自適應局部半徑的DBSCAN聚類算法
2018-10-18 02:17:52秦佳睿徐蔚鴻馬紅華曾水玲
小型微型計算機系統 2018年10期
秦佳睿,徐蔚鴻,馬紅華,曾水玲
1(長沙理工大學 計算機與通信工程學院,長沙 410114)
2(湖南省資興市科學技術局,湖南 郴州 423400)
3(吉首大學 信息科學與工程學院,湖南 吉首 416000)
1 引 言
聚類分析能夠從給定數據集中發現數據元素間的潛在聯系,挖掘感興趣的知識.基于密度的聚類分析方法(以下簡稱為“密度聚類”)能夠在簇(cluster)個數未知的情況下,完成對形狀不規則的、具有噪聲的數據集的聚類.由于這一特點,基于密度的聚類分析方法在電子商務、市場活動、地理預測、模式識別等多個領域得到廣泛應用[1,2].
DBSCAN(Density-Based on Spatial Clustering of Application with Noise)算法[5,6]是一種經典的基于密度的聚類分析算法.該算法需要用戶設定領域最小點數minPts和鄰域半徑eps兩個參數.這兩個參數的取值,對于聚類結果的影響非常大.戶不具有應用領域的先驗知識時,往往難以選擇確定合適的參數.同時,在整個聚類過程中,這兩個參數是不變的,因此在數據集密度不均勻或噪聲干擾較大的情況下,聚類結果的精確度會有所降低.
針對DBSCAN算法的上述問題,國內外許多學者提出了不同的改進方法.DBSCANCC[7]算法通過記錄簇連接信息的方法減小參數選擇的范圍,但該方法仍未實現參數的自適應調整.OPTICS-PLUS算法[8]通過有效的結果重組織策略,以輔助稀疏點的重新定位,并采用針對文本領域的特點的距離度量方法,但該方法仍未解決多密度數據集的聚類問題,而且算法時間復雜度也非常高.I-DBSCAN算法[9]根據數據集本身的統計特性,通過對距離分布矩陣的觀察確定參數,但該方法在獲取參數過程中存在誤差導致聚類結果的準確性不能滿足要求.Greedy-DBSCAN算法[10]通過貪心策略自適應確定鄰域半徑eps參數,該算法實現了自適應確定局部最優eps,并通過鄰域內點間平均距離與確定的eps參數的比較發現噪聲,但該方法難以確定噪聲判定所需的閾值參數.文獻[11]中提出一種基于局部密度峰值進行聚類的方法,該方法通過發現數據集中局部密度最大的點進行聚類,但仍需用戶確定所需局部密度峰值點的個數,并未實現參數的完全自適應.
本文提出一種自適應局部半徑的密度聚類算法SALE-DBSCAN(An Self-Adaptive LocalepsDBSCAN).該算法只需用戶確定一個參數minPts,計算所有點的局部密度,自適應發現符合條件的局部密度峰值個數,并通過自適應選擇eps擴張峰值點鄰域,最后通過類標記合并實現聚類.實驗結果表明SALE-DBSCAN算法能夠對任意形狀,且具有不同密度的數據集進行準確聚類.
本文后續的組織如下,第2節介紹密度聚類的相關概念,第3節介紹SALE-DBSCAN算法基本概念、思想與實現步驟,第4節通過實驗對SALE-DBSCAN算法的聚類效果和性能進行分析,最后對分析總結了進一步可能的工作.
2 密度聚類相關概念
密度聚類算法的基本相關概念如下[1]:
eps鄰域一個用戶指定的參數eps>0用來指定每個對象的領域半徑.對象o的eps領域是以o為中心,以eps為半徑的空間.
鄰域的密度由于鄰域大小由參數eps確定,因此鄰域的密度可以簡單地由鄰域內的對象數度量.用戶指定一個參數minPts,作為稠密區域的密度閾值.
核心點對于指定對象p,如果p的eps鄰域內所包含數據點的數量大于或等于minPts,則把對象p稱為核心點.
直接密度可達給定一個點集合D,如果點p在點q的eps鄰域內,而q是一個核心點,那么說從點q出發到點p是(關于eps和minPts)直接密度可達的(directly density-reachable).
密度可達如果存在一個點鏈p1,p2,…,pn,p1=q,pn=p,對于pi∈D(1≤i≤n),pi+1是從pi關于eps和minPts直接密度可達的,則點p是從點q關于eps和minPts密度可達的(density-reachable).
密度連通如果存在點o∈D使得點p和q都是從o關于eps和minPts密度可達的,那么點p到q是關于eps和minPts密度連通(density-connected)的.
噪聲點不被包含在任何簇中的點被稱為噪聲點(noise).
3 SALE-DBSCAN算法
本文提出的SALE-DBSCAN算法基于如下假設,即數據集中數據點分布不均勻,聚類核心點擁有比它周圍數據點更高的局部密度.可以通過計算所有數據點的局部密度,發現局部密度峰值點.通過計算局部密度峰值點所屬簇的局部半徑,再通過鄰域擴張以及對初步發現的簇進行合并,即可達到聚類的目的.SALE-DBSCAN算法只需用戶指定簇的最小點數,大大減少了參數選擇的難度.同時該算法能自動發現各簇的局部半徑,提高了聚類結果的準確率.SALE-DBSCAN算法的主要流程包括以下三個步驟.
1.發現密度峰值點;
2.擴張密度峰值點鄰域;
3.合并初步聚類結果與沖突處理.
3.1 發現密度峰值點
聚類分析的基本要求是簇內對象的距離盡可能小、不同簇間對象的距離盡可能大.從基于密度的簇的定義來看,可以將簇看做是由低密度區域分隔開的高密度區域.由此可以推知密度峰值點具有兩個典型特征,一是密度峰值點具有更高的局部密度;二是與其它簇間對象的距離比同簇中非密度峰值點與其它簇間對象的距離更大.計算每個數據點的這兩個特征即可發現密度峰值點.
定義1.數據點的鄰域 給定最小點數(minPts),數據點p的鄰域Np定義為,距離p最近的minPts個數據點組成的集合.
定義2.數據點的局部密度 給定最小點數(minPts),數據點p的局部密度(ρp)定義為:
(1)
其中,Np為p的鄰域,Dist(·)為距離函數,在本文中采用歐式距離.
為了度量密度峰值點與其它核心點的差異性,將數據點p的差異度量δp定義為:
(2)
即δp為所有比p點局部密度大的點到p點距離的最小值.當p的局部密度最大時,p最有可能是一個密度峰值點,此時δp定義為:
(3)
由p和δ的定義可知,密度峰值點的ρ值會盡可能的小,而δ值會盡可能的大.以Aggregation數據集為例,其初始數據分布如圖1 (a)所示,當minPts取值為15時,其數據點在ρ-δ空間的分布情況如圖1 (b)所示.由圖1 (b)可以明顯看出大部分數據點都集中在了一起,而越接近密度峰值點定義的點(離散點)與聚集點分離的越遠.ρ-δ空間中離散點在原數據空間的分布情況如圖1 (a)中的被圈出的點.

(a) Aggregation (b) 密度峰值點 數據集初始分布 選擇決策圖 (a)Aggregation dataset (b) Decision graph initial distribution for the data in (a)圖1Fig.1
為了在ρ-δ空間自動發現密度峰值點,本文首先計算每個數據點的ρ與δ的比值γ,定義如下:
γp=δp/ρp
(4)
又根據ρ和δ的定義,數據點的γ值越大,表明該數據點越可能是密度峰值點.對Aggregation數據集中所有數據點的γ值

(a) 對γ從小到大排序 (b) 求(a)中γ的差值(a)Value of γ in increasing (b) Value of Δγorder for the data in Figure 1 圖2Fig.2
從小到大排序,可以得到如圖2 (a)所示分布.由于γ進一步放大了密度峰值點與其它數據點的差異,因此在圖2 (a)中值劇烈變化的點可以考慮作為密度峰值點.本文通過計算γ的一階差分,即Δγ=γi+1-γi,可顯著地發現密度峰值點,如圖2 (b)中的離散點.此時密度峰值點的選擇條件為:
(5)
3.2 擴張密度峰值點鄰域
采用上節所示的方法,在數據集中找到密度峰值點之后,即可通過擴張其鄰域,以挖掘出該點所在簇.本文提出一種自動選擇局部半徑的鄰域擴張算法,較好的解決了使用全局簇半徑導致聚類結果不準確的問題.擴張密度峰值點鄰域的具體步驟如下:
1)任取一個密度峰值點p,根據其自身的局部半徑eps進行鄰域查詢,求出p的鄰域Np,如算法1所示;
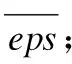

4)Np=Np∪N'p;
5)重復步驟2,直到Np不再變化;
SALE-DBSCAN算法在鄰域擴張時會多次訪問相同的數據點.為提升算法效率,可以為每個數據點設置訪問標記,在擴張數據點鄰域時,對已訪問過的數據點在本次鄰域擴張中不再重復訪問,具體見算法2.
算法1.鄰域查詢算法
輸入:數據集D,密度峰值點p,查詢半徑eps
輸出:鄰域點集Np
過程:
1:For eachiinDDo
2: IfDist(p,i)≤eps
3: PushiintoNp
4: End If
5:End For
6:ReturnNp
算法2.密度峰值點鄰域擴張算法
輸入:數據集D,密度峰值點集P
輸出:簇集合C
過程:
1: For eachpinPDo
2: 初始化數組visited[|D|]=0
3: 對p進行鄰域查詢獲得Np
4:visited[Np]=1

6:D=D-Dvisted=1
7: For eachiinNp
8: 對i進行鄰域查詢獲得N'p
9:Np=Np∪N'p
10:visited[Np]=1
12:D=D-Dvisted=1
13: End For
14: End For
3.3 合并初步聚類結果與沖突處理
3.1節提出的密度峰值點發現方法,無法保證每個簇中只包含一個密度峰值點,如圖1 (a)中所示.因此,在對每個密度峰值點進行鄰域擴張后,需要將包含相同元素的簇進行合并.合并簇時,主要需要考慮兩種情況:
1)兩個密度峰值點在同一個簇中,如圖3中所示的A和B點,此時可直接合并這兩個密度峰值點所在的簇.
2)兩個密度峰值點的簇有交集但不屬于同一個簇,如圖3中所示的C和D點.它們各自所在的簇有共同的交集(E點),但是C和D明顯應該屬于不同簇,此時不能直接將C、D所在簇合并.E點的隸屬問題就是簇合并中的沖突問題.

圖3 聚類合并情況示意圖Fig.3 Dataset initial distribution in clusteR merging
為了解決此類沖突問題,本文提出了一個解決方案.在合并兩個簇前,首先考察其交集中是否包含密度核心點,若包含密度核心點這說明這兩個簇屬于第一種情況,可以直接合并兩個簇;若不包含任何密度核心點則屬于第二種情況,此時需進一步確定其交集元素的隸屬問題.以圖3中的E點為例,假設左邊的簇標簽為1,右邊的標簽為2,E的隸屬函數定義為:
(6)

4 實驗與分析
本文采用Matlab編程實現了SALE-DBSCAN算法,并在不同形狀、大小和密度分布的多個數據集上,通過實驗對比了采用全局聚類半徑的DBSCAN算法、使用了基于貪心策略選擇的局部聚類半徑的Greedy-DBSCAN算法與SALE-DBSCAN算法聚類結果和運行效率.實驗結果表明,SALE-DBSCAN算法在聚類質量上優于DBSCAN算法和Greedy-DBSCAN算法.具體的實驗結果與分析如下.
4.1 實驗環境
實驗的軟硬件環境如下所示:
操作系統:Windows 10;
開發工具:Matlab 2016;
CPU:Inter Core i5-4200H 2.80GHz;
內存:8GB
4.2 實驗結果分析
本實驗中所使用數據集均取自Shape Sets[14].在不均勻數據集中,以compound數據集為例,DBSCAN算法把圖4(a)中A區域點錯誤判定為噪聲點(噪聲點標識為“×”);Greedy-DBSCAN算法雖然使用了局部半徑進行聚類,但是未能有效識別噪聲點,如圖4(b)中的B區域中形狀不同的點.SALE-DBSCAN算法對compound數據集所有簇與噪聲進行了準確劃分,如圖4(c).

圖4 compound聚類結果圖Fig.4 Compound dataset clustering result
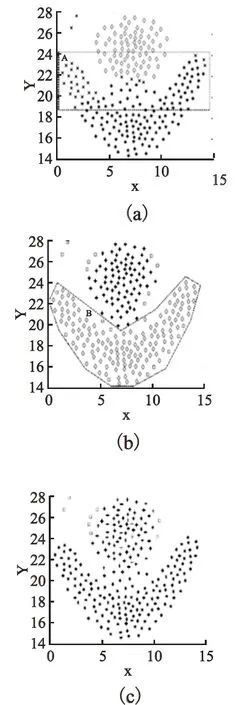
圖5 flame聚類結果Fig.5 Flame dataset clustering result
在相對均勻數據集中,以flame數據集為例,DBSCAN算法的聚類結果中出現了被錯誤劃分的噪聲,如圖5(a)所示;Greedy-DBSCAN算法得到了相對準確的聚類結果,但是從圖5(b)中的B區域可以看出,在簇的邊緣區域出現了將原本應該歸為簇中的點判定為噪聲的情況(噪聲用“□”表示);而SALE-DBSCAN算法的聚類結果將數據集比較精確的分為兩個簇,同時降低了誤判噪聲的數量,在flame數據集上得到了優于其他算法的聚類結果,如圖5(c).
為更進一步驗證聚類結果的準確性,本文使用SALE-DBSCAN算法分別對Aggregation、R15和t4.8k數據集進行聚類.在球狀數據集中,SALE-DBSCAN算法能夠獲得比較準確的聚類結果,如圖6(a)、圖6(b);在不規則且存在干擾點的數據集中,SALE-DBSCAN算法能夠有效處理干擾點,如圖6(c).

圖6 SALE-DBSCAN聚類結果展示Fig.6 SALE-DBSCAN clustering result
在5個不同數據集中,采用F度量(F-Measure)[16]對聚類結果的準確度進行定量分析.結果顯示SALE-DBSCAN算法的聚類精確度均高于DBSCAN算法與Greedy-DBSCAN算法,如圖7所示.實驗表明SALE-DBSCAN算法的聚類質量優于其他兩種算法.但是,由于SALE-DBSCAN在參數自適應選擇、聚類合并過程中產生了大量時間開銷,因此時間消耗要高于其他兩種聚類算法,具體對比結果如圖8所示(三個準確率從左至有分別為SALE-DBSCAN、Greedy-DBSCAN、DBSCAN).

圖7 聚類準確率對比圖Fig.7 Clustering precision

圖8 運行時間對比圖Fig.8 Running time
5 結 語
本文提出了一種自適應局部半徑DBSCAN算法,該算法不但繼承了密度聚類算法的優點,能夠對任意形狀的數據集進行準確聚類;并且僅需用戶指定一個參數,實現了鄰域半徑選擇的自適應;實驗證明本文所提算法聚類結果明顯優于DBSCAN算法與Greedy-DBSCAN算法;但由實驗結果可知,目前SALE-DBSCAN算法時間效率要低于DBSCAN算法與Greedy-DBSCAN算法.下一步目標是如何將改進算法與MapReduce、網格技術相結合;通過網格技術對數據進行預處理,劃分成多個數據塊并保持數據間的密度可達性,通過MapReduce完成對海量數據的聚類.
