無線傳感器網絡LEACH算法的研究與改進
2018-10-18 02:19:02嚴浩偉
小型微型計算機系統 2018年10期
池 濤,嚴浩偉,陳 明
1(上海海洋大學 信息學院,上海 201306)
2(農業部漁業信息重點實驗室,上海 201306)
1 引 言
物聯網一般由傳感器節點部署在監控區域內,通過無線通信方式將采集到的信息發送給技術人員.由于傳感器節點通常是一個微型的嵌入式系統,由干電池供電,它的處理能力、存儲能力和通信能力都相對較弱,所以采用合理的調度算法,節省節點的能量以及延長網絡生存時間都十分重要.LEACH(Low Energy Adaptive Clustering Hierachy)算法[1]將網絡變成層次型拓撲結構,數據通信階段是通過簇內節點收集信息發送給簇頭節點,簇頭進行數據融合并且把結果發送給匯聚節點,較好地解決了網絡節點能量消耗不均衡的問題.但是該算法中由于簇頭節點需要完成數據融合、與匯聚節點通信等工作,所以能量消耗十分大.目前許多學者對LEACH算法進行了改進.文獻[2]將網絡劃分為不同的集群層,采用簇頭與簇頭之間的通信來節省能量.文獻[3]考慮到節點的剩余能量與網絡負載平衡,通過選擇簇的大小來更改周期.文獻[4]提出了VLEACH協議版本,旨在降低節點功耗.文獻[5]提出了基于功率管理、能量管理、網絡壽命、最佳簇頭選擇以及多跳數據傳輸等指標的WSN中各種聚類法.文獻[6]根據模糊算法根據節點剩余能量和節點與基站距離計算節點競爭力,通過節點競爭力采用非均勻分簇方法進行簇首選擇.文獻[7]結合PEGASIS協議提出一種新的能耗均衡的多跳路由算法,優化了簇的結構,均衡了網絡能耗,延長了網絡生命周期.但迄今為止,改進的算法不是僅考慮了節點的剩余能量就是僅考慮了位置信息,或者倆者結合考慮的時候沒有從根源上減小節點能量的消耗.
2 LEACH算法
2.1 算法介紹
LEACH算法選取簇頭的過程如下:節點產生一個0~1之間的隨機數與預設閾值做對比,如果該數小于T(n),該節點自動成為簇頭節點.閾值公式如下:
(1)
其中P是簇頭在全部節點中所占的比例,r為經過的輪數,rmod(1/P)表示一輪循環中已經當選過簇頭的節點個數,G表示一輪循環中未當選過簇頭的節點集合.節點成為簇頭以后,廣播消息通知其他節點自己是新簇頭,非簇頭節點根據自己與簇頭節點之間的距離來決定加入哪個簇頭,并通知該簇頭.當簇頭接收完所有的節點加入信息后,隨即產生一個TDMA定時消息,并且通知簇中所有節點.LEACH算法選擇出的簇頭節點進行數據融合可以降低全網數據冗余,降低網絡能量開銷,選擇出的簇頭進行數據融合后需要定時將數據結果發送給匯聚節點.
2.2 LEACH算法問題描述
LEACH算法使得節點通信變成層次通信,且簇頭個數難以控制,容易造成節點分布不均勻.簇頭擔當了數據融合的任務,減少了其他節點的數據通信量,但簇頭節點因為大量的數據通信任務,容易造成節點死亡,從而可能導致網絡的癱瘓.同時簇頭的選取也沒有考慮地理位置和節點能量信息,會造成部分節點死亡過快,從而可能導致系統的網絡生命周期縮短.目前相關學者提出的改進算法都存在各自的問題,例如LEACH-C算法[8]利用了模擬退火算法只考慮了節點的能量負載,并未考慮節點位置情況,SEP算法僅考慮了簇頭的選取[9].本文結合這三者對LEACH算法進行了改進,提出了GEC算法.
3 GEC算法
3.1 算法詳解
GEC算法思想是首先根據簇頭計算經驗公式得出簇頭個數,利用K-means算法將傳感器節點進行分簇,分好簇以后將簇內節點距離匯聚節點最近的點作為首輪簇頭節點;然后通過分層模型將簇內節點分為3個層次,同時使用分層功率控制技術減小節點能量消耗;最后備選簇頭節點直接在簇內第一層內按照節點剩余能量的大小進行選取,GEC算法很好地解決了傳統LEACH算法簇頭選取的不足,同時通過實驗比較,GEC算法相對于LEACH算法以及LEACH的一些改進算法提升了網絡生存周期,使得系統更加穩定.
3.2 K-means聚類算法
K-means聚類算法是將n個樣本點分成k個聚類,具有方法簡單、快速、效果好等特點.本文使用K-means聚類算法首先將n個傳感器節點分成k個類,由于K-means聚類算法中k值難以確定,而將它和LEACH算法結合,可以通過簇頭經驗公式(2)確定k值,而K-means的分類效果遠遠好于LEACH算法,所以本文結合兩者算法思想.
(2)
其中,N是傳感器節點總數,Efs是自由空間能量,Emp是衰減空間能量,M是區域邊長,dBS為節點到基站的平均距離.根據本文仿真實驗參數的設置,求得簇頭個數為5.因此K-means算法下的簇頭個數為5.本文使用了100個節點進行仿真實驗,K-means算法步驟如下:
第1步.從100個傳感器節點中隨機選中5個簇頭點;
第2步.然后求得所有節點到這5個簇頭的距離,如節點a距離簇頭c值最小,則節點a屬于c簇;
第3步.重新計算簇內中心點作為簇頭;
第4步.重復2、3步,直到簇頭點位置不變.
3.3 簇內分層模型
本文考慮到每次選取簇頭時計算量較大,提出基于地理位置的簇內分層算法.具體思路如下:改進的LEACH算法通過K-means算法分好簇以后,我們標記簇內離匯聚節點最近的點,這個點就選為簇頭節點,本文設定的仿真實驗網絡區域為100m*100m,根據節點的實際通訊距離,將簇內節點按照與標記節點的距離分為三個層次.具體過程為:標記節點向簇內節點廣播消息,首先標記節點使用功率等級Level a廣播數據包,簇內節點收到信息后,反饋一個信息,并將自己處于休眠狀態,所有收到信息的節點為簇內第一層.標記節點使用功率等級Level b廣播數據包,所有簇內節點收到信息后依照上一步工作,此次所有節點為第二層,剩下的簇內所有節點為第三層Level c.圖1是簇內分層的模型,一共將簇分成三個層次.

表1 功率等級與距離的關系

圖1 簇內分層模型Fig.1 Hierarchical model of the cluster
3.4 簇頭的選取
考慮到LEACH算法選取出的簇頭計算量較大且能量消耗大[10],當第一輪簇頭節點死亡以后,備選簇頭節點直接在簇內第一層內根據節點剩余能量的大小進行選取.當第二輪簇頭節點開始選取時,Level a內的節點發送數據包(包括頭部00和節點剩余能量),簇頭節點判斷該節點是否為第一層節點,如果是則通過節點剩余能量的大小來選舉.當第一層節點都死亡之后,簇頭節點從第二層內依據節點剩余能量大小來進行選取,當第二層節點也都死亡之后,第三層的節點通過剩余能量大小來進行簇頭節點的選舉,這樣只需通過數據包就能判斷出節點的位置層次,并且選出的簇頭節點具有距匯聚節點距離近和能量多的優勢,通過功率的調整,可以盡可能地延長簇頭的網絡周期,增加了網絡的魯棒性,大大減少了節點的通信開銷.
第一輪簇頭選取:將節點分為五類S(0)、S(1)、S(2)、S(3)、S(4),根據公式(3)計算每類中節點到匯聚節點的距離,每類中選擇最近的點作為簇頭節點,首輪為5個簇頭節點.
distance=sqrt((S(i).xd-(S(n+1).xd))2+
(S(i).yd-(S(n+1).yd))2)
(3)
備選簇頭節點選取:將節點按照所處位置層次進行選擇,處在第一層的節點具有高優先級,首先系統判斷節點是否處于第一層,若滿足,則根據節點的剩余能量看是否為第一層內最多來進行選取,若第一層內的節點都死亡,則第二層節點當選簇頭的優先級大于第三層節點,備選簇頭節點將在第二層內按照節點剩余能量進行選取.節點剩余能量根據公式(4)計算,備選簇頭節點由節點剩余能量最多者當選.
S(i).E=S(i).E-ETX
(4)
其中S(i).E表示節點能量,ETX表示節點發送數據的能量消耗.
3.5 分層功率控制技術
簇內分好層以后,得到了一個三層節點模型,由于標記節點使用不同的功率等級可以和簇內節點順利通信,所以簇內節點依據不同的位置層次,使用Level a、Level b、Level c三個不同的發射功率可以保證和簇頭節點順利通信,這樣保證了簇內節點的連通性.簇頭節點的發射功率依據和下一跳節點的距離進行設定.對此本文使用了傳感器節點進行試驗,芯片為CC2530,Z-Stack可設置功率范圍在-22dBm~+3dBm,設定一個板子為終端設備發送數據,一個板子為協調器節點進行接收數據,調節發射節點的功率,這里測試的功率范-22dBm~2dBm,定時發送數據,通過協調器顯示信息在串口上.因為實驗參數設置,節點的通信半徑在87m左右,所以這里選擇了可到達的通信距離結果,實驗結果見表1.通過分層功率控制技術,可以減小節點的能量消耗,節點功率與距離的關系參照公式(5).
(5)
P表示發射功率,εami和εamo表示放大參數,Rb表示傳輸速率,distance表示接收節點的距離,do表示節點通信可達距離.通過調整節點發射功率,可以得出節點發送數據時的能耗,見公式(6).
(6)
ETX表示發射單位報文損耗能量,EDA表示多路徑衰減能量,εamia表示第一層節點的放大參數,εamib表示第二層節點的放大參數,εamic表示第三層節點的放大參數,K表示數據的發送量.根據式(5)可以求得放大參數,代入式(6)可得節點能量消耗,剩余能量通過初始能量減去消耗的能量求得.通過分層功率控制技術可以減小節點傳輸數據時的能量開銷,而且保證了網絡了拓撲結構,延長了網絡壽命.
4 模擬實驗
GEC算法實驗采用MATLAB 2016a進行仿真,仿真參數設置見表2.
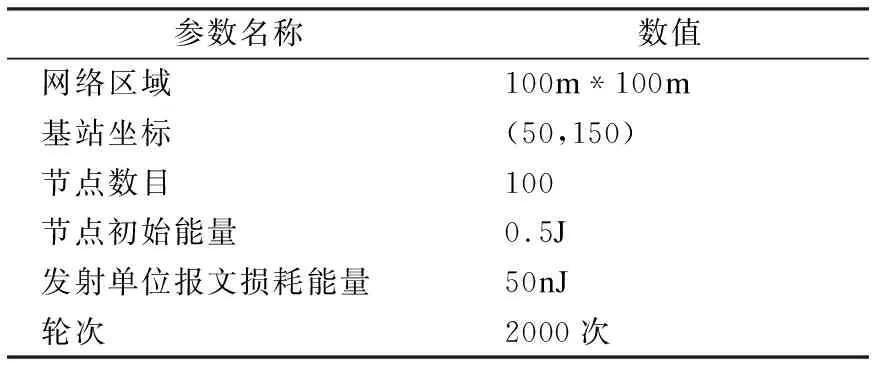
表2 仿真參數表
通過MATLAB仿真,LEACH算法和K-means聚類算法分好簇的結果如圖2、圖3所示,圖2LEACH算法隨機生成100個節點,產生了8個簇頭(圖中+號表示簇頭,其他表示節點)且位置分布不合理,分類效果差,有些簇頭負載過重,而有的負載過少,圖3 K-means聚類算法將100個節點分為了5類,節點分簇效果較好.
通過MATLAB仿真得出的一個簇內分層仿真圖如圖4所示,通過節點所處位置將簇內節點分為三個層次,依次為Level a(+節點)、Level b(*節點)、Level c(o節點).LEACH算法和GEC算法死亡節點數目對比如圖5所示,LEACH算法在進行到900輪次左右時,出現了第一個節點的死亡,到950次左右時,節點開始出現大面積死亡;LEACH-C算法在進行到940輪次左右時,出現了第一個節點的死亡,到950次左右時,節點開始出現大面積死亡;SEP算法在進行到990輪次左右時,出現了第一個節點的死亡,到1110次左右時,節點開始出現大面積死亡.GEC算法在1040輪次左右的時候,開始出現第一個節點死亡,首個節點死亡時間較LEACH算法延長了16%左右,較LEACH-C算法延長了11%左右,較SEP算法延長了5%左右.GEC算法節點在1040-1150 輪次的時候節點死亡較少, 到1150輪次左右的時候,節點開始出現大面積死亡.所以本文提出的GEC算法比LEACH算法系統魯棒性更強,系統更加穩定,節點生存周期延長.
如圖6所示,使用LEACH算法,網絡系統進行到2000輪次左右的時候,網絡剩余能量幾乎耗盡;使用LEACH-C算法,網絡系統進行到1800輪次左右的時候,網絡剩余能量幾乎耗盡;使用SEP算法,網絡系統進行到1400輪次左右的時候,網絡剩余能量幾乎耗盡,當使用GEC算法時,網絡進行到2000次左右的時候,網絡剩余能量幾乎耗盡.網絡剩余能量耗盡的時間相較于LEACH算法相近,相較于LEACH-C算法提升了11%左右,相較于SEP算法43%左右.綜上兩者分析,使用本文的GEC算法延長了整個網絡的生命周期,使得網絡系統更加穩定.

圖2 LEACH算法示意圖
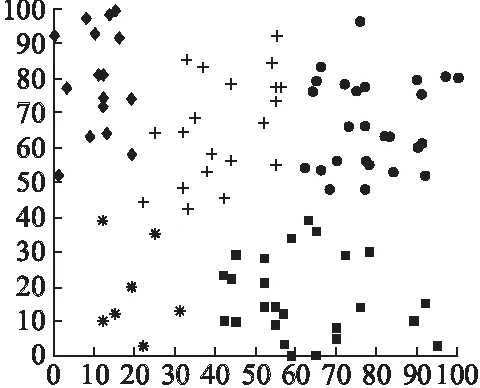
圖3 K-means聚類算法示意圖Fig.3 K-means clustering algorithm

圖4 簇內節點分層Fig.4 Hierarchical nodes in cluster


圖5 存活節點Fig.5 Surviving nodes 圖6 網絡剩余能量Fig.6 Residual energy of network
5 結語及展望
本文較其他改進LEACH算法的不同點在于,通過K-means算法可以較好地實現聚類效果,通過簇內分層技術,可以較快地選擇靠近匯聚節點并且剩余能量較大的節點作為簇頭節點,延長了網絡的生命周期.同時通過分層功率控制技術,使得節點可以順利通信,保證了不必要的能量浪費.基于粗糙集的數據融合可以很好地去除冗余信息,得出決策規則.本文提出的GEC算法較LEACH算法以及其他改進算法有了較大的提升,延長了系統的生命周期.
針對本文提出的方案,接下來的工作可以從兩方面進行加強:首先,本文提出的實驗環境沒有考慮異構性,如何保證節點在不受其他通信方式影響下順利工作,是將來工作的研究重點.此外,本文提出的GEC算法只是在MATLAB上進行了仿真,在實際環境中可能受到電磁、環境、硬件本身等影響,稍微影響實驗結果.
