
基于GCC編譯器向量化的數(shù)據(jù)結(jié)構(gòu)布局優(yōu)化研究
2021-05-28 07:07:48朱廣林賴慶寬何先波王博生陳燕生
綿陽師范學院學報 2021年5期
朱廣林,賴慶寬,何先波,王博生,陳燕生
(西華師范大學計算機學院,四川南充 637009)
0 引言
為了充分利用處理器的并行潛力,現(xiàn)代CPU大多已提供向量處理單元(Vector Processing Units,VPUs)以允許在單條指令中對多個數(shù)據(jù)執(zhí)行操作.GCC、LLVM、ICC和AOCC等主流編譯器中也提供了編譯器的自動向量化(Compiler Automatic Vectorization,CAV)支持,它們能夠分析應(yīng)用程序中的循環(huán),自動找到使用SIMD指令的機會[1].通過一個向量指令操作完成對多個數(shù)據(jù)元素的同時運算[2,3],可以在與標量運算相同的時間內(nèi)執(zhí)行更多的操作,是提高程序性能的重要途徑之一.利用SIMD指令最常用的方法是編譯器的自動向量化,當編譯器不能對代碼進行向量化時,可嵌入向量化的匯編代碼,或調(diào)用一些高級的庫文件,如Boost.SIMD[4]等.
編譯器能否準確高效地進行自動向量化對程序整體的性能至關(guān)重要.編譯器根據(jù)編譯時得到的有效信息對程序進行向量化評估,以決定采用何種指令集[5].商業(yè)編譯器AOCC和ICC在O3及相關(guān)優(yōu)化組合下可以有效地挖掘和使用SIMD指令,做規(guī)整的向量化,但GCC編譯器的自動向量化優(yōu)化存在一些保守限制,因此編譯器的自動向量化技術(shù)仍有重要的研究價值.
本文主要對現(xiàn)代x86多核處理器中, GCC編譯器的數(shù)據(jù)結(jié)構(gòu)布局進行優(yōu)化,將代碼熱區(qū)域中進行數(shù)據(jù)結(jié)構(gòu)對齊,亦或是重組,拆分之后的結(jié)構(gòu)體進行數(shù)組結(jié)構(gòu)體數(shù)組(AoSoA)的布局轉(zhuǎn)換優(yōu)化,通過改善內(nèi)存布局方式,提高向量化優(yōu)化能力.通過分析優(yōu)化前后代碼中向量指令的數(shù)量和功能,最后在AMD平臺上進行了基準測試,驗證了該方法的有效性,以及具有向量化指令寬度擴展能力.
1 研究背景
編譯器的優(yōu)化能力受到諸多因素影響,為使應(yīng)用程序的向量運算性能最大化的發(fā)揮出來,本文基于國產(chǎn)x86處理器平臺上的GCC編譯器進行性能分析,通過變換數(shù)據(jù)結(jié)構(gòu)的布局方式,以有效利用全寬度的向量寄存器.
根據(jù)優(yōu)化粒度的不同,自動向量化分為循環(huán)向量化(Loop vectorization)和超字級并行向量化(Superword-Level Parallelism vectorization,SLP).循環(huán)向量化在基于循環(huán)和依賴關(guān)系的理論上使用SIMD指令[6],它利用粗粒度的并行性,通過展開循環(huán)以減少迭代次數(shù),同時在每個迭代中執(zhí)行更多操作.超字級并行向量化可利用SIMD基本塊中語句之間的并行性[7,8],也可用于優(yōu)化多重的嵌套循環(huán)[9].超字級并行向量化以更精細的粒度使用,可以在循環(huán)向量化存在限制的情況下加以利用,它將多個標量操作打包在一起來使用SIMD指令[10].
循環(huán)向量化先對循環(huán)的最內(nèi)層進行分析,以檢查是否存在數(shù)據(jù)依賴和函數(shù)調(diào)用等限制因素,當確定可進行向量化優(yōu)化之后,變換循環(huán)體結(jié)構(gòu)并生成向量化指令代碼.如圖1所示為循環(huán)向量化示例,圖1(a)的示例程序中,向量化受限于循環(huán)體中存在的循環(huán)依賴關(guān)系和函數(shù)調(diào)用,GCC編譯器需要在-O3及-ffast-math等優(yōu)化組合的情況下才能進行循環(huán)向量化.如圖1(b)所示,為了最大限度地進行向量化,編譯器需要執(zhí)行循環(huán)分裂(loop fission)轉(zhuǎn)換,將循環(huán)的一部分塑造成可向量化的形式,第一個循環(huán)經(jīng)過分裂和展開之后可進行向量化,如圖1(c)所示.
GCC編譯器中,向量化主要作用于中端GIMPLE trees表示的循環(huán)優(yōu)化上,且大部分向量化優(yōu)化選項已在-O3優(yōu)化中默認開啟.如圖2所示,當源碼經(jīng)過前端解析進入中端時,生成GIMPLE表示,它是一種與前端語言和目標機器都無關(guān)的三地址表示形式,引入了臨時變量來保存中間值,GCC中眾多的優(yōu)化在GIMPLE中間表示上進行[11].
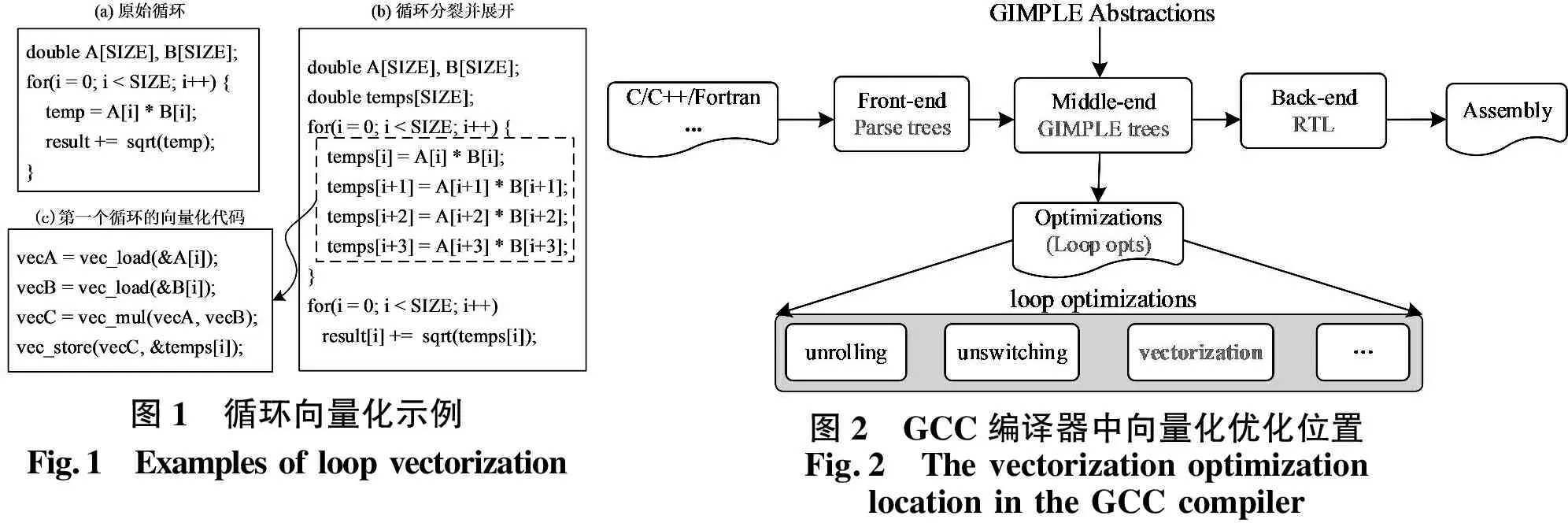
圖1 循環(huán)向量化示例Fig.1 Examples of loop vectorization圖2 GCC編譯器中向量化優(yōu)化位置Fig.2 The vectorization optimization location in the GCC compiler
2 數(shù)據(jù)結(jié)構(gòu)布局優(yōu)化設(shè)計與實現(xiàn)
本章節(jié)結(jié)構(gòu)如下:首先簡要介紹向量化優(yōu)化中指令數(shù)據(jù)類型及其相關(guān)的寄存器內(nèi)存布局;最后詳細說明數(shù)據(jù)結(jié)構(gòu)布局的向量化優(yōu)化方法的設(shè)計與實現(xiàn).
2.1 指令集數(shù)據(jù)類型及其內(nèi)存布局介紹
不同的SIMD擴展指令集都有其對應(yīng)的指令集體系結(jié)構(gòu)(Instruction Set Architecture, ISA和向量寄存器寬度[12].如圖3展示了英特爾SSE和AVX指令集中的數(shù)據(jù)類型以及相關(guān)向量寄存器的布局結(jié)構(gòu),圖3(a)中的數(shù)據(jù)類型,在SSE指令集中,128位寄存器可以表示為四個32位的元素或者兩個64位的元素,并且SSE中定義了標量和打包兩種類型的操作,標量運算對最低位有效數(shù)據(jù)元素進行運算,打包運算可并行計算所有位元素.在x86處理器上目前支持的最大向量寄存器寬度為512位,在支持多個向量寄存器的機器上,位數(shù)較小的寄存器作為較大寄存器的低位,不同大小的寄存器組分別為:ZMM、YMM和XMM[13].如圖3(b)所示,512位的ZMM寄存器低256位是YMM寄存器,而YMM寄存器的低128位與128位XMM寄存器復(fù)用.
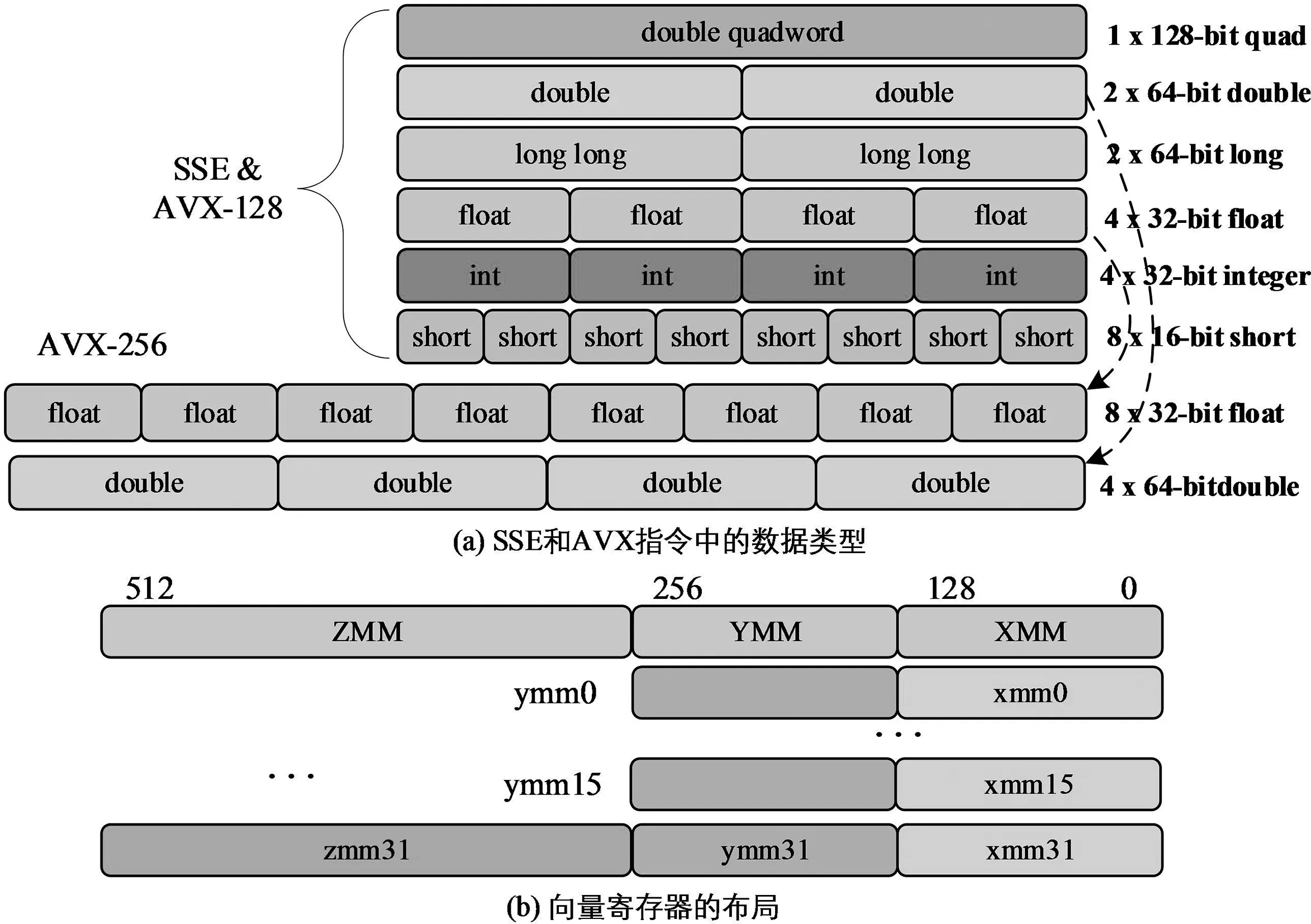
圖3 SSE和AVX指令中的數(shù)據(jù)類型和相關(guān)寄存器布局Fig.3 The data types in SSE and AVX instructions and related register layout
C/C++中的基本類型__m512、__m256d、__m128等可與編譯器的內(nèi)部函數(shù)一起使用,以促進向量寄存器的每一位元素都能有效利用,減少指令數(shù)量.
2.2數(shù)據(jù)結(jié)構(gòu)布局方法設(shè)計
數(shù)據(jù)布局是向量化中最重要的因素之一,數(shù)據(jù)根據(jù)組織方式的不同可以分為:結(jié)構(gòu)體數(shù)組(Array of Structures,AoS)、數(shù)組結(jié)構(gòu)體(Structure of Arrays,SoA)或數(shù)組結(jié)構(gòu)體數(shù)組(Array of Structures of Arrays,AoSoA).本文的設(shè)計方法是通過將數(shù)據(jù)結(jié)構(gòu)對齊,亦或是重組(reorder),拆分(split,peeling)之后的結(jié)構(gòu)體進行內(nèi)存布局轉(zhuǎn)換,變換為AoSoA組織方式.
數(shù)據(jù)結(jié)構(gòu)對齊包含數(shù)據(jù)對齊、數(shù)據(jù)填充和打包.結(jié)構(gòu)體數(shù)據(jù)對齊能提高訪存效率,根據(jù)對齊規(guī)則會對結(jié)構(gòu)中未使用的空間進行填充,如圖4所示,圖4(a)中的示例代碼,根據(jù)結(jié)構(gòu)體總大小為所有成員中最大對齊數(shù)的整數(shù)倍的規(guī)則,進行對齊和填充之后如圖4(b)所示,填充后的內(nèi)存布局如圖4(c)所示,而通過將結(jié)構(gòu)體中數(shù)據(jù)打包,可以減少應(yīng)用程序所需的內(nèi)存空間,如圖4(d)所示,對結(jié)構(gòu)體進行打包之后編譯器便不會進行填充,但某些編譯器可能不允許未對齊的內(nèi)存訪問.
AoS、SoA和AoSoA優(yōu)化示例如圖5所示,使用AoS數(shù)據(jù)結(jié)構(gòu)時,在訪問下一組數(shù)據(jù)之前需要先獲取結(jié)構(gòu)體的所有元素,但可能許多元素都未被使用,使用SoA結(jié)構(gòu)時,結(jié)構(gòu)體的每個元素分為一個數(shù)組,具有更好的布局方式.圖5(d)所示為三種結(jié)構(gòu)的內(nèi)存使用布局方式.AoSoA是AoS和SoA兩種布局的一種組合方法,它通過vpshufb等指令將按AoS組合的數(shù)據(jù)進行混洗到適當向量寄存器中,以有效利用寄存器寬度,不僅保持了良好的數(shù)據(jù)布局和代碼的直觀性,同時對現(xiàn)代處理器的緩存體系也更加友好,使用AoSoA可對大多數(shù)運算進行高效地向量化.

圖4 結(jié)構(gòu)體的數(shù)據(jù)結(jié)構(gòu)對齊及其內(nèi)存布局示意圖Fig.4 Schematic diagram of structure data structure alignment and memory layout圖5 AoS、SoA和AoSoA優(yōu)化示例和內(nèi)存布局Fig.5 AoS, SoA and AoSoA optimized examples and memory layout
在GCC編譯過程中通過插樁(profiling)的反饋數(shù)據(jù)收集到熱區(qū)域中的結(jié)構(gòu)體信息,然后在GCC中端GIMPLE IR(Intermediate Representation)上新建優(yōu)化pass,對熱區(qū)域中的結(jié)構(gòu)體進行數(shù)組結(jié)構(gòu)體數(shù)組的布局轉(zhuǎn)換優(yōu)化.對優(yōu)化前后的匯編碼對比分析發(fā)現(xiàn),優(yōu)化后采用了vbroadcast、vpshufb、vpermilpd等數(shù)據(jù)混洗,轉(zhuǎn)置操作指令.
3 實驗設(shè)計與分析
3.1 實驗平臺與測試用例
為了對本文提出的方法的有效性進行評估,將優(yōu)化方法應(yīng)用到GCC8.2.0編譯器,其中GCC8.2.0版本發(fā)布時間為2018年7月26日.在AMD平臺上,對優(yōu)化前后的編譯器進行實驗,可以評估本文方法的有效性,以及編譯器的向量化能力.
表1列出了實驗中所使用平臺的基礎(chǔ)架構(gòu)特征以及支持的向量化指令集.表2給出了編譯器所使用的主要優(yōu)化選項組合.

表1 實驗平臺主要信息Tab.1 Main information of the experimental platform

表2 編譯器信息Tab.2 Compiler information
表1中進行實驗的AMD平臺支持所有Intel SIMD ISA擴展,表2中列出的編譯器的peak性能主要優(yōu)化選項組合,常規(guī)優(yōu)化-O3,鏈接時優(yōu)化-flto和數(shù)學函數(shù)優(yōu)化等.
本文實驗采用的是國際標準測試套件SPEC CPU 2017,其包含43個基準測試用例,涵蓋區(qū)域海洋模擬、天氣預(yù)報、圖像和視頻壓縮等眾多領(lǐng)域,是一套廣泛用于評估編譯器性能的測試集[14-16].采用ref數(shù)據(jù)集,將優(yōu)化前后的編譯器編譯測試用例得到的ratio值,分別作為baseratio和optimizedratio,根據(jù)公式1計算出優(yōu)化后的編譯器的性能加速比.
(1)
3.2 實驗結(jié)果與分析
為評估本文方法的有效性以及不同版本編譯器的向量化能力,在此對GCC8.2.0編譯器進行基準測試,并計算出性能加速比.以ref為輸入數(shù)據(jù)集進行編譯器優(yōu)化前后的測試,根據(jù)公式1對實驗的ratio值進行計算得到性能加速比.
對SPEC 2017中浮點測試集進行測試,得到實驗結(jié)果如圖6所示,GCC8.2.0編譯器在進行數(shù)據(jù)結(jié)構(gòu)布局優(yōu)化后625.x264_s、628.pop2_s和638.imagick_s 三個benchmark分別取得1.04x、1.05x和1.07x的性能加速比,驗證了該方法的有效性,并且優(yōu)化后的匯編碼中出現(xiàn)預(yù)期的數(shù)據(jù)轉(zhuǎn)換操作相關(guān)的向量化指令.實驗數(shù)據(jù)表明該方法具有在進行向量化指令寬度擴展的能力.

圖6 AMD平臺上優(yōu)化前后的性能加速比Fig.6 Performance speedup before and after optimization on AMD platform
4 結(jié)束語
本文提出的數(shù)據(jù)結(jié)構(gòu)布局優(yōu)化方法對熱區(qū)域中,進行數(shù)據(jù)結(jié)構(gòu)對齊,亦或是重組,拆分之后的結(jié)構(gòu)體進行數(shù)組結(jié)構(gòu)體數(shù)組(AoSoA)的布局轉(zhuǎn)換優(yōu)化,通過改善內(nèi)存布局方式,提高向量化優(yōu)化能力.通過在AMD上進行的實驗分析,驗證了該方法的有效性,以及具有向量化指令寬度擴展能力.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
哲學評論(2021年2期)2021-08-22 01:53:34
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
中華詩詞(2019年7期)2019-11-25 01:43:04
測控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
