基于Q-Learning的無人駕駛船舶路徑規劃
2018-11-01 09:15:18,*,,
船海工程 2018年5期
,*,,
(大連海事大學 a.航海動態仿真與控制交通行業重點實驗室;b.交通信息工程實驗室,116026)
目前,在移動機器人、無人機與無人艇領域中,有效的路徑規劃方法有人工勢場法[1]、粒子群算法[2]、神經網絡法[3]與遺傳算法[4]等方法。這些方法通常需要假設完備的環境信息,然而在未知環境中無人駕駛系統很少有環境的先驗知識,在大量的實際應用中需要系統具有較強的自適應不確定環境的能力,借助傳感器實時感知障礙物信息進行在線規劃。目前,國內外基于強化學習的路徑規劃方法分別在移動機器人[5-6]、無人機[7]、無人車[8]和多智能體[9]等領域取得較好的成果,但在無人駕駛貨船智能航行與路徑規劃方面還處于初步研究階段。為實現未知環境先驗知識情況下無人駕駛貨船自適應路徑規劃,考慮將強化學習創新遷移應用至無人駕駛貨船的路徑規劃領域,利用強化學習選擇策略完成無人駕駛貨船的避障并抵達目的地。
1 強化學習原理及模型基本要素
1.1 強化學習原理
強化學習又稱增強學習、再勵學習[10]。無人駕駛船舶在強化學習系統中通過與環境交互進行在線學習,強化學習原理見圖1。
在強化學習中,無人能駕駛船舶根據當前的狀態St選擇一個動作At對環境造成影響,并接受到環境的反饋Rt(獎或懲),無人駕駛船舶再根據當前的反饋信號和環境選擇下一個動作,選擇的原則是使環境的正反饋概率最大。
在離散時間內強化學習本質上可以被視為馬爾科夫決策過程(Markov decision process,MDP),一個適用于無人駕駛船舶的馬爾科夫決策過程由下面的五元組定義:(S,A,Pa,Ra,γ);S為無人駕駛船舶所處的有限狀態空間;A為無人駕駛船舶的動作空間,即無人駕駛船舶在任何狀態下的所有行為空間的集合,例如左舵、右舵、加速、減速、跟船和停船等;Pa(s,s′)=P(s′|s,a)為一個條件概率,代表無人駕駛船舶在狀態s和動作a下,到達下一個狀態s′的概率;Ra(s,s′)為一個激勵函數,代表了無人駕駛船舶在動作a下,從狀態s到狀態s′所得到的激勵。γ∈(0,1)為激勵的衰減因子,下一個時刻的激勵便按照這個因子進行衰減[11-12]。
目前常用的強化學習算法有Q-Learning、SARSA-Learning、TD-Learning和自適應動態規劃等[13]。這里采用Q-Learning在線學習算法,Q-Learning被視為一個增量式動態規劃,通過優化動作函數Q(s,a)尋找最優策略使得累計回報的期望最大。Q-Learning算法既可滿足系統在環境中的自適應性,又可確保算法在學習過程中收斂[14]。
1.2 強化學習模型基本要素
在無人駕駛貨船的強化學習系統中,除了船舶自身,還有以下4大要素[15]。
1)環境模型。無人駕駛船舶環境模型包括無人駕駛船舶、障礙物、起始點、目標點及傳感器。在環境模型中,無人駕駛船舶通過傳感器獲取障礙物與目標點的信息,執行搜索策略后模型會做出反饋以判斷動作策略的獎懲。
2)激勵函數R。激勵函數是在無人駕駛船舶做出動作策略與環境進行交互后由環境反饋的強化信號,用來評價該動作策略的好壞,如果有助于實現目標則會獎勵,反之懲罰。
3)值函數Q(s)。值函數是指無人駕駛船舶在動作搜索策略下,從當前狀態轉移至目標狀態過程中累積回報的數學期望。值函數Qπ(s,a)在實數范圍內取值,并將決定無人駕駛系統的動作搜索策略。
Qπ(s,a)=Epπ(t)[G(t)|s1=s,a1=a]
(1)
4)策略π。無人駕駛船舶的路徑規劃需要解決的問題就是為尋找一個最優“策略”,使得回報最大,本質上,策略就是無人駕駛船舶狀態S到無人駕駛船舶行為動作A的映射,記為π:S→A。
2 模型建立
2.1 環境模型
基于python和pygame構建二維仿真環境。在二維坐標系中,每一個坐標點對應無人駕駛船舶的一個狀態,每個狀態均可映射到環境狀態集S中的每一個元素。仿真環境模型中,每個坐標點存在兩種狀態值,分別是1和0。其中1代表的是可航行區域,在環境模型中顯示為白色區域;0代表著障礙物區域,在環境模型中顯示為黑色區域。仿真環境模型見圖2,仿真環境狀態大小為800×500的二維地圖,環境模型中仿真了靜態船舶、防波堤和港池岸基等障礙物。對于無人駕駛船舶來說,這些障礙物的位置信息未知。
2.2 動作空間的表示
設定無人駕駛船舶的初始點和目標點之后,在仿真過程中將無人駕駛船舶視為一個質點。在真實的航行過程中無人駕駛船舶自主航行是連續的狀態,進而需要將無人駕駛船舶的觀測行為O泛化為離散動作A=Generalization(A′,O)。一般情況下,無人駕駛船舶的搜索動作為上、下、左、右4個離散動作,當環境出現拐角時則增加對角線方向的搜索行為。
以無人駕駛船舶質點為中心,定義無人駕駛船舶的實際動作空間模型A為上、下、左、右、上左45°、上右45°、下左45°、下右45°8個離散動作,矩陣為
A=[-1,1 0,1 1,1 -1,0 1,0
-1,-1 0,-1 1,-1]
(2)
2.3 激勵函數的設計
在無人駕駛船舶強化學習系統中,激勵函數扮演著重要的角色,可評價無人駕駛船舶行為決策的有效性及避障的安全性等,具有搜索導向性作用。對于無人駕駛船舶來說,激勵函數由安全性、舒適性及抵達目標點組成。在設計激勵函數時,應盡可能考慮以下要素[16]。
1) 接近目標點。強化系統在未知環境情況下做出的搜索行為應使無人駕駛船舶更加接近目標點。更加接近激勵函數會選擇獎賞,否則將懲罰:
(3)
2)安全性。在Q-Learning算法模型中,將無人駕駛船舶所處的未知環境劃分為N個狀態空間,其中分為安全狀態區域和障礙物區域,無人駕駛船舶強化學習系統應在障礙物局部區域選取滿足船舶安全性的動作搜索策略,并“早、清、大”地避開障礙物。因此,在激勵函數中,對接近障礙物的行為增加懲罰值,反之增加獎勵值。
(4)
式中:No為無人駕駛船舶當前狀態下需要考慮的障礙物數量;∨為符號“或”;(xo,yo)為障礙物位置;Z0為船舶航行安全會遇距離,和船舶尺度(船長L)有關,船越長或船型越大,所需要的安全會遇距離就越大。
由于Q-Learning算法中的環境狀態集和無人駕駛船舶動作狀態均是有限的,而實際的無人駕駛船舶運輸過程均是連續系統性事件,因此,將激勵函數泛化處理為非線性分段函數。
(5)
式中:s=0表示無人駕駛船舶與障礙物發生碰撞;s=1表示無人駕駛船舶在安全區域航行;dg(t)為t時刻無人駕駛船舶距離目標點的距離;dg(t-1)為t-1時刻無人駕駛船舶距離目標點的距離;do(t)為t時刻無人駕駛船舶距離障礙物距離;do(t-1)為t-1時刻無人駕駛船舶距離障礙物距離。
2.4 動作選擇策略
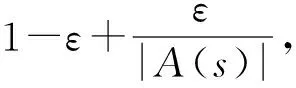
(6)
3 仿真實驗及結果分析
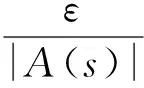
設定無人駕駛船舶的初始位置(128,416)和目標點(685,36),在實驗迭代前期無人駕駛船舶分別在不同的時間步與障礙物發生碰撞,實驗中發生碰撞后無人駕駛船舶將返回上一步并重新選擇動作策略。
如圖3所示,初始迭代中,無人駕駛船舶在仿真環境中無法判斷誘惑區域以至于陷入仿真港池中的“陷阱”海域;在迭代100次之后系統逐漸規劃出有效路徑,但過程中多次出現碰撞障礙物現象且規劃路徑波動較大;迭代200次~500次,碰撞現象逐漸減少且規劃路徑波動減緩;在迭代1 000次有效地避讓所有的障礙物且規劃的路徑波動較弱并逐漸穩定;直到迭代第1 600次,隨機搜索的概率最小,強化學習系統規劃出最終的固定路徑,到達目標點。
4 結論
無人駕駛船舶在與環境交互初期,對環境狀態信息了解過少,會發生碰撞及路徑規劃波動較大等現象。隨著迭代次數的增加,無人駕駛船舶系統累計學習經驗,完成對環境的自適應,最終成功規劃路徑并抵達目標點。但是,如果需要強化學習真正能夠在無人駕駛的場景下應用,強化學習算法還需要很多改進。
1)基于馬爾科夫決策過程的Q-Learning算法能通過試錯算法取得最優路徑,但其收斂速度較慢,迭代次數較多。第一個改進方向就是提高強化學習的自適應能力,以達到只用少量的樣本進行少量的迭代就能學習到正確的行為。
2)強化學習中的策略函數和值函數都是由深度神經網絡表示的,而深度神經網絡的可解釋性比較差,這一安全問題在無人駕駛貨船運輸中不能被接受。第二個改進方向就是提高模型的可解釋性。
3)在實際航行過程中,無人駕駛貨船的行為具有復雜的連續性,在本次仿真實驗中僅做了簡單的泛化處理,將無人駕駛船舶的駕駛行為劃分為上、下、左、右等8個動作,第三個改進的方向是增加模型的預測和“想象”的能力。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
船舶(2021年4期)2021-09-07 17:32:22
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國衛生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
