一種基于支持向量機的安卓惡意軟件新型檢測方法
2018-10-24 08:34:34張超欽胡光武王振龍劉新宇
計算機應用與軟件 2018年10期
張超欽 胡光武 王振龍 劉新宇
1(國家數字交換系統工程技術研究中心 河南 鄭州 450002)2(鄭州輕工業學院計算機與通信工程學院 河南 鄭州 450002)3(深圳信息職業技術學院計算機學院 廣東 深圳 518172)4(清華大學深圳研究生院 廣東 深圳 518055)5(深圳市金洲精工科技股份有限公司 廣東 深圳 518055)
0 引 言
近年來,基于安卓操作系統(Android)的智能終端設備得到了極大普及,并成為大部分智能手機的操作系統。但由于Android平臺的開放性,惡意軟件的制造者可以輕易地開發出大量的惡意軟件,給用戶帶來了很大的危害[1]。隨著Android智能手機的用戶數量不斷增加及越來越多的Android應用(App)不斷推出,檢測和防范Android惡意軟件的重要性日益突出[2]。
Android惡意軟件的檢測方法可以分為兩大類:靜態檢測和動態檢測。靜態檢測不需要實際運行程序,只需將程序源文件(APK)進行解壓和反編譯,然后提取相應的特征信息(如Permission、API等)、或者分析特征碼,就可以識別惡意App。因此靜態檢測過程比較簡單,檢測速度較快,但缺點是只能檢測現有已知惡意程序[8]。而動態檢測是指在程序運行過程中跟蹤程序的運行狀態,通過分析程序的實際運行行為來檢測惡意程序。包括跟蹤內存進程運行狀態、網絡狀態、文件操作、CPU使用情況、用戶隱私數據的訪問、系統調用等。因此,動態檢測過程較為復雜,需要運行程序才能判斷是否是惡意App,其效率較靜態檢測稍差,但可以檢測未知的惡意軟件。基于機器學習的動態檢測方法的成功取決于:(1) 收集信息的有用性和充分性;(2) 機器學習方法是否使用得當[3]。
系統調用是應用程序與操作系統進行交互最底層的接口,系統調用序列是對一個應用程序所有行為的最根本的描述,包含了程序行為的所有信息,因此通過分析程序的系統調用序列來識別惡意App可以取得比較好的檢測效果[4]。機器學習算法在惡意軟件的檢測方面應用非常廣泛,比如:樸素貝葉斯[3]、遺傳算法[5]、決策樹[6]、支持向量機(SVM)[7]、隨機森林[8]等。與其他方法相比,支持向量機可以在樣本比較少、特征維數比較高的情況下仍然擁有很好的泛化能力,而且可以避免“維度災難”[9]。
考慮到以上系統調用序列和支持向量機的特性,本文提出Android平臺基于系統調用序列的SVM檢測惡意軟件的方法。不同于現有的SVM方法[3,6-8,10-11]直接分析調用序列,本文采用了馬爾可夫鏈(Markov Chain)提取系統調用序列的特征,即把一個系統調用當作一個Markov鏈狀態,而一個應用程序在一段時間內調用的系統調用序列可以當作一個離散時間Markov鏈[12]。緊接著,我們利用序列里相鄰系統調用對出現的頻率計算對應狀態的轉移概率,并在轉移概率矩陣的支持下,將其轉化成特征向量。另一方面,我們利用已有標簽(已判定為惡意或正常的App)的特征向量訓練SVM,使得訓練后的SVM可接受未知App的特征向量,計算該App所屬類別標簽(正常或惡意),從而判斷出該App的性質,實現判定未知App是否屬于惡意軟件的目的。通過在1 189個正常軟件和1 227個惡意軟件上進行的實驗結果表明,本文所提方法顯著優于現有的其他SVM檢測方法。
本文主要貢獻如下:(1) 總結了現有的使用SVM檢測Android惡意軟件的方法;(2) 首次提出基于系統調用序列的SVM檢測方法;(3) 利用Markov鏈提取系統調用序列的特征,更好地刻畫了App的動態行為;(4) 使用動態檢測方法檢測未知的惡意軟件,并具有較高的準確率。
1 背景知識
1.1 離散時間Markov鏈
定義1一個隨機過程{ξn,n≥1}具有狀態空間S={s1,s2,…,sn},如果對所有的n≥1,j∈S和sm∈S(1≤m≤n),有:
Pr(ξn+1=j|ξn=sn,ξn-1=sn-1,…,ξ1=s1)=
Pr(ξn+1=j|ξn=sn)
(1)
則稱該過程為離散時間Markov鏈DTMC(Discrete-Time Markov Chain)。
定義2一個離散時間Markov鏈{ξn,n≥1},如果它對所有的i∈S和j∈S,條件概率Pr(ξn+1=j|ξn=i)與n無關,則稱這個DTMC{ξn,n≥1}是時間齊次的。
對于時間齊次的DTMC{ξn,n≥1},一步狀態轉移概率記作pij=Pr(ξn+1=j|ξn=i),由一步狀態轉移概率pij構成的矩陣P=[pij]稱作(一步)狀態轉移概率矩陣。ti=Pr(ξ1=i)稱作狀態i的初始出現概率。行向量T=(ti)i∈S稱作初始概率分布,它由狀態的初始出現概率構成[12]。
定理1初始概率分布T和狀態轉移概率矩陣P可以完全刻畫時間齊次的DTMC{ξn,n≥1},即:
Pr(ξ1=s1,…,ξn-1=sn-1,ξn=sn)=
ts1ps1,s2…psn-1,sn
(2)
1.2 系統調用
操作系統的主要功能是硬件資源管理,為應用程序開發人員提供良好的環境,使應用程序具有更好的兼容性。為了達到這個目的,系統內核提供一系列具備預定功能的多內核函數,通過一組稱為系統調用的接口呈現給用戶。系統調用把應用程序的請求傳給內核,并調用相應的內核函數完成所需的處理,最終將處理結果返回給應用程序。和其他操作系統一樣,Android操作系統的架構也采用了分層的形式,從上層到底層分別是應用層、應用程序架構層、系統運行庫層和Linux內核層。本文所定義的系統調用是指在系統運行庫和Linux內核之間的接口。本文使用的Android版本是4.0.4,一共有196個不同的系統調用。
系統調用是應用程序與操作系統進行交互的最底層的接口,程序對硬件資源的請求最后都要通過調用系統調用來執行(包括API調用的執行)。較其他特征,系統調用序列更能刻畫一個應用程序行為,所以本方法擬通過程序的系統調用序列提取特征來進行惡意程序的檢測。同時,系統調用頻率只能描述事件出現的次數,并不能刻畫事件之間的關聯性。而離散時間Markov 鏈可以很好地挖掘出相鄰事件的關聯關系,因此本文將利用Markov 鏈來提取系統調用序列中的關聯特征。
1.3 支持向量機
下面以二分類問題為例介紹線性支持向量機SVM的原理。
給定樣本訓練集(xi,di),i=1,2,…,N,xi∈Rn,di∈{±1},SVM的原理是試圖尋找一個超平面(w·x)+b=0,x,w∈Rn,b∈R,使該超平面滿足分類要求,即尋找權值向量w和偏置b的最優值,使滿足公式:
di(wTxi+b)≥1-ξii=1,2,…,N
(3)
式中:松馳變量ξi≥0,i=1,2,…,N。
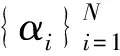
α=(α1,α2,…,αN)T
(4)
F(x)= sgn{(w0·x)+b0}=
(5)
對于線性不可分的輸入數據,支持向量機可以通過核方法利用以上原理,建立線性的特征空間像的最優分類面。此時的最優分類函數為:
(6)
式中:K(xi,x)是核函數。
2 SVM在惡意軟件檢測中的應用
SVM是一種建立在統計學習理論基礎之上的、應用最廣泛的機器學習算法。與傳統的分類方法相比,SVM在訓練樣本比較少,特征維數比較高的情況下仍然能夠顯示出很強的分類能力[9]。所以它廣泛應用于人臉識別、文本分類和人工智能等領域。現有使用SVM檢測Android惡意軟件的方法主要分為兩步,即提取特征和利用SVM進行分類。不同文獻方法之間的主要區別體現在提取了不同的特征。現有方法提取特征一般為:Permission、API調用以及內存使用情況、CPU使用信息、進程信息和電池信息等。
文獻[7]提出了基于Permission的檢測惡意程序的方法。先把程序的APK文件進行解壓和反編譯,提取出每個程序的Permission作為原始特征,然后通過主成分分析方法(PCA)降維得到新特征,作為SVM的輸入進行訓練和測試。單純的Permission不能提供足夠的信息證明一個程序是否惡意,該方法只能達到最高90.08%的準確率。與此類似,文獻[6]也先進行解壓和反編譯,提取出Permission和API調用,然后分別使用三種特征提取算法(Chi-Square、Relief和Information Gain)進行特征提取,最后利用SVM進行分類。文獻[11]的前面處理方式與文獻[6-7]一樣,提取的特征包括細粒度化的Permission(Requested Permissions、Used Permissions)、細粒度化的API(Restricted API calls、Suspicious API calls)以及程序組件和網絡地址(IP、URL、主機名)等。
由于以上這些方法沒有運行程序,因此都屬于靜態分析。它們只是從源代碼中提取特征,這樣提取的程序信息不夠充分,不足以判斷一個程序是否惡意。如通過Java反射機制可以改變或隱藏API的名字,從而逃避API特征的提取。動態分析方法則可以實時跟蹤和監控應用程序的運行行為,根據程序的運行狀態提取特征信息進行識別。與靜態分析相比,這種方法能夠獲取更多的信息[3]。
文獻[13-14]構建了一個檢測系統,通過監控應用程序的網絡、電話、短信息、CPU以及電池、進程、內存的信息,并從這些信息中挑出32個特征,然后利用Linear-SVM來檢測惡意軟件。文獻[14]的整個檢測系統分為兩部分:mobile agent和analysis server。其中mobile agent負責監控和記錄應用程序的運行狀態,而analysis server主要負責對獲得的運行信息進行分析。雖然以上文獻監控了應用程序的相關運行信息,但是這些信息并不全面,因此無法完全刻畫程序的行為,并引起一定的誤判,致使檢測效果不是很理想。例如:在手機上運行游戲程序時,CPU的使用率和內存的使用率突然變高,就可能導致誤判。文獻[3]使用APIMonitor和APE_BOX分別記錄應用程序的API調用和活動(activity),統計特定的25個API和13種活動單獨出現的次數,以及由這些組成的2-gram和3-gram的出現次數,接著拼接成一個56 354維的向量并進行歸一化,最后輸入到LIBSVM中進行檢測。但該方法僅依靠API調用和活動的頻率識別。
3 基于Markov鏈的惡意軟件檢測方法
如圖1所示,除樣本準備階段外本文提出的安卓惡意軟件檢測方法主要有三個步驟:預處理、特征提取和分類階段。

圖1 安卓惡意App檢測方法步驟
其中預處理包括系統調用序列的獲取、編號,并得到一個系統調用數列;特征提取包括計算狀態轉移概率矩陣和將矩陣轉換成特征向量;分類部分包括對SVM的訓練和利用SVM進行檢測。SVM的訓練過程是一個典型的有監督學習的過程,它可以對線性可分和線性不可分的樣本集進行分類。對于線性不可分的情況,SVM通過使用非線性映射算法(核方法)將低維輸入空間線性不可分的樣本轉化為高維特征空間的線性可分樣本,然后在高維空間采用線性算法進行分析。
3.1 預處理階段
預處理階段包括記錄系統調用序列和編號兩部分。我們通過strace、monkey命令來記錄一個應用程序發起的系統調用。strace 命令可以跟蹤到一個進程產生的系統調用,包括參數、返回值、執行消耗的時間。monkey是Android中的一個命令行工具,它能夠向系統發送偽隨機的用戶事件流(如按鍵輸入、觸摸屏輸入、手勢輸入等)。在這里,我們通過monkey工具來模擬用戶的使用行為。
在用strace跟蹤程序的系統調用的輸出文件中,會出現極少數的亂碼,我們通過去噪把這些亂碼刪除。然后把系統調用的時間、參數等都過濾掉,經過簡化,我們得到了只包含系統調用名稱的按時間順序排列的系統調用序列。為了方便后繼處理,我們用1,2,…,196,這196個數對Android4.0.4中的196個系統調用進行編號。經過這些操作后,系統調用序列轉化成了系統調用數列。
3.2 特征提取階段
提取特征的過程包括兩步,即計算狀態轉移概率矩陣和將矩陣轉換成特征向量。每個應用程序的系統調用序列當作一個離散時間Markov鏈,其中一個系統調用對應一個狀態,Android4.0.4共有196個系統調用,所以狀態轉移概率矩陣的維數是196×196。設經過預處理后的系統調用數列為s1,s2,…,sr,r為其長度,N為系統調用總個數(在我們的方法中N=196),計算狀態轉移矩陣P的偽代碼如下:
1P=(pij)N×N:=0;C=(cij)N×N:=0;k:=1;
2i:=sk,j:=sk+1;cij:=cij+1;
3k:=k+1;
4 IF (k≤r-1) Goto STEP 2;
6 For (1≤i,j≤N)pij:=cij/di;
假設一個系統只有6個不同的系統調用1、2、3、4、5、6,經過預處理后的系統調用序列假定為:2,1,6,4,1,3,5,4,6,3,2,5,1,4,5,3,4,2,1,4,6,2,5,3,6,4從系統調用i轉移到系統調用j的個數記為cij,從系統調用i轉移到任意系統調用的個數記為di,根據以上的系統調用序列有c11=0,c12=0,c13=1,c14=2,c15=0,c16=1,d1=4,……進而我們可以求出所有cij和di:
若系統調用i轉移到系統調用j的概率記為pij,根據概率論中的大數定理,我們可以定義:
(7)
最后,我們可以求得狀態轉移概率矩陣:
因為支持向量機的輸入為向量,所以在得到狀態轉移概率矩陣后,需要將矩陣轉換成(特征)向量,才能作為支持向量機的輸入。具體的轉換方法是將矩陣的每一行按行號從小到大把每行元素首尾相接連在一起構成一個(特征)向量。如以上的矩陣轉化后的特征向量是(0,0,1/4,1/2,0,1/4,1/2,0,0,0,1/2,0,0,1/4,0,1/4,1/4,1/4,1/5,1/5,0,0,1/5,2/5,1/4,0,1/2,1/4,0,0,0,1/4,1/4,1/2,0,0)。在我們的方法中,轉移概率矩陣的維數為196×196,所以轉換后的特征向量維數為38 416。
3.3 分類階段
本文的分類過程包括支持向量機的訓練過程和檢測過程兩部分。在我們的樣本集中有1 227個惡意軟件和1 189個正常軟件,取其中614個惡意軟件和595個正常軟件作為訓練樣本,剩下的613個惡意軟件和594個正常軟件作為測試樣本。每個軟件的系統調用序列經過預處理4.1和提取特征4.2的處理后得到了一個38 416維的特征向量。記惡意軟件得到的特征向量為xi∈R38 416,i=1,2,…,1 227;正常軟件得到的特征向量為yi∈R38 416,i=1,2,…,1 189。SVM的訓練過程是一個有監督的學習過程,其輸入為特征向量和其對應的標簽。具體在我們的方法中,SVM的訓練數據為38 417維的向量,即(xi,+1),i=1,2,…,614,和(yi,-1),i=1,2,…,595。其中“+1”是惡意軟件的標簽,“-1”是正常軟件的標簽。通過以上帶有標簽的數據的訓練,SVM求得最優權值向量w0,最優偏置b0和最優分類函數F(x),這樣就獲得了分類的知識,可以為無標簽數據計算標簽。
檢測過程是對未知的惡意軟件進行檢測,SVM的輸入不需要標簽,所以只是38 416維的特征向量。訓練好的SVM通過式(6)中的最優分類函數F(x)為每個輸入特征向量計算出一個新的標簽(1或-1)。具體在我們的方法中,對于每個測試樣本,訓練好后的SVM的輸入數據為其系統調用轉移概率矩陣轉化的特征向量xi(i=615,…,1 227),或yi(i=596,…,1 189);SVM的輸出數據為SVM通過式(6)計算出的該向量對應的標簽,如果標簽為“+1”,則該軟件被判為惡意,否則該軟件被判為正常。我們統計xi(i=615,…,1 227)作為SVM的輸入時,SVM輸出的標簽為“+1”的樣本總個數為TP(True Positive),輸出的標簽為“-1”的樣本總個數為FN(False Negative);yi(i=596,…,1 189)作為SVM的輸入時,SVM輸出標簽為“+1”的樣本總個數為FP(False Positive),輸出標簽為“-1”的樣本總個數為TN(True Negative)。這些數量可用于評估我們的方法。
4 實驗結果和分析
4.1 數據集和評判指標
本文的實驗數據集中的正常軟件來自于Android市場的官方網站。我們通過修改Chrome瀏覽器的插件,從中一共批量下載了1 189個App當作正常軟件。實驗數據集中的惡意軟件來自文獻[15],一共有1 227個惡意App,其中包括49個病毒家族。我們在MATLAB R2013b 中采用5個不同的核函數進行訓練和測試。
評判一個檢測系統好壞的常用指標有TPR(True Positive Rate)、FPR(False Positive Rate)、Precision和F-Score。記TP為惡意軟件被判定為惡意軟件的個數,FN為惡意軟件被判定為正常軟件的個數,TN為正常軟件被判定為正常軟件的個數,FP為正常軟件被判定為惡意軟件的個數,則TPR定義為:
(8)
FPR定義為:
(9)
Precision定義為:
(10)
F-Score定義為:
(11)
TPR相等時,FPR越小,檢測效果越好;反之FPR相等時,TPR越大,檢測效果越好。Precision越大說明檢測系統的準確度越高。F-Score是Precision和TPR的加權調和平均,是評判一個檢測系統綜合好壞的最重要的指標。
4.2 實驗結果
表1給出了我們的方法在不同核函數下的實驗結果。其中linear是線性核函數,quadratic是二次的核函數,polynomial是3次的多項式核函數,RBF是寬度為1的高斯徑向基函數,MLP是權重為1偏置為-1的多層感知器核函數。由表1可知,新方法利用線性SVM取得最好的檢測準確度:TPR為0.956 0,FPR為0.010 1,Precision為0.989 9,F-Score為0.972 6。其中613個惡意軟件的測試樣本中只有27個被誤判為正常軟件,594個正常軟件的測試樣本中只有6個被誤判為惡意軟件。

表1 本方案利用不同核函數對惡意軟件的判定結果
4.3 比較與分析
現有文獻[3,6-8,10-11]分別提出了6種不同的使用SVM檢測惡意軟件的方法。表2列出了本文方法(線性核)與以上6種方法的檢測結果的比較。從表中可以看出本文方法在Precision和F-Score值明顯優于其他SVM檢測方法。
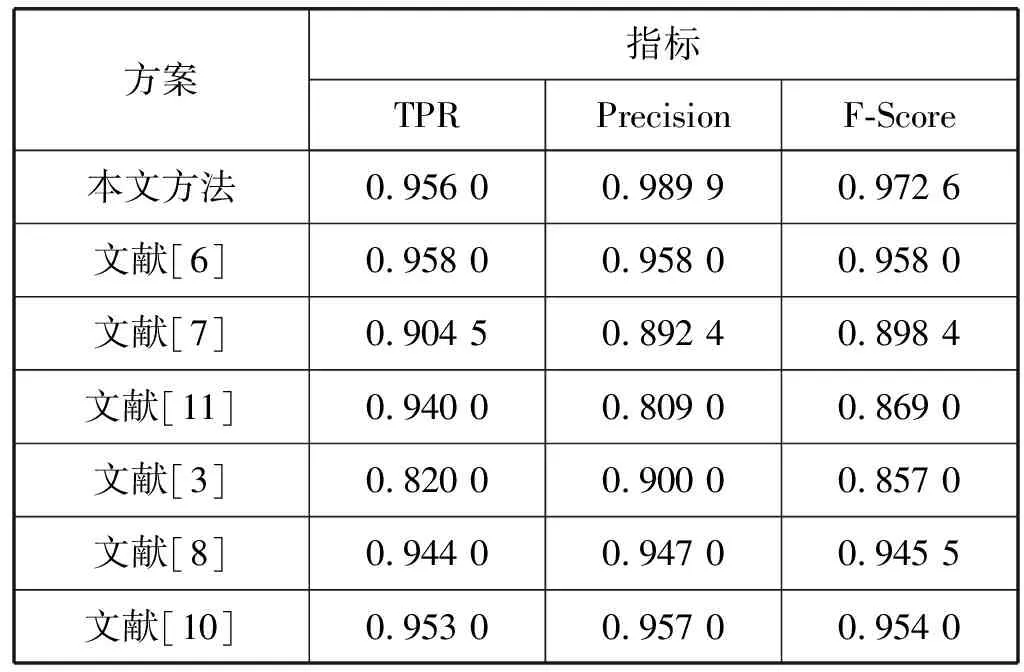
表2 本方案與其他方法的比較
文獻[6-7,11]是靜態分析的Android惡意軟件檢測方法。文獻[6]只考慮了應用程序的Permission特征,單純的Permission提供的信息非常有限。文獻[7,11]從Permission和API調用兩個方面提取特征。這些方法都是從靜態的源代碼中提取特征,這樣提取的程序信息不夠充分,不能描述程序的實際動態行為,所以它們的檢測結果比較差。
文獻[3,8,10]使用的是動態分析的檢測方法。文獻[8,10]從應用程序運行時的電話、短信息、網絡、CPU、電池以及進程、內存的信息中提取特征。由于這些相關運行信息并不夠全面,不能完全刻畫程序的所有行為,所以會引起一定誤判,檢測效果不是很理想。文獻[3]依靠API調用和活動的頻率來判別惡意程序。API調用是應用程序接口,底層都是通過調用系統的系統調用來執行的。系統調用相對于API調用更能細粒度地刻畫程序行為,而且頻率僅能體現事件次數,不能體現事件的內部聯系。Markov鏈描述了事件的前后聯系,所以利用Markov鏈提取系統調用特征的方法比文獻[3]方法的檢測結果好。
圖2直觀地反映了表2的結果,從該圖我們看可以出,本文提出的方案要優于靜態檢測方案6及動態檢測方案10,同時也明顯優于其他方案。
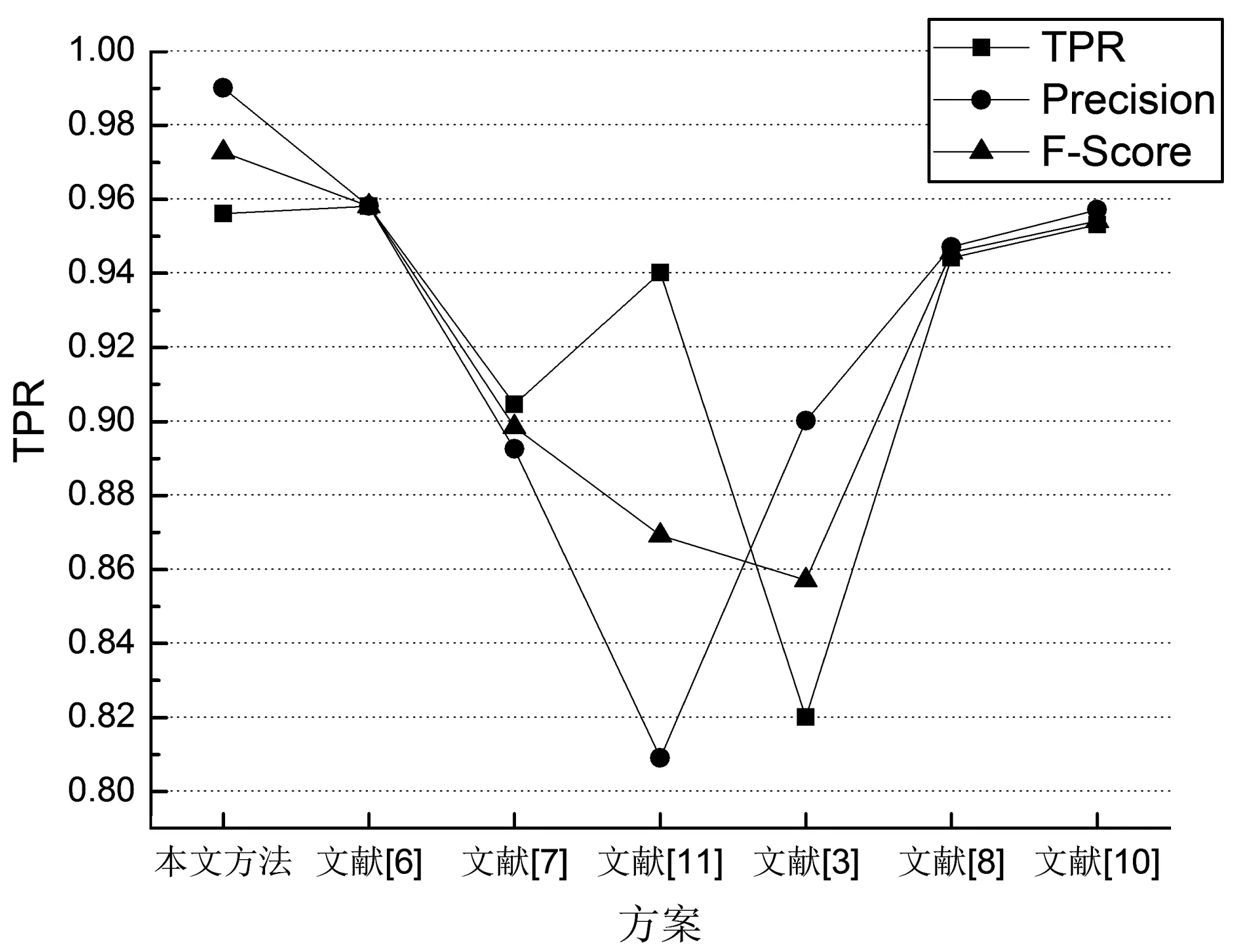
圖2 本方案與其他方案對比
5 結 語
本文提出了一種基于SVM分類器的Android惡意軟件檢測新型方法。該方法為系統調用序列建立了Markov模型,把Markov鏈的狀態轉移概率矩陣作為SVM的輸入來判別惡意軟件。實驗表明本方法的檢測效果優于現有的其他基于SVM的檢測方法。一方面是由于系統調用是一個應用程序具體行為的最根本的體現,另一方面是由于離散時間Markov鏈可以挖掘出隱藏在系統調用系列里的事件之間的聯系。但是本文中還有一些工作可以進一步的研究。建立Markov模型,計算狀態轉移概率矩陣只是從系統調用序列中提取信息的一種方法,是否存在更好的數學模型來提取特征值得我們將進一步研究和探討。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
