網絡家用紡織品資源抽取方法
2018-10-30 07:42:02吳志明張遠鵬
紡織學報 2018年10期
楊 娟, 吳志明, 張遠鵬
(1. 南通大學 紡織服裝學院, 江蘇 南通 226019; 2. 蘇州大學 紡織與服裝工程學院, 江蘇 蘇州 215123; 3. 江南大學 紡織服裝學院, 江蘇 無錫 214122; 4. 南通大學 醫學信息學系, 江蘇 南通 226001; 5. 江南大學 數字媒體學院, 江蘇 無錫 214122)
紡織業是我國重要的傳統支柱產業,“十三五”規劃對紡織工業進行了定位調整,強調了信息化技術的深入應用[1]。家用紡織品作為紡織業終端用途中的重要組成部分占有相當一部分比重。中國是世界生產、消費和出口家紡產品的大國,擁有全球規模前列的家紡產業集群和床品交易市場,然而在國際上的品牌影響力和競爭力卻并不占優勢。通過對現有的家紡從業者、研究者及學習者的調研發現,目前家紡行業普遍存在文化資源相對匱乏、資源獲取困難、信息資源共享不足、信息分散且檢索任務繁重、產學研對接不暢等現象[2]。基于此,建立集文化傳承、產業資源、行業資訊、設計開發、學術研究、技術共享、交易流通于一體的特色綜合資源庫勢在必行。
國內的相關資源庫主要是圖片等基礎設計素材的集合,近年來新開發的一些素材庫增加了定制模塊、花型交易模塊等,是對原有素材庫的一種突破。2003年中國紡織信息中心開發了一套“紡織行業數據庫咨詢系統”,奠定了紡織行業信息化的基礎,但由于數據更新及資源量的限制,資源庫的作用并未得到充分的發揮。曹飛[3]對家紡床品數據庫查詢系統進行了研究,主要面向家紡設計師建立了風格、圖案題材和加工工藝數據庫,該資源庫的建設模式主要以人工采集數據源和手工錄入為主,工作量大且繁瑣。從目前的市場應用來看,針對家用紡織品且尚無集文化、設計、市場、教學于一體的綜合資源庫。互聯網各類家紡資源井噴式增長為構建特色家紡資源庫提供了豐富的數據來源。然而,龐大、復雜、多樣的網絡資源也為此類資源的獲取帶來了極大的挑戰,如何有效地從海量的網絡資源中自動抽取有價值的信息是家紡資源庫構建過程中亟待解決的問題。本文從家紡資源庫的構建需求出發,提出一種深網資源的抽取和噪聲過濾的方法,實現網絡家紡資源的自動化抽取和噪聲過濾,為家紡資源庫的構建奠定基礎。
1 家紡網絡資源庫構建背景
1.1 構建需求
本文在充分考慮中國家紡產業集群優勢的基礎上,建立集文化傳承、產業資源、行業資訊、設計開發、學術研究、技術共享、交易流通于一體的特色綜合資源庫。具體來說,所構建的特色家紡資源庫需求陳述如下。
1)文化庫:包括歷史文化,傳統工藝,傳統紋樣,品牌文化和博物館收藏;
2)資訊庫:包括新聞資訊,政策法規和產業分析,家紡知識,展會信息,大賽信息;
3)家紡名錄庫:包括企業名錄,工作室名錄和設計師名錄;
4)學術資源庫:包括行業標準,專利信息,圖書檢索,文獻檢索,會議檢索;
5)設計資源庫:包括花型圖片,款式圖片,面料圖片和家紡展圖片;
6)工藝庫:包括常規工藝,特殊工藝和裝飾工藝;
7)定制庫:包括全定制,部分定制和自定制;
8)交易平臺:包括產品信息,報價和技術共享;
9)視頻資源庫:包括教學視頻,展會視頻和綜合視頻。
1.2 資源分布
根據家紡資源庫的建設需求,組織相關人力在互聯網上進行廣泛搜索,尋找相關資源的分布。為后續能夠利用信息抽取(information extraction, IE)技術自動化抽取,給出所獲得部分資源的統一資源定位符(uniform recourse location, URL),如表1所示。
2 家紡網絡資源抽取
2.1 基本框架
網絡信息抽取作為數據挖掘的重要組成部分,其主要目標是從Web非結構化的資源中獲取結構化的信息。由于網絡資源所呈現的方式具有多樣性、復雜性以及無規律性等特征,為網絡信息抽取工作帶來了眾多的困難。在搜集URL過程中發現,家紡資源在網絡上主要以2種方式呈現,即淺網(Surface Web)資源和深網(Deep Web)資源。淺網資源是指以靜態方式呈現在網絡上的信息,這類信息直接顯示在Web頁面上,可通過一些通用的網絡爬蟲軟件(如“火車頭”)直接獲取;深網資源是指隱藏在查詢接口背后的資源,這類資源對用戶不是直接可見,需要在頁面所提供的查詢接口中,輸入相關查詢條件,才能獲取[4]。
無論是淺網資源還是深網資源,在獲取之后往往包含噪聲信息,這些噪聲信息包括“頁面導航欄”、“廣告欄”、“版權欄”等,如何有效地過濾這些噪聲信息,亦是本文研究的核心技術。圖1示出家紡特色資源抽取的基本架構。深網資源的獲取關鍵是發現查詢接口(query interfaces,QIs),并判斷接口所屬領域,然后填寫領域關鍵詞。在本文中,通過構建領域模型(domain model,DM)來實現對查詢接口的判別。對于所獲取的家紡資源(網頁文件),首先利用基于視覺的頁面分塊算法(vision-based page segmentation, VIPS)[5]對頁面進行分塊,然后構建分塊重要度模型,通過人工標注,訓練該模型參數,實現對頁面噪聲的過濾。
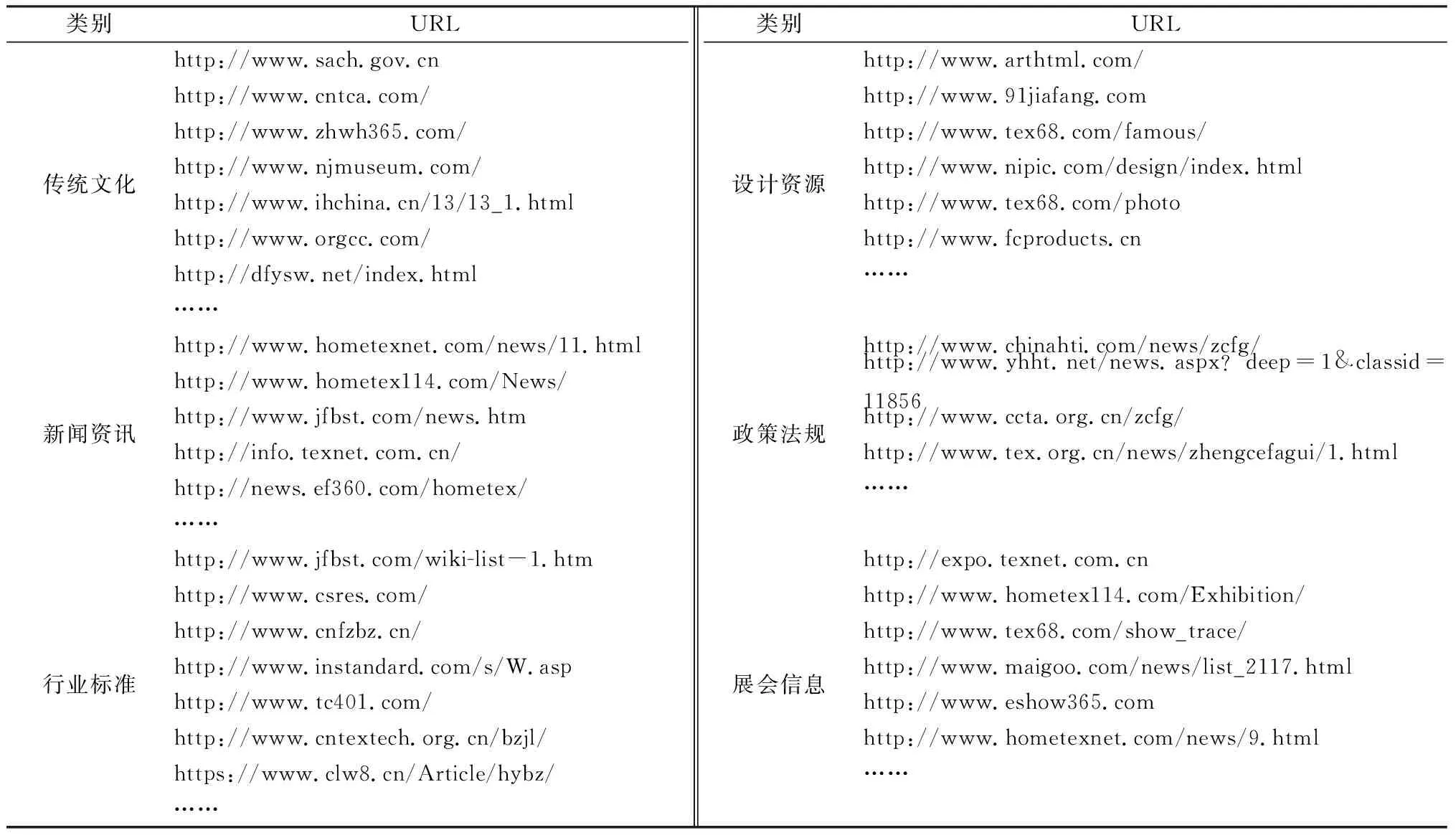
表1 部分家紡資源的URL分布Tab.1 URL for part of home textile resources
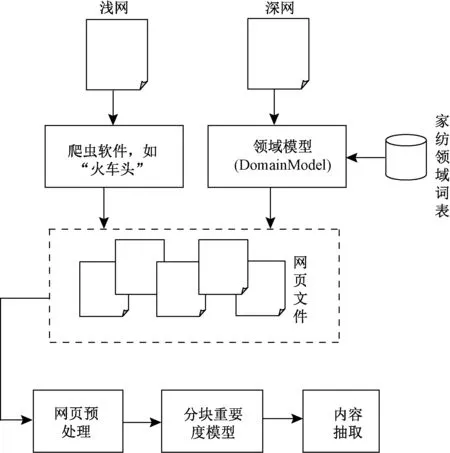
圖1 家紡資源抽取框架Fig.1 Framework of home textile resources extraction
2.2 領域模型
對于Deep Web家紡資源的自動抽取,其核心是發現QIs,QIs在Web頁面中通常是以Web表單的形式存在,Web表單是HTML中的高級元素,由起始鏈接簽組成,之間一般包含表單域,如文本框等。表單的HTML結構如下:
對于上述表單,name,method,action均為表單的屬性,其中:name表示表單的名稱;method表示表單提交的方式,可以有get和post 2種提交方式;action指明處理表單程序所在的位置,該屬性的值為一個URL。為更好地描述Web表單,定義1個五元組來進行形式化描述,即:Form={{C1,C2,…,Cn},A,N,M,U},其中,C1,C2,…,Cn表示表單中所包含的表單域,如文本框,單選按鈕,復選按鈕等,A表示表單的action屬性,N表示表單的名稱,M表示表單method屬性,U表示表單所在頁面的URL。
此后,通過構建領域模型來實現對QIs進行領域分類以及自動進行關鍵詞填寫。
2.2.1領域模型的定義
伊利諾伊大學厄本那-香檳分校的研究人員通過收集和分析Deep Web QIs發現:每個QI所包含的屬性個數是有限的;雖然在同一個領域,QI的數量很多,但是,其屬性進行聚合后,具有收斂性[6]。依據上述2個特征,提出領域模型對QIs的屬性進行建模,其定義如下:
領域模型可被描述為1個包含11元素的有序屬性樹,即DM=(V,v0,E, Δ,TP, N,Lb, Val, tf, R, ≤),其中:V為節點集,即為領域模型中所有節點的集合;v0∈V,表示領域模型中的根節點;E為邊集,即父節點和子節點的集合;Δ為字符集,即領域模型中,所有字符的集合;TP為一映射函數,實現節點到表單域類型的映射,這里,表單域類型集合為{radio button (單選按鈕), check box (復選按鈕),text box (文本框),select list (下拉列表)},其返回值為表單域類型;N為一映射函數,實現節點到表單域名稱的映射,返回值為表單域名稱;Lb為一映射函數,實現節點到表單域名稱列表的映射,返回值為表單域列表;Val為一映射函數,實現節點到表單域值的映射,返回值為表單域的值;tf為一映射函數,實現節點到使用頻率的映射,返回表單域使用的頻率;R為一映射函數,實現節點和其父節點的映射,返回它們之間的關系,包括range(節點是其父節點的區間成分)關系,part (節點是其父節點的組成部分)關系,group (表示節點與其他兄弟節點具有相同的語義)關系,constraint (表示節點是其父節點的一個約束)關系;≤表示領域模型中,節點之間出現的先后順序,例如,如果存在(u,v)∈≤,則表示u先于v出現。
2.2.2領域模型的構建
按照上述領域模型的定義,圖2示出領域模型的構建流程。在圖中,條件1:如果新加入的節點v與DM中所有節點的語義均不同,則執行“添加”操作,在DM中添加以節點v為根節點的子樹;條件2:如果新加入的節點v與DM中存在語義相近的節點,若為u,則執行“更新”操作,在DM中將當前節點v的TP,N,Lb,Val等更新至節點u對應屬性的列表中;條件3:如果新加入的節點v與DM中存在語義相近的節點,若為u,且節點v中包含了u中沒有的屬性,則執行“細化”操作,將v作為u的子節點;條件4:如果新加入的節點v與DM中若干節點u1,u2,…的語義相近,且包含這些節點的屬性,則執行“泛化”操作,將節點v作為u1,u2,…的父親節點。

圖2 領域模型的構建步驟Fig.2 Construct steps of domain model
圖2不斷重復執行,直至所構建的DM模型趨于穩定時,則停止,基于此可獲取家紡領域模型。
2.2.3DeepWeb查詢接口模式抽取
對于需要進行查詢的QIs,利用上述所構建的領域模型,進行接口模式抽取,其算法描述如下:
輸入:待處理表單,Form={{C1,C2,…,Cn},A,N,M,U};
輸出:待處理表單是否為QI及其領域類別。
過程如下:
1)若Ci(1≤i≤n)∈{Password, File, Textarea},則舍棄該表單;
2)抽取Ci(1≤i≤n)中的屬性詞,并進行規范化處理,包括過濾非法字符,去掉停用詞等;
3)遍歷所構建的DM,尋找與屬性詞對應的節點,并記為DMi(1≤i≤n);
4)通過向量空間模型(Vector Space Model, VSM),計算當前待處理Form表單與DMi的相似度,并選擇相似度最大的作為Form的領域分類;
5)從當前待處理Form表單所屬的領域中,選擇關鍵詞填寫表單,并進行查詢,所返回的結果中包含3個或以上鏈接,則認為當前待處理表單為QI。
值得注意的是,在1)中,如果Ci(1≤i≤n)∈ {Password, File, Textarea},則表明當前待處理表單中包含的表單域有密碼框,或文件上傳框,或多行文本框。如果表單中含有這種類型的表單域,則表明其實登錄表單,文件處理表單等,這類表單一般不返回有用的查詢結果,所以應該舍棄。
2.3 分塊重要度模型
在利用領域模型進行QIs判別和分類后,執行查詢并返回查詢界面,然而,對于返回的結果中,往往含有一些噪聲信息,例如導航欄,廣告欄,版權欄等。如果過濾這些噪聲信息對于本文所研究的家紡資源抽取來說,顯得非常重要。通過QIs返回的頁面及其布局結構,可以抽取正文欄目中的信息,過濾其他欄目信息。
鑒于此目標,首先要對返回的頁面進行分塊,用于分塊的方法有很多,例如文檔對象模型(document object model, DOM)算法[7],DOM算法可以將Web頁面格式化為DOM樹,雖然DOM樹能夠反映Web頁面的視覺和內在排版信息,但是卻依賴于瀏覽器進行顯示,且不同內核的瀏覽器顯示的效果不盡相同。VIPS算法能夠顯現地表達Web頁面的視覺信息和排版信息,易于后續加工處理,因此,在本文進行頁面內容抽取時,選用VIPS進行分塊處理。
通過使用1個離散的值來表示分塊的重要程度,為確定分塊的等級,組織人員對獲取的分塊進行重要等級劃分,最后對劃分的情況進行投票統計,最終分為3個等級,如表2所示。

表2 分塊等級及其描述Tab.2 Levels of blocks and their corresponding descriptions
為確定分塊的等級,本文提出分塊重要度模型,該模型的基本思想是按照頁面分塊的空間特征和內容特征,實現其到分塊重要程度值的映射,即:

表3 空間特征及其描述Tab.3 Space features and their corresponding descriptions
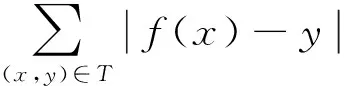

表4 內容特征及其描述Tab.4 Content features and their corresponding descriptions
3 實驗分析
為定量地評價本文所引入的領域模型以及分塊重要度模型在網絡家紡資源抽取中的效果,從1.2所闡述的家紡資源分布的URL中,選取足夠的查詢接口按照領域模型的構建方法來構建該領域的領域模型(當領域模型趨于穩定時,所選擇的查詢接口數量為2 385個)。隨后,依然從這些家紡資源中分別選取100個Deep Web QIs和50個非Deep Web QIs(包括登錄表單,文件上傳表單以及注冊表單等),用戶對領域模型的驗證和評價[8]。選擇陽性預測值P和正確率A作為評價指標,二者的定義如下:
式中:rQIs為正確識別為QIs的數量;wQIs為錯誤識別為QIs的數量;rNQIs為正確識別為非QIs的數量;t為所有接口數量。
同時,選擇文獻[9]中的方法,與基于規則的判別方法進行比較,結果如表5所示。
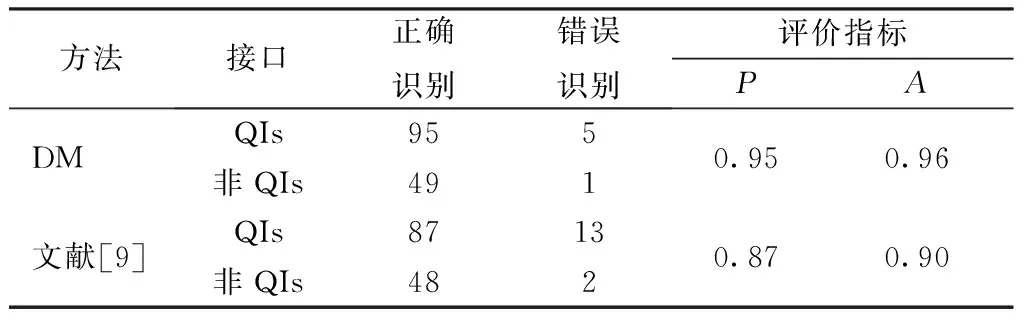
表5 QIs識別結果Tab.5 Identification results of QIs
從表5可看出,對于非QIs,DM和文獻[9]具有相當的識別效果,這是因為非QIs具有非常明顯的特征,且算法1在應用DM之前按照表單特征進行了類似于規則的判斷。然而,對于QIs,DM相對于文獻[9]中的算法,識別效果有了明顯的提升。
對于分塊重要度模型,選擇基于RBF核函數的SVM(support vector machines)[8,10-11]來學習模型參數。首先選擇3 000個通過QIs返回的頁面,并將其分成訓練組(2 000)和測試組(1 000),然后且利用VIPS進行頁面分塊,各得到13 589和7 415個分塊。對于訓練組,人工對分塊進行標注來訓練SVM模型參數。對于訓練好的模型,利用測試組分塊來進行測試,對于測試結果的評價,選擇的評價指標為準確率(Pr),召回率(R)以及準確率和召回率的調和平均數(F1),其定義如下:
式中:x表示正確識別出于抽取主題相關的分塊數量;y表示正確識別識別的與抽取主題相關和不相關的分塊數;z表示所有與主題相關的分塊數。表6示出了正確識別準確率的實驗結果。
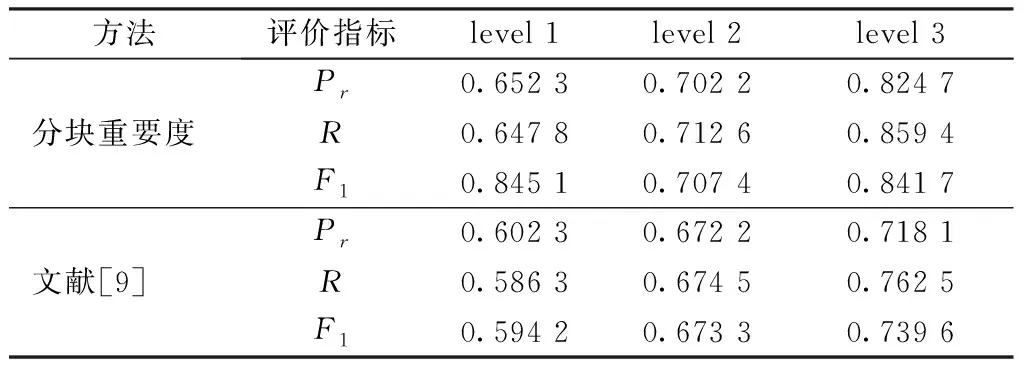
表6 噪聲過濾結果Tab.6 Noise filtration results
當面對海量網絡資源,按照返回的頁面布局很難構建有效的規則函數,因此,利用規則的方法難以奏效。然而,按照頁面的內容特征和空間特征,選擇機器學習算法進行模式學習,在高維空間分離出與主題相關的分塊以及噪聲分塊。實驗結果也表明這種方法優于基于規則的方法。
4 結束語
為構建家紡特色資源庫,本文構建了一種自動化的家紡資源抽取方法,該方法通過識別Deep Web查詢接口的方式,自動抽取家紡資源,且對返回的頁面進行噪聲過濾,實驗結果表明了該方法的有效性。在后續的研究中,將考慮采用分布式架構,來減少抽取的時間,同時進一步對所抽取的資源進行整合集成以及分類。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
中外會展(2014年4期)2014-11-27 07:46:46
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
