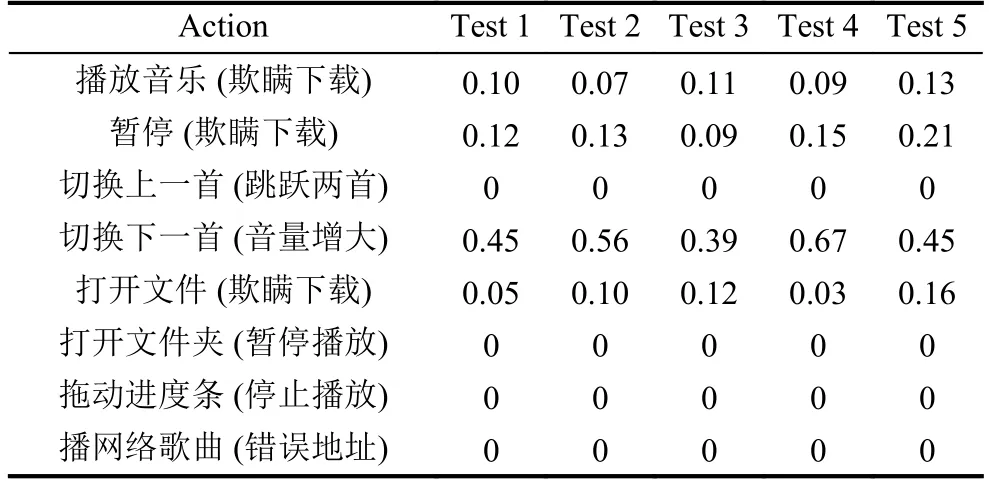
表2 實驗中不可信行為的5組可信度
由表2中數據可以看出,對顯現指標為達到標準的行為,測試方法能準確的判定為可信度0.在欺瞞行為的可信度計算上,對環境事件影響較大的行為,可信度在0.2以下.對環境事件影響較小的事件,可信度在0.45~0.67之間.
3.2 相似行為甄別分析
在相似行為的分析上選取播放音樂(行為A),切換上一首(B)和切換下一首(C)三個行為做比對,為了增加系統參數,我們默認三種行為均會連接網絡下載歌詞以及歌曲.此三個行為都會觸發事件ID為3001的播放環境事件.
可信的相似行為的驗證上,選取對三個行為分別進行多次試驗,構造出三個不同的隱性指標模型,進而再利用本文提出的相似度計算方法得出相似行為的可信度.
在參數上的選擇上,我們選取UI幀率,UI響應時間,點擊響應時間,硬件響應時間,文件寫入量,讀取量,當前內存使用量,交換區總量,CPU用戶使用率,系統使用率,當前等待率,當前錯誤率,當前空閑率,接收的總包裹數,發送的總包裹數,連接時長,這16個指標作為本次實驗的隱性指標.
分別對三種行為進行50次實驗.以行為A為例構造的數據矩陣示意圖如圖12所示.
將A行為的數據矩陣Matix錄入K-means收斂程序.根據上文提出的方案,降噪處理后,依據中心質點M.根據公式(4)和公式(5),已知可信中心點與可信半徑r,將B行為逐條錄入計算可信度取平均值,即得到B對A的可信相似度為0.835,相對C(切換上一首)相似度為0.811.對C行為做欺瞞處理(網絡下載歌曲)后,用同樣方式測得相似度為0.231.有明顯的數據波動,由此說明相似行為的可信判斷是具有可行性的.
4 結論
本論文中可信測試方法重點解決了兩個方面的問題,第一是在軟件運行的過程中通過埋點感知軟件行為的動作路徑.第二是將埋點信息重組軟件行為機制,依據行為聲明做比較,提出針對隱形指標的的K-means可信度的計算模型,并應用于相似行為的可信甄別.在計算模型的應用上,環境事件波動越大準確度越高,在對環境事件影響小的行為上,準確度有待提高.這也是后續值得改進的地方.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
光學精密工程(2016年6期)2016-11-07 09:07:19
