SPA-PLS和GA-PLS算法預測胡楊葉片含水量的對比
2018-11-08 06:05:40白鐵成喻彩麗張楠楠王莎莎
江蘇農業科學 2018年19期
關鍵詞:模型
王 濤, 白鐵成, 喻彩麗, 張楠楠, 王莎莎
(1.塔里木大學信息工程學院/新疆南疆農業信息化研究中心,新疆阿拉爾 843300; 2.西北大學現代教育技術中心,陜西西安 710127)
塔里木河流域的胡楊林對阻擋塔克拉瑪干沙漠的風沙侵襲、維護區域生態平衡和保障綠洲農業起著重要作用。但近年來由于受干旱和蟲害的影響,沿河兩岸天然植被大幅削減和破壞,我國塔里木河流域的珍貴樹種胡楊面臨著生存危機[1],因此須要對胡楊林的健康狀況進行及時有效的監測,胡楊葉片水分狀況為胡楊干旱脅迫提供了指示作用,對胡楊林實施有效的保護具有重要的現實意義。
近紅外光譜技術是一種高效率、穩定、低成本的檢測方法。近年來,使用近紅外方法對農產品品質進行測定主要以漫反射和透射光譜檢測為主,包括蔬菜、小麥、玉米、水稻等主要農產品中水分、淀粉、蛋白質等成分含量的測定[2-6]。方美紅等利用高光譜數據反演作物葉片含水量,采用小波分析方法,綜合利用多波段信息的作物葉片含水量反演模型,提高了預測精度[7]。劉明博等基于連續投影算法結合主成分回歸與偏最小二乘法(partial least squares regression,PLS)預測水稻葉片含氮量,證明了連續投影算法進行有效波長的選取是可行的[8]。Li等基于遺傳算法結合偏最小二乘法在植物水分近紅外光譜分析模型中進行譜區選擇,優化了預測模型,增強了模型的穩定性[9]。王加華等采用遺傳算法用于PLS建立西洋梨糖度校正模型前的數據優化篩選是可行的,有效提高測量精度,減少建模變量[10]。前人利用各種光譜預處理方法,主要包括多元散射校正,矢量歸一化、一階導數、二階導數等[11-13],分析了農產品關鍵成分與光譜的關系,證實了使用連續投影算法[14-16]與遺傳算法[17-18]選取特征波長的可行性,而采用近紅外波段的光譜信息檢測胡楊葉片含水量研究鮮有報道。
本試驗選用SavitZky-Golay一階導數對樣本的原始光譜進行預處理,然后分別使用連續投影算法(successive projection algorithm,SPA)和遺傳算法(genetic algorithm,GA)[19]篩選特征波長,并結合偏最小二乘法[20]建立胡楊葉片含水量光譜預測模型,通過試驗驗證,該方法有效地剔除了噪聲的影響,增加了特征波長的選擇能力,提高了胡楊葉片含水量估測精度,從而為基于高光譜技術檢測胡楊葉片含水量提供依據。
1 材料與方法
1.1 光譜采集
試驗采用Zolix Gaia Sorter近紅外成像高光譜儀,光譜測定范圍900~1 700 nm(實際測量到1 750 nm),光譜分辨率 5 nm,光譜采樣點4 nm,共256個波段。樣本在室內20~25 ℃ 環境下進行掃描,獲取一維影像和光譜信息,通過自帶軟件獲取每張葉片的平均光譜值,每個樣本數據測量5次取平均值,共采集100個樣本,表1是根據Kennard-Stone(K-S)算法[21]挑選出30份胡楊樣品作為預測集,剩下的70份樣品作為定標集。葉片水分采用烘干法進行測量,按如下公式計算:

1.2 光譜變量選擇與建模方法
1.2.1 SPA-PLS方法 使用SPA-PLS方法進行特征波長選取和建立預測模型,其算法分為4個階段:第一階段,篩選出共線性最小的若干組備選波長變量子集。第二階段,分別使用各子集中的變量建立多元線性回歸(MLR)模型,選出均方根誤差(RMSE)最小的子集。第三階段,對第二階段選出的子集進行逐步回歸建模,在盡量不損失預測準確度的前提下,得到1個變量數目較少的集合,該集合中的波長變量即是所選有效波長。第四階段,對第三階段中所選的有效波長作偏最小二乘法(PLS)的輸入變量,葉片含水量作為輸出變量進行預測模型的建立。SPA-PLS具體算法過程可參閱文獻[21-22]。

表1 胡楊葉片校正集和預測集含水量統計
1.2.2 GA-PLS方法 GA算法引入染色體概念,將變量視為染色體內的基因。通過隨機建立種群,利用適宜度(fitness)評價種群內個體優劣并繁衍后代,模擬自然界遺傳選擇規律,以優勝劣汰機制選擇更適宜的基因。另外,引入交叉機制模擬種群間的基因交叉,生成新的個體保證了尋優過程的收斂,同時引入變異機制以避免結果終止于局部最優。GA-PLS具體算法過程可參閱文獻[23-24]。
1.2.3 模型精度檢驗 采用預測集相關系數(r)、預測集均方根誤差(RMSEP)、預測精度(precision)以及交叉驗證均方根誤差(RMSPCV),對胡楊葉片含水量進行精度評價。模型r和Precision越高,RMSEP和RMSEP越小,則模型的預測性能越好。
2 結果與分析
2.1 光譜預處理
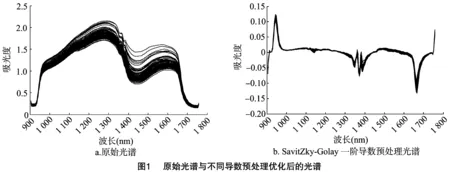
利用Zolix Gaia Sorter近紅外成像高光譜儀采集了100組胡楊葉片樣本的近紅外光譜吸收譜圖,結果發現,在1 280、1 420、1 620 nm附近有明顯的吸收峰、吸收谷存在,其中 1 420 nm 附近對應H—O鍵的1倍頻波長位置[16](圖1)。光譜儀中得到的光譜信號既包括對建模有用的光譜信息,又包含不利于建模的噪聲,會影響到特征波長的選取,因此對光譜信號進行消除噪聲等預處理是十分必要的。試驗中應用SavitZky-Golay一階導數對原始光譜進行預處理,圖1是原始光譜與一階導數預處理后的光譜圖。
2.2 特征波長選取
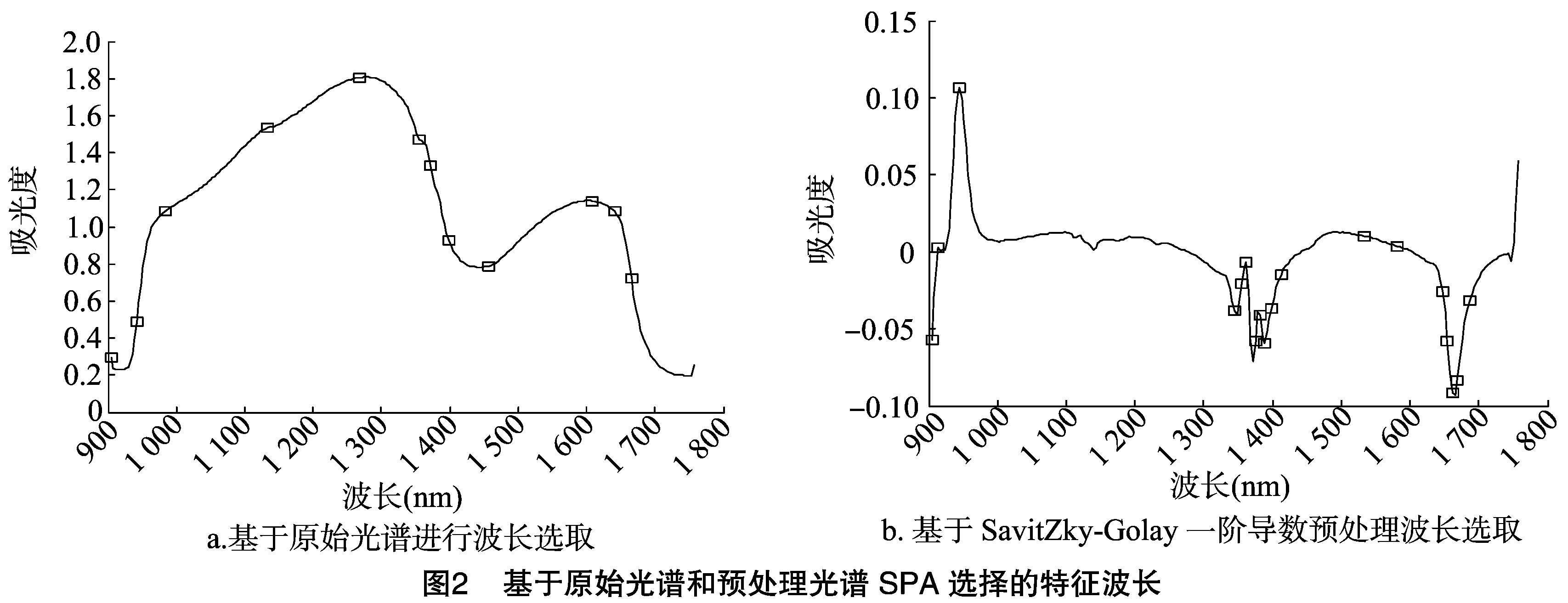
2.2.1 SPA選取特征波長 使用連續投影算法(SPA)分別對胡楊葉片的原始光譜與一階導數光譜數據的校正集與驗證集進行SPA特征波長選擇,SPA選擇變量數的最優區間是[2,50][15],其中基于原始光譜選擇的波長數為21個,且在1 280、1 460、1 620 nm附近集中了多數的波長,它們分布在平滑光譜中各個峰值的位置;基于SavitZky-Golay一階導數選擇的波長數為16個,且在1 360、1 650 nm附近集中了多數的波長,分布在一階導數譜中各個峰值的位置,無信息的平緩區域沒有波長被選取,這正是連續投影算法的優點(圖2)。
2.2.2 GA選取特征波長 分別對原始光譜和一階導數光譜使用GA方法進行特征波長的選取和對256個波段變量進行GA運算,設定遺傳算法迭代次數為100,種群大小為30個數據點,變異概率為0.01、遺傳概率為0.6,依變量被選中的頻率對變量排序。為了防止算法運行過程中隨機性對結果的影響,研究共進行5次運算,最后挑選出其中性能最好的模型所選用的頻率變量作為最佳變量。每次迭代過程中,波段特征變量(優勢基因)在所設定的競爭模式下保留。通過GA所選的特征波段主要集中在900~1 600 nm之間,并且在900~1 300 nm 之前特別集中(圖3)。這是由于GA算法在尋優路徑上的隨機性造成特征波段選擇數目的不確定性,即每次運行結果之間具有差異,甚至存在陷入局部最優的概率,所以基于每種預處理選擇的最佳變量數存在差異,并且存在陷入900~1 300 nm局部最優波段的可能。

2.3 模型的建立和預測
2.3.1 SPA-PLS模型建立與預測 通過SPA和PLS算法,分別對胡楊葉片原始光譜和一階導數光譜進行建模,將SPA算法提取的特征波長,作為PLS的輸入變量,葉片含水量作為輸出變量。結果發現,基于一階導數光譜與SPA算法提取的特征波長進行建模的精度、相關性均明顯提高,交叉驗證預測均方差(RMSPCV)由0.666 38降低到 0.026 633,預測均方根誤差(RMSEP)由0.020 228降低到 0.014 391,預測精度由0.973 61提高到0.981 23,相關系數(r)由0.779 93提高到0.793 63(圖4)。試驗結果表明,基于SavitZky-Golay一階導數使用連續投影算法(SPA)能夠有效地對光譜數據進行壓縮,提取特征波長,消了散射影響,降低噪聲干擾、提高建模精度。

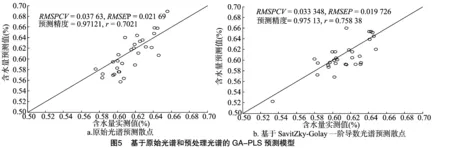
2.3.2 GA-PLS模型建立與預測 通過GA和PLS算法,分別對胡楊葉片原始光譜和一階導數光譜進行建模,在PLS方法交叉驗證計算過程中,依變量負載值對變量排序,通過逐一計算誤差值RMSPCV,選取最小RMSPCV所對應的特征變量數即是最優擬合特征數。結果發現,基于一階導數光譜與GA算法提取的特征波長進行建模的精度、相關性均明顯提高,交叉驗證預測均方差(RMSPCV)由0.037 63降低到0.033 348,預測均方根誤差(RMSEP)由 0.021 69 降低到 0.019 726,預測精度由0.971 21提高到 0.975 13,相關系數(r)由0.702 1提高到0.758 38(圖5)。試驗結果表明,基于SavitZky-Golay一階導數使用遺傳算法(GA)能夠有效地對光譜數據進行壓縮,提取特征波長,消了散射影響,降低噪聲干擾、提高建模精度。
綜合比較SPA-PLS和GA-PLS算法在同一預處理結果上的建模指數,SPA-PLS總體要優于GA-PLS。SPA-PLS選擇的變量只用了18個,而GA-PLS用了29個,并且評價指數均優于GA-PLS,較少的波段能夠提高運算速度,同時減少成本。因此,選擇SPA-PLS算法為胡楊葉片含水量最佳預測模型。
3 結論
在胡楊葉片含水量近紅外光譜監測中使用連續投影算法(SPA)與遺傳算法(GA)進行有效波長的選取是可行的。對SavitZky-Golay一階導數光譜數據使用SPA選取的有效波長基本上都分布在1 360、1 650 nm附近,并且所選波長與含水量有較好的相關性。利用SPA可以有效地降低光譜矩陣的維數。基于相同預處理光譜采用SPA-PLS的結果要優于GA-PLS,預測精度達到了0.981 23,相關系數達到了 0.793 63,為研制胡楊葉片水分便攜式檢測儀提供了理論依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
