網(wǎng)頁去噪算法研究與應用
2018-11-08 03:47:26孫竹君
信息記錄材料 2018年11期
孫竹君
(中北大學信息商務學院 山西 太原 030000)
1 引言
伴隨著因特網(wǎng)的快速發(fā)展、網(wǎng)絡(luò)日益廣泛的應用與社會信息化的大步推進,給自然語言處理的研究帶來新的機遇和挑戰(zhàn)。Web已經(jīng)成為獲取信息的主要平臺,而恰恰日前的網(wǎng)站目錄主要是以人工識別歸類或電腦自動區(qū)分歸類來完成,這種方式下文字檔案的區(qū)分歸類、歸類體系等很多方面有很多不便于人工識別搜索信息的困難存在。同時,在瀏覽Web上的網(wǎng)頁時,會出現(xiàn)與文檔主要內(nèi)容沒有關(guān)聯(lián)的“導航信息”、廣告消息欄目等內(nèi)容,這就可以認為做“噪音”。 網(wǎng)絡(luò)頁面上的“噪音”不單單制約著以網(wǎng)絡(luò)頁面內(nèi)容信息為基礎(chǔ)的Web應用系統(tǒng)的應用開發(fā),而且也帶給基于網(wǎng)頁超鏈接指向應用系統(tǒng)很多難題。因此,如何高效準確地從WWW中獲取有用信息,如何迅捷精準地查找并去除網(wǎng)絡(luò)頁面上的噪音信息就成了提高Web應用程序整合處置結(jié)果精確性的一類重要技術(shù),也是當前信息檢索的一項值得研究的工作。
2 開展網(wǎng)頁去噪研究的重要性
在網(wǎng)頁的處理中應用自然語言處理技術(shù),把網(wǎng)絡(luò)中的信息進行深入、細致的處理,如何快捷準確的從大量的信息資源中提取所用的各種各樣知識,獲取人們需要的有效信息,已經(jīng)成為很多專業(yè)人員的研究對象和目標。根據(jù)所用用途不同,可以把web中的內(nèi)容分為兩種,一種是瀏覽器所用的標記信息,另一類是為使用者提供的閱讀信息,對于后一類需要處理自然語言。所以,去掉網(wǎng)頁中的標記信息就成了運用自然語言處理技術(shù)處理網(wǎng)頁中的內(nèi)容的先決條件。自然語言處理技術(shù)適用于網(wǎng)頁正文,所以,怎樣查找并抽取網(wǎng)絡(luò)頁面上的正文內(nèi)容,進而把它轉(zhuǎn)化為文字文本的技術(shù)是連接自然語言處理技術(shù)和網(wǎng)絡(luò)頁面內(nèi)容的紐帶。
3 關(guān)于網(wǎng)頁去噪的算法研究
基于現(xiàn)有技術(shù),可行的網(wǎng)頁去噪技術(shù)大致分為以下三種。
3.1 基于分塊的網(wǎng)頁去噪算法。在互聯(lián)網(wǎng)信息檢索方面,一般采用兩方面的指標來考評一個Web的檢索系統(tǒng),即完成檢索所用時間的長短和反饋檢索的相關(guān)度,如果噪音去除的技術(shù)不夠成熟,不能有效地將噪音刪除,索引系統(tǒng)就會建立一個噪音目錄。從而使得資源樹的一些節(jié)點出現(xiàn)噪音索引,當完成搜索結(jié)果后,反饋給用戶的內(nèi)容相應也會有噪音內(nèi)容。降低了搜索效率,浪費了寶貴的時間。
基于分塊的網(wǎng)頁去噪算法,第一步是按照table標簽,把整個網(wǎng)頁進行分塊處理;第二步是進行對數(shù)據(jù)的統(tǒng)計處理,運用一個模板對生成一個網(wǎng)頁集,然后對網(wǎng)頁集的內(nèi)容數(shù)據(jù)進行統(tǒng)計,出現(xiàn)次數(shù)較多且內(nèi)容松散的一般是廣告等等的噪音,需要濾除。大量的研究表明此方法是可行的。
3.2 基于統(tǒng)計的網(wǎng)頁正文信息的網(wǎng)頁去噪算法。基于統(tǒng)計的網(wǎng)頁正文信息的網(wǎng)頁去噪算法應用到文摘系統(tǒng)上,可以把網(wǎng)絡(luò)頁面進行文摘處理;應用到文本處理系統(tǒng)中,可以對網(wǎng)頁進行自動化的處理和分類。照此,對網(wǎng)絡(luò)也沒的整理處置和對純文本的處置相同,擴大了之前技術(shù)的應用范圍。所以,研究網(wǎng)絡(luò)頁面內(nèi)容提取技術(shù)對于把自然語言技術(shù)的應用范圍拓展到網(wǎng)絡(luò)頁面處理有著非常重大的意義。
3.3 基于網(wǎng)頁框架和規(guī)則的網(wǎng)頁去噪算法。網(wǎng)絡(luò)頁面中的噪音定義其實是該網(wǎng)絡(luò)頁面里面與本頁面的重要內(nèi)容不存在直接關(guān)系的區(qū)域及具體項目。我們搜索查看的網(wǎng)頁大多遵循下圖的方式進行對網(wǎng)頁排版,不僅符合用戶的瀏覽習慣,而且也是設(shè)計者的用意。同時,網(wǎng)絡(luò)噪音部分(例如作者、廣告、版權(quán)信息等)大多是存在于那些非主要的地方和比較細長的方式地方,這就使得我們在編輯算法是可以輕易的去除網(wǎng)絡(luò)噪音內(nèi)容。如圖1顯示。
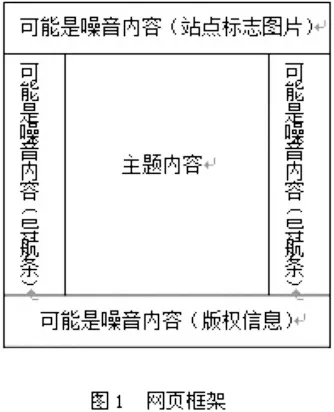
實現(xiàn)此算法依據(jù)的規(guī)則:
依據(jù)通常網(wǎng)頁的格式和HTML文檔,基本匯總出以下這樣啟發(fā)式的規(guī)則:
(1)標簽 (2)標簽 (3)對于多層嵌套的標簽 (4)對于沒有標簽 以上幾種網(wǎng)頁去噪的算法,可普遍應用于針對當前互聯(lián)網(wǎng)信息的處理,這些算法可以較為高效精準地從網(wǎng)頁中篩選凝練出主要內(nèi)容,同時將所謂的噪音除去濾掉,并且過濾這樣噪音的精準率比較高。搜索引擎中應用上述算法,可很大程度提升搜索引擎的查找搜索的速度、減少差搜數(shù)量和提高檢索的精準度和成功率;在分類上運用這樣算法,便可以將主要內(nèi)容從網(wǎng)絡(luò)頁面中的提煉出來,并文本存儲到對應文檔中,這樣的話就能夠很快速的使用現(xiàn)有的分類措施實現(xiàn)自動分類處理的效果。不過,以上算法局限性還是不同程度存在的,例如它只能處理有明顯的主題正文特征的網(wǎng)頁,就像新聞類的網(wǎng)頁等等,但是在處置那些綜合性內(nèi)容較多的頁面,或者頁面中的重點內(nèi)容不容易區(qū)分的,例如重點內(nèi)容就是一句話的描述,或是圖片信息作為主題內(nèi)容的等等頁面,它處理的能力不帶為或可以說無法識別處理,因為閾值這種算法里的重要依據(jù)是通過不間斷地實驗,不斷的累積,從中得出的,所以說算法閾值的合理性仍然需要在今后的試驗中進一步得出結(jié)論。4 去噪算法應用方面
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00保健醫(yī)苑(2022年1期)2022-08-30 08:39:14科學大眾(2022年11期)2022-06-21 09:20:52中華手工(2017年2期)2017-06-06 23:00:31臺聲(2016年2期)2016-09-16 01:06:53中外會展(2014年4期)2014-11-27 07:46:46電腦愛好者(2011年11期)2011-06-22 08:20:18河北軟件職業(yè)技術(shù)學院學報(2010年3期)2010-06-06 07:18:42祝您健康(1987年3期)1987-12-30 09:52:32祝您健康(1987年2期)1987-12-30 09:52:28
