基于多編碼器多解碼器的大規模維漢神經網絡機器翻譯模型
2018-10-19 03:03:28張金超艾山吾買爾買合木提買買提
中文信息學報 2018年9期
張金超,艾山·吾買爾,買合木提·買買提,劉 群
(1. 中國科學院 計算技術研究所 智能信息處理重點實驗室,北京 100190;2. 中國科學院大學,北京 100049; 3. 騰訊科技(北京)有限公司,北京 100080;4. 新疆大學 信息科學與工程學院,烏魯木齊 新疆 830046;5. 都柏林城市大學,都柏林 愛爾蘭)
0 引言
機器翻譯任務致力于使用計算機實現源端語言到目標端語言的自動化翻譯,降低不同語種群體之間的溝通代價,是人工智能學科的一個重要分支。統計機器翻譯模型(statistical machine translation model,SMT)在神經網絡翻譯模型(neural machine translation model,NMT)被提出之前是主流的翻譯模型,主要的模型有基于詞的機器翻譯模型[1]、基于短語的機器翻譯模型[2]、基于句法的機器翻譯模型[3]。在統計機器翻譯模型中,翻譯知識是從雙語平行句對中使用統計方法學習到的顯式規則。統計機器翻譯模型通常包括多個子模型,比如翻譯概率子模型、調序子模型、語言模型子模型,這些子模型被流水線式地一步步搭建和調優。與統計機器翻譯模型不同,神經網絡翻譯模型[4-7]使用一個神經網絡直接進行端到端(end-to-end)的訓練來擬合翻譯知識。具體地,神經網絡翻譯模型借助于編碼器(encoder)對源端的句子進行向量化的分布式表示,使用解碼器(decoder)根據源端的分布式表示逐詞地生成目標端的句子。注意力(attention)機制被引入來建模詞對齊的信息。通過這樣的方式,模型中所有的參數都統一到一致的目標函數下調整,模型中的翻譯知識通過神經元之間的連接權重隱含地表達。神經網絡翻譯模型自提出以來,在多個語言對上的表現顯著地超過了統計機器翻譯模型,成為當前主流的翻譯模型。
維漢神經網絡機器翻譯模型面臨著兩個困難: 一方面,維吾爾語是一種黏著語,通過在詞干上附加各種不同的詞綴來實現語法功能。維吾爾語的詞匯具有豐富的詞形變化,這就造成了嚴重的數據稀疏問題;另一方面,目前搭建維漢機器翻譯模型的語料規模都較小,在小規模的訓練語料上得到的系統翻譯質量低。對于神經網絡機器翻譯模型,數據規模十分影響模型質量。為提高維漢神經網絡機器翻譯模型的能力,本文提出使用多編碼器多解碼器的結構,搭建大規模的神經網絡模型。同時,分別探索了適合神經網絡機器翻譯的維漢翻譯單元粒度。本文的實驗在190萬句的維漢平行語料上進行,該語料是目前最大的維漢平行語料庫,實驗結果參考性高。本文的實驗結果證明,在大規模訓練數據的條件下,基于神經網絡的維漢機器翻譯模型的能力顯著地超過了統計機器翻譯模型;多編碼器多解碼器的網絡結構能夠有效地提高神經網絡機器翻譯模型的能力;維吾爾語端采用字節對編碼作為基本翻譯單元,漢語端采用漢字作為基本翻譯單元,可以擺脫對漢語端分詞器的依賴,并得到效果很好的翻譯系統。
1 相關工作
神經網絡機器翻譯模型的基本結構是編碼器—解碼器(encoder-decoder)結構。編碼器通常是循環神經網絡(recurrent meural network,RNN)[7]或卷積神經網絡(convolutional neural network,CNN)[8],最新的研究也有使用基于自注意力機制(self attention)的編碼器[9]。編碼器的主要功能是對源端待翻譯的句子進行向量化的壓縮表示。基于RNN的編碼器視句子為一個序列,對句子中出現的詞匯按時間順序逐個處理,形成壓縮表示。兩個不同的RNN分別處理正向和逆向的詞匯序列,兩種表示被連接起來作為最終的源端表示。基于門(gate)控機制的門控循環神經網絡(gated recurrent neural network,GRU)[5]和帶有記憶模塊和門控機制的長短時記憶循環神經網絡(long-short term memory recurrent neural network,LSTM)[10]使得RNN具有選擇性捕獲和遺忘歷史信息的能力。基于CNN的編碼器通過使用不同寬度的滑動窗口,從序列中捕獲上下文局部信息。多層的CNN編碼器和池化(pooling)機制可以實現對全局信息的學習。基于自注意力機制的編碼器,使句子序列中詞匯之間的交互距離成為與句子長度無關的常數,對于捕獲長距離依賴信息具有顯著優勢。解碼器會根據編碼器對源端句子的表示和已經生成的目標端的局部譯文,逐翻譯單元地生成目標端譯文。對已生成的目標端的局部譯文的建模,同編碼器一樣可以使用循環神經網絡、卷積神經網絡、自注意力機制等。注意力機制[6]被引入到神經網絡翻譯模型中,目的是對詞對齊信息進行顯式的建模。
之前已有研究者嘗試使用神經網絡模型搭建維漢機器翻譯模型的工作。孔金英[11]等使用帶注意力機制的編碼器解碼器結構搭建了維漢口語機器翻譯模型。哈里旦木[12]等對比了多種神經網絡機器翻譯模型。這些工作都是基于單編碼器單解碼器的基本神經網絡結構。訓練數據分別為50萬句和10萬句的小規模語料,神經網絡規模較小,結構較簡單。本文提出使用多編碼器多解碼器的結構,搭建結構更復雜的大規模維漢機器翻譯模型來提高維漢機器翻譯譯文的質量,并在大規模數據上進行了有效性驗證。
神經網絡機器翻譯模型以端到端的方式對輸入序列和輸出序列的映射進行直接建模。給定源端輸入X={x1,…,xm}和目標端輸出Y={y1,…,yn},翻譯概率被建模成,如式(1)所示。
(1)
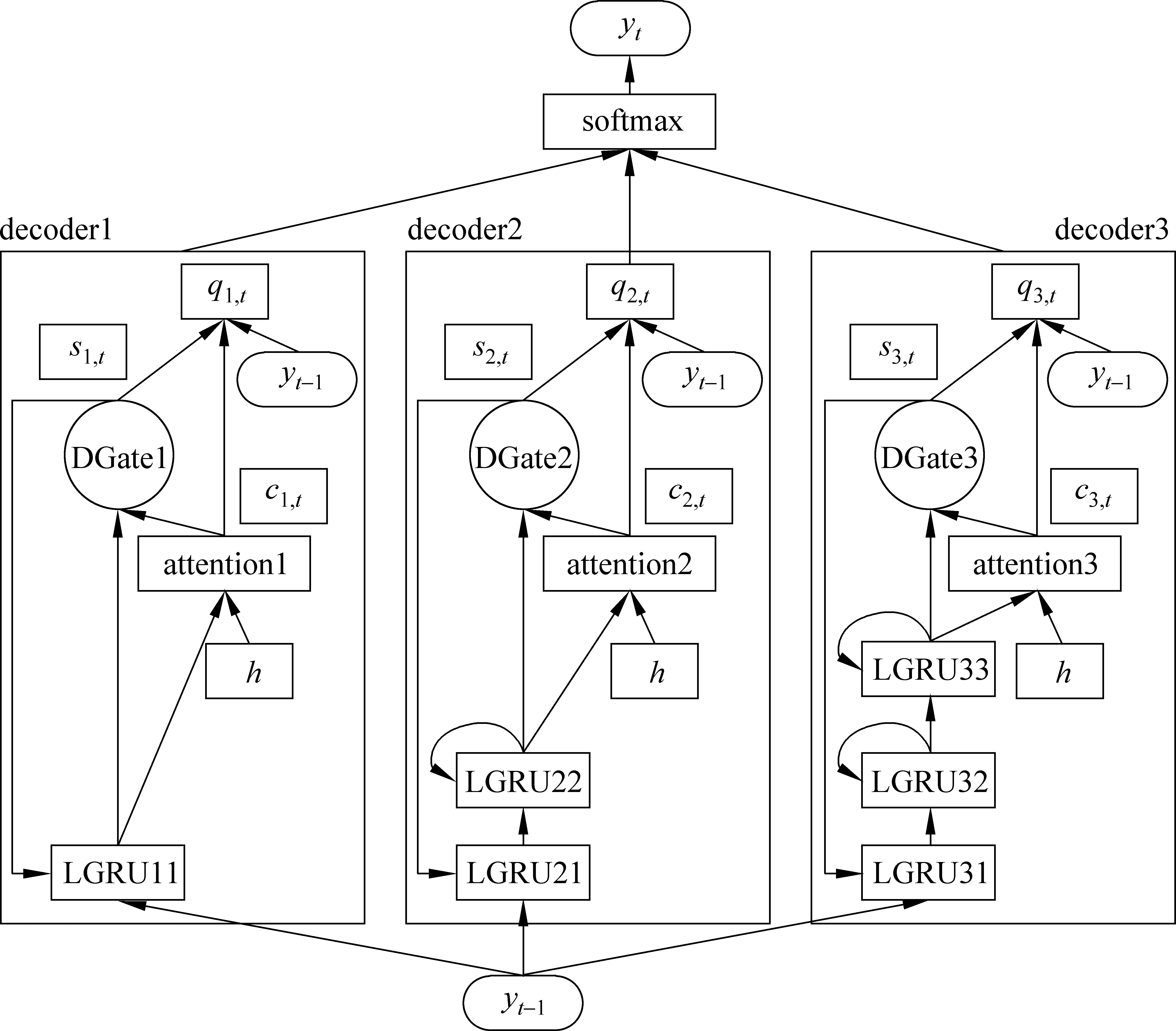
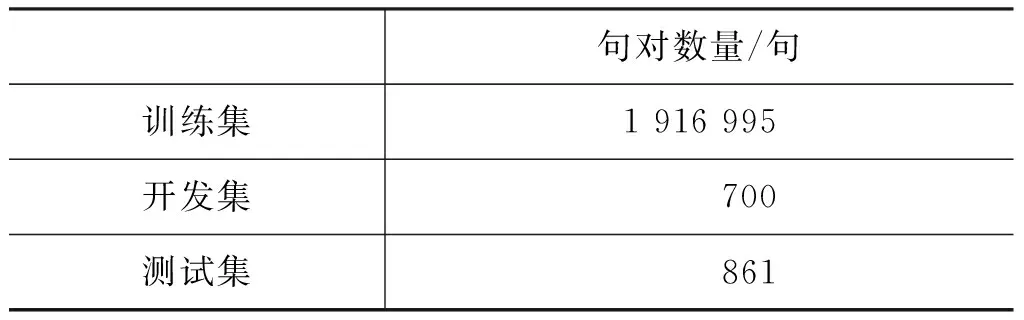
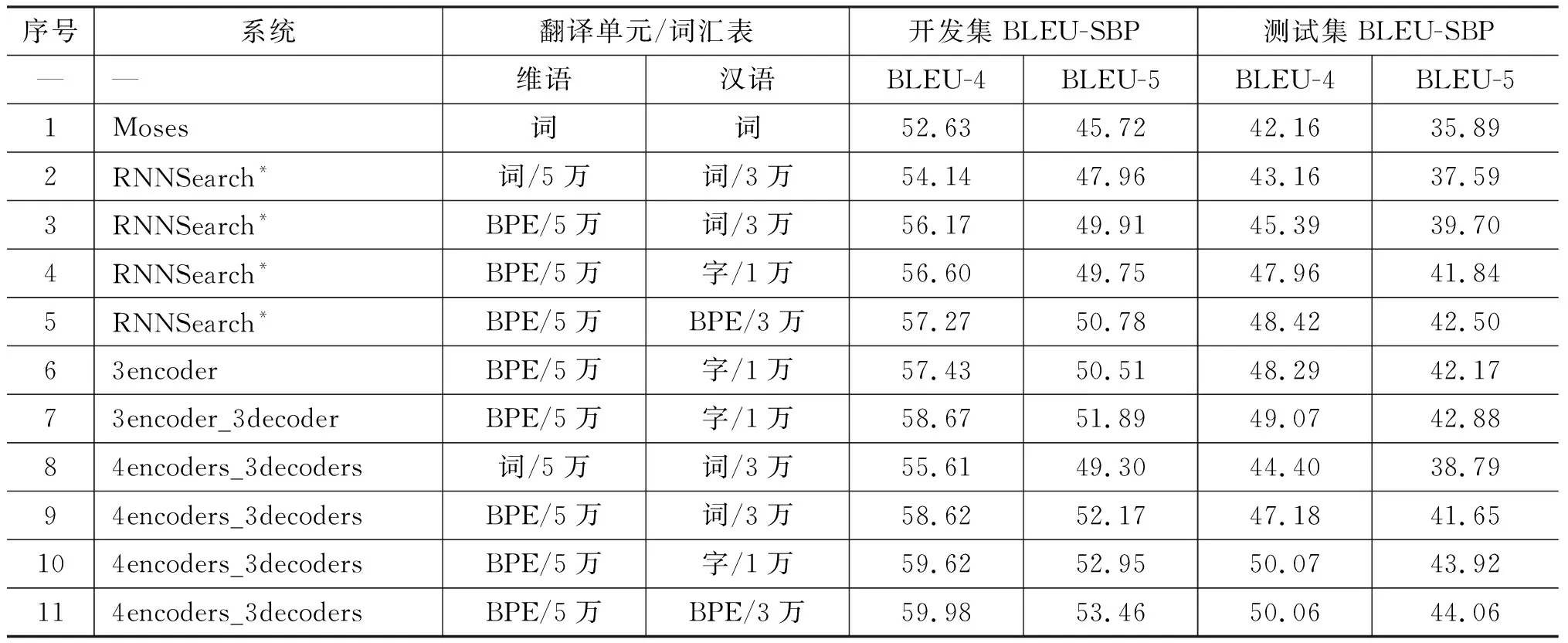
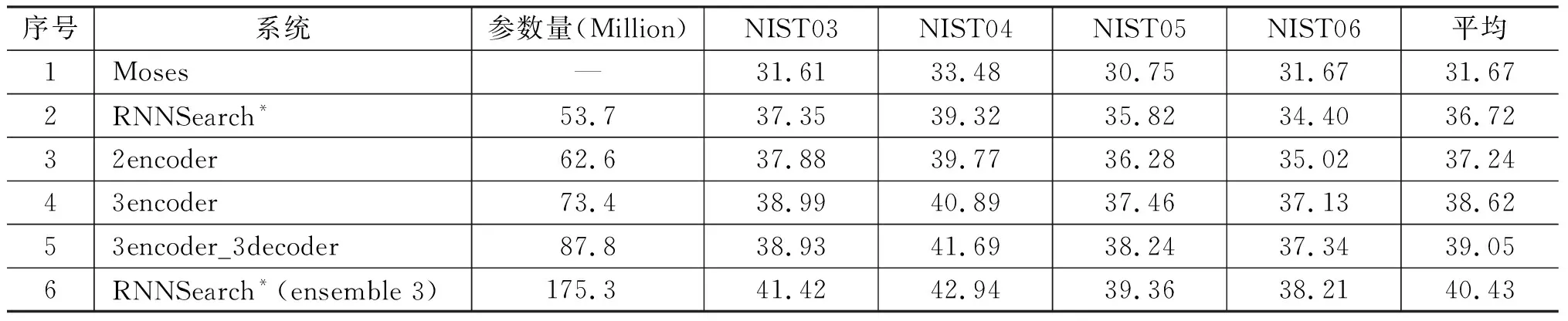
其中,y h={h1,…,hm}=Encoder(X), Y={y1,…,yn}=Decoder(h) (2) 其中,h是源端句子的分布式表示,目標語言的生成過程如式(3)所示。 q=g(yt-1,ct,st), P(yt|y (3) 其中,q是預測目標端詞的張量,g(·)是一個線性函數,st是解碼器的隱層狀態,ct是源端分布式表示的權重加和,通過注意力機制計算得出。ct的計算方式如式(4)所示。 (4) 其中,Wα,Uα,Vα為矩陣參數。 圖1展示了一個基本的神經網絡機器翻譯模型的架構,包括編碼器、解碼器和注意力機制。 圖1 帶注意力機制的神經網絡機器翻譯模型 為提升維漢機器翻譯的譯文質量,本文提出使用多編碼器多解碼器結構,搭建大型的神經網絡機器翻譯模型。該模型結構如圖2所示,可以容納任意個數的編碼器和解碼器,易于擴展和增強。多個編碼器獨立工作,對源端句子進行分布式表示,所有編碼器的輸出通過一個前饋神經網絡結合到一起,構成源端句子的最終分布式表示。多個解碼器具有獨立的注意力機制,所有解碼器的輸出同樣被一個前饋神經網絡結合到一起,最終被集成到目標端詞匯表,分類層: 計算每個目標端翻譯單元的概率。網絡中所有的參數都統一到一致的目標函數下進行訓練學習。 圖2 多編碼器多解碼器結構示意圖 編碼器的作用是對源端句子進行分布式的表示,基本的神經網絡機器翻譯模型使用一個編碼器來處理源端的句子。多編碼器的思路是使用不同深度和結構的多個編碼器對源端句子分別進行分布式表示,然后將這多個分布式的表示融合起來作為源端句子最終的表示。不同深度的編碼器對源端句子具有不同的分布式表示能力,不同結構的編碼器對句子表示過程中關注的句子特征的方式不同。我們期望通過這種方式能得到一個對源端句子更全面的表示,增強模型能力。 圖3展示了一個由三個RNN和一個CNN構成的編碼器。四個子編碼器共享詞向量矩陣,其他參數獨立。輸入一個源端句子,句子中的翻譯單元,例如字或詞,經過詞向量矩陣的映射成為向量,每個子編碼器對該向量序列進行壓縮表示。我們使用GRU作為RNN的單元,逐層地堆疊RNN,形成深度網絡結構。前向的RNN和后向的RNN依次堆疊,來捕獲正向和反向的上下文環境。圖中所示的三個基于RNN的編碼器具有不同的深度,層數分別為2層、4層、6層。CNN子編碼器使用一個固定大小的滑動窗口來捕獲局部的上下文信息。為減少梯度傳播損失,我們使用一個門控單元來將每個子解碼器的原始輸出和詞向量通過一個門控單元進行重組。我們以encoder2的輸出為例,門控單元具體的計算如式(5)所示。 圖3 由三個RNN和一個CNN構成的編碼器 (5) 其中,Wxz,Woz,Wxh,Woh∈Rd×d為矩陣參數,bz,bh∈Rd為偏置參數。最終門控單元的輸出被一個前饋神經網絡組合起來,作為源端句子的分布式表示。該前饋神經網絡的計算如式(6)所示。 (6) 其中,Whk∈Rd×d是矩陣參數,b∈Rd是偏置參數。 解碼器逐翻譯單元地生成目標端譯文,我們提出使用多解碼器的結構提升解碼器的生成能力。為了方便表述,我們將注意力機制視為解碼器的一部分,我們的每個子解碼器中都包含一套獨立的注意力機制。所有子解碼器的輸出最終被結合到一起,用于目標端譯文的生成。 圖4展示了由三個子解碼器構成的解碼器結構,每個解碼器具有不同的深度。以decoder2為例,該子解碼器的計算邏輯,如式(7)所示。 (7) 圖4 由三個子解碼器構成的解碼器 (8) 其中,z是更新門,r是重置門,Wcz,Wsz,Wcr,Wsr,Wss,Wcs是矩陣參數。每個子解碼器的輸出qk,t使用一個前饋神經網絡組合到一起,輸入到目標端詞匯表分類模塊,得到歸一化的翻譯單元概率,計算過程如式(9)所示。 (9) 我們進行了多組實驗來驗證多編碼器多解碼器結構的有效性,并探索了翻譯單元的粒度對翻譯結果的影響。 訓練數據我們采用了新疆大學收集的新聞領域數據,數據規模在190萬句左右,是到目前為止維漢機器翻譯實驗使用的最大的平行語料。開發數據采用了CWMT2017維漢機器翻譯評測提供的開發集,測試數據使用了CWMT2017維漢機器翻譯評測提供的去重版測試集。數據規模如表1所示。 表1 數據規模 維吾爾語端進行了拉丁化處理和簡單的切分,拉丁化采用的是新疆大學提出的維吾爾語拉丁化方案,切分的目的是將標點符號和維吾爾語詞語分開。對于漢語,我們使用了中科院計算所的分詞工具進行了分詞處理,分詞標準遵循《人民日報》標準。翻譯結果的評價指標與CWMT2017保持一致,即基于字的BLEU-SBP分數。譯文沒有做任何后處理操作,統計機器翻譯模型的輸出譯文保留未登錄詞,神經網絡機器翻譯的輸出譯文保留未登錄詞符號。 統計機器翻譯模型使用了基于短語的模型,模型采用開源Moses系統訓練得到。詞對齊使用GIZA++工具,對齊策略為“grow-diag-final-and”。四元語言模型使用了SRLIM工具,借助Kneser-Ney算法做平滑。我們使用了MERT工具在開發集上進行調優。解碼搜索空間stack參數設為100。 我們實現了神經網絡機器翻譯模型RNNSearch*作為神經網絡翻譯模型的基線系統。該模型的編碼器和解碼器都基于門控神經網絡GRU,使用注意力機制連接編碼器和解碼器。我們搭建了多個多編碼器和多解碼器的模型,來探究該結構的有效性。神經網絡機器翻譯中,詞向量維度和隱層神經元的個數均設為512。對于方陣的權重參數,我們使用正交的初始化方式。對于非正交的矩陣權重參數,我們使用均值為0、方差為0.01的高斯分布進行初始化。所有的偏置參數初始化為0。參數訓練使用基于batch的梯度下降算法,batch的大小設置為80,學習率控制算法基于AdaDelta,其中衰減參數ρ=0.95,分母常量ξ=1E-6。Dropout策略只使用在解碼器輸出層,drop rate為0.5。梯度截斷(gradient cliping)算法被用來防止梯度爆炸,作用方式為L2正則的梯度大于1.0的時候重置為閾值。解碼采用柱搜索(beam search)的方式,beam size參數設為12,最終的譯文分數除以譯文長度做歸一化處理后進行重排序。 針對神經網絡翻譯面對的詞匯數據稀疏問題,我們在維吾爾語端進行了使用詞和字節對(BPE)編碼作為基本翻譯單元的實驗。字節對編碼使用了BPE開源工具,在維吾爾語端單語迭代5萬次。在漢語端進行了使用詞、漢字和字節對編碼作為基本翻譯單元的實驗。維吾爾語端5萬詞表在訓練語料上的文本覆蓋率約為94.6%; 5萬BPE單元詞匯表在訓練語料上的文本覆蓋率約為100%。漢語端3萬詞表在訓練語料上的文本覆蓋率為96.5%;1萬字單元詞匯表文本覆蓋率約為99.9%; 3萬BPE單元的詞匯表在訓練語料上的文本覆蓋率約為99.3%。 下面我們對實驗系統進行具體描述: (1) Moses是基于短語的統計機器翻譯系統; (2) RNNSearch*是帶注意力機制的單編碼器單解碼器結構的神經網絡機器翻譯系統; (3) 3encoder是具有三個編碼器的多編碼器結構的神經網絡機器翻譯系統,編碼器基本單元是GRU,每個編碼器的深度分別為2,4,6; (4) 3encoders_3decoders是具有三個編碼器三個解碼器的多解碼器多編碼器結構的神經網絡模型,編碼器和解碼器基本單元是GRU,每個編碼器的深度分別為2,4,6,每個解碼器深度分別為2,4,6; (5) 4encoders_3decoders是具有四個編碼器三個解碼器的多解碼器多編碼器結構的神經網絡機器翻譯系統。編碼器中三個是使用GRU的RNN,深度分別為2,4,6,還有一個是窗口寬度為3的CNN;多解碼器端有三個解碼器,都是使用GRU的RNN,深度分別為2,4,6。 表2展示了我們的實驗結果。通過分析實驗結果,我們可以看到統計機器翻譯模型的BLEU值明顯低于所有的神經網絡模型。對比系統1和系統2,在測試集的BLEU-5指標上,基于詞單元粒度的基本神經網絡翻譯模型RNNSearch*超過Moses約1.70個點。這說明在大規模訓練數據的條件下,即使維吾爾語由于其語言特點存在比較嚴重的詞匯稀疏問題,基于神經網絡的維漢機器翻譯模型的性能依然可以顯著超過基于短語的統計機器翻譯系統。 系統2~5用來對比不同粒度的翻譯單元對模型能力的影響。對比系統2和3,我們發現對維吾爾語端做字節對編碼后,測試集BLEU-5指標增長約2.11個點。實驗說明,維吾爾語端字節對編碼能夠改善其詞匯稀疏導致的詞匯表覆蓋率低、未登錄詞較多的問題。對比系統3和系統4,當我們在漢語端使用字作為翻譯單元時,可以進一步得到約2.14個BLEU-5點的提升。漢語端使用字作為翻譯單元具有多個優點: (1) 可以緩解詞匯稀疏問題,有效地提升翻譯質量; (2) 不再需要額外的分詞工具對訓練語料和測試語料進行分詞,同時也避免了不同分詞標準對模型的影響; (3) 詞匯表的規模可以大幅度縮小,有效地減少訓練時間和解碼時間。 對比系統3~4和5,我們發現在RNNSearch*模型上,維吾爾語端和漢語端都基于BPE單元,可以在測試集上得到最高的BLEU-5值。 系統6~7和10用來分別驗證多編碼器結構和多解碼器結構對模型能力的提升效果。對比系統4和系統6,我們發現多編碼器結構的神經網絡機器翻譯系統雖然在參數量上要小于RNNSearch*系統,但是效果卻優于RNNSearch*,這證明了多編碼器結構的有效性。對比系統6和系統7,我們發現通過擴展單解碼器到多解碼器結構,進一步帶來了翻譯效果的提升。對比系統7和系統10, 我們發現引入基于CNN結構的編碼器會進一步提高測試集BLEU-5分數約1.04個點的提升。這些實驗證明了我們提出的多解碼器多編碼器結構的有效性。 表2 維漢實驗結果 系統8~11是我們提出的使用多編碼器多解碼器結構搭建的大型神經網絡機器翻譯模型,我們同時也對其進行了不同翻譯單元粒度的測試。基于詞—詞粒度的多編碼器多解碼器系統8,與RNNSearch*系統2對比,測試集上BLEU-5指標提升了約1.2個點;基于BPE-詞的多編碼器多解碼器系統9與RNNSearch*系統3相比,測試集上BLEU-5指標提升了約1.95個點;基于BPE-字的多編碼器多解碼器系統10與RNNSearch*系統4相比,測試集上BLEU-5指標提升了2.08個點;基于BPE-BPE的多編碼器多解碼器系統11和RNNSearch*系統5相比,測試集上BLEU-5指標提升了1.56個點。這四組實驗對比,說明多編碼器多解碼器結構對于提升維漢神經網絡翻譯的性能有明顯的效果。對比系統10和11,我們發現在RNNSearch*系統上帶來了提升的漢語端BPE方案并沒有在大模型上帶來顯著性的提升。系統11是我們所有實驗中最優的模型,在BLEU-5指標上,超過了基于短語的統計機器翻譯系統約8.17個點,超過了基于詞的基本的神經網絡模型RNNSearch*約6.47個點。我們的實驗結論對于搭建高性能的維漢機器翻譯系統具有重要的參考價值。 我們在漢英翻譯方向上對多編碼器多解碼器神經網絡機器翻譯模型進行了實驗對比。訓練集選用的語料是語言數據聯盟(Linguistic Data Consortium)發布的語料(LDC2002E18,LDC2003E07,LDC2003E14,LDC2004T07 Hansards,LDC2004T08,LDC2005T06),共125萬句對,開發集使用的是2002年NIST評測發布的測試集,測試集使用的是2003—2006年NIST評測發布的測試集。實驗參數配置與維漢系統一致,雙語詞匯表規模限定為三萬,評價指標采用四元的BLEU值(mteval-v11b.pl)。 我們的實驗結果如表3所示。通過對比系統2、3、4、5,可以看出基于多編碼器多解碼器結構的神經網絡機器翻譯系統性能有了顯著的提升,這說明該結構在漢英翻譯方向上也可以有效地改善譯文質量。我們同時也和集成方法做了性能對比,這里使用的集成方法(ensemble)是獨立訓練了三個具有不同深度編碼器和解碼器(2、4、6層)的神經網絡機器翻譯模型,然后在解碼搜索的過程中,對三個模型輸出的目標端詞匯的概率分布做了平均化。我們可以看到,集成方法對于提升翻譯效果是有效的,但是會帶來總參數量成倍地增加。在訓練的時候,要針對每個模型進行獨立訓練和調優,在解碼的時候,所需的時間相對于單模型也會成倍的增加。我們提出的多編碼器多解碼器,參數統一訓練,共享結構使得參數量增長速度是線性的,解碼時最終計算目標端詞匯表概率分布的時候,只需要一次大矩陣的變換和一次softmax歸一化,計算量比集成方法要小很多,對于提升單模型的性能是十分經濟有效的。 表3 漢英實驗結果 本文提出使用多編碼器多解碼器的結構,搭建大規模的維漢神經網絡機器翻譯模型的方法。該結構可以對源語言進行多層次、多視角的壓縮表示;同時具有多個解碼器,可以增強目標語言的生成能力。實驗證明,在大規模的訓練數據上,使用該方法搭建的大規模維漢神經網絡機器翻譯模型,譯文質量可以大幅度地超過基于短語的統計機器翻譯模型和基本的神經網絡翻譯模型;維吾爾語端使用字節對編碼(BPE)單元、漢語端使用字單元,可以擺脫對漢語端分詞器的依賴,得到較強的翻譯系統。未來我們會考慮根據維吾爾語的特點,從語言學的角度提出更具有針對性的解決方案來緩解數據稀疏的問題,進一步提高維漢機器翻譯系統的性能表現。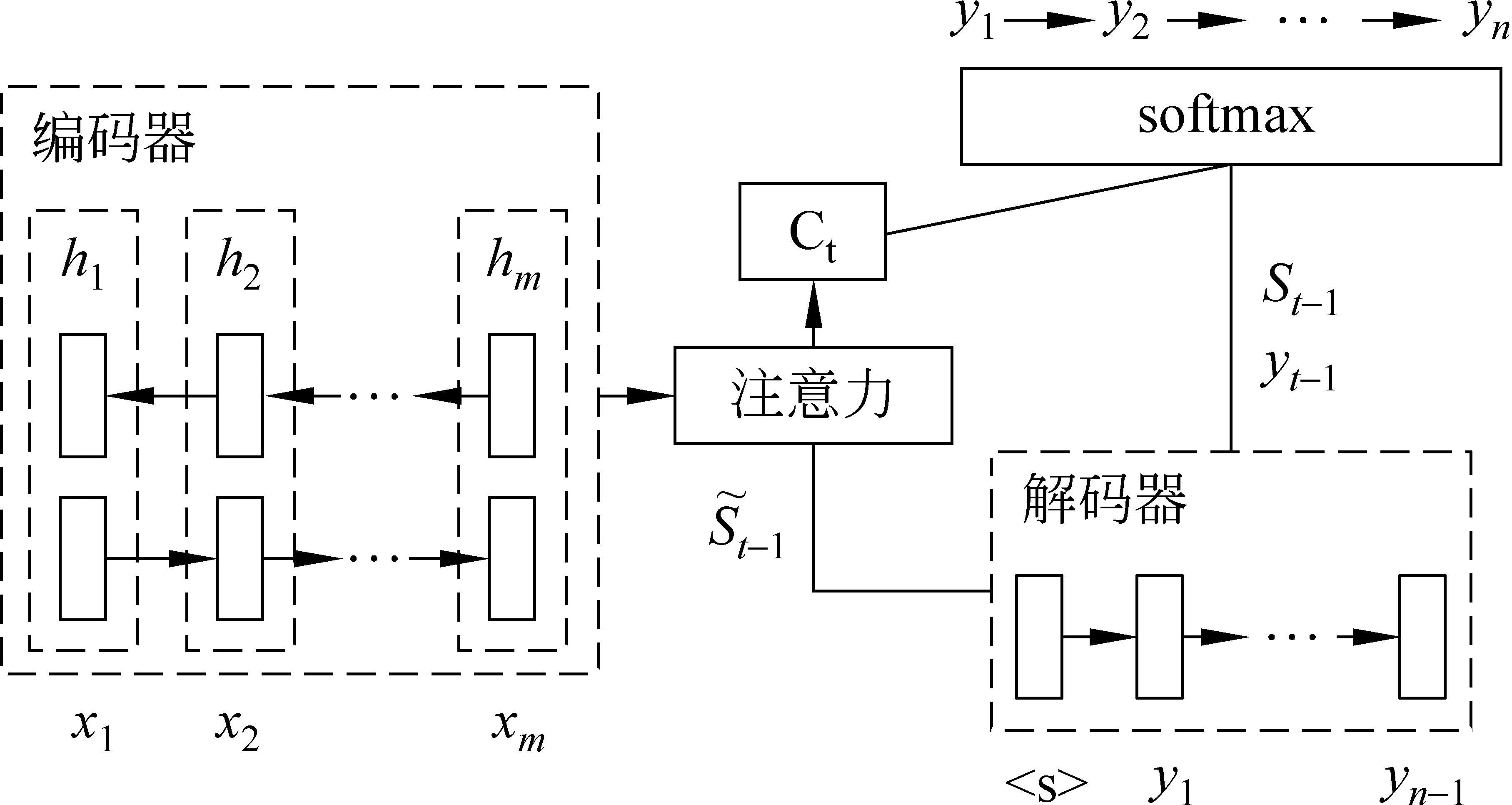
2 基于多編碼器多解碼器結構的維漢神經網絡模型
2.1 多編碼器結構
2.2 多解碼器結構
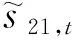
3 實驗
3.1 實驗數據與評價指標
3.2 實驗設計和參數細節
3.3 實驗結果及分析
3.4 漢英翻譯實驗及與集成方法的對比分析
4 總結與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38工業設計(2022年8期)2022-09-09 07:43:20哲學評論(2021年2期)2021-08-22 01:53:34軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30北京測繪(2020年12期)2020-12-29 01:33:58中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24中華詩詞(2019年7期)2019-11-25 01:43:04家庭影院技術(2017年9期)2017-09-26 03:41:45影視與戲劇評論(2016年0期)2016-11-23 05:26:01
